 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Person Generation: A Survey from the Perspective of Face, Pose and Cloth Synthesis
Sep 05, 2021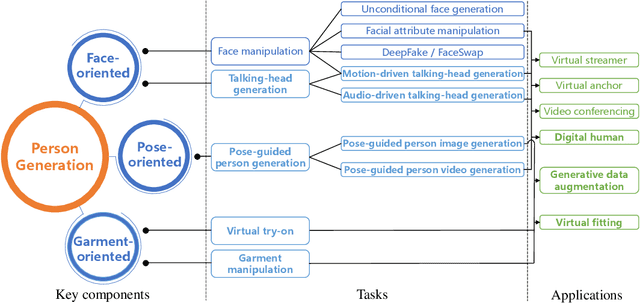
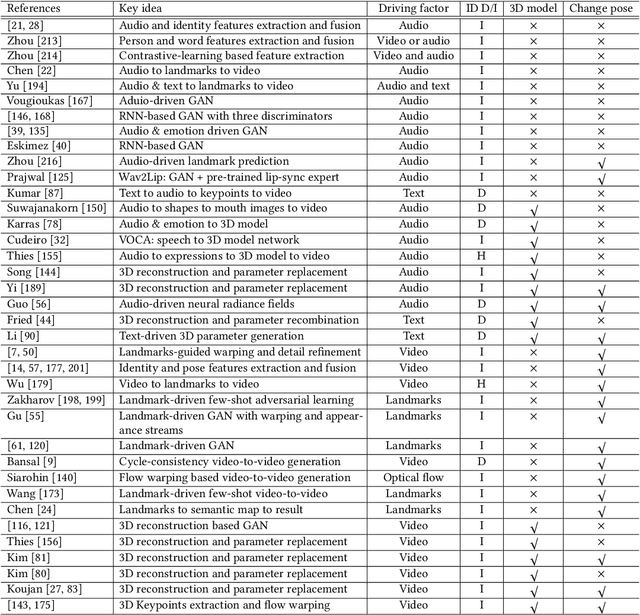
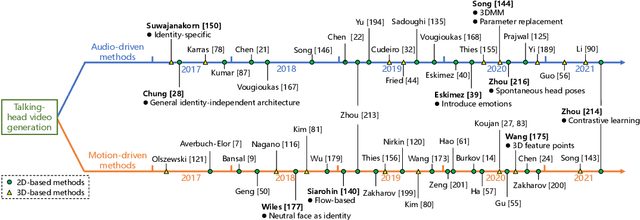
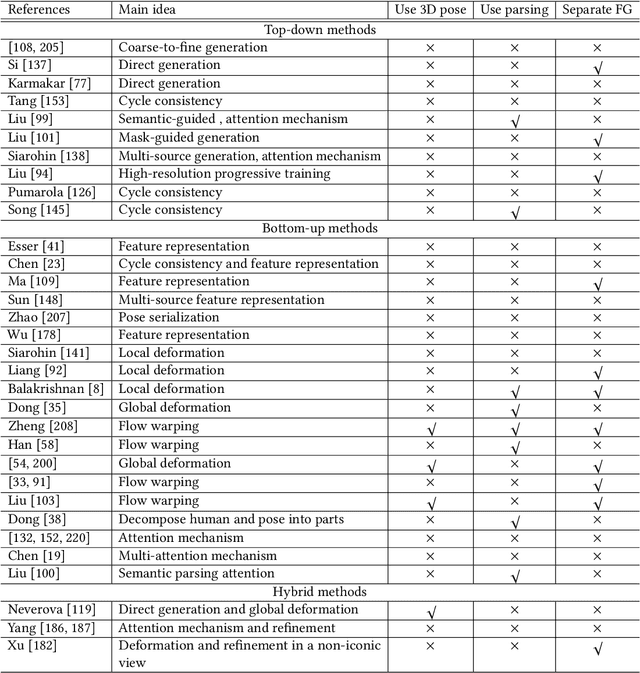
Deep person generation has attracted extensive research attention due to its wide applications in virtual agents, video conferencing, online shopping and art/movie production. With the advancement of deep learning, visual appearances (face, pose, cloth) of a person image can be easily generated or manipulated on demand. In this survey, we first summarize the scope of person generation, and then systematically review recent progress and technical trends in deep person generation, covering three major tasks: talking-head generation (face), pose-guided person generation (pose) and garment-oriented person generation (cloth). More than two hundred papers are covered for a thorough overview, and the milestone works are highlighted to witness the major technical breakthrough. Based on these fundamental tasks, a number of applications are investigated, e.g., virtual fitting, digital human, generative data augmentation. We hope this survey could shed some light on the future prospects of deep person generation, and provide a helpful foundation for full applications towards digital human.
