 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Adaptive Policy Selection for Multi-Task Imitation Learning through Task Division
Mar 28, 2022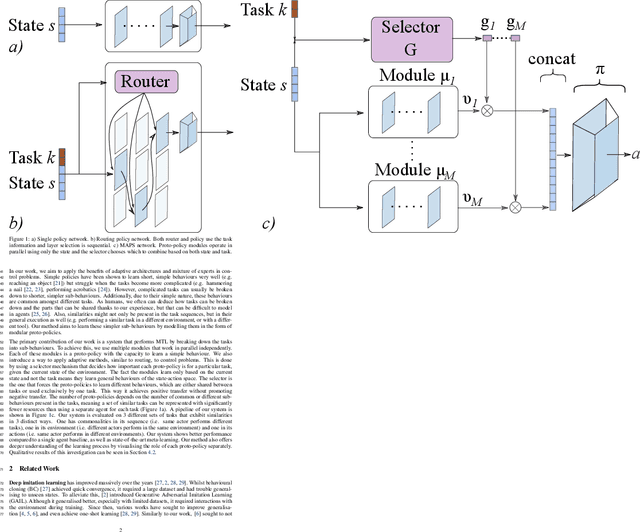

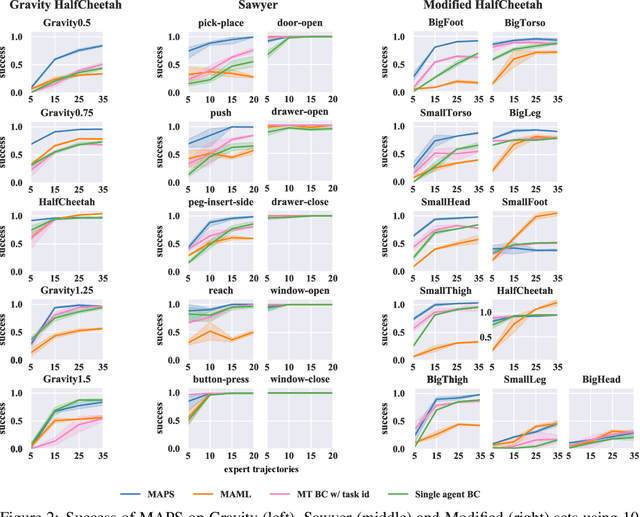
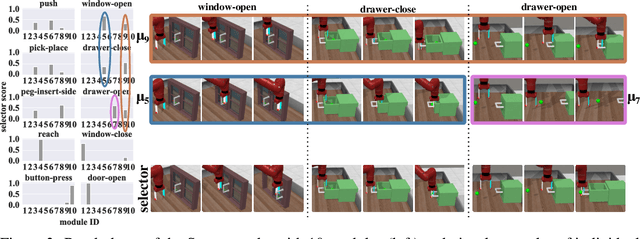
Deep imitation learning requires many expert demonstrations, which can be hard to obtain, especially when many tasks are involved. However, different tasks often share similarities, so learning them jointly can greatly benefit them and alleviate the need for many demonstrations. But, joint multi-task learning often suffers from negative transfer, sharing information that should be task-specific. In this work, we introduce a method to perform multi-task imitation while allowing for task-specific features. This is done by using proto-policies as modules to divide the tasks into simple sub-behaviours that can be shared. The proto-policies operate in parallel and are adaptively chosen by a selector mechanism that is jointly trained with the modules. Experiments on different sets of tasks show that our method improves upon the accuracy of single agents, task-conditioned and multi-headed multi-task agents, as well as state-of-the-art meta learning agents. We also demonstrate its ability to autonomously divide the tasks into both shared and task-specific sub-behaviours.
