 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestormer: Efficient Transformer for High-Resolution Image Restoration
Nov 18, 2021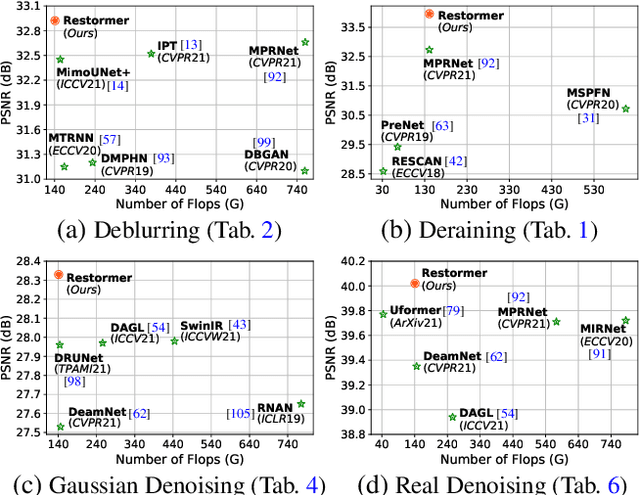
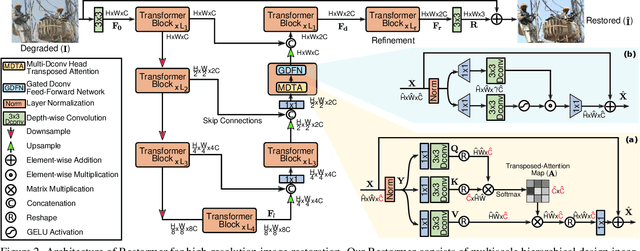
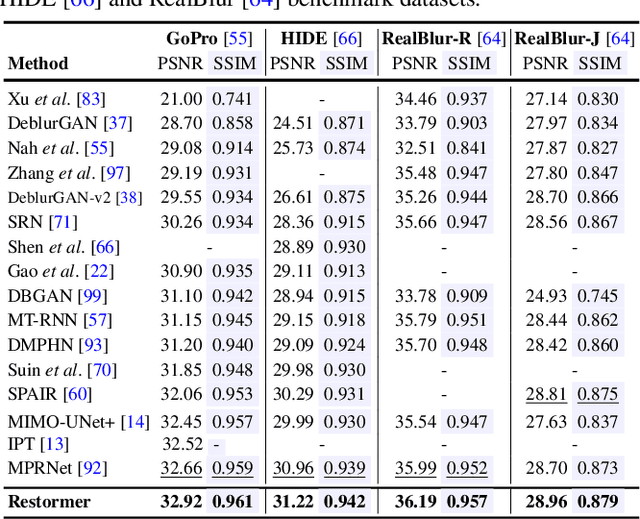
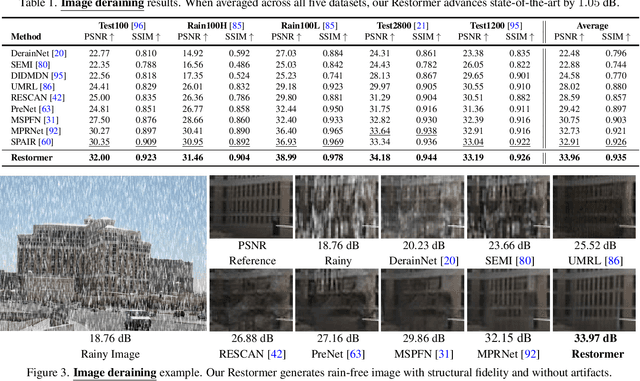
Since convolutional neural networks (CNNs) perform well at learning generalizable image priors from large-scale data, these models have been extensively applied to image restoration and related tasks. Recently, another class of neural architectures, Transformers, have shown significant performance gains on natural language and high-level vision tasks. While the Transformer model mitigates the shortcomings of CNNs (i.e., limited receptive field and inadaptability to input content), its computational complexity grows quadratically with the spatial resolution, therefore making it infeasible to apply to most image restoration tasks involving high-resolution images. In this work, we propose an efficient Transformer model by making several key designs in the building blocks (multi-head attention and feed-forward network) such that it can capture long-range pixel interactions, while still remaining applicable to large images. Our model, named Restoration Transformer (Restormer), achieves state-of-the-art results on several image restoration tasks, including image deraining, single-image motion deblurring, defocus deblurring (single-image and dual-pixel data), and image denoising (Gaussian grayscale/color denoising, and real image denoising). The source code and pre-trained models are available at https://github.com/swz30/Restormer.
