 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikeTrack: A Spike-driven Framework for Efficient Visual Tracking
Feb 27, 2026Spiking Neural Networks (SNNs) promise energy-efficient vision, but applying them to RGB visual tracking remains difficult: Existing SNN tracking frameworks either do not fully align with spike-driven computation or do not fully leverage neurons' spatiotemporal dynamics, leading to a trade-off between efficiency and accuracy. To address this, we introduce SpikeTrack, a spike-driven framework for energy-efficient RGB object tracking. SpikeTrack employs a novel asymmetric design that uses asymmetric timestep expansion and unidirectional information flow, harnessing spatiotemporal dynamics while cutting computation. To ensure effective unidirectional information transfer between branches, we design a memory-retrieval module inspired by neural inference mechanisms. This module recurrently queries a compact memory initialized by the template to retrieve target cues and sharpen target perception over time. Extensive experiments demonstrate that SpikeTrack achieves the state-of-the-art among SNN-based trackers and remains competitive with advanced ANN trackers. Notably, it surpasses TransT on LaSOT dataset while consuming only 1/26 of its energy. To our knowledge, SpikeTrack is the first spike-driven framework to make RGB tracking both accurate and energy efficient. The code and models are available at https://github.com/faicaiwawa/SpikeTrack.
FlowCut: Rethinking Redundancy via Information Flow for Efficient Vision-Language Models
May 26, 2025Large vision-language models (LVLMs) excel at multimodal understanding but suffer from high computational costs due to redundant vision tokens. Existing pruning methods typically rely on single-layer attention scores to rank and prune redundant visual tokens to solve this inefficiency. However, as the interaction between tokens and layers is complicated, this raises a basic question: Is such a simple single-layer criterion sufficient to identify redundancy? To answer this question, we rethink the emergence of redundant visual tokens from a fundamental perspective: information flow, which models the interaction between tokens and layers by capturing how information moves between tokens across layers. We find (1) the CLS token acts as an information relay, which can simplify the complicated flow analysis; (2) the redundancy emerges progressively and dynamically via layer-wise attention concentration; and (3) relying solely on attention scores from single layers can lead to contradictory redundancy identification. Based on this, we propose FlowCut, an information-flow-aware pruning framework, mitigating the insufficiency of the current criterion for identifying redundant tokens and better aligning with the model's inherent behaviors. Extensive experiments show that FlowCut achieves superior results, outperforming SoTA by 1.6% on LLaVA-1.5-7B with 88.9% token reduction, and by 4.3% on LLaVA-NeXT-7B with 94.4% reduction, delivering 3.2x speed-up in the prefilling stage. Our code is available at https://github.com/TungChintao/FlowCut
RA-BLIP: Multimodal Adaptive Retrieval-Augmented Bootstrapping Language-Image Pre-training
Oct 18, 2024



Multimodal Large Language Models (MLLMs) have recently received substantial interest, which shows their emerging potential as general-purpose models for various vision-language tasks. MLLMs involve significant external knowledge within their parameters; however, it is challenging to continually update these models with the latest knowledge, which involves huge computational costs and poor interpretability. Retrieval augmentation techniques have proven to be effective plugins for both LLMs and MLLMs. In this study, we propose multimodal adaptive Retrieval-Augmented Bootstrapping Language-Image Pre-training (RA-BLIP), a novel retrieval-augmented framework for various MLLMs. Considering the redundant information within vision modality, we first leverage the question to instruct the extraction of visual information through interactions with one set of learnable queries, minimizing irrelevant interference during retrieval and generation. Besides, we introduce a pre-trained multimodal adaptive fusion module to achieve question text-to-multimodal retrieval and integration of multimodal knowledge by projecting visual and language modalities into a unified semantic space. Furthermore, we present an Adaptive Selection Knowledge Generation (ASKG) strategy to train the generator to autonomously discern the relevance of retrieved knowledge, which realizes excellent denoising performance. Extensive experiments on open multimodal question-answering datasets demonstrate that RA-BLIP achieves significant performance and surpasses the state-of-the-art retrieval-augmented models.
New Solutions on LLM Acceleration, Optimization, and Application
Jun 16, 2024



