 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Reward Modulation for Pretraining Reinforcement Learning
Aug 23, 2023Using learned reward functions (LRFs) as a means to solve sparse-reward reinforcement learning (RL) tasks has yielded some steady progress in task-complexity through the years. In this work, we question whether today's LRFs are best-suited as a direct replacement for task rewards. Instead, we propose leveraging the capabilities of LRFs as a pretraining signal for RL. Concretely, we propose $\textbf{LA}$nguage Reward $\textbf{M}$odulated $\textbf{P}$retraining (LAMP) which leverages the zero-shot capabilities of Vision-Language Models (VLMs) as a $\textit{pretraining}$ utility for RL as opposed to a downstream task reward. LAMP uses a frozen, pretrained VLM to scalably generate noisy, albeit shaped exploration rewards by computing the contrastive alignment between a highly diverse collection of language instructions and the image observations of an agent in its pretraining environment. LAMP optimizes these rewards in conjunction with standard novelty-seeking exploration rewards with reinforcement learning to acquire a language-conditioned, pretrained policy. Our VLM pretraining approach, which is a departure from previous attempts to use LRFs, can warmstart sample-efficient learning on robot manipulation tasks in RLBench.
Multi-View Masked World Models for Visual Robotic Manipulation
Feb 05, 2023Visual robotic manipulation research and applications often use multiple cameras, or views, to better perceive the world. How else can we utilize the richness of multi-view data? In this paper, we investigate how to learn good representations with multi-view data and utilize them for visual robotic manipulation. Specifically, we train a multi-view masked autoencoder which reconstructs pixels of randomly masked viewpoints and then learn a world model operating on the representations from the autoencoder. We demonstrate the effectiveness of our method in a range of scenarios, including multi-view control and single-view control with auxiliary cameras for representation learning. We also show that the multi-view masked autoencoder trained with multiple randomized viewpoints enables training a policy with strong viewpoint randomization and transferring the policy to solve real-robot tasks without camera calibration and an adaptation procedure. Videos demonstrations in real-world experiments and source code are available at the project website: https://sites.google.com/view/mv-mwm.
StereoPose: Category-Level 6D Transparent Object Pose Estimation from Stereo Images via Back-View NOCS
Nov 03, 2022



Most existing methods for category-level pose estimation rely on object point clouds. However, when considering transparent objects, depth cameras are usually not able to capture meaningful data, resulting in point clouds with severe artifacts. Without a high-quality point cloud, existing methods are not applicable to challenging transparent objects. To tackle this problem, we present StereoPose, a novel stereo image framework for category-level object pose estimation, ideally suited for transparent objects. For a robust estimation from pure stereo images, we develop a pipeline that decouples category-level pose estimation into object size estimation, initial pose estimation, and pose refinement. StereoPose then estimates object pose based on representation in the normalized object coordinate space~(NOCS). To address the issue of image content aliasing, we further define a back-view NOCS map for the transparent object. The back-view NOCS aims to reduce the network learning ambiguity caused by content aliasing, and leverage informative cues on the back of the transparent object for more accurate pose estimation. To further improve the performance of the stereo framework, StereoPose is equipped with a parallax attention module for stereo feature fusion and an epipolar loss for improving the stereo-view consistency of network predictions. Extensive experiments on the public TOD dataset demonstrate the superiority of the proposed StereoPose framework for category-level 6D transparent object pose estimation.
Sim-to-Real via Sim-to-Seg: End-to-end Off-road Autonomous Driving Without Real Data
Oct 25, 2022



Autonomous driving is complex, requiring sophisticated 3D scene understanding, localization, mapping, and control. Rather than explicitly modelling and fusing each of these components, we instead consider an end-to-end approach via reinforcement learning (RL). However, collecting exploration driving data in the real world is impractical and dangerous. While training in simulation and deploying visual sim-to-real techniques has worked well for robot manipulation, deploying beyond controlled workspace viewpoints remains a challenge. In this paper, we address this challenge by presenting Sim2Seg, a re-imagining of RCAN that crosses the visual reality gap for off-road autonomous driving, without using any real-world data. This is done by learning to translate randomized simulation images into simulated segmentation and depth maps, subsequently enabling real-world images to also be translated. This allows us to train an end-to-end RL policy in simulation, and directly deploy in the real-world. Our approach, which can be trained in 48 hours on 1 GPU, can perform equally as well as a classical perception and control stack that took thousands of engineering hours over several months to build. We hope this work motivates future end-to-end autonomous driving research.