Burst Image Restoration and Enhancement
Oct 07, 2021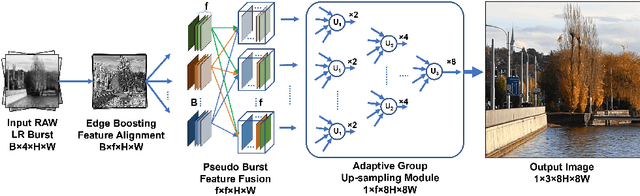
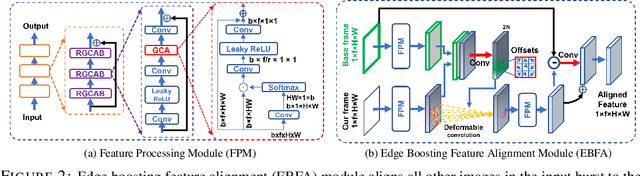
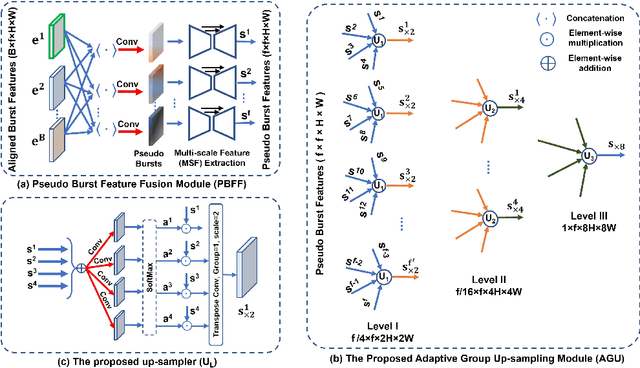
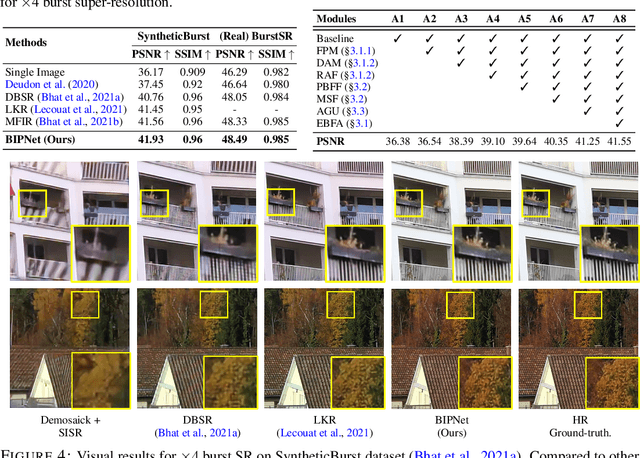
Modern handheld devices can acquire burst image sequence in a quick succession. However, the individual acquired frames suffer from multiple degradations and are misaligned due to camera shake and object motions. The goal of Burst Image Restoration is to effectively combine complimentary cues across multiple burst frames to generate high-quality outputs. Towards this goal, we develop a novel approach by solely focusing on the effective information exchange between burst frames, such that the degradations get filtered out while the actual scene details are preserved and enhanced. Our central idea is to create a set of \emph{pseudo-burst} features that combine complimentary information from all the input burst frames to seamlessly exchange information. The pseudo-burst representations encode channel-wise features from the original burst images, thus making it easier for the model to learn distinctive information offered by multiple burst frames. However, the pseudo-burst cannot be successfully created unless the individual burst frames are properly aligned to discount inter-frame movements. Therefore, our approach initially extracts preprocessed features from each burst frame and matches them using an edge-boosting burst alignment module. The pseudo-burst features are then created and enriched using multi-scale contextual information. Our final step is to adaptively aggregate information from the pseudo-burst features to progressively increase resolution in multiple stages while merging the pseudo-burst features. In comparison to existing works that usually follow a late fusion scheme with single-stage upsampling, our approach performs favorably, delivering state of the art performance on burst super-resolution and low-light image enhancement tasks. Our codes and models will be released publicly.