Large Language Models (LLMs) have become extremely potent instruments with exceptional capacities for comprehending and producing human-like text in a wide range of applications. However, the increasing size and complexity of LLMs present significant challenges in both training and deployment, leading to substantial computational and storage costs as well as heightened energy consumption. In this paper, we provide a review of recent advancements and research directions aimed at addressing these challenges and enhancing the efficiency of LLM-based systems. We begin by discussing algorithm-level acceleration techniques focused on optimizing LLM inference speed and resource utilization. We also explore LLM-hardware co-design strategies with a vision to improve system efficiency by tailoring hardware architectures to LLM requirements. Further, we delve into LLM-to-accelerator compilation approaches, which involve customizing hardware accelerators for efficient LLM deployment. Finally, as a case study to leverage LLMs for assisting circuit design, we examine LLM-aided design methodologies for an important task: High-Level Synthesis (HLS) functional verification, by creating a new dataset that contains a large number of buggy and bug-free codes, which can be essential for training LLMs to specialize on HLS verification and debugging. For each aspect mentioned above, we begin with a detailed background study, followed by the presentation of several novel solutions proposed to overcome specific challenges. We then outline future research directions to drive further advancements. Through these efforts, we aim to pave the way for more efficient and scalable deployment of LLMs across a diverse range of applications.
Heterophilous Distribution Propagation for Graph Neural Networks
May 31, 2024



Graph Neural Networks (GNNs) have achieved remarkable success in various graph mining tasks by aggregating information from neighborhoods for representation learning. The success relies on the homophily assumption that nearby nodes exhibit similar behaviors, while it may be violated in many real-world graphs. Recently, heterophilous graph neural networks (HeterGNNs) have attracted increasing attention by modifying the neural message passing schema for heterophilous neighborhoods. However, they suffer from insufficient neighborhood partition and heterophily modeling, both of which are critical but challenging to break through. To tackle these challenges, in this paper, we propose heterophilous distribution propagation (HDP) for graph neural networks. Instead of aggregating information from all neighborhoods, HDP adaptively separates the neighbors into homophilous and heterphilous parts based on the pseudo assignments during training. The heterophilous neighborhood distribution is learned with orthogonality-oriented constraint via a trusted prototype contrastive learning paradigm. Both the homophilous and heterophilous patterns are propagated with a novel semantic-aware message passing mechanism. We conduct extensive experiments on 9 benchmark datasets with different levels of homophily. Experimental results show that our method outperforms representative baselines on heterophilous datasets.
SnapKV: LLM Knows What You are Looking for Before Generation
Apr 22, 2024



Large Language Models (LLMs) have made remarkable progress in processing extensive contexts, with the Key-Value (KV) cache playing a vital role in enhancing their performance. However, the growth of the KV cache in response to increasing input length poses challenges to memory and time efficiency. To address this problem, this paper introduces SnapKV, an innovative and fine-tuning-free approach that efficiently minimizes KV cache size while still delivering comparable performance in real-world applications. We discover that each attention head in the model consistently focuses on specific prompt attention features during generation. Meanwhile, this robust pattern can be obtained from an `observation' window located at the end of the prompts. Drawing on this insight, SnapKV automatically compresses KV caches by selecting clustered important KV positions for each attention head. Our approach significantly reduces the growing computational overhead and memory footprint when processing long input sequences. Specifically, SnapKV achieves a consistent decoding speed with a 3.6x increase in generation speed and an 8.2x enhancement in memory efficiency compared to baseline when processing inputs of 16K tokens. At the same time, it maintains comparable performance to baseline models across 16 long sequence datasets. Moreover, SnapKV can process up to 380K context tokens on a single A100-80GB GPU using HuggingFace implementation with minor changes, exhibiting only a negligible accuracy drop in the Needle-in-a-Haystack test. Further comprehensive studies suggest SnapKV's potential for practical applications.
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Jan 19, 2024