A Unified Architecture of Semantic Segmentation and Hierarchical Generative Adversarial Networks for Expression Manipulation
Dec 08, 2021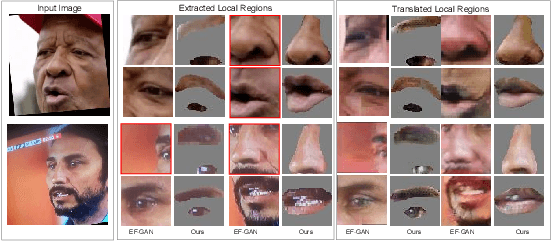
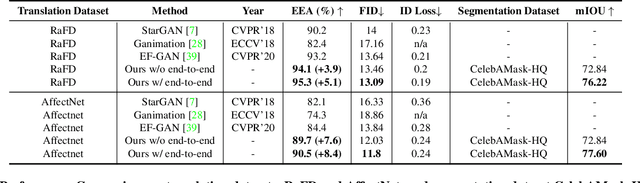
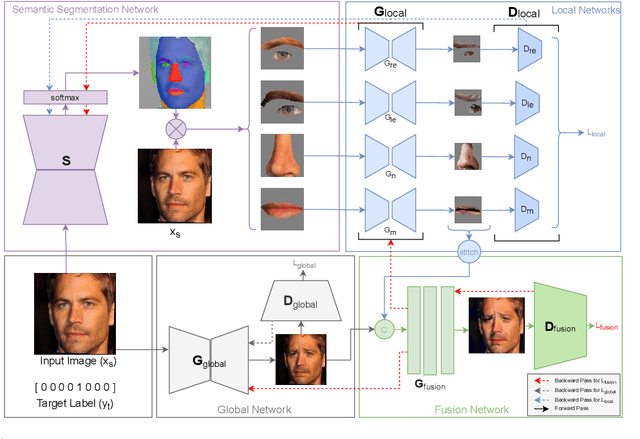
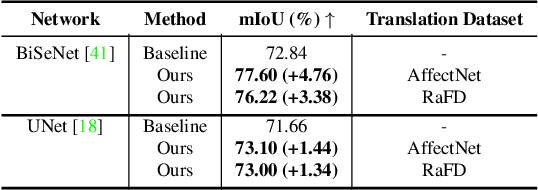
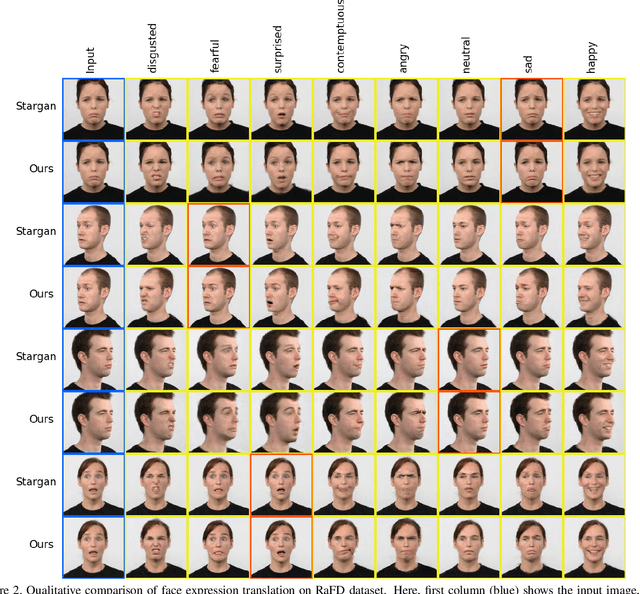
Editing facial expressions by only changing what we want is a long-standing research problem in Generative Adversarial Networks (GANs) for image manipulation. Most of the existing methods that rely only on a global generator usually suffer from changing unwanted attributes along with the target attributes. Recently, hierarchical networks that consist of both a global network dealing with the whole image and multiple local networks focusing on local parts are showing success. However, these methods extract local regions by bounding boxes centred around the sparse facial key points which are non-differentiable, inaccurate and unrealistic. Hence, the solution becomes sub-optimal, introduces unwanted artefacts degrading the overall quality of the synthetic images. Moreover, a recent study has shown strong correlation between facial attributes and local semantic regions. To exploit this relationship, we designed a unified architecture of semantic segmentation and hierarchical GANs. A unique advantage of our framework is that on forward pass the semantic segmentation network conditions the generative model, and on backward pass gradients from hierarchical GANs are propagated to the semantic segmentation network, which makes our framework an end-to-end differentiable architecture. This allows both architectures to benefit from each other. To demonstrate its advantages, we evaluate our method on two challenging facial expression translation benchmarks, AffectNet and RaFD, and a semantic segmentation benchmark, CelebAMask-HQ across two popular architectures, BiSeNet and UNet. Our extensive quantitative and qualitative evaluations on both face semantic segmentation and face expression manipulation tasks validate the effectiveness of our work over existing state-of-the-art methods.