Multi-Stage Progressive Image Restoration
Feb 04, 2021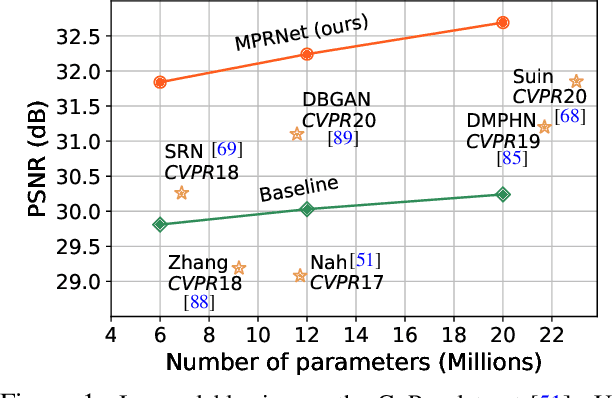

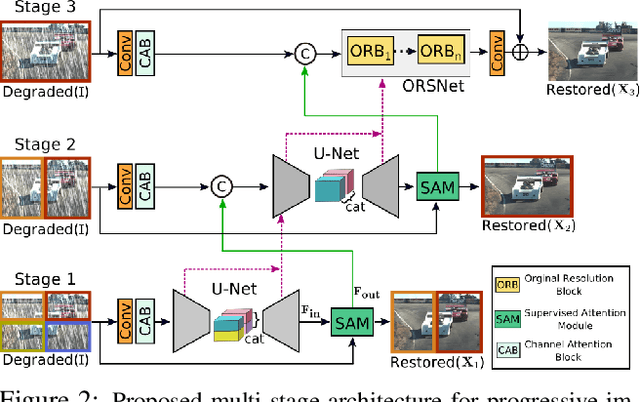
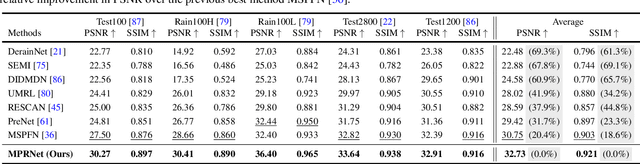
Image restoration tasks demand a complex balance between spatial details and high-level contextualized information while recovering images. In this paper, we propose a novel synergistic design that can optimally balance these competing goals. Our main proposal is a multi-stage architecture, that progressively learns restoration functions for the degraded inputs, thereby breaking down the overall recovery process into more manageable steps. Specifically, our model first learns the contextualized features using encoder-decoder architectures and later combines them with a high-resolution branch that retains local information. At each stage, we introduce a novel per-pixel adaptive design that leverages in-situ supervised attention to reweight the local features. A key ingredient in such a multi-stage architecture is the information exchange between different stages. To this end, we propose a two-faceted approach where the information is not only exchanged sequentially from early to late stages, but lateral connections between feature processing blocks also exist to avoid any loss of information. The resulting tightly interlinked multi-stage architecture, named as MPRNet, delivers strong performance gains on ten datasets across a range of tasks including image deraining, deblurring, and denoising. For example, on the Rain100L, GoPro and DND datasets, we obtain PSNR gains of 4 dB, 0.81 dB and 0.21 dB, respectively, compared to the state-of-the-art. The source code and pre-trained models are available at https://github.com/swz30/MPRNet.
Transformers in Vision: A Survey
Jan 04, 2021
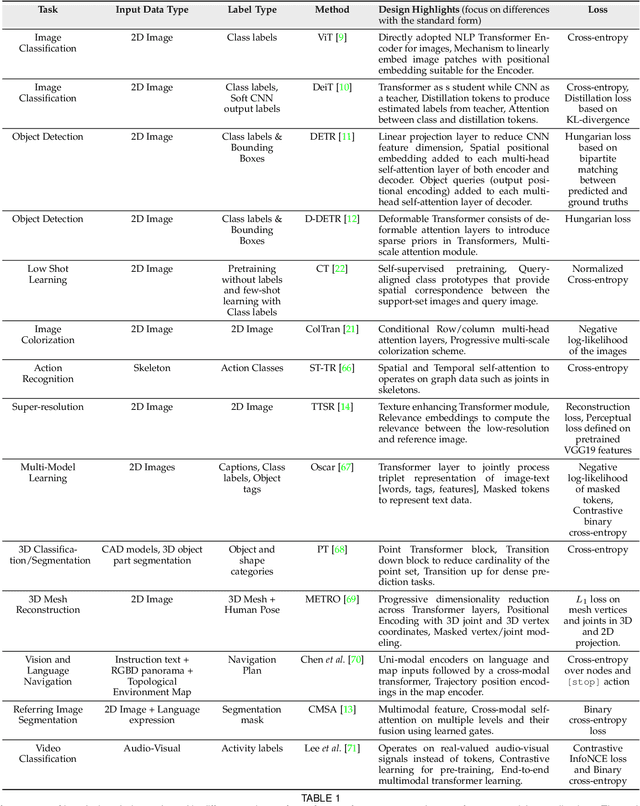
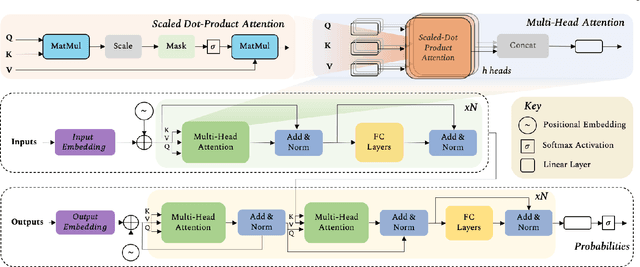
