 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBagpiper: Solving Open-Ended Audio Tasks via Rich Captions
Feb 05, 2026Current audio foundation models typically rely on rigid, task-specific supervision, addressing isolated factors of audio rather than the whole. In contrast, human intelligence processes audio holistically, seamlessly bridging physical signals with abstract cognitive concepts to execute complex tasks. Grounded in this philosophy, we introduce Bagpiper, an 8B audio foundation model that interprets physical audio via rich captions, i.e., comprehensive natural language descriptions that encapsulate the critical cognitive concepts inherent in the signal (e.g., transcription, audio events). By pre-training on a massive corpus of 600B tokens, the model establishes a robust bidirectional mapping between raw audio and this high-level conceptual space. During fine-tuning, Bagpiper adopts a caption-then-process workflow, simulating an intermediate cognitive reasoning step to solve diverse tasks without task-specific priors. Experimentally, Bagpiper outperforms Qwen-2.5-Omni on MMAU and AIRBench for audio understanding and surpasses CosyVoice3 and TangoFlux in generation quality, capable of synthesizing arbitrary compositions of speech, music, and sound effects. To the best of our knowledge, Bagpiper is among the first works that achieve unified understanding generation for general audio. Model, data, and code are available at Bagpiper Home Page.
Evaluating Self-Supervised Speech Models via Text-Based LLMS
Oct 06, 2025Self-Supervised Learning (SSL) has gained traction for its ability to learn rich representations with low labeling costs, applicable across diverse downstream tasks. However, assessing the downstream-task performance remains challenging due to the cost of extra training and evaluation. Existing methods for task-agnostic evaluation also require extra training or hyperparameter tuning. We propose a novel evaluation metric using large language models (LLMs). By inputting discrete token sequences and minimal domain cues derived from SSL models into LLMs, we obtain the mean log-likelihood; these cues guide in-context learning, rendering the score more reliable without extra training or hyperparameter tuning. Experimental results show a correlation between LLM-based scores and automatic speech recognition task. Additionally, our findings reveal that LLMs not only functions as an SSL evaluation tools but also provides inference-time embeddings that are useful for speaker verification task.
ESPnet-SpeechLM: An Open Speech Language Model Toolkit
Feb 21, 2025



We present ESPnet-SpeechLM, an open toolkit designed to democratize the development of speech language models (SpeechLMs) and voice-driven agentic applications. The toolkit standardizes speech processing tasks by framing them as universal sequential modeling problems, encompassing a cohesive workflow of data preprocessing, pre-training, inference, and task evaluation. With ESPnet-SpeechLM, users can easily define task templates and configure key settings, enabling seamless and streamlined SpeechLM development. The toolkit ensures flexibility, efficiency, and scalability by offering highly configurable modules for every stage of the workflow. To illustrate its capabilities, we provide multiple use cases demonstrating how competitive SpeechLMs can be constructed with ESPnet-SpeechLM, including a 1.7B-parameter model pre-trained on both text and speech tasks, across diverse benchmarks. The toolkit and its recipes are fully transparent and reproducible at: https://github.com/espnet/espnet/tree/speechlm.
LV-CTC: Non-autoregressive ASR with CTC and latent variable models
Mar 28, 2024Non-autoregressive (NAR) models for automatic speech recognition (ASR) aim to achieve high accuracy and fast inference by simplifying the autoregressive (AR) generation process of conventional models. Connectionist temporal classification (CTC) is one of the key techniques used in NAR ASR models. In this paper, we propose a new model combining CTC and a latent variable model, which is one of the state-of-the-art models in the neural machine translation research field. A new neural network architecture and formulation specialized for ASR application are introduced. In the proposed model, CTC alignment is assumed to be dependent on the latent variables that are expected to capture dependencies between tokens. Experimental results on a 100 hours subset of Librispeech corpus showed the best recognition accuracy among CTC-based NAR models. On the TED-LIUM2 corpus, the best recognition accuracy is achieved including AR E2E models with faster inference speed.
HuBERTopic: Enhancing Semantic Representation of HuBERT through Self-supervision Utilizing Topic Model
Oct 06, 2023Recently, the usefulness of self-supervised representation learning (SSRL) methods has been confirmed in various downstream tasks. Many of these models, as exemplified by HuBERT and WavLM, use pseudo-labels generated from spectral features or the model's own representation features. From previous studies, it is known that the pseudo-labels contain semantic information. However, the masked prediction task, the learning criterion of HuBERT, focuses on local contextual information and may not make effective use of global semantic information such as speaker, theme of speech, and so on. In this paper, we propose a new approach to enrich the semantic representation of HuBERT. We apply topic model to pseudo-labels to generate a topic label for each utterance. An auxiliary topic classification task is added to HuBERT by using topic labels as teachers. This allows additional global semantic information to be incorporated in an unsupervised manner. Experimental results demonstrate that our method achieves comparable or better performance than the baseline in most tasks, including automatic speech recognition and five out of the eight SUPERB tasks. Moreover, we find that topic labels include various information about utterance, such as gender, speaker, and its theme. This highlights the effectiveness of our approach in capturing multifaceted semantic nuances.
Exploring Speech Recognition, Translation, and Understanding with Discrete Speech Units: A Comparative Study
Sep 27, 2023



