 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Multimodal Fusion with TupleInfoNCE
Jul 06, 2021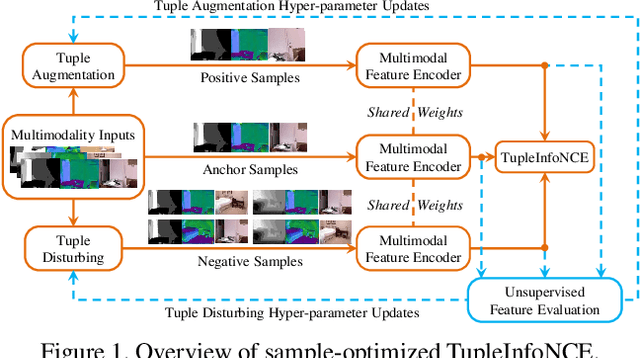
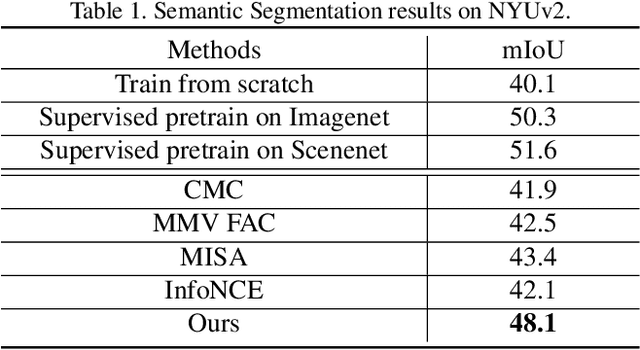
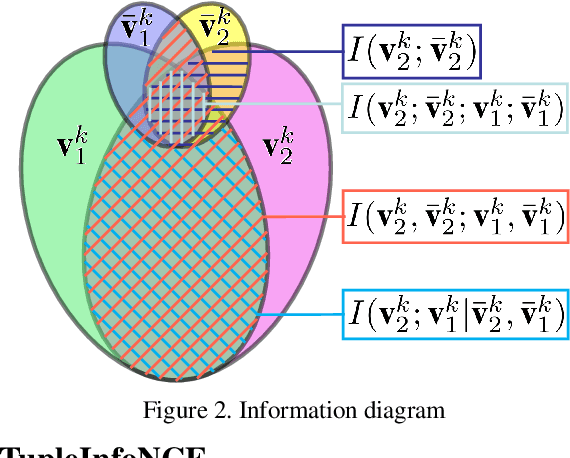
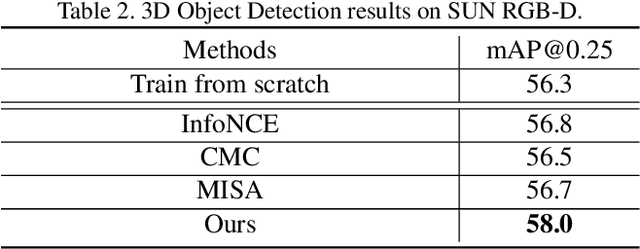
This paper proposes a method for representation learning of multimodal data using contrastive losses. A traditional approach is to contrast different modalities to learn the information shared between them. However, that approach could fail to learn the complementary synergies between modalities that might be useful for downstream tasks. Another approach is to concatenate all the modalities into a tuple and then contrast positive and negative tuple correspondences. However, that approach could consider only the stronger modalities while ignoring the weaker ones. To address these issues, we propose a novel contrastive learning objective, TupleInfoNCE. It contrasts tuples based not only on positive and negative correspondences but also by composing new negative tuples using modalities describing different scenes. Training with these additional negatives encourages the learning model to examine the correspondences among modalities in the same tuple, ensuring that weak modalities are not ignored. We provide a theoretical justification based on mutual information for why this approach works, and we propose a sample optimization algorithm to generate positive and negative samples to maximize training efficacy. We find that TupleInfoNCE significantly outperforms the previous state of the arts on three different downstream tasks.