SeCGAN: Parallel Conditional Generative Adversarial Networks for Face Editing via Semantic Consistency
Nov 24, 2021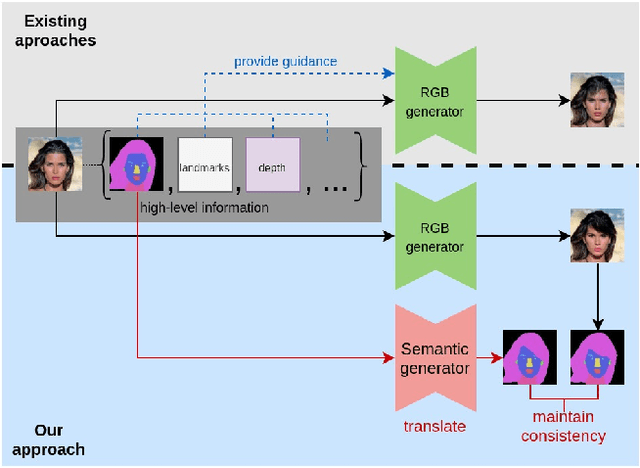
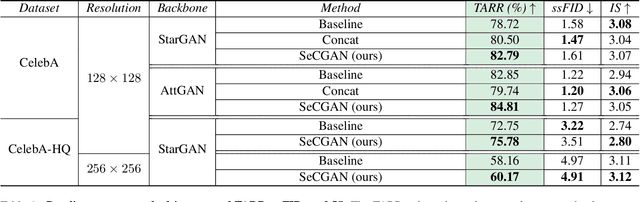
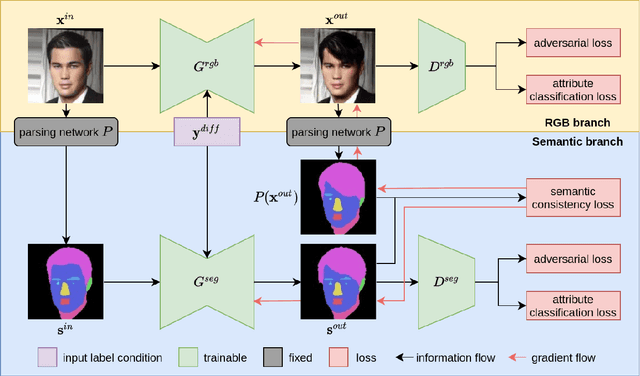
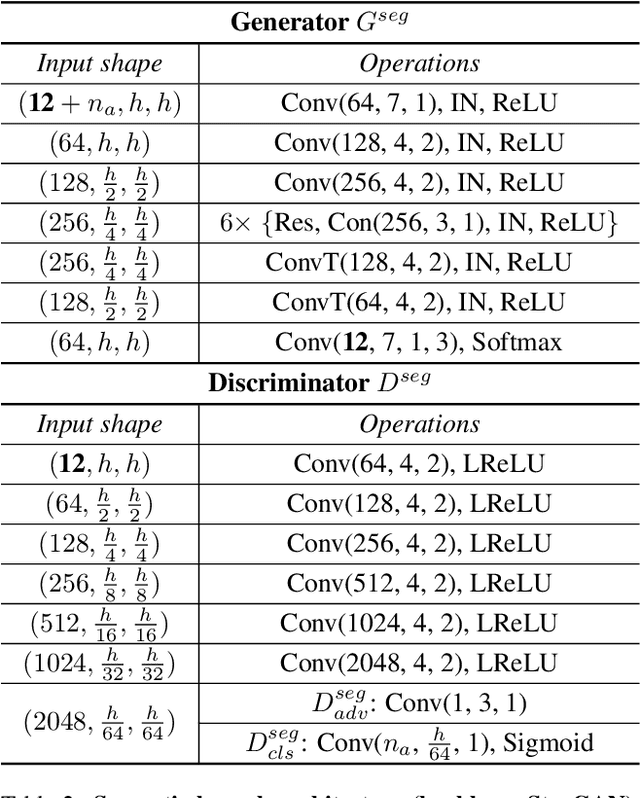
Semantically guided conditional Generative Adversarial Networks (cGANs) have become a popular approach for face editing in recent years. However, most existing methods introduce semantic masks as direct conditional inputs to the generator and often require the target masks to perform the corresponding translation in the RGB space. We propose SeCGAN, a novel label-guided cGAN for editing face images utilising semantic information without the need to specify target semantic masks. During training, SeCGAN has two branches of generators and discriminators operating in parallel, with one trained to translate RGB images and the other for semantic masks. To bridge the two branches in a mutually beneficial manner, we introduce a semantic consistency loss which constrains both branches to have consistent semantic outputs. Whilst both branches are required during training, the RGB branch is our primary network and the semantic branch is not needed for inference. Our results on CelebA and CelebA-HQ demonstrate that our approach is able to generate facial images with more accurate attributes, outperforming competitive baselines in terms of Target Attribute Recognition Rate whilst maintaining quality metrics such as self-supervised Fr\'{e}chet Inception Distance and Inception Score.
EvDistill: Asynchronous Events to End-task Learning via Bidirectional Reconstruction-guided Cross-modal Knowledge Distillation
