 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing the Power of Multi-Task Pretraining for Ground-Truth Level Natural Language Explanations
Dec 08, 2022Natural language explanations promise to offer intuitively understandable explanations of a neural network's decision process in complex vision-language tasks, as pursued in recent VL-NLE models. While current models offer impressive performance on task accuracy and explanation plausibility, they suffer from a range of issues: Some models feature a modular design where the explanation generation module is poorly integrated with a separate module for task-answer prediction, employ backbone models trained on limited sets of tasks, or incorporate ad hoc solutions to increase performance on single datasets. We propose to evade these limitations by applying recent advances in large-scale multi-task pretraining of generative Transformer models to the problem of VL-NLE tasks. Our approach outperforms recent models by a large margin, with human annotators preferring the generated explanations over the ground truth in two out of three evaluated datasets. As a novel challenge in VL-NLE research, we propose the problem of multi-task VL-NLE and show that jointly training on multiple tasks can increase the explanation quality. We discuss the ethical implications of high-quality NLE generation and other issues in recent VL-NLE research.
Neuro-Symbolic Spatio-Temporal Reasoning
Nov 28, 2022Knowledge about space and time is necessary to solve problems in the physical world: An AI agent situated in the physical world and interacting with objects often needs to reason about positions of and relations between objects; and as soon as the agent plans its actions to solve a task, it needs to consider the temporal aspect (e.g., what actions to perform over time). Spatio-temporal knowledge, however, is required beyond interacting with the physical world, and is also often transferred to the abstract world of concepts through analogies and metaphors (e.g., "a threat that is hanging over our heads"). As spatial and temporal reasoning is ubiquitous, different attempts have been made to integrate this into AI systems. In the area of knowledge representation, spatial and temporal reasoning has been largely limited to modeling objects and relations and developing reasoning methods to verify statements about objects and relations. On the other hand, neural network researchers have tried to teach models to learn spatial relations from data with limited reasoning capabilities. Bridging the gap between these two approaches in a mutually beneficial way could allow us to tackle many complex real-world problems, such as natural language processing, visual question answering, and semantic image segmentation. In this chapter, we view this integration problem from the perspective of Neuro-Symbolic AI. Specifically, we propose a synergy between logical reasoning and machine learning that will be grounded on spatial and temporal knowledge. Describing some successful applications, remaining challenges, and evaluation datasets pertaining to this direction is the main topic of this contribution.
Introspection-based Explainable Reinforcement Learning in Episodic and Non-episodic Scenarios
Nov 23, 2022



With the increasing presence of robotic systems and human-robot environments in today's society, understanding the reasoning behind actions taken by a robot is becoming more important. To increase this understanding, users are provided with explanations as to why a specific action was taken. Among other effects, these explanations improve the trust of users in their robotic partners. One option for creating these explanations is an introspection-based approach which can be used in conjunction with reinforcement learning agents to provide probabilities of success. These can in turn be used to reason about the actions taken by the agent in a human-understandable fashion. In this work, this introspection-based approach is developed and evaluated further on the basis of an episodic and a non-episodic robotics simulation task. Furthermore, an additional normalization step to the Q-values is proposed, which enables the usage of the introspection-based approach on negative and comparatively small Q-values. Results obtained show the viability of introspection for episodic robotics tasks and, additionally, that the introspection-based approach can be used to generate explanations for the actions taken in a non-episodic robotics environment as well.
Visually Grounded Commonsense Knowledge Acquisition
Nov 22, 2022



Large-scale commonsense knowledge bases empower a broad range of AI applications, where the automatic extraction of commonsense knowledge (CKE) is a fundamental and challenging problem. CKE from text is known for suffering from the inherent sparsity and reporting bias of commonsense in text. Visual perception, on the other hand, contains rich commonsense knowledge about real-world entities, e.g., (person, can_hold, bottle), which can serve as promising sources for acquiring grounded commonsense knowledge. In this work, we present CLEVER, which formulates CKE as a distantly supervised multi-instance learning problem, where models learn to summarize commonsense relations from a bag of images about an entity pair without any human annotation on image instances. To address the problem, CLEVER leverages vision-language pre-training models for deep understanding of each image in the bag, and selects informative instances from the bag to summarize commonsense entity relations via a novel contrastive attention mechanism. Comprehensive experimental results in held-out and human evaluation show that CLEVER can extract commonsense knowledge in promising quality, outperforming pre-trained language model-based methods by 3.9 AUC and 6.4 mAUC points. The predicted commonsense scores show strong correlation with human judgment with a 0.78 Spearman coefficient. Moreover, the extracted commonsense can also be grounded into images with reasonable interpretability. The data and codes can be obtained at https://github.com/thunlp/CLEVER.