Speech signals, typically sampled at rates in the tens of thousands per second, contain redundancies, evoking inefficiencies in sequence modeling. High-dimensional speech features such as spectrograms are often used as the input for the subsequent model. However, they can still be redundant. Recent investigations proposed the use of discrete speech units derived from self-supervised learning representations, which significantly compresses the size of speech data. Applying various methods, such as de-duplication and subword modeling, can further compress the speech sequence length. Hence, training time is significantly reduced while retaining notable performance. In this study, we undertake a comprehensive and systematic exploration into the application of discrete units within end-to-end speech processing models. Experiments on 12 automatic speech recognition, 3 speech translation, and 1 spoken language understanding corpora demonstrate that discrete units achieve reasonably good results in almost all the settings. We intend to release our configurations and trained models to foster future research efforts.
Exploration of Efficient End-to-End ASR using Discretized Input from Self-Supervised Learning
May 29, 2023



Self-supervised learning (SSL) of speech has shown impressive results in speech-related tasks, particularly in automatic speech recognition (ASR). While most methods employ the output of intermediate layers of the SSL model as real-valued features for downstream tasks, there is potential in exploring alternative approaches that use discretized token sequences. This approach offers benefits such as lower storage requirements and the ability to apply techniques from natural language processing. In this paper, we propose a new protocol that utilizes discretized token sequences in ASR tasks, which includes de-duplication and sub-word modeling to enhance the input sequence. It reduces computational cost by decreasing the length of the sequence. Our experiments on the LibriSpeech dataset demonstrate that our proposed protocol performs competitively with conventional ASR systems using continuous input features, while reducing computational and storage costs.
End-to-End Integration of Speech Recognition, Speech Enhancement, and Self-Supervised Learning Representation
Apr 01, 2022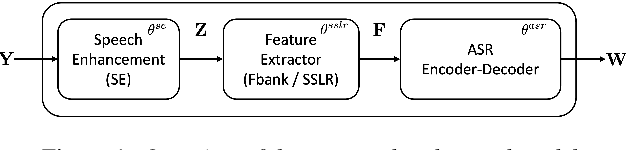
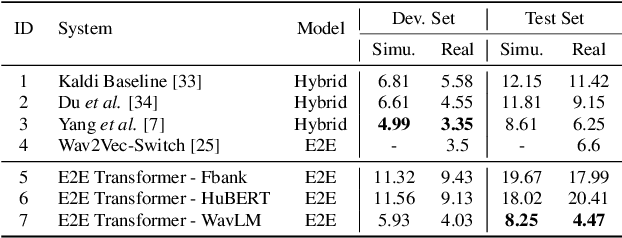
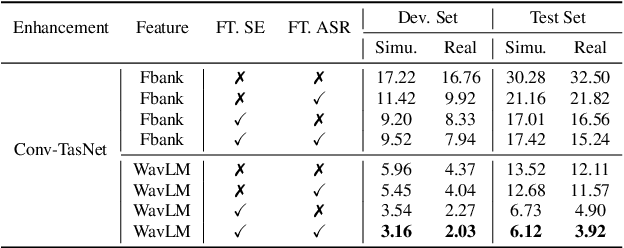
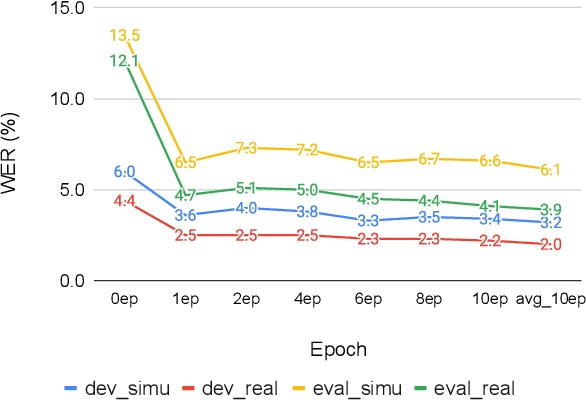
This work presents our end-to-end (E2E) automatic speech recognition (ASR) model targetting at robust speech recognition, called Integraded speech Recognition with enhanced speech Input for Self-supervised learning representation (IRIS). Compared with conventional E2E ASR models, the proposed E2E model integrates two important modules including a speech enhancement (SE) module and a self-supervised learning representation (SSLR) module. The SE module enhances the noisy speech. Then the SSLR module extracts features from enhanced speech to be used for speech recognition (ASR). To train the proposed model, we establish an efficient learning scheme. Evaluation results on the monaural CHiME-4 task show that the IRIS model achieves the best performance reported in the literature for the single-channel CHiME-4 benchmark (2.0% for the real development and 3.9% for the real test) thanks to the powerful pre-trained SSLR module and the fine-tuned SE module.