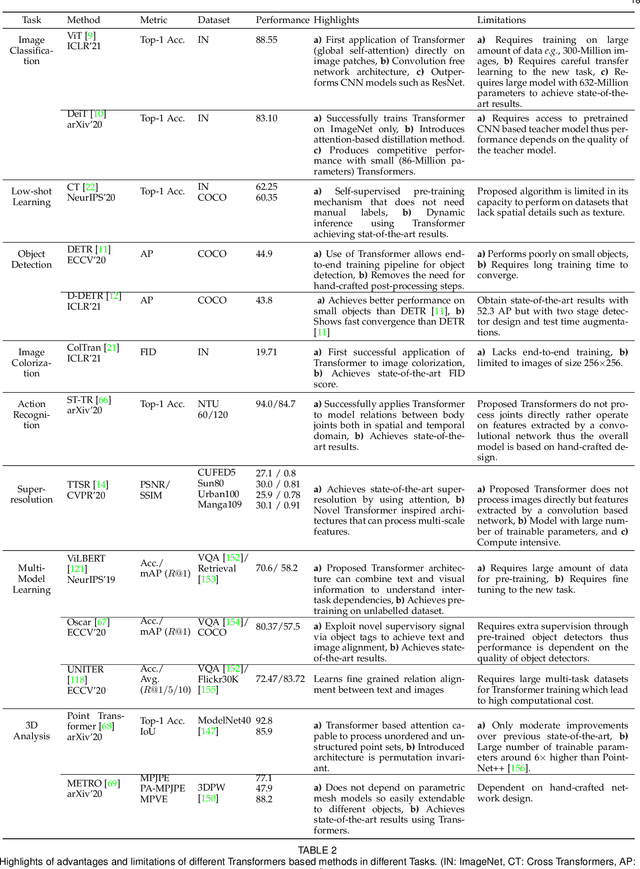
Astounding results from transformer models on natural language tasks have intrigued the vision community to study their application to computer vision problems. This has led to exciting progress on a number of tasks while requiring minimal inductive biases in the model design. This survey aims to provide a comprehensive overview of the transformer models in the computer vision discipline and assumes little to no prior background in the field. We start with an introduction to fundamental concepts behind the success of transformer models i.e., self-supervision and self-attention. Transformer architectures leverage self-attention mechanisms to encode long-range dependencies in the input domain which makes them highly expressive. Since they assume minimal prior knowledge about the structure of the problem, self-supervision using pretext tasks is applied to pre-train transformer models on large-scale (unlabelled) datasets. The learned representations are then fine-tuned on the downstream tasks, typically leading to excellent performance due to the generalization and expressivity of encoded features. We cover extensive applications of transformers in vision including popular recognition tasks (e.g., image classification, object detection, action recognition, and segmentation), generative modeling, multi-modal tasks (e.g., visual-question answering and visual reasoning), video processing (e.g., activity recognition, video forecasting), low-level vision (e.g., image super-resolution and colorization) and 3D analysis (e.g., point cloud classification and segmentation). We compare the respective advantages and limitations of popular techniques both in terms of architectural design and their experimental value. Finally, we provide an analysis on open research directions and possible future works.