Memory-Augmented Non-Local Attention for Video Super-Resolution
Aug 25, 2021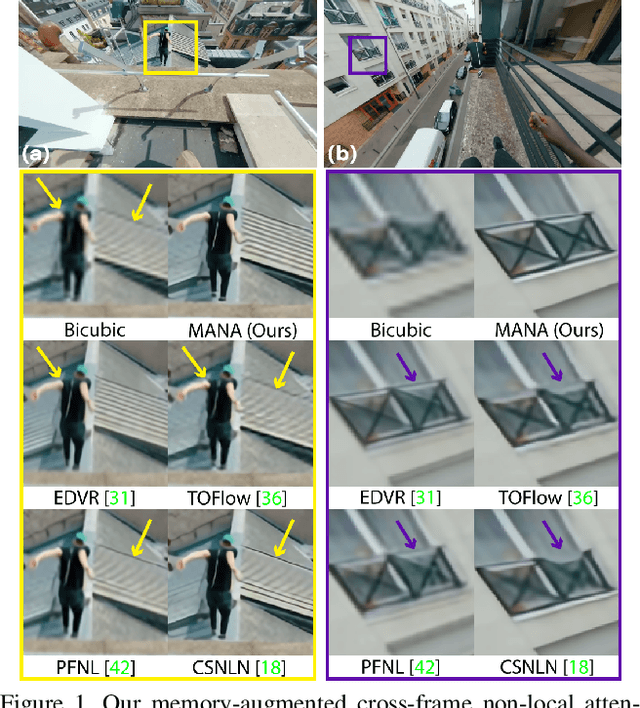
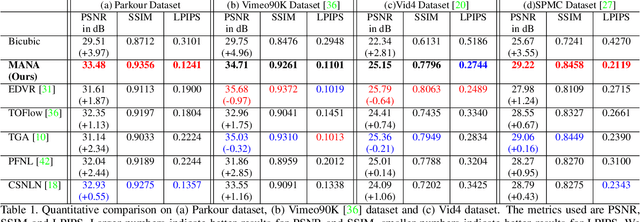
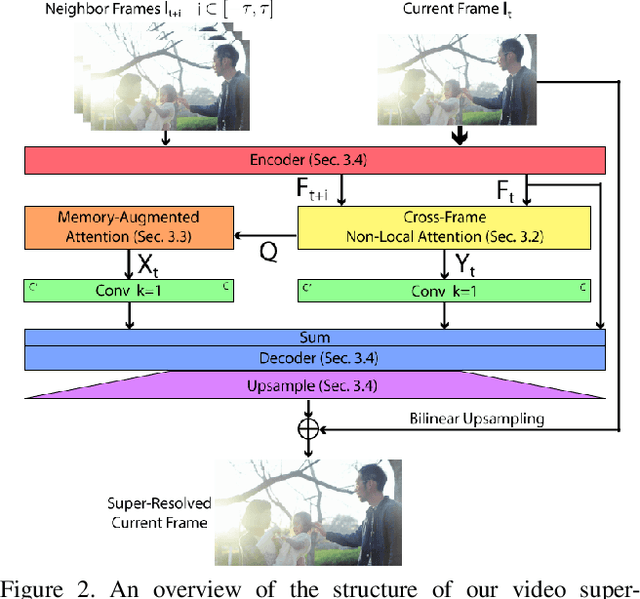
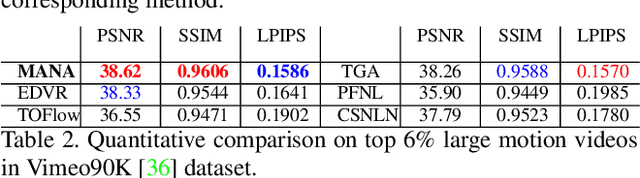
In this paper, we propose a novel video super-resolution method that aims at generating high-fidelity high-resolution (HR) videos from low-resolution (LR) ones. Previous methods predominantly leverage temporal neighbor frames to assist the super-resolution of the current frame. Those methods achieve limited performance as they suffer from the challenge in spatial frame alignment and the lack of useful information from similar LR neighbor frames. In contrast, we devise a cross-frame non-local attention mechanism that allows video super-resolution without frame alignment, leading to be more robust to large motions in the video. In addition, to acquire the information beyond neighbor frames, we design a novel memory-augmented attention module to memorize general video details during the super-resolution training. Experimental results indicate that our method can achieve superior performance on large motion videos comparing to the state-of-the-art methods without aligning frames. Our source code will be released.