The inference process in Large Language Models (LLMs) is often limited due to the absence of parallelism in the auto-regressive decoding process, resulting in most operations being restricted by the memory bandwidth of accelerators. While methods such as speculative decoding have been suggested to address this issue, their implementation is impeded by the challenges associated with acquiring and maintaining a separate draft model. In this paper, we present Medusa, an efficient method that augments LLM inference by adding extra decoding heads to predict multiple subsequent tokens in parallel. Using a tree-based attention mechanism, Medusa constructs multiple candidate continuations and verifies them simultaneously in each decoding step. By leveraging parallel processing, Medusa introduces only minimal overhead in terms of single-step latency while substantially reducing the number of decoding steps required. We present two levels of fine-tuning procedures for Medusa to meet the needs of different use cases: Medusa-1: Medusa is directly fine-tuned on top of a frozen backbone LLM, enabling lossless inference acceleration. Medusa-2: Medusa is fine-tuned together with the backbone LLM, enabling better prediction accuracy of Medusa heads and higher speedup but needing a special training recipe that preserves the backbone model's capabilities. Moreover, we propose several extensions that improve or expand the utility of Medusa, including a self-distillation to handle situations where no training data is available and a typical acceptance scheme to boost the acceptance rate while maintaining generation quality. We evaluate Medusa on models of various sizes and training procedures. Our experiments demonstrate that Medusa-1 can achieve over 2.2x speedup without compromising generation quality, while Medusa-2 further improves the speedup to 2.3-3.6x.
Synthesizing Coherent Story with Auto-Regressive Latent Diffusion Models
Nov 20, 2022



Conditioned diffusion models have demonstrated state-of-the-art text-to-image synthesis capacity. Recently, most works focus on synthesizing independent images; While for real-world applications, it is common and necessary to generate a series of coherent images for story-stelling. In this work, we mainly focus on story visualization and continuation tasks and propose AR-LDM, a latent diffusion model auto-regressively conditioned on history captions and generated images. Moreover, AR-LDM can generalize to new characters through adaptation. To our best knowledge, this is the first work successfully leveraging diffusion models for coherent visual story synthesizing. Quantitative results show that AR-LDM achieves SoTA FID scores on PororoSV, FlintstonesSV, and the newly introduced challenging dataset VIST containing natural images. Large-scale human evaluations show that AR-LDM has superior performance in terms of quality, relevance, and consistency.
Extensible Proxy for Efficient NAS
Oct 17, 2022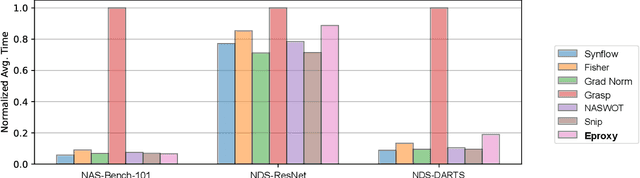