Data Augmentation with Unsupervised Speaking Style Transfer for Speech Emotion Recognition
Nov 16, 2022



Currently, the performance of Speech Emotion Recognition (SER) systems is mainly constrained by the absence of large-scale labelled corpora. Data augmentation is regarded as a promising approach, which borrows methods from Automatic Speech Recognition (ASR), for instance, perturbation on speed and pitch, or generating emotional speech utilizing generative adversarial networks. In this paper, we propose EmoAug, a novel style transfer model to augment emotion expressions, in which a semantic encoder and a paralinguistic encoder represent verbal and non-verbal information respectively. Additionally, a decoder reconstructs speech signals by conditioning on the aforementioned two information flows in an unsupervised fashion. Once training is completed, EmoAug enriches expressions of emotional speech in different prosodic attributes, such as stress, rhythm and intensity, by feeding different styles into the paralinguistic encoder. In addition, we can also generate similar numbers of samples for each class to tackle the data imbalance issue. Experimental results on the IEMOCAP dataset demonstrate that EmoAug can successfully transfer different speaking styles while retaining the speaker identity and semantic content. Furthermore, we train a SER model with data augmented by EmoAug and show that it not only surpasses the state-of-the-art supervised and self-supervised methods but also overcomes overfitting problems caused by data imbalance. Some audio samples can be found on our demo website.
Learning to Autonomously Reach Objects with NICO and Grow-When-Required Networks
Oct 17, 2022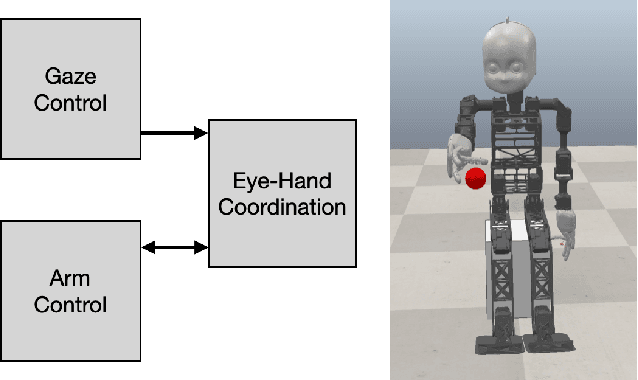
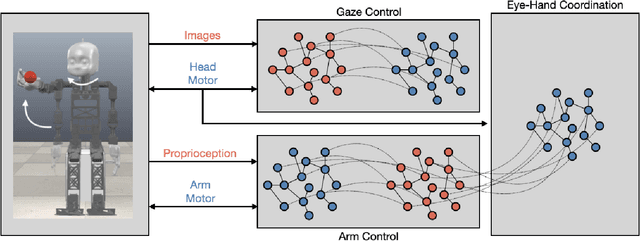
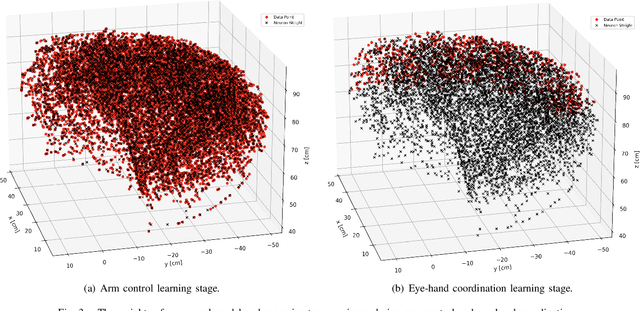
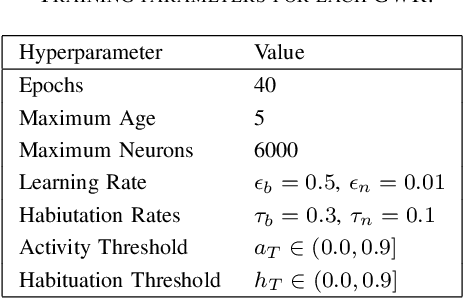
The act of reaching for an object is a fundamental yet complex skill for a robotic agent, requiring a high degree of visuomotor control and coordination. In consideration of dynamic environments, a robot capable of autonomously adapting to novel situations is desired. In this paper, a developmental robotics approach is used to autonomously learn visuomotor coordination on the NICO (Neuro-Inspired COmpanion) platform, for the task of object reaching. The robot interacts with its environment and learns associations between motor commands and temporally correlated sensory perceptions based on Hebbian learning. Multiple Grow-When-Required (GWR) networks are used to learn increasingly more complex motoric behaviors, by first learning how to direct the gaze towards a visual stimulus, followed by learning motor control of the arm, and finally learning how to reach for an object using eye-hand coordination. We demonstrate that the model is able to deal with an unforeseen mechanical change in the NICO's body, showing the adaptability of the proposed approach. In evaluations of our approach, we show that the humanoid robot NICO is able to reach objects with a 76% success rate.