X-modaler: A Versatile and High-performance Codebase for Cross-modal Analytics
Aug 18, 2021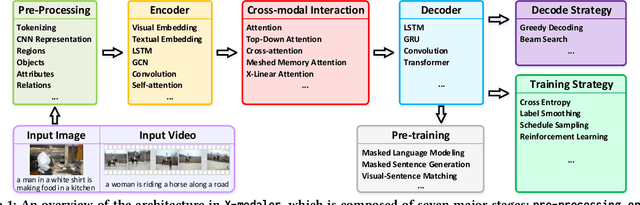
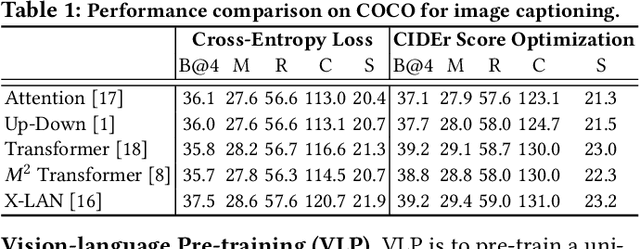
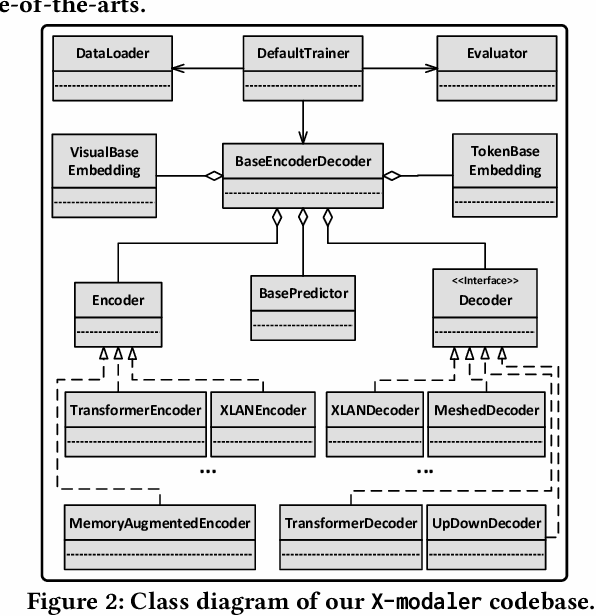
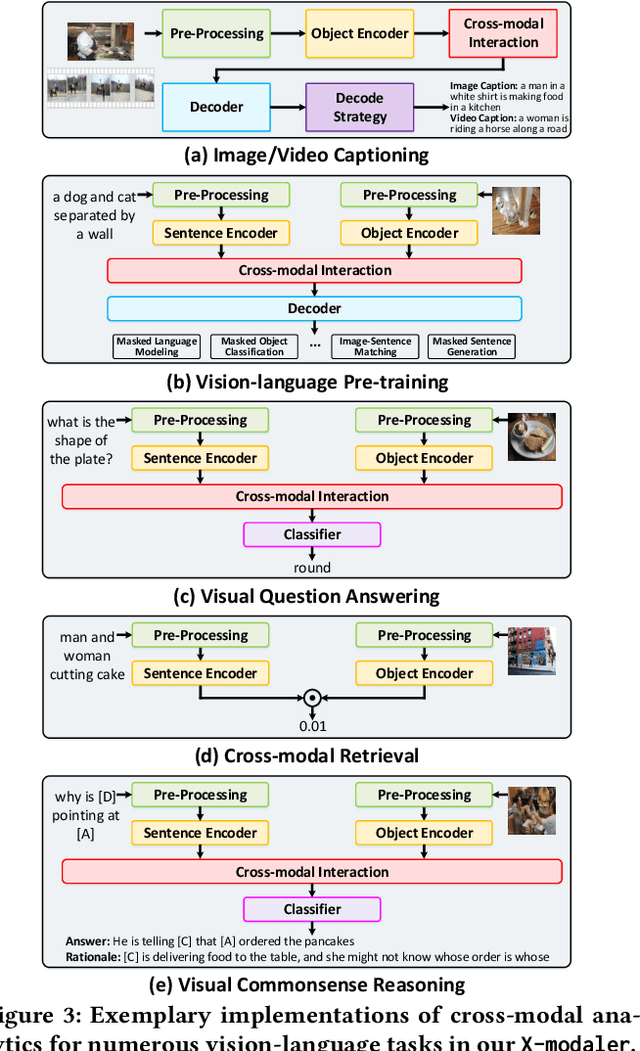
With the rise and development of deep learning over the past decade, there has been a steady momentum of innovation and breakthroughs that convincingly push the state-of-the-art of cross-modal analytics between vision and language in multimedia field. Nevertheless, there has not been an open-source codebase in support of training and deploying numerous neural network models for cross-modal analytics in a unified and modular fashion. In this work, we propose X-modaler -- a versatile and high-performance codebase that encapsulates the state-of-the-art cross-modal analytics into several general-purpose stages (e.g., pre-processing, encoder, cross-modal interaction, decoder, and decode strategy). Each stage is empowered with the functionality that covers a series of modules widely adopted in state-of-the-arts and allows seamless switching in between. This way naturally enables a flexible implementation of state-of-the-art algorithms for image captioning, video captioning, and vision-language pre-training, aiming to facilitate the rapid development of research community. Meanwhile, since the effective modular designs in several stages (e.g., cross-modal interaction) are shared across different vision-language tasks, X-modaler can be simply extended to power startup prototypes for other tasks in cross-modal analytics, including visual question answering, visual commonsense reasoning, and cross-modal retrieval. X-modaler is an Apache-licensed codebase, and its source codes, sample projects and pre-trained models are available on-line: https://github.com/YehLi/xmodaler.