Spatial Intention Maps for Multi-Agent Mobile Manipulation
Mar 23, 2021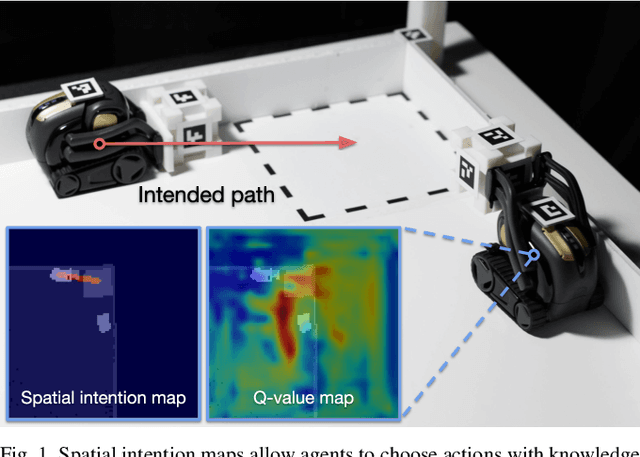
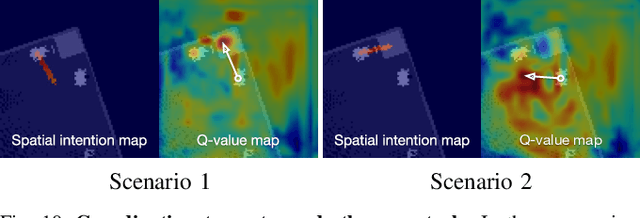
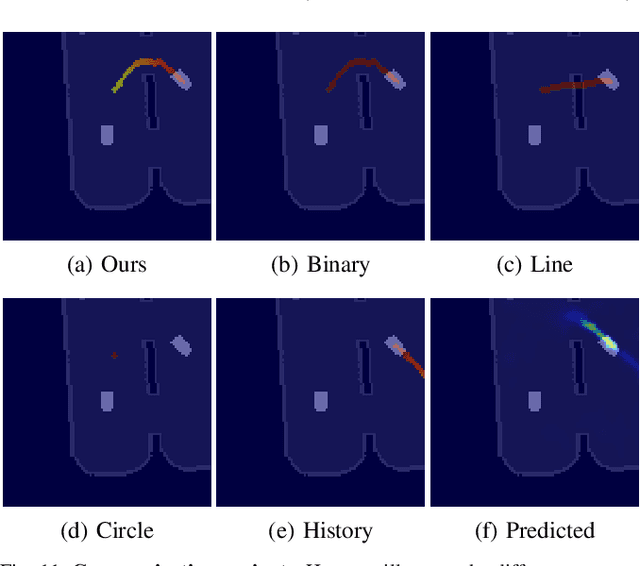
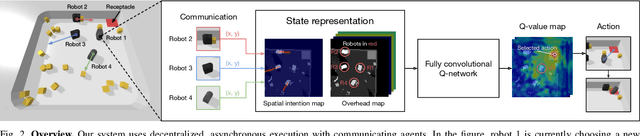
The ability to communicate intention enables decentralized multi-agent robots to collaborate while performing physical tasks. In this work, we present spatial intention maps, a new intention representation for multi-agent vision-based deep reinforcement learning that improves coordination between decentralized mobile manipulators. In this representation, each agent's intention is provided to other agents, and rendered into an overhead 2D map aligned with visual observations. This synergizes with the recently proposed spatial action maps framework, in which state and action representations are spatially aligned, providing inductive biases that encourage emergent cooperative behaviors requiring spatial coordination, such as passing objects to each other or avoiding collisions. Experiments across a variety of multi-agent environments, including heterogeneous robot teams with different abilities (lifting, pushing, or throwing), show that incorporating spatial intention maps improves performance for different mobile manipulation tasks while significantly enhancing cooperative behaviors.
