 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapley Machine: A Game-Theoretic Framework for N-Agent Ad Hoc Teamwork
Jun 12, 2025Open multi-agent systems are increasingly important in modeling real-world applications, such as smart grids, swarm robotics, etc. In this paper, we aim to investigate a recently proposed problem for open multi-agent systems, referred to as n-agent ad hoc teamwork (NAHT), where only a number of agents are controlled. Existing methods tend to be based on heuristic design and consequently lack theoretical rigor and ambiguous credit assignment among agents. To address these limitations, we model and solve NAHT through the lens of cooperative game theory. More specifically, we first model an open multi-agent system, characterized by its value, as an instance situated in a space of cooperative games, generated by a set of basis games. We then extend this space, along with the state space, to accommodate dynamic scenarios, thereby characterizing NAHT. Exploiting the justifiable assumption that basis game values correspond to a sequence of n-step returns with different horizons, we represent the state values for NAHT in a form similar to $\lambda$-returns. Furthermore, we derive Shapley values to allocate state values to the controlled agents, as credits for their contributions to the ad hoc team. Different from the conventional approach to shaping Shapley values in an explicit form, we shape Shapley values by fulfilling the three axioms uniquely describing them, well defined on the extended game space describing NAHT. To estimate Shapley values in dynamic scenarios, we propose a TD($\lambda$)-like algorithm. The resulting reinforcement learning (RL) algorithm is referred to as Shapley Machine. To our best knowledge, this is the first time that the concepts from cooperative game theory are directly related to RL concepts. In experiments, we demonstrate the effectiveness of Shapley Machine and verify reasonableness of our theory.
Preference Alignment on Diffusion Model: A Comprehensive Survey for Image Generation and Editing
Feb 10, 2025


The integration of preference alignment with diffusion models (DMs) has emerged as a transformative approach to enhance image generation and editing capabilities. Although integrating diffusion models with preference alignment strategies poses significant challenges for novices at this intersection, comprehensive and systematic reviews of this subject are still notably lacking. To bridge this gap, this paper extensively surveys preference alignment with diffusion models in image generation and editing. First, we systematically review cutting-edge optimization techniques such as reinforcement learning with human feedback (RLHF), direct preference optimization (DPO), and others, highlighting their pivotal role in aligning preferences with DMs. Then, we thoroughly explore the applications of aligning preferences with DMs in autonomous driving, medical imaging, robotics, and more. Finally, we comprehensively discuss the challenges of preference alignment with DMs. To our knowledge, this is the first survey centered on preference alignment with DMs, providing insights to drive future innovation in this dynamic area.
Attaining Human`s Desirable Outcomes in Human-AI Interaction via Structural Causal Games
May 26, 2024



In human-AI interaction, a prominent goal is to attain human`s desirable outcome with the assistance of AI agents, which can be ideally delineated as a problem of seeking the optimal Nash Equilibrium that matches the human`s desirable outcome. However, reaching the outcome is usually challenging due to the existence of multiple Nash Equilibria that are related to the assisting task but do not correspond to the human`s desirable outcome. To tackle this issue, we employ a theoretical framework called structural causal game (SCG) to formalize the human-AI interactive process. Furthermore, we introduce a strategy referred to as pre-policy intervention on the SCG to steer AI agents towards attaining the human`s desirable outcome. In more detail, a pre-policy is learned as a generalized intervention to guide the agents` policy selection, under a transparent and interpretable procedure determined by the SCG. To make the framework practical, we propose a reinforcement learning-like algorithm to search out this pre-policy. The proposed algorithm is tested in both gridworld environments and realistic dialogue scenarios with large language models, demonstrating its adaptability in a broader class of problems and potential effectiveness in real-world situations.
Tiny Refinements Elicit Resilience: Toward Efficient Prefix-Model Against LLM Red-Teaming
May 21, 2024