A Low Rank Promoting Prior for Unsupervised Contrastive Learning
Aug 05, 2021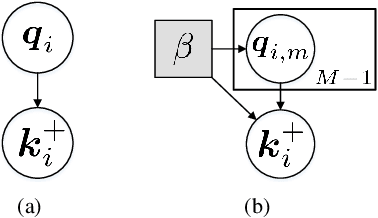
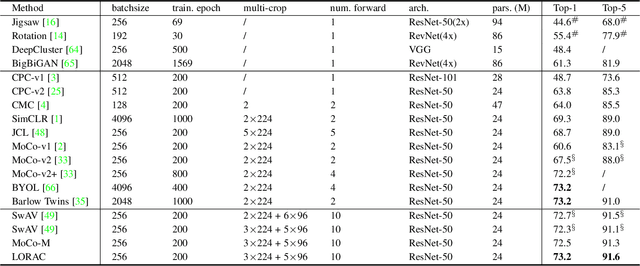
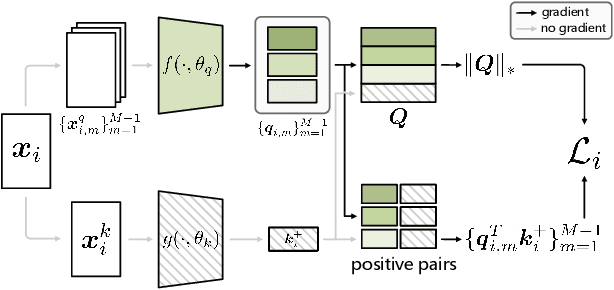

Unsupervised learning is just at a tipping point where it could really take off. Among these approaches, contrastive learning has seen tremendous progress and led to state-of-the-art performance. In this paper, we construct a novel probabilistic graphical model that effectively incorporates the low rank promoting prior into the framework of contrastive learning, referred to as LORAC. In contrast to the existing conventional self-supervised approaches that only considers independent learning, our hypothesis explicitly requires that all the samples belonging to the same instance class lie on the same subspace with small dimension. This heuristic poses particular joint learning constraints to reduce the degree of freedom of the problem during the search of the optimal network parameterization. Most importantly, we argue that the low rank prior employed here is not unique, and many different priors can be invoked in a similar probabilistic way, corresponding to different hypotheses about underlying truth behind the contrastive features. Empirical evidences show that the proposed algorithm clearly surpasses the state-of-the-art approaches on multiple benchmarks, including image classification, object detection, instance segmentation and keypoint detection.
Contextual Transformer Networks for Visual Recognition
Jul 26, 2021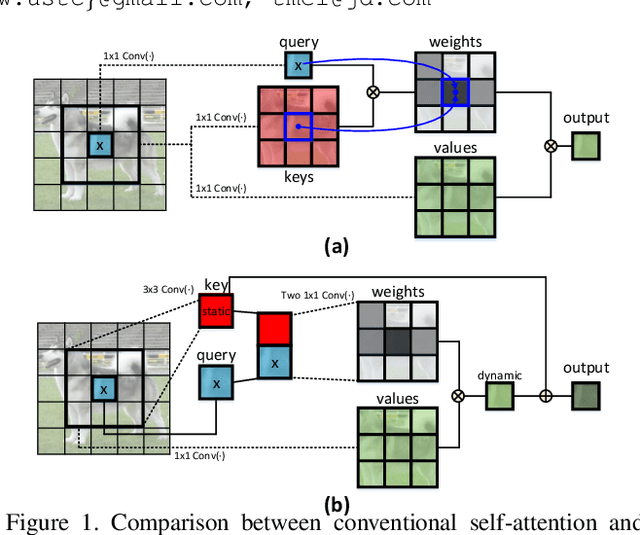
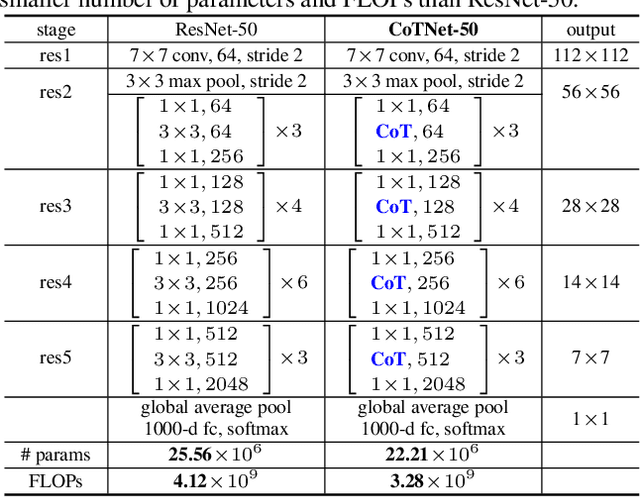
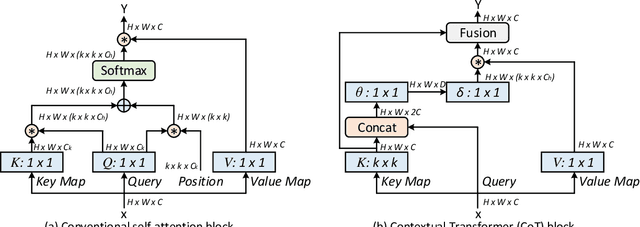
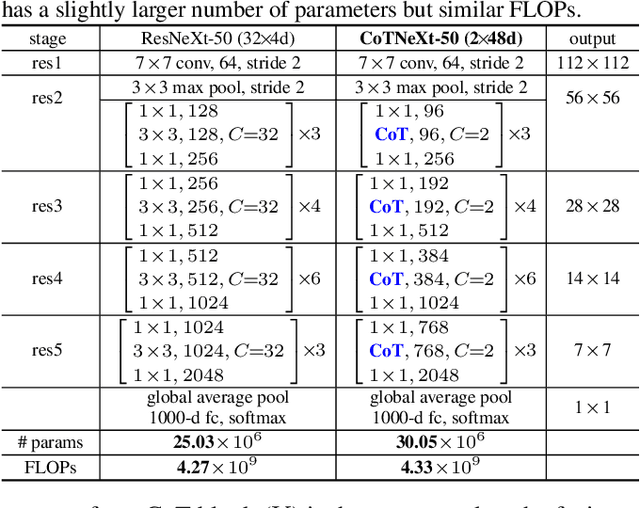
Transformer with self-attention has led to the revolutionizing of natural language processing field, and recently inspires the emergence of Transformer-style architecture design with competitive results in numerous computer vision tasks. Nevertheless, most of existing designs directly employ self-attention over a 2D feature map to obtain the attention matrix based on pairs of isolated queries and keys at each spatial location, but leave the rich contexts among neighbor keys under-exploited. In this work, we design a novel Transformer-style module, i.e., Contextual Transformer (CoT) block, for visual recognition. Such design fully capitalizes on the contextual information among input keys to guide the learning of dynamic attention matrix and thus strengthens the capacity of visual representation. Technically, CoT block first contextually encodes input keys via a $3\times3$ convolution, leading to