 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld-Model-Based Control for Industrial box-packing of Multiple Objects using NewtonianVAE
Aug 04, 2023



The process of industrial box-packing, which involves the accurate placement of multiple objects, requires high-accuracy positioning and sequential actions. When a robot is tasked with placing an object at a specific location with high accuracy, it is important not only to have information about the location of the object to be placed, but also the posture of the object grasped by the robotic hand. Often, industrial box-packing requires the sequential placement of identically shaped objects into a single box. The robot's action should be determined by the same learned model. In factories, new kinds of products often appear and there is a need for a model that can easily adapt to them. Therefore, it should be easy to collect data to train the model. In this study, we designed a robotic system to automate real-world industrial tasks, employing a vision-based learning control model. We propose in-hand-view-sensitive Newtonian variational autoencoder (ihVS-NVAE), which employs an RGB camera to obtain in-hand postures of objects. We demonstrate that our model, trained for a single object-placement task, can handle sequential tasks without additional training. To evaluate efficacy of the proposed model, we employed a real robot to perform sequential industrial box-packing of multiple objects. Results showed that the proposed model achieved a 100% success rate in industrial box-packing tasks, thereby outperforming the state-of-the-art and conventional approaches, underscoring its superior effectiveness and potential in industrial tasks.
Learning Compliant Stiffness by Impedance Control-Aware Task Segmentation and Multi-objective Bayesian Optimization with Priors
Jul 28, 2023



Rather than traditional position control, impedance control is preferred to ensure the safe operation of industrial robots programmed from demonstrations. However, variable stiffness learning studies have focused on task performance rather than safety (or compliance). Thus, this paper proposes a novel stiffness learning method to satisfy both task performance and compliance requirements. The proposed method optimizes the task and compliance objectives (T/C objectives) simultaneously via multi-objective Bayesian optimization. We define the stiffness search space by segmenting a demonstration into task phases, each with constant responsible stiffness. The segmentation is performed by identifying impedance control-aware switching linear dynamics (IC-SLD) from the demonstration. We also utilize the stiffness obtained by proposed IC-SLD as priors for efficient optimization. Experiments on simulated tasks and a real robot demonstrate that IC-SLD-based segmentation and the use of priors improve the optimization efficiency compared to existing baseline methods.