Low Light Image Enhancement via Global and Local Context Modeling
Jan 04, 2021
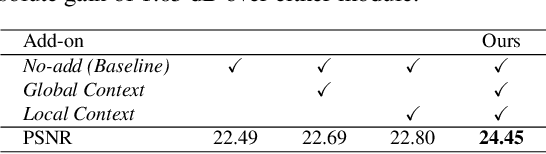
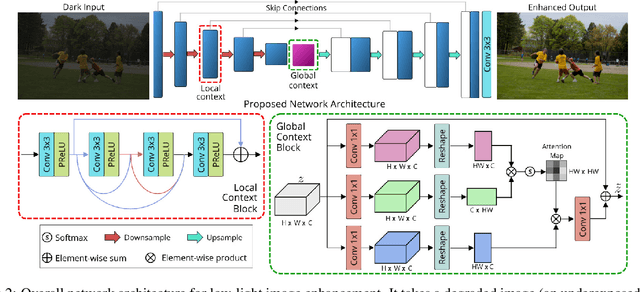

Images captured under low-light conditions manifest poor visibility, lack contrast and color vividness. Compared to conventional approaches, deep convolutional neural networks (CNNs) perform well in enhancing images. However, being solely reliant on confined fixed primitives to model dependencies, existing data-driven deep models do not exploit the contexts at various spatial scales to address low-light image enhancement. These contexts can be crucial towards inferring several image enhancement tasks, e.g., local and global contrast, brightness and color corrections; which requires cues from both local and global spatial extent. To this end, we introduce a context-aware deep network for low-light image enhancement. First, it features a global context module that models spatial correlations to find complementary cues over full spatial domain. Second, it introduces a dense residual block that captures local context with a relatively large receptive field. We evaluate the proposed approach using three challenging datasets: MIT-Adobe FiveK, LoL, and SID. On all these datasets, our method performs favorably against the state-of-the-arts in terms of standard image fidelity metrics. In particular, compared to the best performing method on the MIT-Adobe FiveK dataset, our algorithm improves PSNR from 23.04 dB to 24.45 dB.
Synthesizing the Unseen for Zero-shot Object Detection
Oct 19, 2020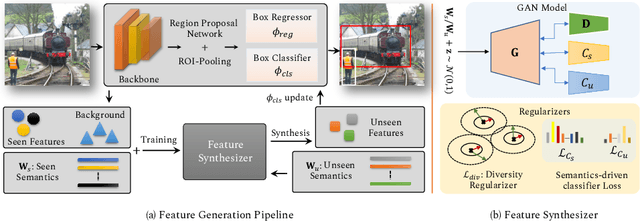
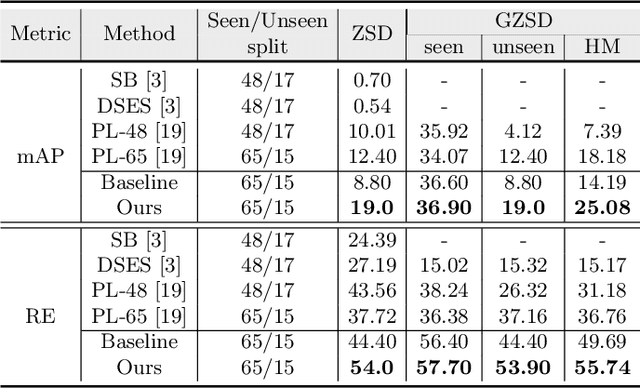