a static contextual representation of inputs. We further concatenate the encoded keys with input queries to learn the dynamic multi-head attention matrix through two consecutive $1\times1$ convolutions. The learnt attention matrix is multiplied by input values to achieve the dynamic contextual representation of inputs. The fusion of the static and dynamic contextual representations are finally taken as outputs. Our CoT block is appealing in the view that it can readily replace each $3\times3$ convolution in ResNet architectures, yielding a Transformer-style backbone named as Contextual Transformer Networks (CoTNet). Through extensive experiments over a wide range of applications (e.g., image recognition, object detection and instance segmentation), we validate the superiority of CoTNet as a stronger backbone. Source code is available at \url{https://github.com/JDAI-CV/CoTNet}.
Augmentation Pathways Network for Visual Recognition
Jul 26, 2021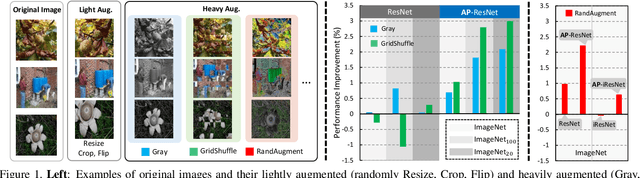

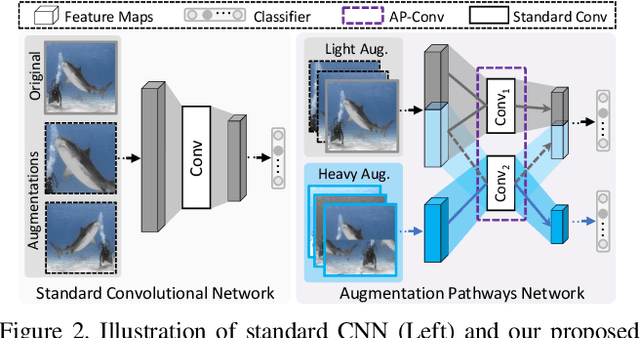
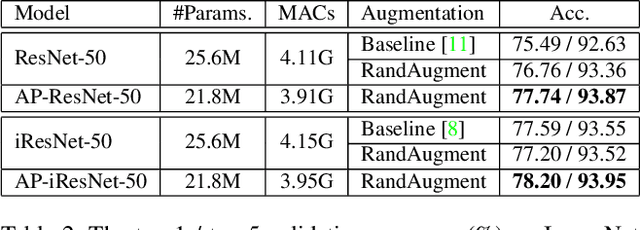
Data augmentation is practically helpful for visual recognition, especially at the time of data scarcity. However, such success is only limited to quite a few light augmentations (e.g., random crop, flip). Heavy augmentations (e.g., gray, grid shuffle) are either unstable or show adverse effects during training, owing to the big gap between the original and augmented images. This paper introduces a novel network design, noted as Augmentation Pathways (AP), to systematically stabilize training on a much wider range of augmentation policies. Notably, AP tames heavy data augmentations and stably boosts performance without a careful selection among augmentation policies. Unlike traditional single pathway, augmented images are processed in different neural paths. The main pathway handles light augmentations, while other pathways focus on heavy augmentations. By interacting with multiple paths in a dependent manner, the backbone network robustly learns from shared visual patterns among augmentations, and suppresses noisy patterns at the same time. Furthermore, we extend AP to a homogeneous version and a heterogeneous version for high-order scenarios, demonstrating its robustness and flexibility in practical usage. Experimental results on ImageNet benchmarks demonstrate the compatibility and effectiveness on a much wider range of augmentations (e.g., Crop, Gray, Grid Shuffle, RandAugment), while consuming fewer parameters and lower computational costs at inference time. Source code:https://github.com/ap-conv/ap-net.