Patch-based Object-centric Transformers for Efficient Video Generation
Jun 19, 2022
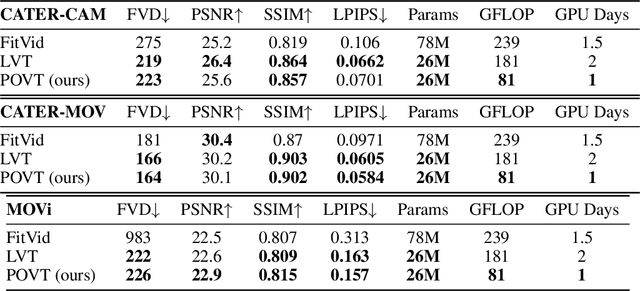
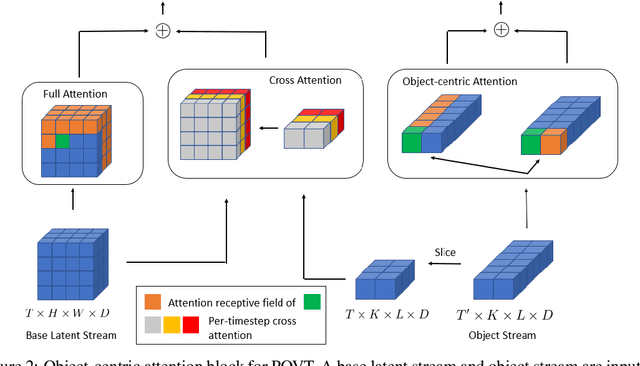

In this work, we present Patch-based Object-centric Video Transformer (POVT), a novel region-based video generation architecture that leverages object-centric information to efficiently model temporal dynamics in videos. We build upon prior work in video prediction via an autoregressive transformer over the discrete latent space of compressed videos, with an added modification to model object-centric information via bounding boxes. Due to better compressibility of object-centric representations, we can improve training efficiency by allowing the model to only access object information for longer horizon temporal information. When evaluated on various difficult object-centric datasets, our method achieves better or equal performance to other video generation models, while remaining computationally more efficient and scalable. In addition, we show that our method is able to perform object-centric controllability through bounding box manipulation, which may aid downstream tasks such as video editing, or visual planning. Samples are available at https://sites.google.com/view/povt-public
Multi-View Dreaming: Multi-View World Model with Contrastive Learning
Mar 15, 2022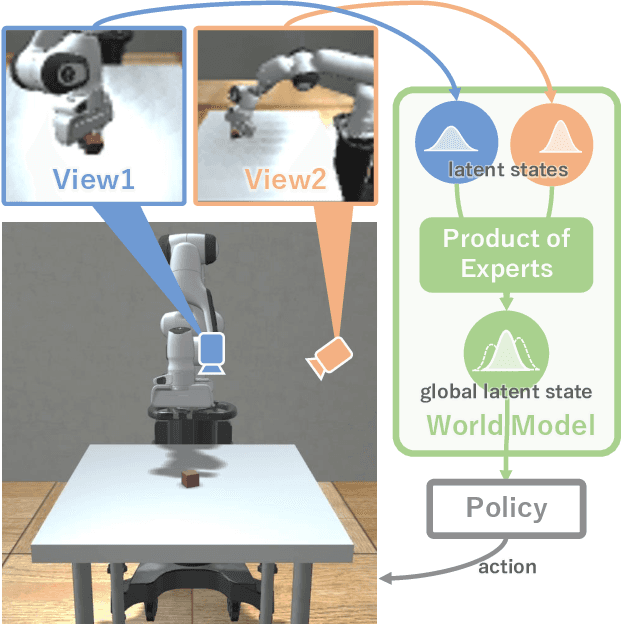
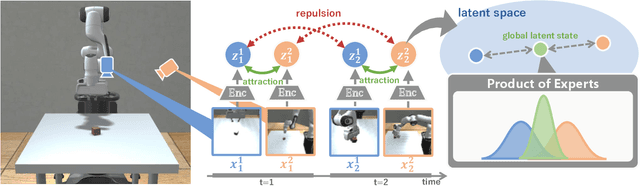
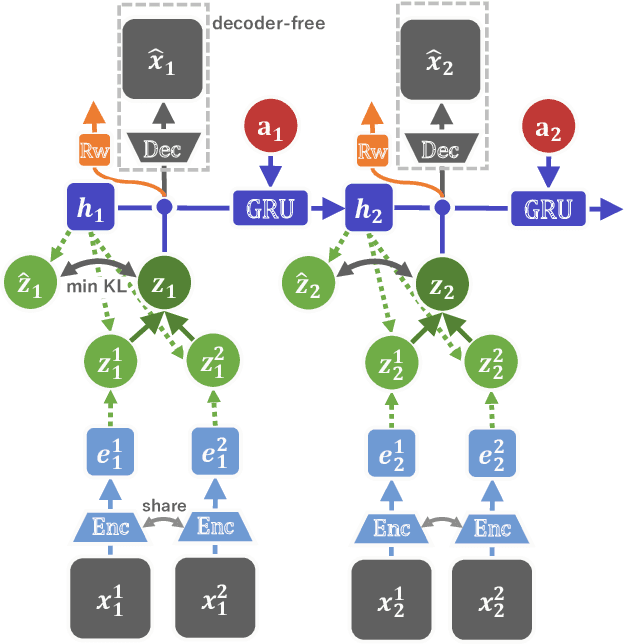
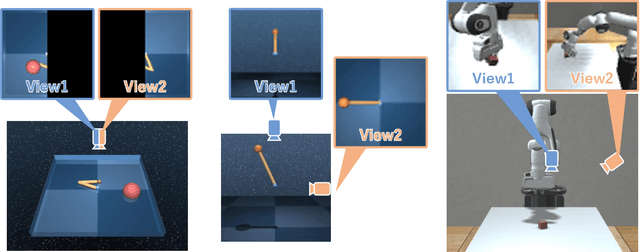
In this paper, we propose Multi-View Dreaming, a novel reinforcement learning agent for integrated recognition and control from multi-view observations by extending Dreaming. Most current reinforcement learning method assumes a single-view observation space, and this imposes limitations on the observed data, such as lack of spatial information and occlusions. This makes obtaining ideal observational information from the environment difficult and is a bottleneck for real-world robotics applications. In this paper, we use contrastive learning to train a shared latent space between different viewpoints, and show how the Products of Experts approach can be used to integrate and control the probability distributions of latent states for multiple viewpoints. We also propose Multi-View DreamingV2, a variant of Multi-View Dreaming that uses a categorical distribution to model the latent state instead of the Gaussian distribution. Experiments show that the proposed method outperforms simple extensions of existing methods in a realistic robot control task.