IBRNet: Learning Multi-View Image-Based Rendering
Feb 25, 2021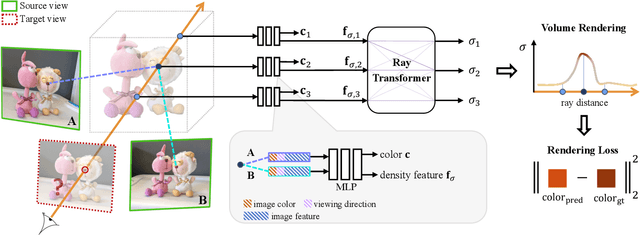
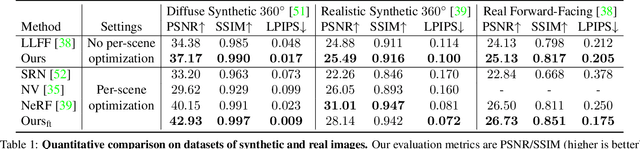
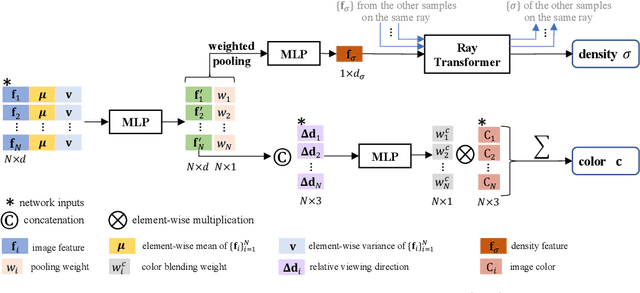
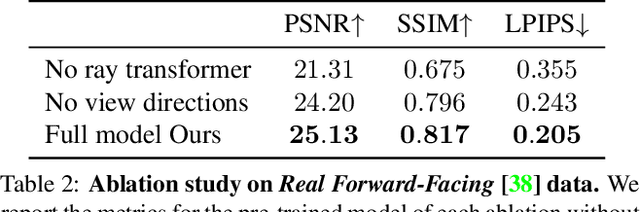
We present a method that synthesizes novel views of complex scenes by interpolating a sparse set of nearby views. The core of our method is a network architecture that includes a multilayer perceptron and a ray transformer that estimates radiance and volume density at continuous 5D locations (3D spatial locations and 2D viewing directions), drawing appearance information on the fly from multiple source views. By drawing on source views at render time, our method hearkens back to classic work on image-based rendering (IBR), and allows us to render high-resolution imagery. Unlike neural scene representation work that optimizes per-scene functions for rendering, we learn a generic view interpolation function that generalizes to novel scenes. We render images using classic volume rendering, which is fully differentiable and allows us to train using only multi-view posed images as supervision. Experiments show that our method outperforms recent novel view synthesis methods that also seek to generalize to novel scenes. Further, if fine-tuned on each scene, our method is competitive with state-of-the-art single-scene neural rendering methods.