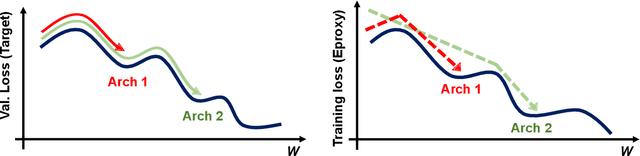

Neural Architecture Search (NAS) has become a de facto approach in the recent trend of AutoML to design deep neural networks (DNNs). Efficient or near-zero-cost NAS proxies are further proposed to address the demanding computational issues of NAS, where each candidate architecture network only requires one iteration of backpropagation. The values obtained from the proxies are considered the predictions of architecture performance on downstream tasks. However, two significant drawbacks hinder the extended usage of Efficient NAS proxies. (1) Efficient proxies are not adaptive to various search spaces. (2) Efficient proxies are not extensible to multi-modality downstream tasks. Based on the observations, we design a Extensible proxy (Eproxy) that utilizes self-supervised, few-shot training (i.e., 10 iterations of backpropagation) which yields near-zero costs. The key component that makes Eproxy efficient is an untrainable convolution layer termed barrier layer that add the non-linearities to the optimization spaces so that the Eproxy can discriminate the performance of architectures in the early stage. Furthermore, to make Eproxy adaptive to different downstream tasks/search spaces, we propose a Discrete Proxy Search (DPS) to find the optimized training settings for Eproxy with only handful of benchmarked architectures on the target tasks. Our extensive experiments confirm the effectiveness of both Eproxy and Eproxy+DPS. Code is available at https://github.com/leeyeehoo/GenNAS-Zero.
What Makes Convolutional Models Great on Long Sequence Modeling?
Oct 17, 2022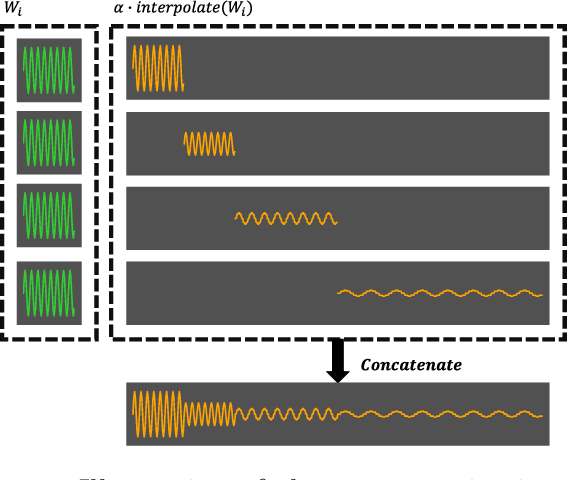
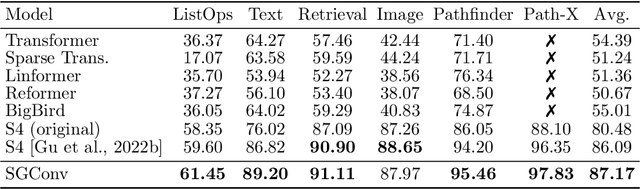
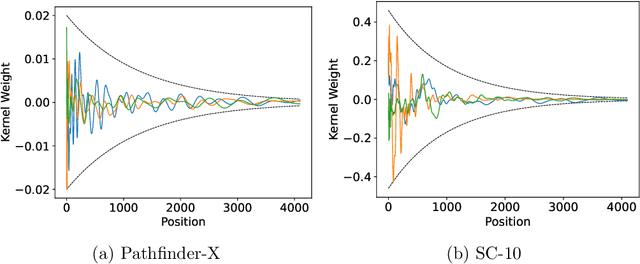
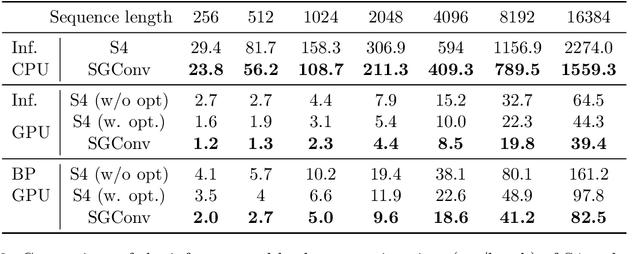
Convolutional models have been widely used in multiple domains. However, most existing models only use local convolution, making the model unable to handle long-range dependency efficiently. Attention overcomes this problem by aggregating global information but also makes the computational complexity quadratic to the sequence length. Recently, Gu et al. [2021] proposed a model called S4 inspired by the state space model. S4 can be efficiently implemented as a global convolutional model whose kernel size equals the input sequence length. S4 can model much longer sequences than Transformers and achieve significant gains over SoTA on several long-range tasks. Despite its empirical success, S4 is involved. It requires sophisticated parameterization and initialization schemes. As a result, S4 is less intuitive and hard to use. Here we aim to demystify S4 and extract basic principles that contribute to the success of S4 as a global convolutional model. We focus on the structure of the convolution kernel and identify two critical but intuitive principles enjoyed by S4 that are sufficient to make up an effective global convolutional model: 1) The parameterization of the convolutional kernel needs to be efficient in the sense that the number of parameters should scale sub-linearly with sequence length. 2) The kernel needs to satisfy a decaying structure that the weights for convolving with closer neighbors are larger than the more distant ones. Based on the two principles, we propose a simple yet effective convolutional model called Structured Global Convolution (SGConv). SGConv exhibits strong empirical performance over several tasks: 1) With faster speed, SGConv surpasses S4 on Long Range Arena and Speech Command datasets. 2) When plugging SGConv into standard language and vision models, it shows the potential to improve both efficiency and performance.