FasterPose: A Faster Simple Baseline for Human Pose Estimation
Jul 07, 2021
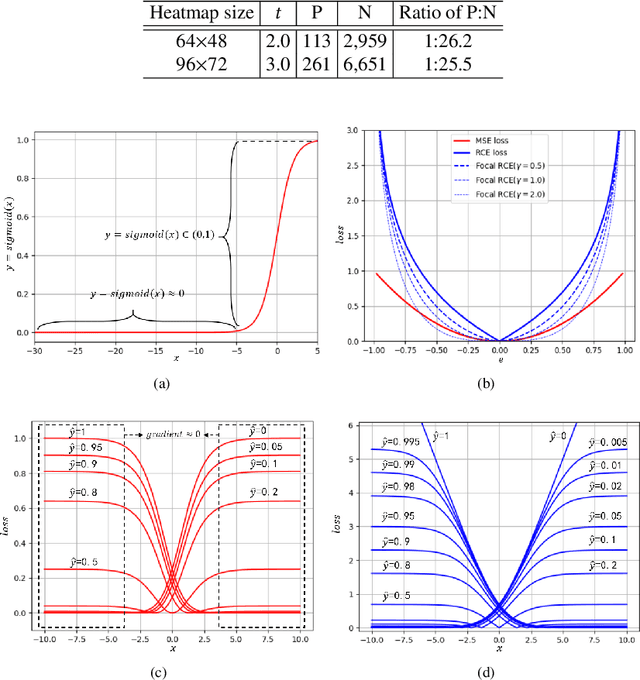
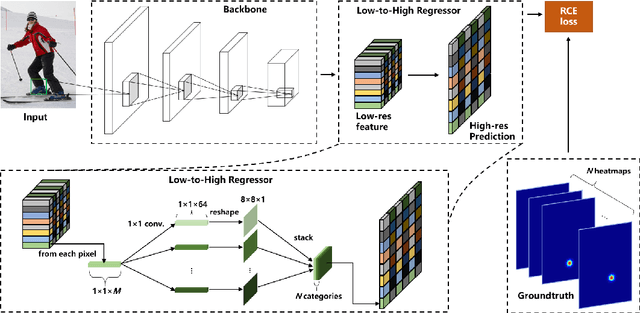
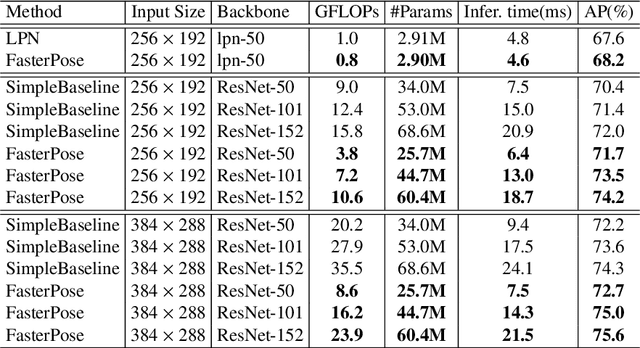
The performance of human pose estimation depends on the spatial accuracy of keypoint localization. Most existing methods pursue the spatial accuracy through learning the high-resolution (HR) representation from input images. By the experimental analysis, we find that the HR representation leads to a sharp increase of computational cost, while the accuracy improvement remains marginal compared with the low-resolution (LR) representation. In this paper, we propose a design paradigm for cost-effective network with LR representation for efficient pose estimation, named FasterPose. Whereas the LR design largely shrinks the model complexity, yet how to effectively train the network with respect to the spatial accuracy is a concomitant challenge. We study the training behavior of FasterPose, and formulate a novel regressive cross-entropy (RCE) loss function for accelerating the convergence and promoting the accuracy. The RCE loss generalizes the ordinary cross-entropy loss from the binary supervision to a continuous range, thus the training of pose estimation network is able to benefit from the sigmoid function. By doing so, the output heatmap can be inferred from the LR features without loss of spatial accuracy, while the computational cost and model size has been significantly reduced. Compared with the previously dominant network of pose estimation, our method reduces 58% of the FLOPs and simultaneously gains 1.3% improvement of accuracy. Extensive experiments show that FasterPose yields promising results on the common benchmarks, i.e., COCO and MPII, consistently validating the effectiveness and efficiency for practical utilization, especially the low-latency and low-energy-budget applications in the non-GPU scenarios.
Boosting Semi-Supervised Face Recognition with Noise Robustness
May 10, 2021
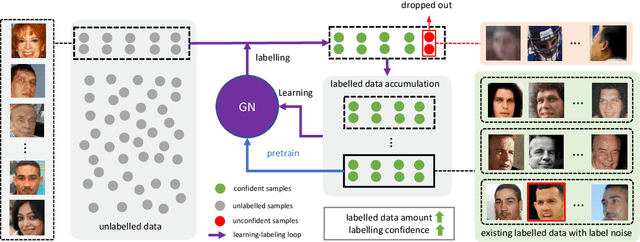


Although deep face recognition benefits significantly from large-scale training data, a current bottleneck is the labelling cost. A feasible solution to this problem is semi-supervised learning, exploiting a small portion of labelled data and large amounts of unlabelled data. The major challenge, however, is the accumulated label errors through auto-labelling, compromising the training. This paper presents an effective solution to semi-supervised face recognition that is robust to the label noise aroused by the auto-labelling. Specifically, we introduce a multi-agent method, named GroupNet (GN), to endow our solution with the ability to identify the wrongly labelled samples and preserve the clean samples. We show that GN alone achieves the leading accuracy in traditional supervised face recognition even when the noisy labels take over 50\% of the training data. Further, we develop a semi-supervised face recognition solution, named Noise Robust Learning-Labelling (NRoLL), which is based on the robust training ability empowered by GN. It starts with a small amount of labelled data and consequently conducts high-confidence labelling on a large amount of unlabelled data to boost further training. The more data is labelled by NRoLL, the higher confidence is with the label in the dataset. To evaluate the competitiveness of our method, we run NRoLL with a rough condition that only one-fifth of the labelled MSCeleb is available and the rest is used as unlabelled data. On a wide range of benchmarks, our method compares favorably against the state-of-the-art methods.