P4Contrast: Contrastive Learning with Pairs of Point-Pixel Pairs for RGB-D Scene Understanding
Dec 24, 2020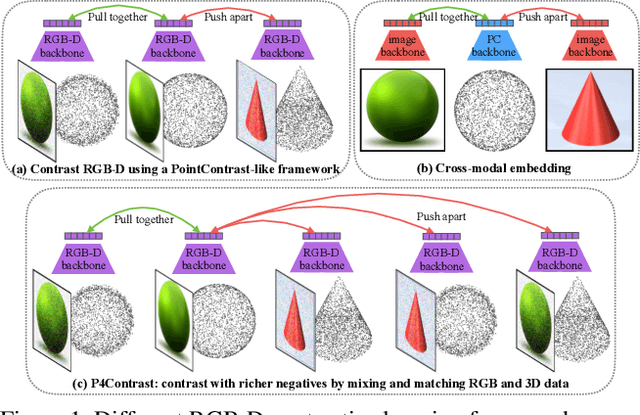
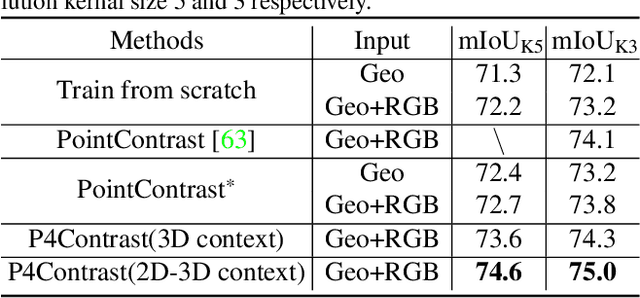
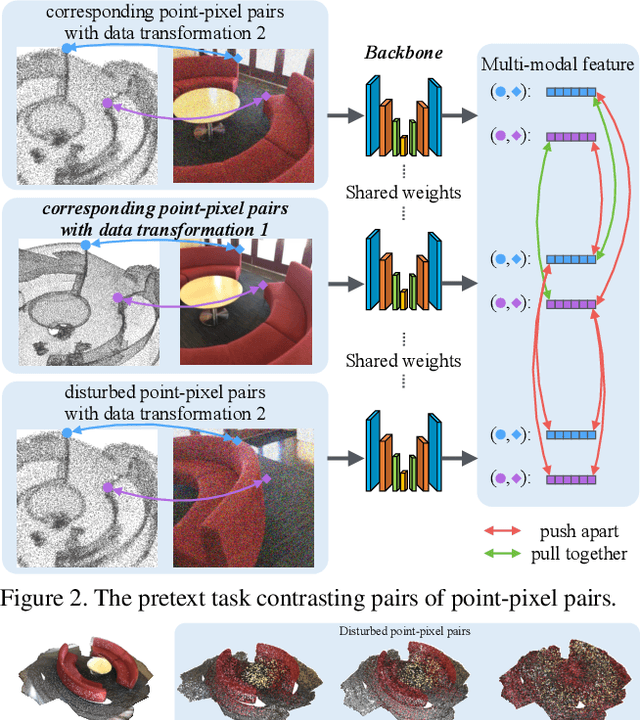
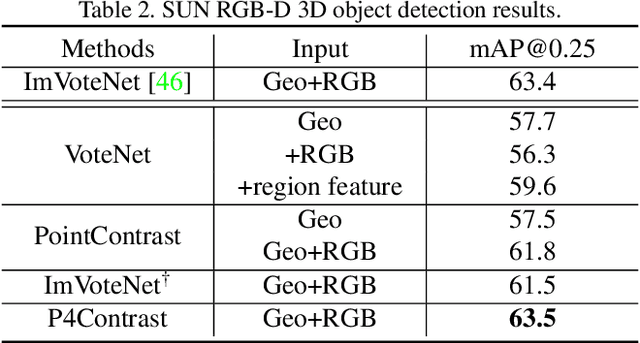
Self-supervised representation learning is a critical problem in computer vision, as it provides a way to pretrain feature extractors on large unlabeled datasets that can be used as an initialization for more efficient and effective training on downstream tasks. A promising approach is to use contrastive learning to learn a latent space where features are close for similar data samples and far apart for dissimilar ones. This approach has demonstrated tremendous success for pretraining both image and point cloud feature extractors, but it has been barely investigated for multi-modal RGB-D scans, especially with the goal of facilitating high-level scene understanding. To solve this problem, we propose contrasting "pairs of point-pixel pairs", where positives include pairs of RGB-D points in correspondence, and negatives include pairs where one of the two modalities has been disturbed and/or the two RGB-D points are not in correspondence. This provides extra flexibility in making hard negatives and helps networks to learn features from both modalities, not just the more discriminating one of the two. Experiments show that this proposed approach yields better performance on three large-scale RGB-D scene understanding benchmarks (ScanNet, SUN RGB-D, and 3RScan) than previous pretraining approaches.