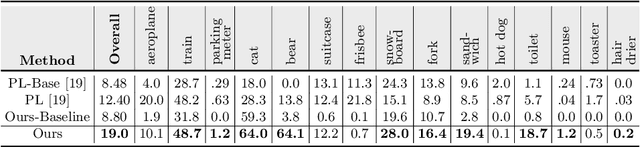
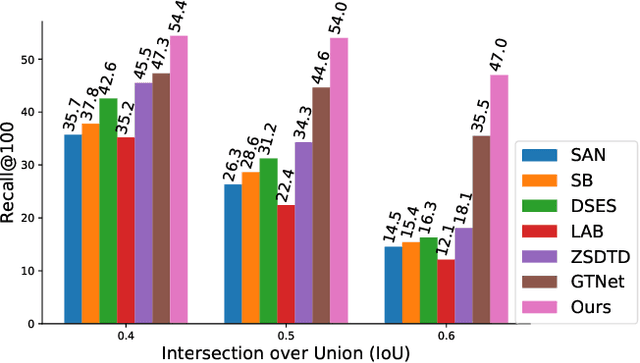
The existing zero-shot detection approaches project visual features to the semantic domain for seen objects, hoping to map unseen objects to their corresponding semantics during inference. However, since the unseen objects are never visualized during training, the detection model is skewed towards seen content, thereby labeling unseen as background or a seen class. In this work, we propose to synthesize visual features for unseen classes, so that the model learns both seen and unseen objects in the visual domain. Consequently, the major challenge becomes, how to accurately synthesize unseen objects merely using their class semantics? Towards this ambitious goal, we propose a novel generative model that uses class-semantics to not only generate the features but also to discriminatively separate them. Further, using a unified model, we ensure the synthesized features have high diversity that represents the intra-class differences and variable localization precision in the detected bounding boxes. We test our approach on three object detection benchmarks, PASCAL VOC, MSCOCO, and ILSVRC detection, under both conventional and generalized settings, showing impressive gains over the state-of-the-art methods. Our codes are available at https://github.com/nasir6/zero_shot_detection.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020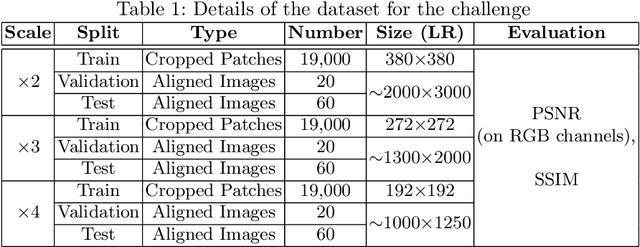
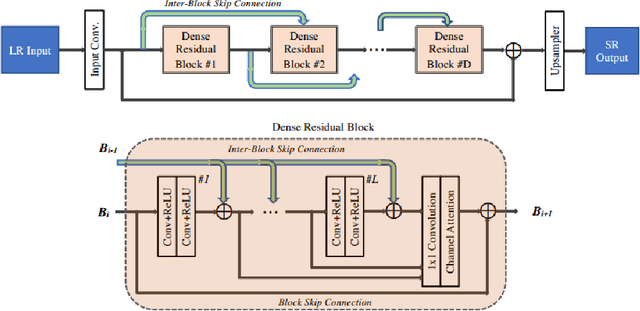
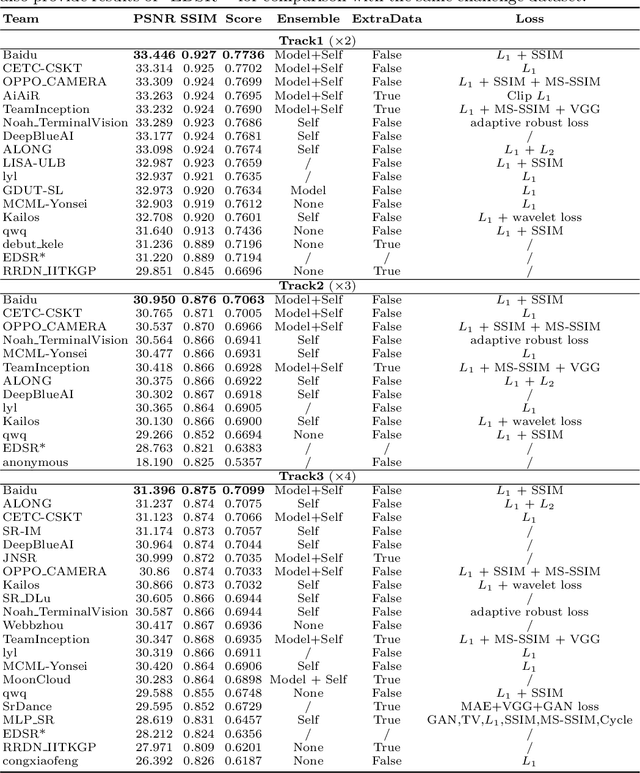
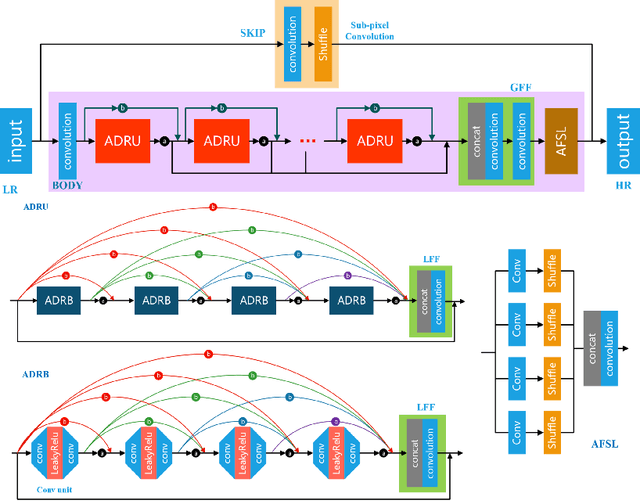
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.