Real-World Robot Learning with Masked Visual Pre-training
Oct 06, 2022

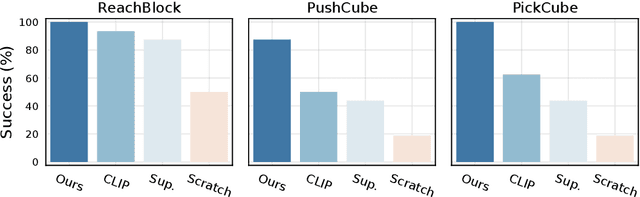
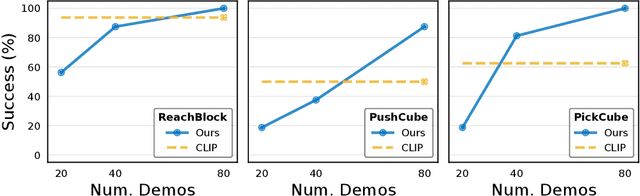
In this work, we explore self-supervised visual pre-training on images from diverse, in-the-wild videos for real-world robotic tasks. Like prior work, our visual representations are pre-trained via a masked autoencoder (MAE), frozen, and then passed into a learnable control module. Unlike prior work, we show that the pre-trained representations are effective across a range of real-world robotic tasks and embodiments. We find that our encoder consistently outperforms CLIP (up to 75%), supervised ImageNet pre-training (up to 81%), and training from scratch (up to 81%). Finally, we train a 307M parameter vision transformer on a massive collection of 4.5M images from the Internet and egocentric videos, and demonstrate clearly the benefits of scaling visual pre-training for robot learning.
Temporally Consistent Video Transformer for Long-Term Video Prediction
Oct 05, 2022
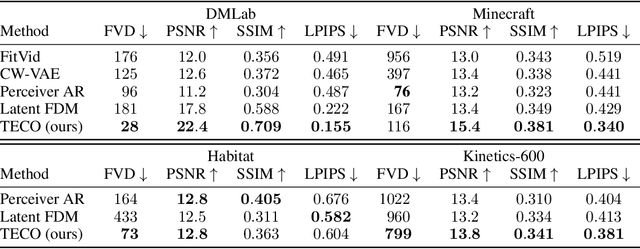
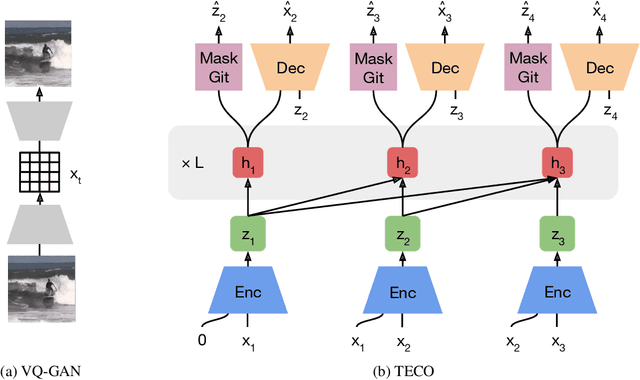
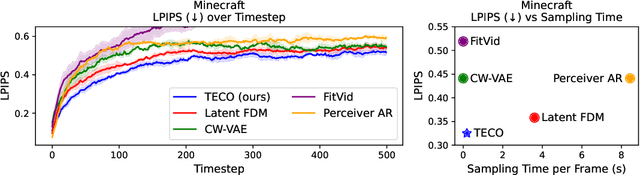
Generating long, temporally consistent video remains an open challenge in video generation. Primarily due to computational limitations, most prior methods limit themselves to training on a small subset of frames that are then extended to generate longer videos through a sliding window fashion. Although these techniques may produce sharp videos, they have difficulty retaining long-term temporal consistency due to their limited context length. In this work, we present Temporally Consistent Video Transformer (TECO), a vector-quantized latent dynamics video prediction model that learns compressed representations to efficiently condition on long videos of hundreds of frames during both training and generation. We use a MaskGit prior for dynamics prediction which enables both sharper and faster generations compared to prior work. Our experiments show that TECO outperforms SOTA baselines in a variety of video prediction benchmarks ranging from simple mazes in DMLab, large 3D worlds in