Object-Centric Neural Scene Rendering
Dec 15, 2020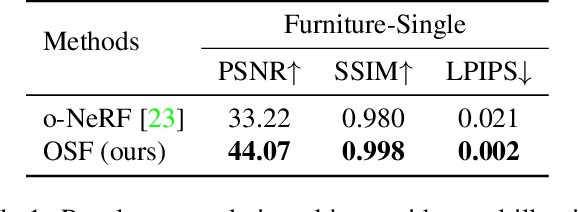

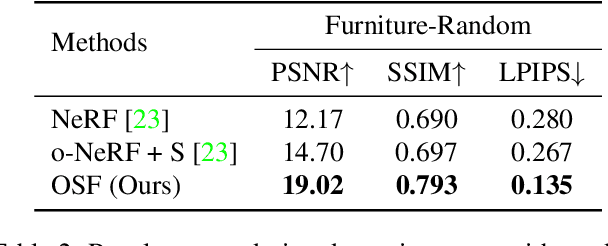
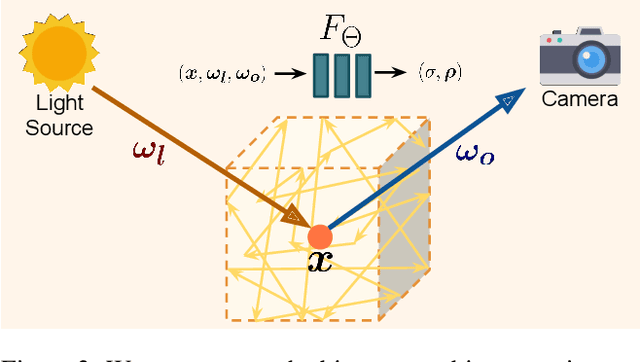
We present a method for composing photorealistic scenes from captured images of objects. Our work builds upon neural radiance fields (NeRFs), which implicitly model the volumetric density and directionally-emitted radiance of a scene. While NeRFs synthesize realistic pictures, they only model static scenes and are closely tied to specific imaging conditions. This property makes NeRFs hard to generalize to new scenarios, including new lighting or new arrangements of objects. Instead of learning a scene radiance field as a NeRF does, we propose to learn object-centric neural scattering functions (OSFs), a representation that models per-object light transport implicitly using a lighting- and view-dependent neural network. This enables rendering scenes even when objects or lights move, without retraining. Combined with a volumetric path tracing procedure, our framework is capable of rendering both intra- and inter-object light transport effects including occlusions, specularities, shadows, and indirect illumination. We evaluate our approach on scene composition and show that it generalizes to novel illumination conditions, producing photorealistic, physically accurate renderings of multi-object scenes.