Nov 24, 2021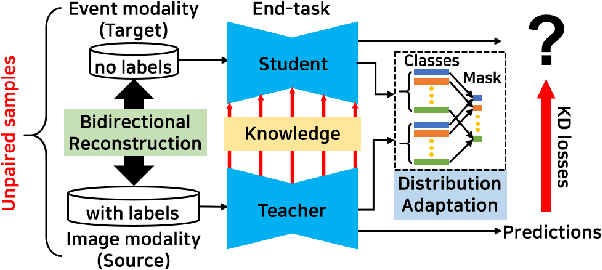
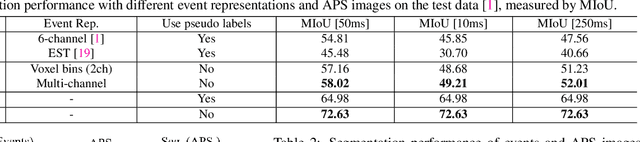
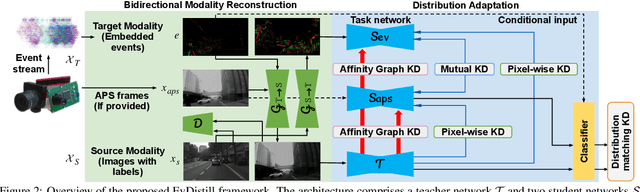

Event cameras sense per-pixel intensity changes and produce asynchronous event streams with high dynamic range and less motion blur, showing advantages over conventional cameras. A hurdle of training event-based models is the lack of large qualitative labeled data. Prior works learning end-tasks mostly rely on labeled or pseudo-labeled datasets obtained from the active pixel sensor (APS) frames; however, such datasets' quality is far from rivaling those based on the canonical images. In this paper, we propose a novel approach, called \textbf{EvDistill}, to learn a student network on the unlabeled and unpaired event data (target modality) via knowledge distillation (KD) from a teacher network trained with large-scale, labeled image data (source modality). To enable KD across the unpaired modalities, we first propose a bidirectional modality reconstruction (BMR) module to bridge both modalities and simultaneously exploit them to distill knowledge via the crafted pairs, causing no extra computation in the inference. The BMR is improved by the end-tasks and KD losses in an end-to-end manner. Second, we leverage the structural similarities of both modalities and adapt the knowledge by matching their distributions. Moreover, as most prior feature KD methods are uni-modality and less applicable to our problem, we propose to leverage an affinity graph KD loss to boost the distillation. Our extensive experiments on semantic segmentation and object recognition demonstrate that EvDistill achieves significantly better results than the prior works and KD with only events and APS frames.