Minecraft, and complex real-world videos from Kinetics-600. In addition, to better understand the capabilities of video prediction models in modeling temporal consistency, we introduce several challenging video prediction tasks consisting of agents randomly traversing 3D scenes of varying difficulty. This presents a challenging benchmark for video prediction in partially observable environments where a model must understand what parts of the scenes to re-create versus invent depending on its past observations or generations. Generated videos are available at https://wilson1yan.github.io/teco
HARP: Autoregressive Latent Video Prediction with High-Fidelity Image Generator
Sep 15, 2022
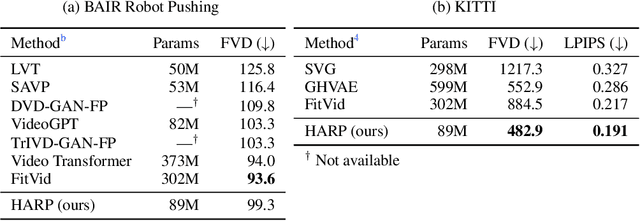
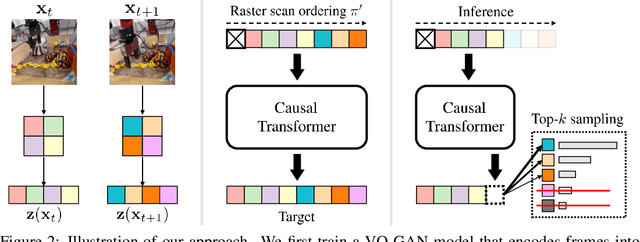
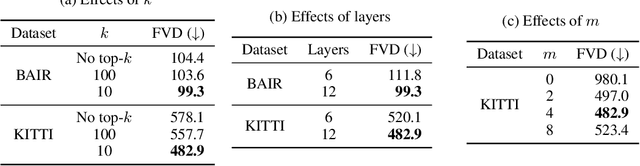
Video prediction is an important yet challenging problem; burdened with the tasks of generating future frames and learning environment dynamics. Recently, autoregressive latent video models have proved to be a powerful video prediction tool, by separating the video prediction into two sub-problems: pre-training an image generator model, followed by learning an autoregressive prediction model in the latent space of the image generator. However, successfully generating high-fidelity and high-resolution videos has yet to be seen. In this work, we investigate how to train an autoregressive latent video prediction model capable of predicting high-fidelity future frames with minimal modification to existing models, and produce high-resolution (256x256) videos. Specifically, we scale up prior models by employing a high-fidelity image generator (VQ-GAN) with a causal transformer model, and introduce additional techniques of top-k sampling and data augmentation to further improve video prediction quality. Despite the simplicity, the proposed method achieves competitive performance to state-of-the-art approaches on standard video prediction benchmarks with fewer parameters, and enables high-resolution video prediction on complex and large-scale datasets. Videos are available at https://sites.google.com/view/harp-videos/home.