Robust Neural Routing Through Space Partitions for Camera Relocalization in Dynamic Indoor Environments
Dec 08, 2020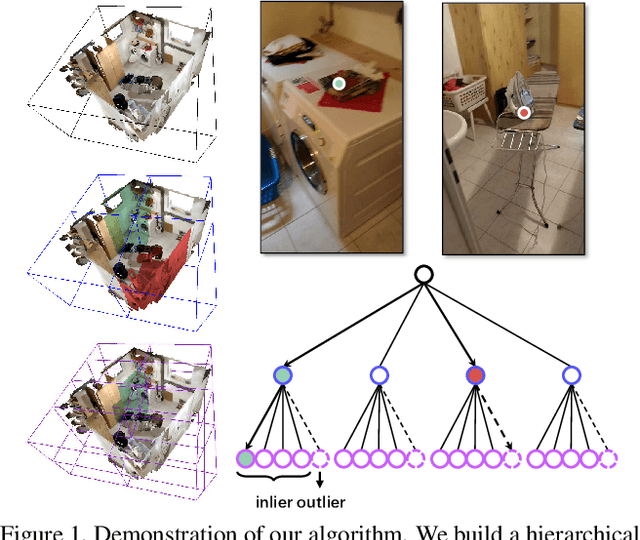
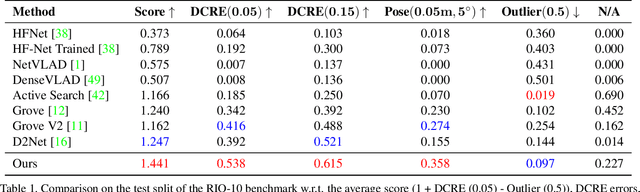
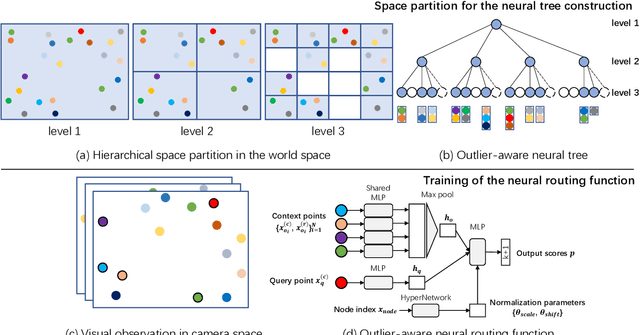
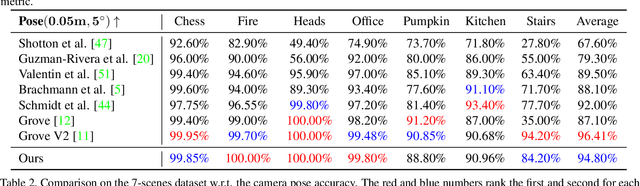
Localizing the camera in a known indoor environment is a key building block for scene mapping, robot navigation, AR, etc. Recent advances estimate the camera pose via optimization over the 2D/3D-3D correspondences established between the coordinates in 2D/3D camera space and 3D world space. Such a mapping is estimated with either a convolution neural network or a decision tree using only the static input image sequence, which makes these approaches vulnerable to dynamic indoor environments that are quite common yet challenging in the real world. To address the aforementioned issues, in this paper, we propose a novel outlier-aware neural tree which bridges the two worlds, deep learning and decision tree approaches. It builds on three important blocks; (a) a hierarchical space partition over the indoor scene to construct the decision tree; (b) a neural routing function, implemented as a deep classification network, employed for better 3D scene understanding; and (c) an outlier rejection module used to filter out dynamic points during the hierarchical routing process. Our proposed algorithm is evaluated on the RIO-10 benchmark developed for camera relocalization in dynamic indoor environment. It achieves robust neural routing through space partitions and outperforms the state-of-the-art approaches by around 30\% on camera pose accuracy, while running comparably fast for evaluation.