Visual Transformer for Task-aware Active Learning
Jun 07, 2021

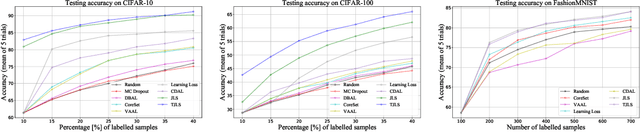

Pool-based sampling in active learning (AL) represents a key framework for an-notating informative data when dealing with deep learning models. In this paper, we present a novel pipeline for pool-based Active Learning. Unlike most previous works, our method exploits accessible unlabelled examples during training to estimate their co-relation with the labelled examples. Another contribution of this paper is to adapt Visual Transformer as a sampler in the AL pipeline. Visual Transformer models non-local visual concept dependency between labelled and unlabelled examples, which is crucial to identifying the influencing unlabelled examples. Also, compared to existing methods where the learner and the sampler are trained in a multi-stage manner, we propose to train them in a task-aware jointly manner which enables transforming the latent space into two separate tasks: one that classifies the labelled examples; the other that distinguishes the labelling direction. We evaluated our work on four different challenging benchmarks of classification and detection tasks viz. CIFAR10, CIFAR100,FashionMNIST, RaFD, and Pascal VOC 2007. Our extensive empirical and qualitative evaluations demonstrate the superiority of our method compared to the existing methods. Code available: https://github.com/razvancaramalau/Visual-Transformer-for-Task-aware-Active-Learning
SHAQ: Incorporating Shapley Value Theory into Q-Learning for Multi-Agent Reinforcement Learning
May 31, 2021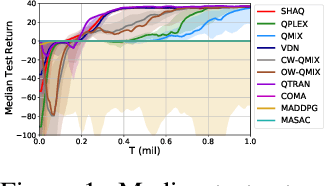

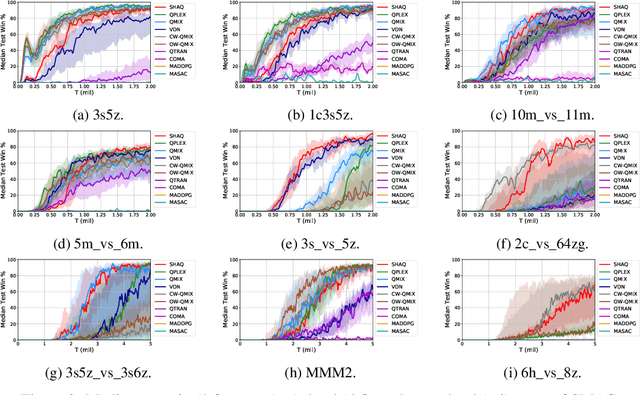
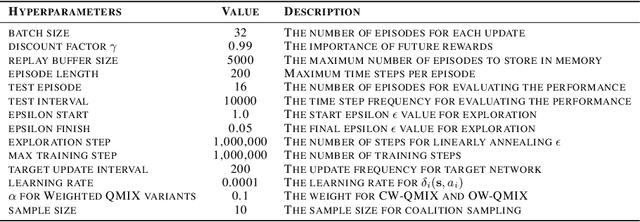
Value factorisation proves to be a very useful technique in multi-agent reinforcement learning (MARL), but the underlying mechanism is not yet fully understood. This paper explores a theoretic basis for value factorisation. We generalise the Shapley value in the coalitional game theory to a Markov convex game (MCG) and use it to guide value factorisation in MARL. We show that the generalised Shapley value possesses several features such as (1) accurate estimation of the maximum global value, (2) fairness in the factorisation of the global value, and (3) being sensitive to dummy agents. The proposed theory yields a new learning algorithm called Sharpley Q-learning (SHAQ), which inherits the important merits of ordinary Q-learning but extends it to MARL. In comparison with prior-arts, SHAQ has a much weaker assumption (MCG) that is more compatible with real-world problems, but has superior explainability and performance in many cases. We demonstrated SHAQ and verified the theoretic claims on Predator-Prey and StarCraft Multi-Agent Challenge (SMAC).