Multi-Agent Semi-Siamese Training for Long-tail and Shallow Face Learning
May 10, 2021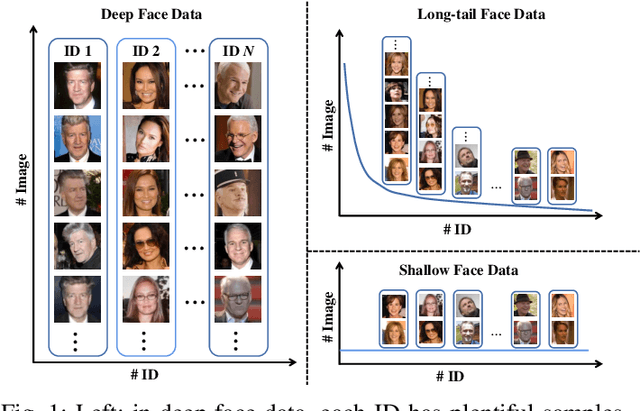
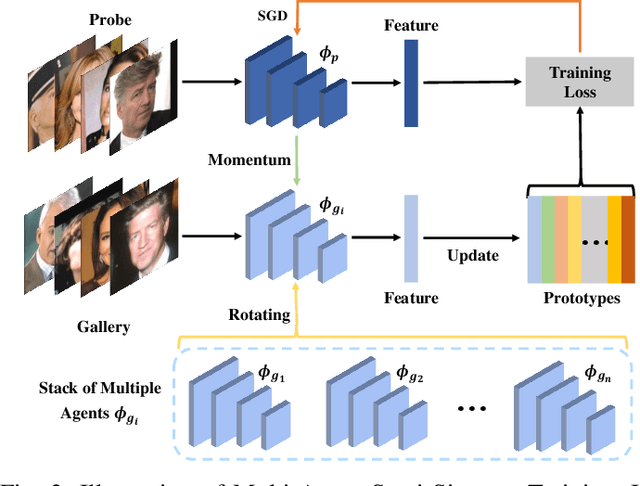
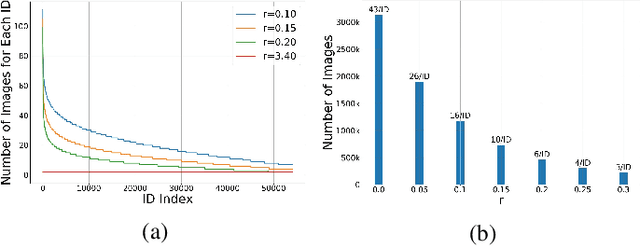
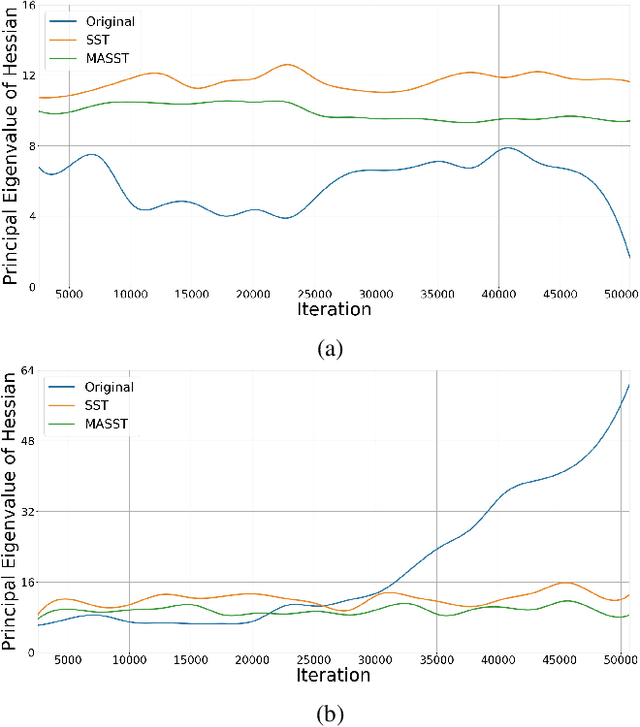
With the recent development of deep convolutional neural networks and large-scale datasets, deep face recognition has made remarkable progress and been widely used in various applications. However, unlike the existing public face datasets, in many real-world scenarios of face recognition, the depth of training dataset is shallow, which means only two face images are available for each ID. With the non-uniform increase of samples, such issue is converted to a more general case, a.k.a long-tail face learning, which suffers from data imbalance and intra-class diversity dearth simultaneously. These adverse conditions damage the training and result in the decline of model performance. Based on the Semi-Siamese Training (SST), we introduce an advanced solution, named Multi-Agent Semi-Siamese Training (MASST), to address these problems. MASST includes a probe network and multiple gallery agents, the former aims to encode the probe features, and the latter constitutes a stack of networks that encode the prototypes (gallery features). For each training iteration, the gallery network, which is sequentially rotated from the stack, and the probe network form a pair of semi-siamese networks. We give theoretical and empirical analysis that, given the long-tail (or shallow) data and training loss, MASST smooths the loss landscape and satisfies the Lipschitz continuity with the help of multiple agents and the updating gallery queue. The proposed method is out of extra-dependency, thus can be easily integrated with the existing loss functions and network architectures. It is worth noting that, although multiple gallery agents are employed for training, only the probe network is needed for inference, without increasing the inference cost. Extensive experiments and comparisons demonstrate the advantages of MASST for long-tail and shallow face learning.