An Exploration of Self-Supervised Pretrained Representations for End-to-End Speech Recognition
Oct 09, 2021
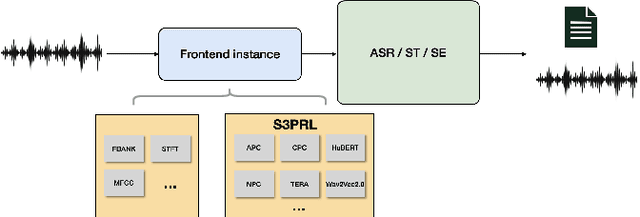
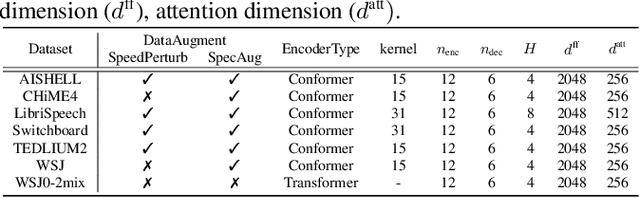
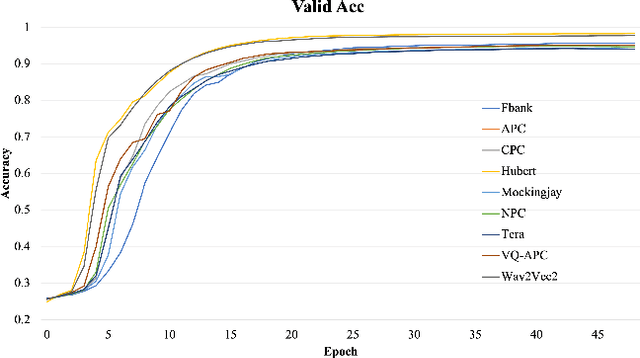
Self-supervised pretraining on speech data has achieved a lot of progress. High-fidelity representation of the speech signal is learned from a lot of untranscribed data and shows promising performance. Recently, there are several works focusing on evaluating the quality of self-supervised pretrained representations on various tasks without domain restriction, e.g. SUPERB. However, such evaluations do not provide a comprehensive comparison among many ASR benchmark corpora. In this paper, we focus on the general applications of pretrained speech representations, on advanced end-to-end automatic speech recognition (E2E-ASR) models. We select several pretrained speech representations and present the experimental results on various open-source and publicly available corpora for E2E-ASR. Without any modification of the back-end model architectures or training strategy, some of the experiments with pretrained representations, e.g., WSJ, WSJ0-2mix with HuBERT, reach or outperform current state-of-the-art (SOTA) recognition performance. Moreover, we further explore more scenarios for whether the pretraining representations are effective, such as the cross-language or overlapped speech. The scripts, configuratons and the trained models have been released in ESPnet to let the community reproduce our experiments and improve them.
Speech Representation Learning Combining Conformer CPC with Deep Cluster for the ZeroSpeech Challenge 2021
Jul 13, 2021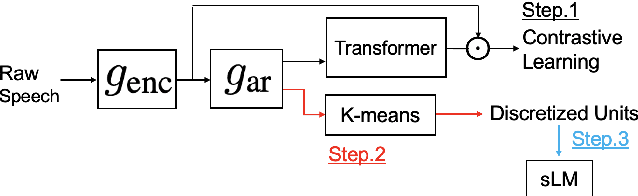

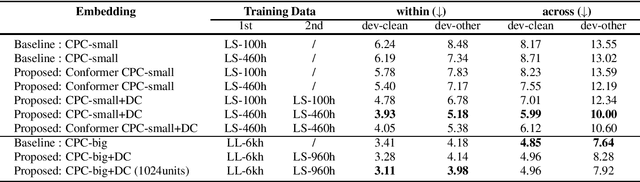

We present a system for the Zero Resource Speech Challenge 2021, which combines a Contrastive Predictive Coding (CPC) with deep cluster. In deep cluster, we first prepare pseudo-labels obtained by clustering the outputs of a CPC network with k-means. Then, we train an additional autoregressive model to classify the previously obtained pseudo-labels in a supervised manner. Phoneme discriminative representation is achieved by executing the second-round clustering with the outputs of the final layer of the autoregressive model. We show that replacing a Transformer layer with a Conformer layer leads to a further gain in a lexical metric. Experimental results show that a relative improvement of 35% in a phonetic metric, 1.5% in the lexical metric, and 2.3% in a syntactic metric are achieved compared to a baseline method of CPC-small which is trained on LibriSpeech 460h data. We achieve top results in this challenge with the syntactic metric.