Label Geometry Aware Discriminator for Conditional Generative Networks
May 12, 2021
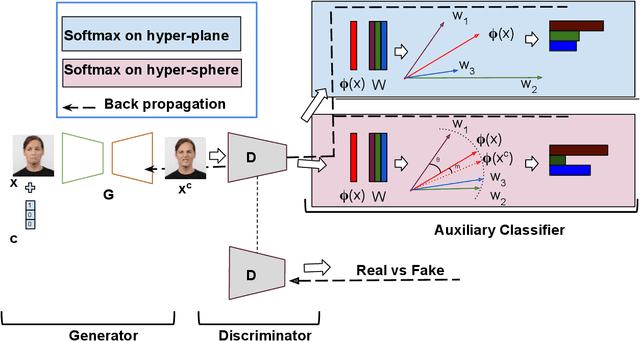
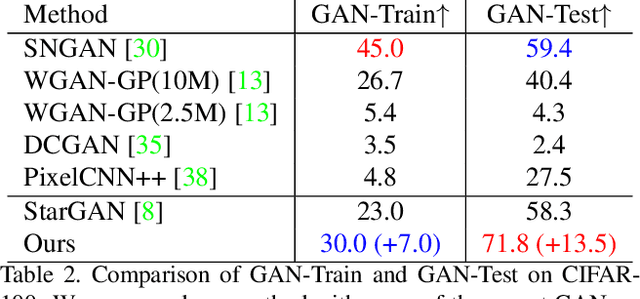
Multi-domain image-to-image translation with conditional Generative Adversarial Networks (GANs) can generate highly photo realistic images with desired target classes, yet these synthetic images have not always been helpful to improve downstream supervised tasks such as image classification. Improving downstream tasks with synthetic examples requires generating images with high fidelity to the unknown conditional distribution of the target class, which many labeled conditional GANs attempt to achieve by adding soft-max cross-entropy loss based auxiliary classifier in the discriminator. As recent studies suggest that the soft-max loss in Euclidean space of deep feature does not leverage their intrinsic angular distribution, we propose to replace this loss in auxiliary classifier with an additive angular margin (AAM) loss that takes benefit of the intrinsic angular distribution, and promotes intra-class compactness and inter-class separation to help generator synthesize high fidelity images. We validate our method on RaFD and CIFAR-100, two challenging face expression and natural image classification data set. Our method outperforms state-of-the-art methods in several different evaluation criteria including recently proposed GAN-train and GAN-test metrics designed to assess the impact of synthetic data on downstream classification task, assessing the usefulness in data augmentation for supervised tasks with prediction accuracy score and average confidence score, and the well known FID metric.