Judging by the Look: The Impact of Robot Gaze Strategies on Human Cooperation
Aug 25, 2022
Human eye gaze plays an important role in delivering information, communicating intent, and understanding others' mental states. Previous research shows that a robot's gaze can also affect humans' decision-making and strategy during an interaction. However, limited studies have trained humanoid robots on gaze-based data in human-robot interaction scenarios. Considering gaze impacts the naturalness of social exchanges and alters the decision process of an observer, it should be regarded as a crucial component in human-robot interaction. To investigate the impact of robot gaze on humans, we propose an embodied neural model for performing human-like gaze shifts. This is achieved by extending a social attention model and training it on eye-tracking data, collected by watching humans playing a game. We will compare human behavioral performances in the presence of a robot adopting different gaze strategies in a human-human cooperation game.
Intelligent problem-solving as integrated hierarchical reinforcement learning
Aug 18, 2022According to cognitive psychology and related disciplines, the development of complex problem-solving behaviour in biological agents depends on hierarchical cognitive mechanisms. Hierarchical reinforcement learning is a promising computational approach that may eventually yield comparable problem-solving behaviour in artificial agents and robots. However, to date the problem-solving abilities of many human and non-human animals are clearly superior to those of artificial systems. Here, we propose steps to integrate biologically inspired hierarchical mechanisms to enable advanced problem-solving skills in artificial agents. Therefore, we first review the literature in cognitive psychology to highlight the importance of compositional abstraction and predictive processing. Then we relate the gained insights with contemporary hierarchical reinforcement learning methods. Interestingly, our results suggest that all identified cognitive mechanisms have been implemented individually in isolated computational architectures, raising the question of why there exists no single unifying architecture that integrates them. As our final contribution, we address this question by providing an integrative perspective on the computational challenges to develop such a unifying architecture. We expect our results to guide the development of more sophisticated cognitively inspired hierarchical machine learning architectures.