Forecasting Characteristic 3D Poses of Human Actions
Nov 30, 2020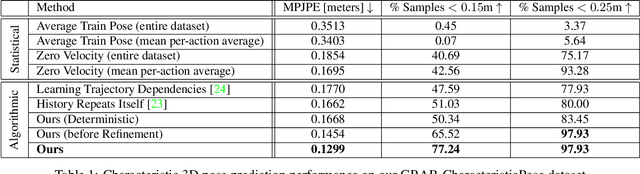
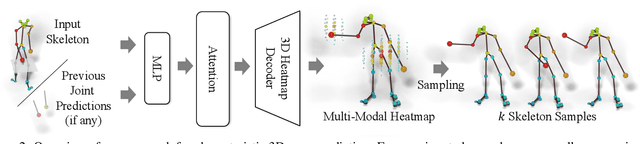
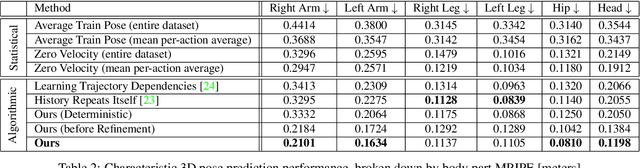
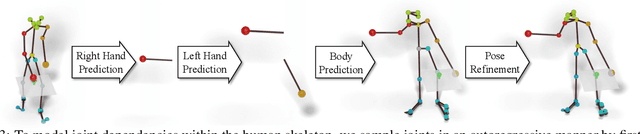
We propose the task of forecasting characteristic 3D poses: from a single pose observation of a person, to predict a future 3D pose of that person in a likely action-defining, characteristic pose - for instance, from observing a person picking up a banana, predict the pose of the person eating the banana. Prior work on human motion prediction estimates future poses at fixed time intervals. Although easy to define, this frame-by-frame formulation confounds temporal and intentional aspects of human action. Instead, we define a goal-directed pose prediction task that decouples pose prediction from time, taking inspiration from human, goal-directed behavior. To predict characteristic goal poses, we propose a probabilistic approach that first models the possible multi-modality in the distribution of possible characteristic poses. It then samples future pose hypotheses from the predicted distribution in an autoregressive fashion to model dependencies between joints and then optimizes the final pose with bone length and angle constraints. To evaluate our method, we construct a dataset of manually annotated single-frame observations and characteristic 3D poses. Our experiments with this dataset suggest that our proposed probabilistic approach outperforms state-of-the-art approaches by 22% on average.
Learning to Infer Semantic Parameters for 3D Shape Editing
Nov 09, 2020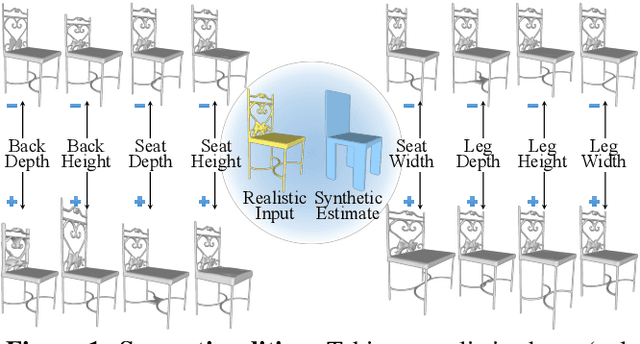

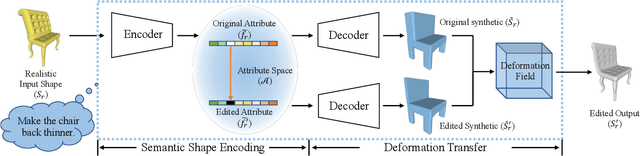
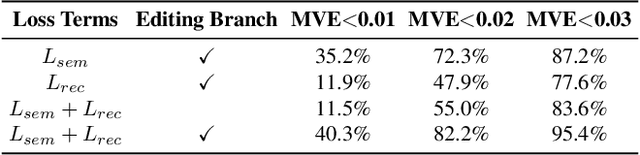
Many applications in 3D shape design and augmentation require the ability to make specific edits to an object's semantic parameters (e.g., the pose of a person's arm or the length of an airplane's wing) while preserving as much existing details as possible. We propose to learn a deep network that infers the semantic parameters of an input shape and then allows the user to manipulate those parameters. The network is trained jointly on shapes from an auxiliary synthetic template and unlabeled realistic models, ensuring robustness to shape variability while relieving the need to label realistic exemplars. At testing time, edits within the parameter space drive deformations to be applied to the original shape, which provides semantically-meaningful manipulation while preserving the details. This is in contrast to prior methods that either use autoencoders with a limited latent-space dimensionality, failing to preserve arbitrary detail, or drive deformations with purely-geometric controls, such as cages, losing the ability to update local part regions. Experiments with datasets of chairs, airplanes, and human bodies demonstrate that our method produces more natural edits than prior work.