CycleISP: Real Image Restoration via Improved Data Synthesis
Mar 17, 2020
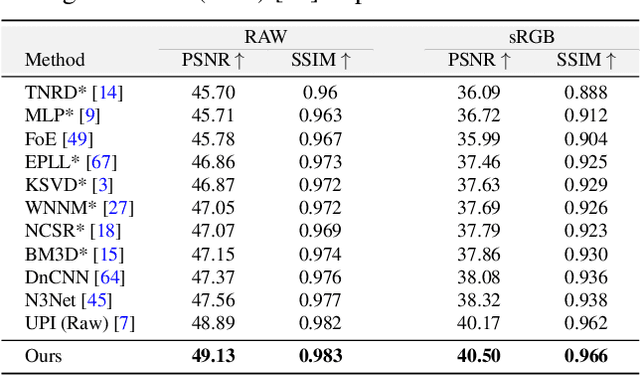
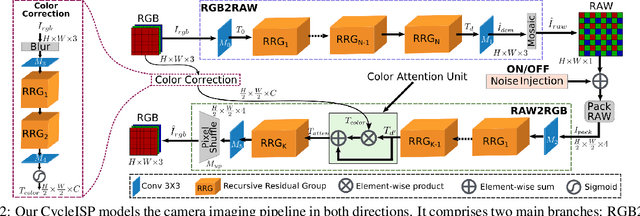
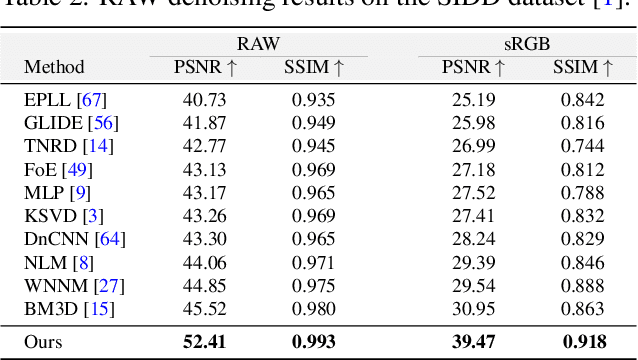
The availability of large-scale datasets has helped unleash the true potential of deep convolutional neural networks (CNNs). However, for the single-image denoising problem, capturing a real dataset is an unacceptably expensive and cumbersome procedure. Consequently, image denoising algorithms are mostly developed and evaluated on synthetic data that is usually generated with a widespread assumption of additive white Gaussian noise (AWGN). While the CNNs achieve impressive results on these synthetic datasets, they do not perform well when applied on real camera images, as reported in recent benchmark datasets. This is mainly because the AWGN is not adequate for modeling the real camera noise which is signal-dependent and heavily transformed by the camera imaging pipeline. In this paper, we present a framework that models camera imaging pipeline in forward and reverse directions. It allows us to produce any number of realistic image pairs for denoising both in RAW and sRGB spaces. By training a new image denoising network on realistic synthetic data, we achieve the state-of-the-art performance on real camera benchmark datasets. The parameters in our model are ~5 times lesser than the previous best method for RAW denoising. Furthermore, we demonstrate that the proposed framework generalizes beyond image denoising problem e.g., for color matching in stereoscopic cinema. The source code and pre-trained models are available at https://github.com/swz30/CycleISP.
Learning Enriched Features for Real Image Restoration and Enhancement
Mar 15, 2020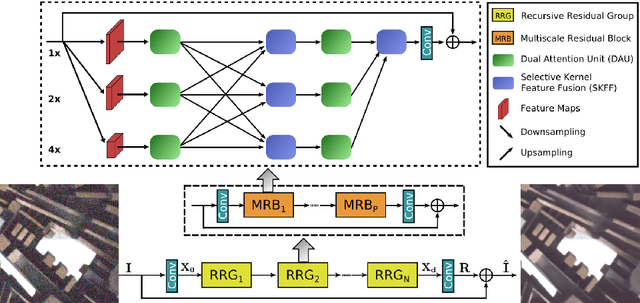

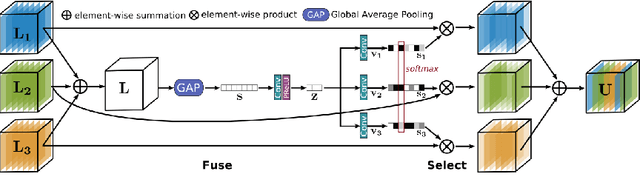
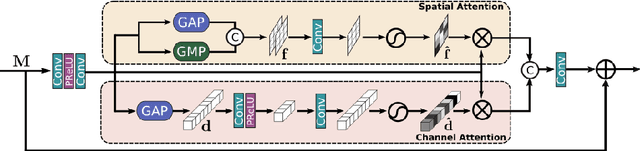
With the goal of recovering high-quality image content from its degraded version, image restoration enjoys numerous applications, such as in surveillance, computational photography, medical imaging, and remote sensing. Recently, convolutional neural networks (CNNs) have achieved dramatic improvements over conventional approaches for image restoration task. Existing CNN-based methods typically operate either on full-resolution or on progressively low-resolution representations. In the former case, spatially precise but contextually less robust results are achieved, while in the latter case, semantically reliable but spatially less accurate outputs are generated. In this paper, we present a novel architecture with the collective goals of maintaining spatially-precise high-resolution representations through the entire network, and receiving strong contextual information from the low-resolution representations. The core of our approach is a multi-scale residual block containing several key elements: (a) parallel multi-resolution convolution streams for extracting multi-scale features, (b) information exchange across the multi-resolution streams, (c) spatial and channel attention mechanisms for capturing contextual information, and (d) attention based multi-scale feature aggregation. In the nutshell, our approach learns an enriched set of features that combines contextual information from multiple scales, while simultaneously preserving the high-resolution spatial details. Extensive experiments on five real image benchmark datasets demonstrate that our method, named as MIRNet, achieves state-of-the-art results for a variety of image processing tasks, including image denoising, super-resolution and image enhancement.