Masked World Models for Visual Control
Jun 28, 2022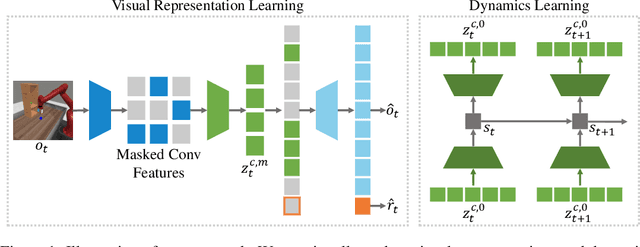

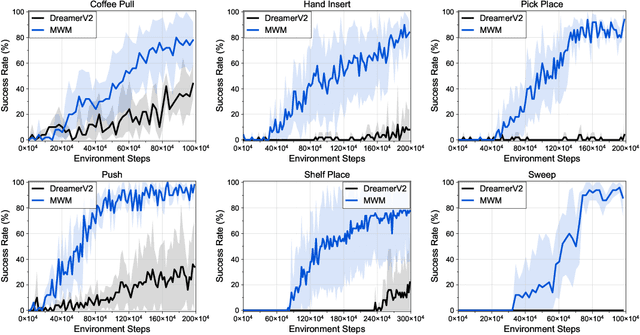
Visual model-based reinforcement learning (RL) has the potential to enable sample-efficient robot learning from visual observations. Yet the current approaches typically train a single model end-to-end for learning both visual representations and dynamics, making it difficult to accurately model the interaction between robots and small objects. In this work, we introduce a visual model-based RL framework that decouples visual representation learning and dynamics learning. Specifically, we train an autoencoder with convolutional layers and vision transformers (ViT) to reconstruct pixels given masked convolutional features, and learn a latent dynamics model that operates on the representations from the autoencoder. Moreover, to encode task-relevant information, we introduce an auxiliary reward prediction objective for the autoencoder. We continually update both autoencoder and dynamics model using online samples collected from environment interaction. We demonstrate that our decoupling approach achieves state-of-the-art performance on a variety of visual robotic tasks from Meta-world and RLBench, e.g., we achieve 81.7% success rate on 50 visual robotic manipulation tasks from Meta-world, while the baseline achieves 67.9%. Code is available on the project website: https://sites.google.com/view/mwm-rl.
Patch-based Object-centric Transformers for Efficient Video Generation
Jun 19, 2022
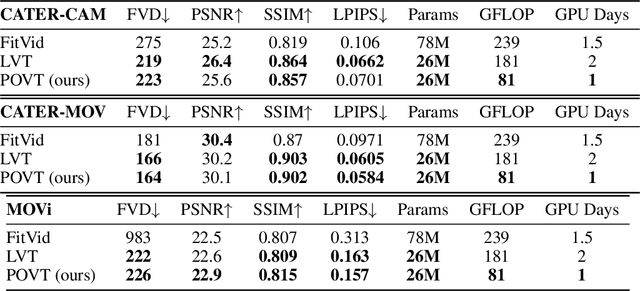
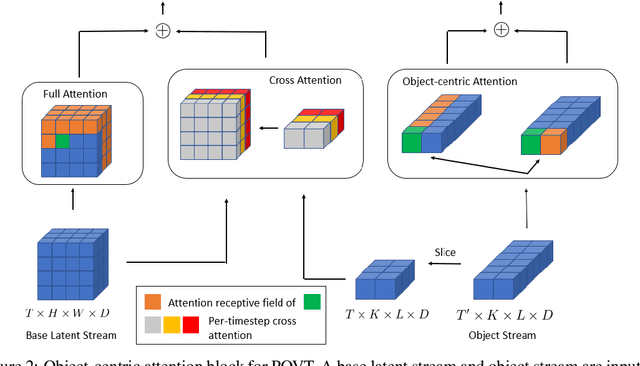

In this work, we present Patch-based Object-centric Video Transformer (POVT), a novel region-based video generation architecture that leverages object-centric information to efficiently model temporal dynamics in videos. We build upon prior work in video prediction via an autoregressive transformer over the discrete latent space of compressed videos, with an added modification to model object-centric information via bounding boxes. Due to better compressibility of object-centric representations, we can improve training efficiency by allowing the model to only access object information for