Learning Feature Aggregation for Deep 3D Morphable Models
May 05, 2021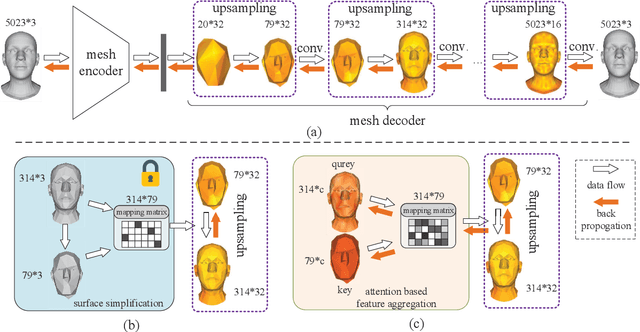

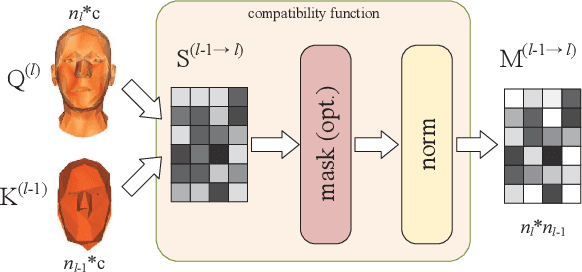
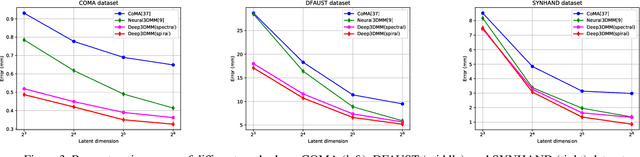
3D morphable models are widely used for the shape representation of an object class in computer vision and graphics applications. In this work, we focus on deep 3D morphable models that directly apply deep learning on 3D mesh data with a hierarchical structure to capture information at multiple scales. While great efforts have been made to design the convolution operator, how to best aggregate vertex features across hierarchical levels deserves further attention. In contrast to resorting to mesh decimation, we propose an attention based module to learn mapping matrices for better feature aggregation across hierarchical levels. Specifically, the mapping matrices are generated by a compatibility function of the keys and queries. The keys and queries are trainable variables, learned by optimizing the target objective, and shared by all data samples of the same object class. Our proposed module can be used as a train-only drop-in replacement for the feature aggregation in existing architectures for both downsampling and upsampling. Our experiments show that through the end-to-end training of the mapping matrices, we achieve state-of-the-art results on a variety of 3D shape datasets in comparison to existing morphable models.
Geometry-based Distance Decomposition for Monocular 3D Object Detection
Apr 08, 2021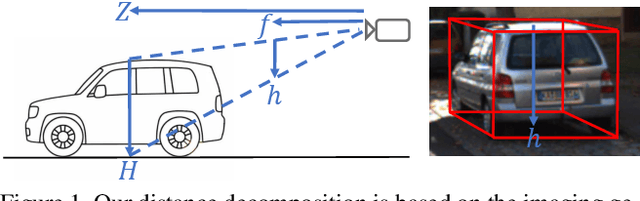
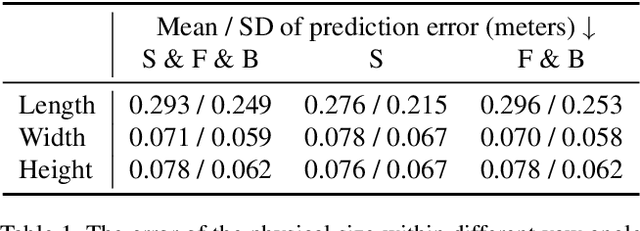

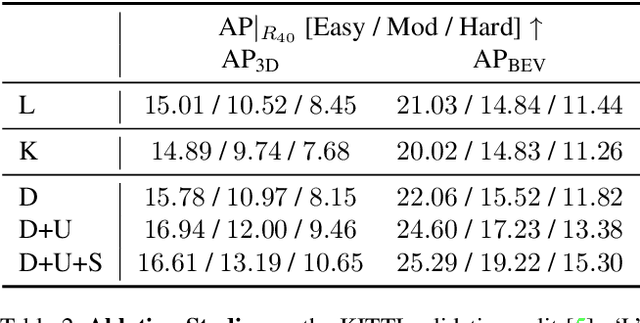
Monocular 3D object detection is of great significance for autonomous driving but remains challenging. The core challenge is to predict the distance of objects in the absence of explicit depth information. Unlike regressing the distance as a single variable in most existing methods, we propose a novel geometry-based distance decomposition to recover the distance by its factors. The decomposition factors the distance of objects into the most representative and stable variables, i.e. the physical height and the projected visual height in the image plane. Moreover, the decomposition maintains the self-consistency between the two heights, leading to the robust distance prediction when both predicted heights are inaccurate. The decomposition also enables us to trace the cause of the distance uncertainty for different scenarios. Such decomposition makes the distance prediction interpretable, accurate, and robust. Our method directly predicts 3D bounding boxes from RGB images with a compact architecture, making the training and inference simple and efficient. The experimental results show that our method achieves the state-of-the-art performance on the monocular 3D Object detection and Birds Eye View tasks on the KITTI dataset, and can generalize to images with different camera intrinsics.