iSAID: A Large-scale Dataset for Instance Segmentation in Aerial Images
May 30, 2019
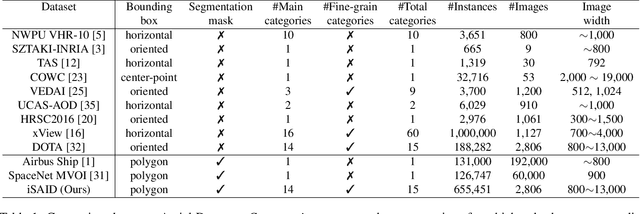
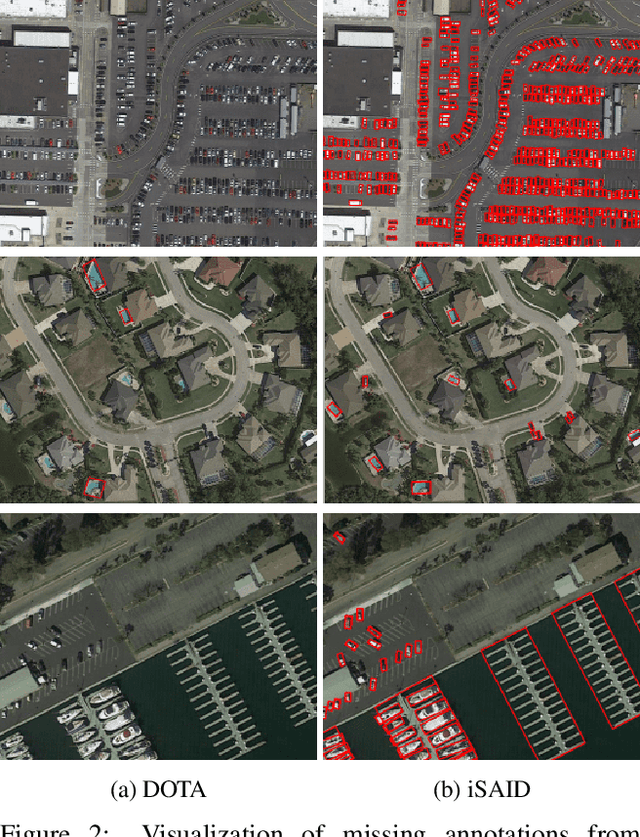
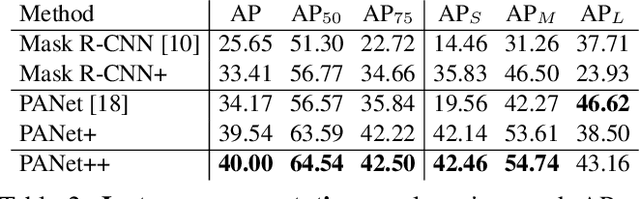
Existing Earth Vision datasets are either suitable for semantic segmentation or object detection. In this work, we introduce the first benchmark dataset for instance segmentation in aerial imagery that combines instance-level object detection and pixel-level segmentation tasks. In comparison to instance segmentation in natural scenes, aerial images present unique challenges e.g., a huge number of instances per image, large object-scale variations and abundant tiny objects. Our large-scale and densely annotated Instance Segmentation in Aerial Images Dataset (iSAID) comes with 655,451 object instances for 15 categories across 2,806 high-resolution images. Such precise per-pixel annotations for each instance ensure accurate localization that is essential for detailed scene analysis. Compared to existing small-scale aerial image based instance segmentation datasets, iSAID contains 15$\times$ the number of object categories and 5$\times$ the number of instances. We benchmark our dataset using two popular instance segmentation approaches for natural images, namely Mask R-CNN and PANet. In our experiments we show that direct application of off-the-shelf Mask R-CNN and PANet on aerial images provide suboptimal instance segmentation results, thus requiring specialized solutions from the research community.