With the proliferation of red-teaming strategies for Large Language Models (LLMs), the deficiency in the literature about improving the safety and robustness of LLM defense strategies is becoming increasingly pronounced. This paper introduces the LLM-based \textbf{sentinel} model as a plug-and-play prefix module designed to reconstruct the input prompt with just a few ($<30$) additional tokens, effectively reducing toxicity in responses from target LLMs. The sentinel model naturally overcomes the \textit{parameter inefficiency} and \textit{limited model accessibility} for fine-tuning large target models. We employ an interleaved training regimen using Proximal Policy Optimization (PPO) to optimize both red team and sentinel models dynamically, incorporating a value head-sharing mechanism inspired by the multi-agent centralized critic to manage the complex interplay between agents. Our extensive experiments across text-to-text and text-to-image demonstrate the effectiveness of our approach in mitigating toxic outputs, even when dealing with larger models like \texttt{Llama-2}, \texttt{GPT-3.5} and \texttt{Stable-Diffusion}, highlighting the potential of our framework in enhancing safety and robustness in various applications.
Shapley Value Based Multi-Agent Reinforcement Learning: Theory, Method and Its Application to Energy Network
Feb 23, 2024Multi-agent reinforcement learning is an area of rapid advancement in artificial intelligence and machine learning. One of the important questions to be answered is how to conduct credit assignment in a multi-agent system. There have been many schemes designed to conduct credit assignment by multi-agent reinforcement learning algorithms. Although these credit assignment schemes have been proved useful in improving the performance of multi-agent reinforcement learning, most of them are designed heuristically without a rigorous theoretic basis and therefore infeasible to understand how agents cooperate. In this thesis, we aim at investigating the foundation of credit assignment in multi-agent reinforcement learning via cooperative game theory. We first extend a game model called convex game and a payoff distribution scheme called Shapley value in cooperative game theory to Markov decision process, named as Markov convex game and Markov Shapley value respectively. We represent a global reward game as a Markov convex game under the grand coalition. As a result, Markov Shapley value can be reasonably used as a credit assignment scheme in the global reward game. Markov Shapley value possesses the following virtues: (i) efficiency; (ii) identifiability of dummy agents; (iii) reflecting the contribution and (iv) symmetry, which form the fair credit assignment. Based on Markov Shapley value, we propose three multi-agent reinforcement learning algorithms called SHAQ, SQDDPG and SMFPPO. Furthermore, we extend Markov convex game to partial observability to deal with the partially observable problems, named as partially observable Markov convex game. In application, we evaluate SQDDPG and SMFPPO on the real-world problem in energy networks.
Open Ad Hoc Teamwork with Cooperative Game Theory
Feb 23, 2024Ad hoc teamwork poses a challenging problem, requiring the design of an agent to collaborate with teammates without prior coordination or joint training. Open ad hoc teamwork further complicates this challenge by considering environments with a changing number of teammates, referred to as open teams. The state-of-the-art solution to this problem is graph-based policy learning (GPL), leveraging the generalizability of graph neural networks to handle an unrestricted number of agents and effectively address open teams. GPL's performance is superior to other methods, but its joint Q-value representation presents challenges for interpretation, hindering further development of this research line and applicability. In this paper, we establish a new theory to give an interpretation for the joint Q-value representation employed in GPL, from the perspective of cooperative game theory. Building on our theory, we propose a novel algorithm based on GPL framework, to complement the critical features that facilitate learning, but overlooked in GPL. Through experiments, we demonstrate the correctness of our theory by comparing the performance of the resulting algorithm with GPL in dynamic team compositions.
Aligning Individual and Collective Objectives in Multi-Agent Cooperation
Feb 19, 2024



In the field of multi-agent learning, the challenge of mixed-motive cooperation is pronounced, given the inherent contradictions between individual and collective goals. Current research in this domain primarily focuses on incorporating domain knowledge into rewards or introducing additional mechanisms to foster cooperation. However, many of these methods suffer from the drawbacks of manual design costs and the lack of a theoretical grounding convergence procedure to the solution. To address this gap, we approach the mixed-motive game by modeling it as a differentiable game to study learning dynamics. We introduce a novel optimization method named Altruistic Gradient Adjustment (AgA) that employs gradient adjustments to novelly align individual and collective objectives. Furthermore, we provide theoretical proof that the selection of an appropriate alignment weight in AgA can accelerate convergence towards the desired solutions while effectively avoiding the undesired ones. The visualization of learning dynamics effectively demonstrates that AgA successfully achieves alignment between individual and collective objectives. Additionally, through evaluations conducted on established mixed-motive benchmarks such as the public good game, Cleanup, Harvest, and our modified mixed-motive SMAC environment, we validate AgA's capability to facilitate altruistic and fair collaboration.
E2E-AT: A Unified Framework for Tackling Uncertainty in Task-aware End-to-end Learning
Dec 23, 2023



Successful machine learning involves a complete pipeline of data, model, and downstream applications. Instead of treating them separately, there has been a prominent increase of attention within the constrained optimization (CO) and machine learning (ML) communities towards combining prediction and optimization models. The so-called end-to-end (E2E) learning captures the task-based objective for which they will be used for decision making. Although a large variety of E2E algorithms have been presented, it has not been fully investigated how to systematically address uncertainties involved in such models. Most of the existing work considers the uncertainties of ML in the input space and improves robustness through adversarial training. We extend this idea to E2E learning and prove that there is a robustness certification procedure by solving augmented integer programming. Furthermore, we show that neglecting the uncertainty of COs during training causes a new trigger for generalization errors. To include all these components, we propose a unified framework that covers the uncertainties emerging in both the input feature space of the ML models and the COs. The framework is described as a robust optimization problem and is practically solved via end-to-end adversarial training (E2E-AT). Finally, the performance of E2E-AT is evaluated by a real-world end-to-end power system operation problem, including load forecasting and sequential scheduling tasks.
Semi-Supervised Dual-Stream Self-Attentive Adversarial Graph Contrastive Learning for Cross-Subject EEG-based Emotion Recognition
Aug 13, 2023



