 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexDrummer: In-Hand, Contact-Rich, and Long-Horizon Dexterous Robot Drumming
Mar 23, 2026Performing in-hand, contact-rich, and long-horizon dexterous manipulation remains an unsolved challenge in robotics. Prior hand dexterity works have considered each of these three challenges in isolation, yet do not combine these skills into a single, complex task. To further test the capabilities of dexterity, we propose drumming as a testbed for dexterous manipulation. Drumming naturally integrates all three challenges: it involves in-hand control for stabilizing and adjusting the drumstick with the fingers, contact-rich interaction through repeated striking of the drum surface, and long-horizon coordination when switching between drums and sustaining rhythmic play. We present DexDrummer, a hierarchical object-centric bimanual drumming policy trained in simulation with sim-to-real transfer. The framework reduces the exploration difficulty of pure reinforcement learning by combining trajectory planning with residual RL corrections for fast transitions between drums. A dexterous manipulation policy handles contact-rich dynamics, guided by rewards that explicitly model both finger-stick and stick-drum interactions. In simulation, we show our policy can play two styles of music: multi-drum, bimanual songs and challenging, technical exercises that require increased dexterity. Across simulated bimanual tasks, our dexterous, reactive policy outperforms a fixed grasp policy by 1.87x across easy songs and 1.22x across hard songs F1 scores. In real-world tasks, we show song performance across a multi-drum setup. DexDrummer is able to play our training song and its extended version with an F1 score of 1.0.
HandelBot: Real-World Piano Playing via Fast Adaptation of Dexterous Robot Policies
Mar 12, 2026Mastering dexterous manipulation with multi-fingered hands has been a grand challenge in robotics for decades. Despite its potential, the difficulty of collecting high-quality data remains a primary bottleneck for high-precision tasks. While reinforcement learning and simulation-to-real-world transfer offer a promising alternative, the transferred policies often fail for tasks demanding millimeter-scale precision, such as bimanual piano playing. In this work, we introduce HandelBot, a framework that combines a simulation policy and rapid adaptation through a two-stage pipeline. Starting from a simulation-trained policy, we first apply a structured refinement stage to correct spatial alignments by adjusting lateral finger joints based on physical rollouts. Next, we use residual reinforcement learning to autonomously learn fine-grained corrective actions. Through extensive hardware experiments across five recognized songs, we demonstrate that HandelBot can successfully perform precise bimanual piano playing. Our system outperforms direct simulation deployment by a factor of 1.8x and requires only 30 minutes of physical interaction data.
Latent Diffusion Planning for Imitation Learning
Apr 23, 2025Recent progress in imitation learning has been enabled by policy architectures that scale to complex visuomotor tasks, multimodal distributions, and large datasets. However, these methods often rely on learning from large amount of expert demonstrations. To address these shortcomings, we propose Latent Diffusion Planning (LDP), a modular approach consisting of a planner which can leverage action-free demonstrations, and an inverse dynamics model which can leverage suboptimal data, that both operate over a learned latent space. First, we learn a compact latent space through a variational autoencoder, enabling effective forecasting of future states in image-based domains. Then, we train a planner and an inverse dynamics model with diffusion objectives. By separating planning from action prediction, LDP can benefit from the denser supervision signals of suboptimal and action-free data. On simulated visual robotic manipulation tasks, LDP outperforms state-of-the-art imitation learning approaches, as they cannot leverage such additional data.