Multi-Frame to Single-Frame: Knowledge Distillation for 3D Object Detection
Sep 24, 2020
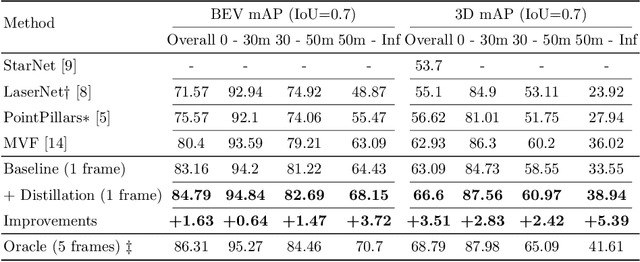

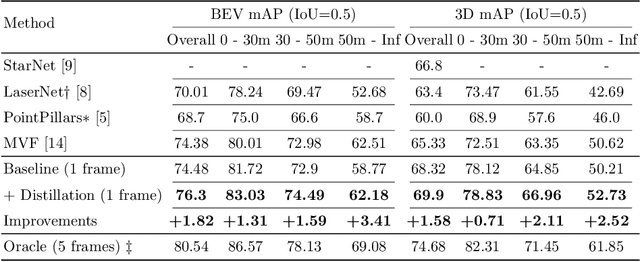
A common dilemma in 3D object detection for autonomous driving is that high-quality, dense point clouds are only available during training, but not testing. We use knowledge distillation to bridge the gap between a model trained on high-quality inputs at training time and another tested on low-quality inputs at inference time. In particular, we design a two-stage training pipeline for point cloud object detection. First, we train an object detection model on dense point clouds, which are generated from multiple frames using extra information only available at training time. Then, we train the model's identical counterpart on sparse single-frame point clouds with consistency regularization on features from both models. We show that this procedure improves performance on low-quality data during testing, without additional overhead.
Pillar-based Object Detection for Autonomous Driving
Jul 26, 2020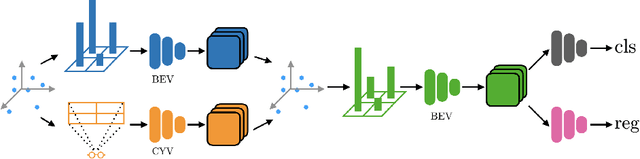
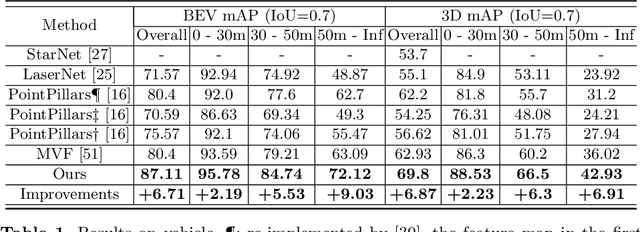
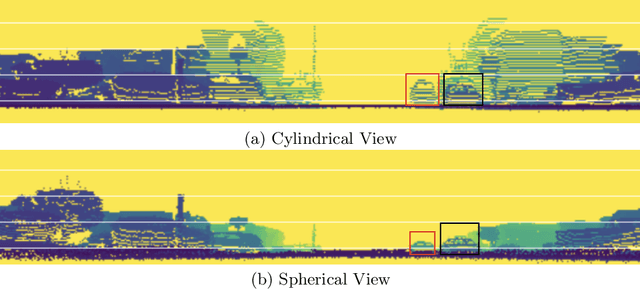

We present a simple and flexible object detection framework optimized for autonomous driving. Building on the observation that point clouds in this application are extremely sparse, we propose a practical pillar-based approach to fix the imbalance issue caused by anchors. In particular, our algorithm incorporates a cylindrical projection into multi-view feature learning, predicts bounding box parameters per pillar rather than per point or per anchor, and includes an aligned pillar-to-point projection module to improve the final prediction. Our anchor-free approach avoids hyperparameter search associated with past methods, simplifying 3D object detection while significantly improving upon state-of-the-art.