longer horizon temporal information. When evaluated on various difficult object-centric datasets, our method achieves better or equal performance to other video generation models, while remaining computationally more efficient and scalable. In addition, we show that our method is able to perform object-centric controllability through bounding box manipulation, which may aid downstream tasks such as video editing, or visual planning. Samples are available at https://sites.google.com/view/povt-public
On the Effectiveness of Fine-tuning Versus Meta-reinforcement Learning
Jun 07, 2022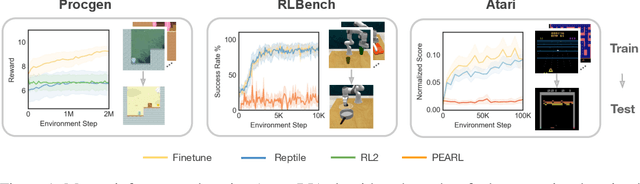
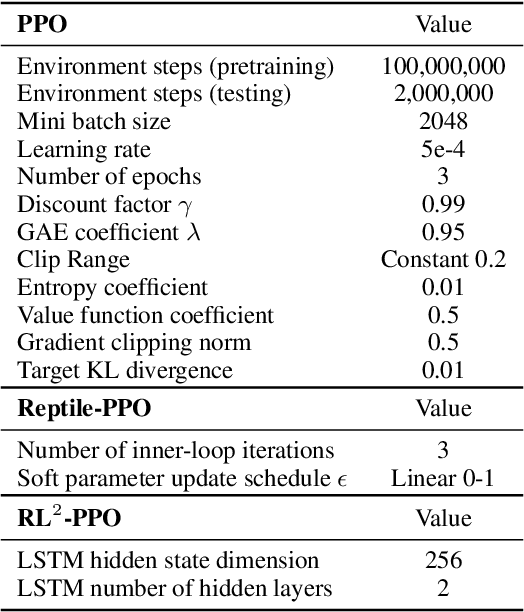
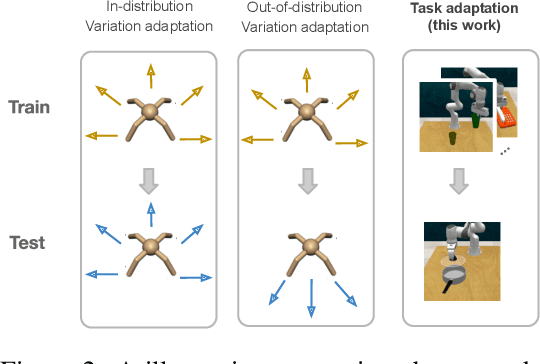
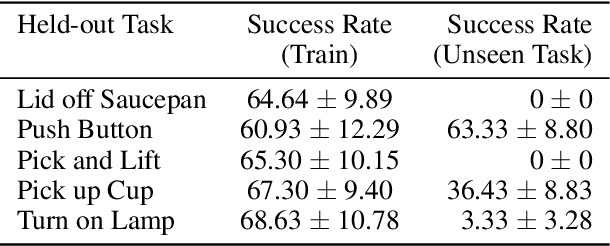
Intelligent agents should have the ability to leverage knowledge from previously learned tasks in order to learn new ones quickly and efficiently. Meta-learning approaches have emerged as a popular solution to achieve this. However, meta-reinforcement learning (meta-RL) algorithms have thus far been restricted to simple environments with narrow task distributions. Moreover, the paradigm of pretraining followed by fine-tuning to adapt to new tasks has emerged as a simple yet effective solution in supervised and self-supervised learning. This calls into question the benefits of meta-learning approaches also in reinforcement learning, which typically come at the cost of high complexity. We hence investigate meta-RL approaches in a variety of vision-based benchmarks, including Procgen, RLBench, and Atari, where evaluations are made on completely novel tasks. Our findings show that when meta-learning approaches are evaluated on different tasks (rather than different variations of the same task), multi-task pretraining with fine-tuning on new tasks performs equally as well, or better, than meta-pretraining with meta test-time adaptation. This is encouraging for future research, as multi-task pretraining tends to be simpler and computationally cheaper than meta-RL. From these findings, we advocate for evaluating future meta-RL methods on more challenging tasks and including multi-task pretraining with fine-tuning as a simple, yet strong baseline.