Adversarial Imitation Learning with Trajectorial Augmentation and Correction
Mar 26, 2021
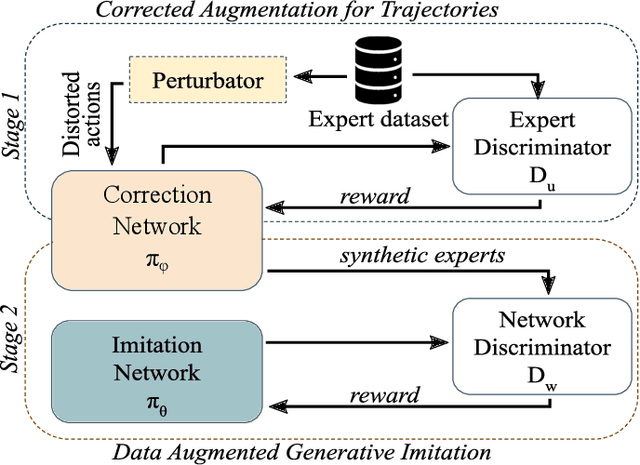
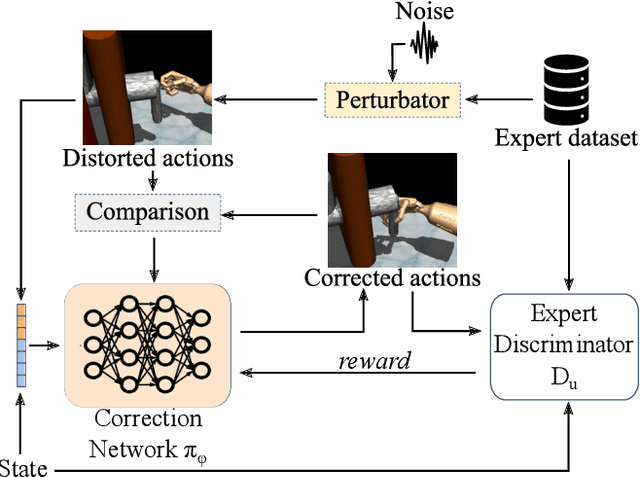
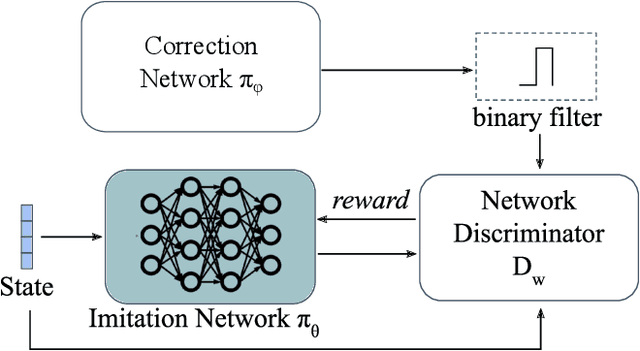
Deep Imitation Learning requires a large number of expert demonstrations, which are not always easy to obtain, especially for complex tasks. A way to overcome this shortage of labels is through data augmentation. However, this cannot be easily applied to control tasks due to the sequential nature of the problem. In this work, we introduce a novel augmentation method which preserves the success of the augmented trajectories. To achieve this, we introduce a semi-supervised correction network that aims to correct distorted expert actions. To adequately test the abilities of the correction network, we develop an adversarial data augmented imitation architecture to train an imitation agent using synthetic experts. Additionally, we introduce a metric to measure diversity in trajectory datasets. Experiments show that our data augmentation strategy can improve accuracy and convergence time of adversarial imitation while preserving the diversity between the generated and real trajectories.