Action Unit Memory Network for Weakly Supervised Temporal Action Localization
Apr 29, 2021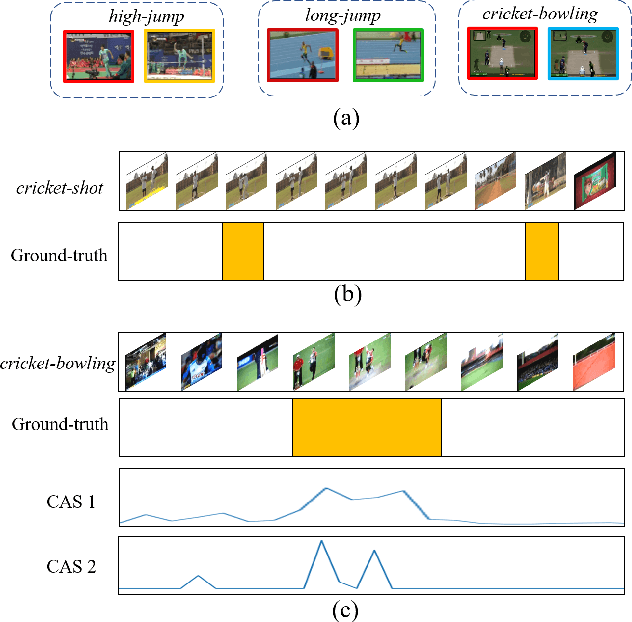
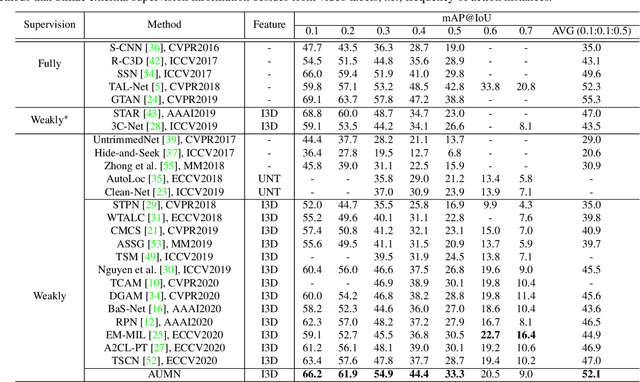
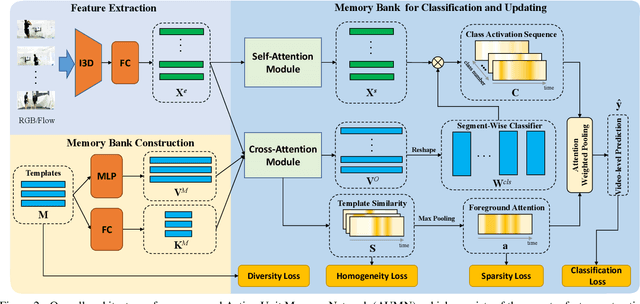
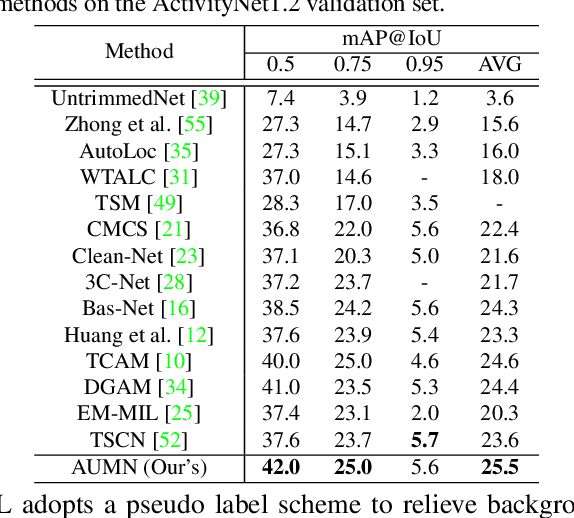
Weakly supervised temporal action localization aims to detect and localize actions in untrimmed videos with only video-level labels during training. However, without frame-level annotations, it is challenging to achieve localization completeness and relieve background interference. In this paper, we present an Action Unit Memory Network (AUMN) for weakly supervised temporal action localization, which can mitigate the above two challenges by learning an action unit memory bank. In the proposed AUMN, two attention modules are designed to update the memory bank adaptively and learn action units specific classifiers. Furthermore, three effective mechanisms (diversity, homogeneity and sparsity) are designed to guide the updating of the memory network. To the best of our knowledge, this is the first work to explicitly model the action units with a memory network. Extensive experimental results on two standard benchmarks (THUMOS14 and ActivityNet) demonstrate that our AUMN performs favorably against state-of-the-art methods. Specifically, the average mAP of IoU thresholds from 0.1 to 0.5 on the THUMOS14 dataset is significantly improved from 47.0% to 52.1%.