Tactile-Sensitive NewtonianVAE for High-Accuracy Industrial Connector-Socket Insertion
Mar 10, 2022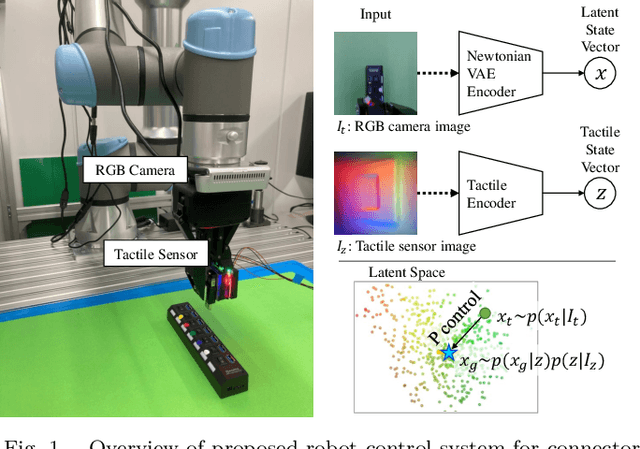
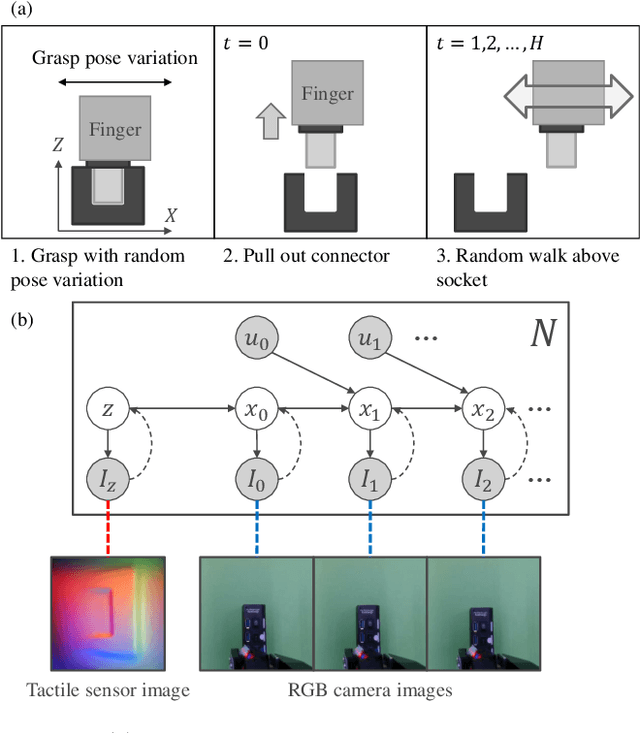
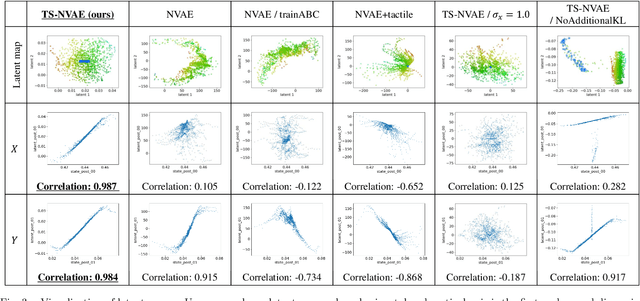
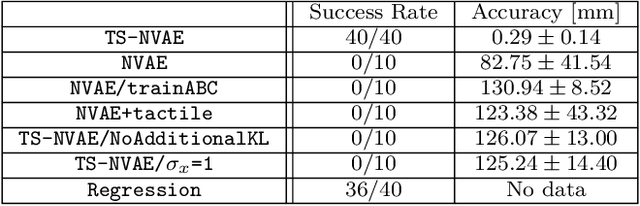
An industrial connector-socket insertion task requires sub-millimeter positioning and compensation of grasp pose of a connector. Thus high accurate estimation of relative pose between socket and connector is a key factor to achieve the task. World models are promising technology for visuo-motor control. They obtain appropriate state representation for control to jointly optimize feature extraction and latent dynamics model. Recent study shows NewtonianVAE, which is a kind of the world models, acquires latent space which is equivalent to mapping from images to physical coordinate. Proportional control can be achieved in the latent space of NewtonianVAE. However, application of NewtonianVAE to high accuracy industrial tasks in physical environments is open problem. Moreover, there is no general frameworks to compensate goal position in the obtained latent space considering the grasp pose. In this work, we apply NewtonianVAE to USB connector insertion with grasp pose variation in the physical environments. We adopt a GelSight type tactile sensor and estimate insertion position compensated by the grasp pose of the connector. Our method trains the latent space in an end-to-end manner, and simple proportional control is available. Therefore, it requires no additional engineering and annotation. Experimental results show that the proposed method, Tactile-Sensitive NewtonianVAE, outperforms naive combination of regression-based grasp pose estimator and coordinate transformation. Moreover, we reveal the original NewtonianVAE does not work in some situation, and demonstrate that domain knowledge induction improves model accuracy. This domain knowledge is easy to be known from specification of robots or measurement.