FlowRetrieval: Flow-Guided Data Retrieval for Few-Shot Imitation Learning
Aug 29, 2024Few-shot imitation learning relies on only a small amount of task-specific demonstrations to efficiently adapt a policy for a given downstream tasks. Retrieval-based methods come with a promise of retrieving relevant past experiences to augment this target data when learning policies. However, existing data retrieval methods fall under two extremes: they either rely on the existence of exact behaviors with visually similar scenes in the prior data, which is impractical to assume; or they retrieve based on semantic similarity of high-level language descriptions of the task, which might not be that informative about the shared low-level behaviors or motions across tasks that is often a more important factor for retrieving relevant data for policy learning. In this work, we investigate how we can leverage motion similarity in the vast amount of cross-task data to improve few-shot imitation learning of the target task. Our key insight is that motion-similar data carries rich information about the effects of actions and object interactions that can be leveraged during few-shot adaptation. We propose FlowRetrieval, an approach that leverages optical flow representations for both extracting similar motions to target tasks from prior data, and for guiding learning of a policy that can maximally benefit from such data. Our results show FlowRetrieval significantly outperforms prior methods across simulated and real-world domains, achieving on average 27% higher success rate than the best retrieval-based prior method. In the Pen-in-Cup task with a real Franka Emika robot, FlowRetrieval achieves 3.7x the performance of the baseline imitation learning technique that learns from all prior and target data. Website: https://flow-retrieval.github.io
Leveraging Human Revisions for Improving Text-to-Layout Models
May 16, 2024



Learning from human feedback has shown success in aligning large, pretrained models with human values. Prior works have mostly focused on learning from high-level labels, such as preferences between pairs of model outputs. On the other hand, many domains could benefit from more involved, detailed feedback, such as revisions, explanations, and reasoning of human users. Our work proposes using nuanced feedback through the form of human revisions for stronger alignment. In this paper, we ask expert designers to fix layouts generated from a generative layout model that is pretrained on a large-scale dataset of mobile screens. Then, we train a reward model based on how human designers revise these generated layouts. With the learned reward model, we optimize our model with reinforcement learning from human feedback (RLHF). Our method, Revision-Aware Reward Models ($\method$), allows a generative text-to-layout model to produce more modern, designer-aligned layouts, showing the potential for utilizing human revisions and stronger forms of feedback in improving generative models.
Language-Conditioned Path Planning
Aug 31, 2023Contact is at the core of robotic manipulation. At times, it is desired (e.g. manipulation and grasping), and at times, it is harmful (e.g. when avoiding obstacles). However, traditional path planning algorithms focus solely on collision-free paths, limiting their applicability in contact-rich tasks. To address this limitation, we propose the domain of Language-Conditioned Path Planning, where contact-awareness is incorporated into the path planning problem. As a first step in this domain, we propose Language-Conditioned Collision Functions (LACO) a novel approach that learns a collision function using only a single-view image, language prompt, and robot configuration. LACO predicts collisions between the robot and the environment, enabling flexible, conditional path planning without the need for manual object annotations, point cloud data, or ground-truth object meshes. In both simulation and the real world, we demonstrate that LACO can facilitate complex, nuanced path plans that allow for interaction with objects that are safe to collide, rather than prohibiting any collision.
Language Reward Modulation for Pretraining Reinforcement Learning
Aug 23, 2023Using learned reward functions (LRFs) as a means to solve sparse-reward reinforcement learning (RL) tasks has yielded some steady progress in task-complexity through the years. In this work, we question whether today's LRFs are best-suited as a direct replacement for task rewards. Instead, we propose leveraging the capabilities of LRFs as a pretraining signal for RL. Concretely, we propose $\textbf{LA}$nguage Reward $\textbf{M}$odulated $\textbf{P}$retraining (LAMP) which leverages the zero-shot capabilities of Vision-Language Models (VLMs) as a $\textit{pretraining}$ utility for RL as opposed to a downstream task reward. LAMP uses a frozen, pretrained VLM to scalably generate noisy, albeit shaped exploration rewards by computing the contrastive alignment between a highly diverse collection of language instructions and the image observations of an agent in its pretraining environment. LAMP optimizes these rewards in conjunction with standard novelty-seeking exploration rewards with reinforcement learning to acquire a language-conditioned, pretrained policy. Our VLM pretraining approach, which is a departure from previous attempts to use LRFs, can warmstart sample-efficient learning on robot manipulation tasks in RLBench.
VectorFusion: Text-to-SVG by Abstracting Pixel-Based Diffusion Models
Nov 21, 2022Diffusion models have shown impressive results in text-to-image synthesis. Using massive datasets of captioned images, diffusion models learn to generate raster images of highly diverse objects and scenes. However, designers frequently use vector representations of images like Scalable Vector Graphics (SVGs) for digital icons or art. Vector graphics can be scaled to any size, and are compact. We show that a text-conditioned diffusion model trained on pixel representations of images can be used to generate SVG-exportable vector graphics. We do so without access to large datasets of captioned SVGs. By optimizing a differentiable vector graphics rasterizer, our method, VectorFusion, distills abstract semantic knowledge out of a pretrained diffusion model. Inspired by recent text-to-3D work, we learn an SVG consistent with a caption using Score Distillation Sampling. To accelerate generation and improve fidelity, VectorFusion also initializes from an image sample. Experiments show greater quality than prior work, and demonstrate a range of styles including pixel art and sketches. See our project webpage at https://ajayj.com/vectorfusion .