Electroencephalography (EEG) is an objective tool for emotion recognition with promising applications. However, the scarcity of labeled data remains a major challenge in this field, limiting the widespread use of EEG-based emotion recognition. In this paper, a semi-supervised Dual-stream Self-Attentive Adversarial Graph Contrastive learning framework (termed as DS-AGC) is proposed to tackle the challenge of limited labeled data in cross-subject EEG-based emotion recognition. The DS-AGC framework includes two parallel streams for extracting non-structural and structural EEG features. The non-structural stream incorporates a semi-supervised multi-domain adaptation method to alleviate distribution discrepancy among labeled source domain, unlabeled source domain, and unknown target domain. The structural stream develops a graph contrastive learning method to extract effective graph-based feature representation from multiple EEG channels in a semi-supervised manner. Further, a self-attentive fusion module is developed for feature fusion, sample selection, and emotion recognition, which highlights EEG features more relevant to emotions and data samples in the labeled source domain that are closer to the target domain. Extensive experiments conducted on two benchmark databases (SEED and SEED-IV) using a semi-supervised cross-subject leave-one-subject-out cross-validation evaluation scheme show that the proposed model outperforms existing methods under different incomplete label conditions (with an average improvement of 5.83% on SEED and 6.99% on SEED-IV), demonstrating its effectiveness in addressing the label scarcity problem in cross-subject EEG-based emotion recognition.
Semi-Centralised Multi-Agent Reinforcement Learning with Policy-Embedded Training
Sep 02, 2022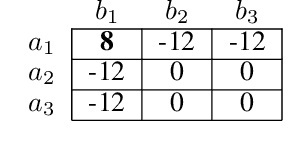
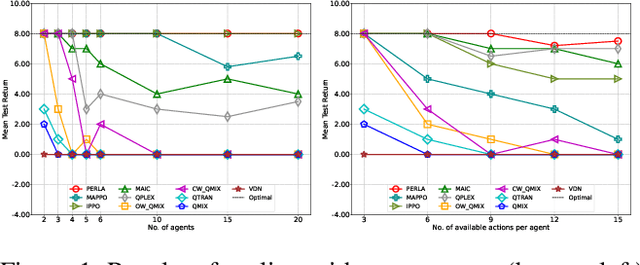
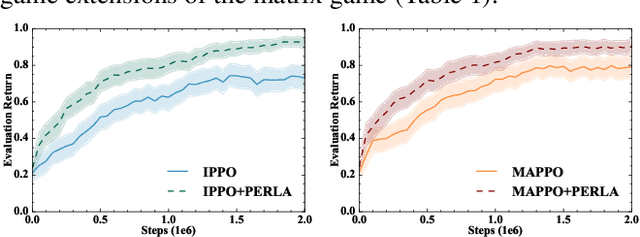
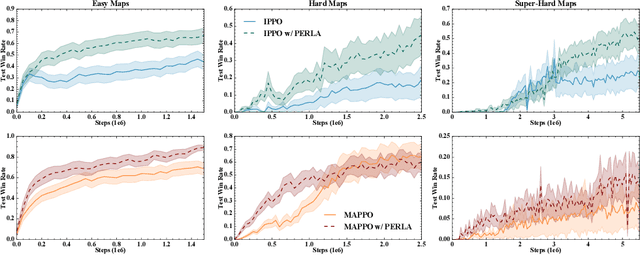
Centralised training (CT) is the basis for many popular multi-agent reinforcement learning (MARL) methods because it allows agents to quickly learn high-performing policies. However, CT relies on agents learning from one-off observations of other agents' actions at a given state. Because MARL agents explore and update their policies during training, these observations often provide poor predictions about other agents' behaviour and the expected return for a given action. CT methods therefore suffer from high variance and error-prone estimates, harming learning. CT methods also suffer from explosive growth in complexity due to the reliance on global observations, unless strong factorisation restrictions are imposed (e.g., monotonic reward functions for QMIX). We address these challenges with a new semi-centralised MARL framework that performs policy-embedded training and decentralised execution. Our method, policy embedded reinforcement learning algorithm (PERLA), is an enhancement tool for Actor-Critic MARL algorithms that leverages a novel parameter sharing protocol and policy embedding method to maintain estimates that account for other agents' behaviour. Our theory proves PERLA dramatically reduces the variance in value estimates. Unlike various CT methods, PERLA, which seamlessly adopts MARL algorithms, scales easily with the number of agents without the need for restrictive factorisation assumptions. We demonstrate PERLA's superior empirical performance and efficient scaling in benchmark environments including StarCraft Micromanagement II and Multi-agent Mujoco