Domain-Adversarial and -Conditional State Space Model for Imitation Learning
Jan 31, 2020
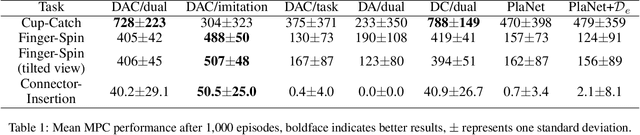
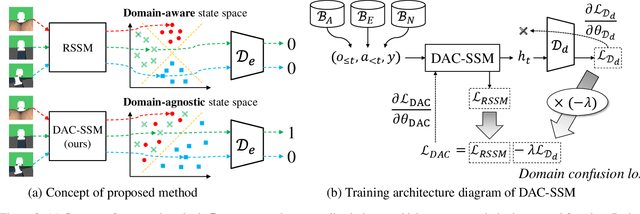

State representation learning (SRL) in partially observable Markov decision processes has been studied to learn abstract features of data useful for robot control tasks. For SRL, acquiring domain-agnostic states is essential for achieving efficient imitation learning (IL). Without these states, IL is hampered by domain-dependent information useless for control. However, existing methods fail to remove such disturbances from the states when the data from experts and agents show large domain shifts. To overcome this issue, we propose a domain-adversarial and -conditional state space model (DAC-SSM) that enables control systems to obtain domain-agnostic and task- and dynamics-aware states. DAC-SSM jointly optimizes the state inference, observation reconstruction, forward dynamics, and reward models. To remove domain-dependent information from the states, the model is trained with domain discriminators in an adversarial manner, and the reconstruction is conditioned on domain labels. We experimentally evaluated the model predictive control performance via IL for continuous control of sparse reward tasks in simulators and compared it with the performance of the existing SRL method. The agents from DAC-SSM achieved performance comparable to experts and more than twice the baselines. We conclude domain-agnostic states are essential for IL that has large domain shifts and can be obtained using DAC-SSM.