Sim-to-Real via Sim-to-Seg: End-to-end Off-road Autonomous Driving Without Real Data
Oct 25, 2022



Autonomous driving is complex, requiring sophisticated 3D scene understanding, localization, mapping, and control. Rather than explicitly modelling and fusing each of these components, we instead consider an end-to-end approach via reinforcement learning (RL). However, collecting exploration driving data in the real world is impractical and dangerous. While training in simulation and deploying visual sim-to-real techniques has worked well for robot manipulation, deploying beyond controlled workspace viewpoints remains a challenge. In this paper, we address this challenge by presenting Sim2Seg, a re-imagining of RCAN that crosses the visual reality gap for off-road autonomous driving, without using any real-world data. This is done by learning to translate randomized simulation images into simulated segmentation and depth maps, subsequently enabling real-world images to also be translated. This allows us to train an end-to-end RL policy in simulation, and directly deploy in the real-world. Our approach, which can be trained in 48 hours on 1 GPU, can perform equally as well as a classical perception and control stack that took thousands of engineering hours over several months to build. We hope this work motivates future end-to-end autonomous driving research.
Skill-Based Reinforcement Learning with Intrinsic Reward Matching
Oct 17, 2022
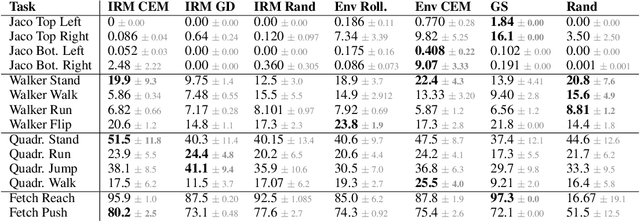
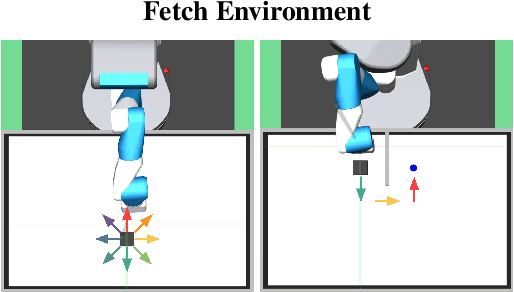
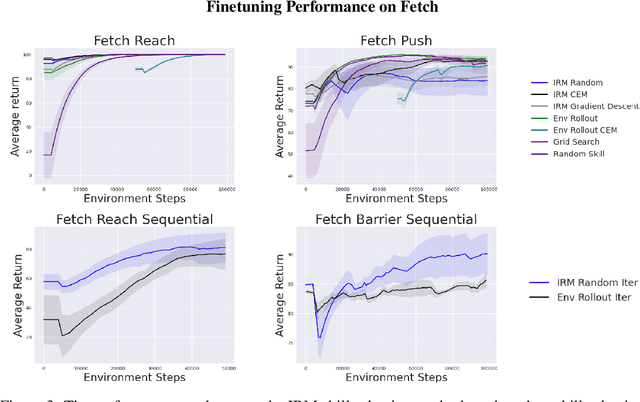
While unsupervised skill discovery has shown promise in autonomously acquiring behavioral primitives, there is still a large methodological disconnect between task-agnostic skill pretraining and downstream, task-aware finetuning. We present Intrinsic Reward Matching (IRM), which unifies these two phases of learning via the $\textit{skill discriminator}$, a pretraining model component often discarded during finetuning. Conventional approaches finetune pretrained agents directly at the policy level, often relying on expensive environment rollouts to empirically determine the optimal skill. However, often the most concise yet complete description of a task is the reward function itself, and skill learning methods learn an $\textit{intrinsic}$ reward function via the discriminator that corresponds to the skill policy. We propose to leverage the skill discriminator to $\textit{match}$ the intrinsic and downstream task rewards and determine the optimal skill for an unseen task without environment samples, consequently finetuning with greater sample-efficiency. Furthermore, we generalize IRM to sequence skills and solve more complex, long-horizon tasks. We demonstrate that IRM is competitive with previous skill selection methods on the Unsupervised Reinforcement Learning Benchmark and enables us to utilize pretrained skills far more effectively on challenging tabletop manipulation tasks.