* Published as accepted article in Nature Machine Intelligence: https://www.nature.com/articles/s42256-021-00433-9. arXiv admin note: substantial text overlap with arXiv:2012.10147
Impact Makes a Sound and Sound Makes an Impact: Sound Guides Representations and Explorations
Aug 04, 2022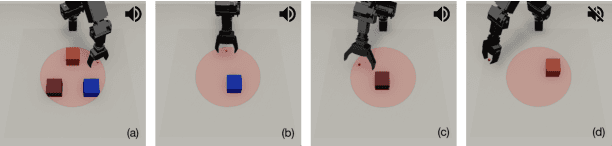
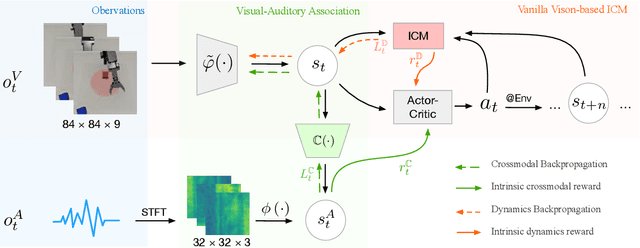
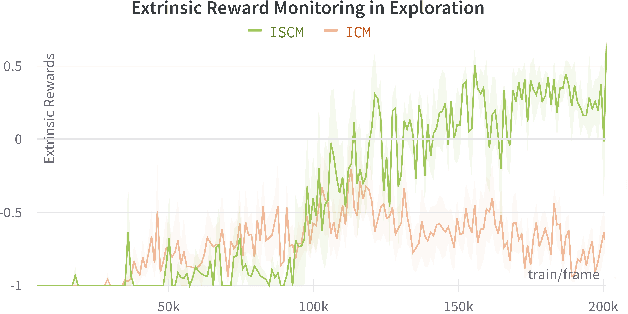
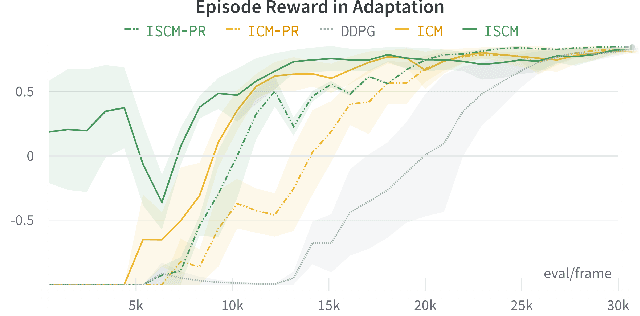
Sound is one of the most informative and abundant modalities in the real world while being robust to sense without contacts by small and cheap sensors that can be placed on mobile devices. Although deep learning is capable of extracting information from multiple sensory inputs, there has been little use of sound for the control and learning of robotic actions. For unsupervised reinforcement learning, an agent is expected to actively collect experiences and jointly learn representations and policies in a self-supervised way. We build realistic robotic manipulation scenarios with physics-based sound simulation and propose the Intrinsic Sound Curiosity Module (ISCM). The ISCM provides feedback to a reinforcement learner to learn robust representations and to reward a more efficient exploration behavior. We perform experiments with sound enabled during pre-training and disabled during adaptation, and show that representations learned by ISCM outperform the ones by vision-only baselines and pre-trained policies can accelerate the learning process when applied to downstream tasks.
Learning Flexible Translation between Robot Actions and Language Descriptions
Jul 15, 2022
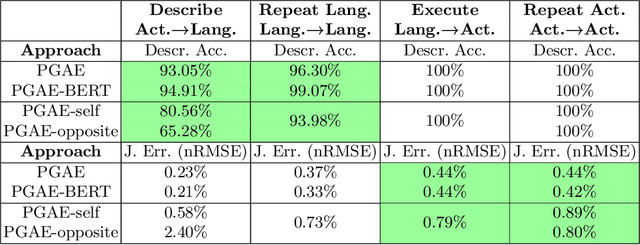

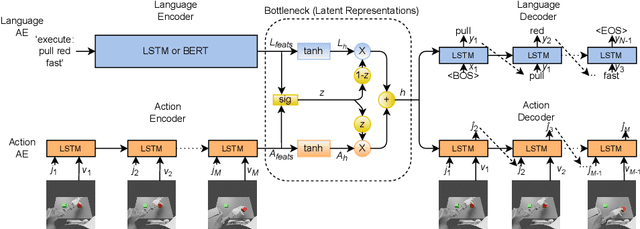
Handling various robot action-language translation tasks flexibly is an essential requirement for natural interaction between a robot and a human. Previous approaches require change in the configuration of the model architecture per task during inference, which undermines the premise of multi-task learning. In this work, we propose the paired gated autoencoders (PGAE) for flexible translation between robot actions and language descriptions in a tabletop object manipulation scenario. We train our model in an end-to-end fashion by pairing each action with appropriate descriptions that contain a signal informing about the translation direction. During inference, our model can flexibly translate from action to language and vice versa according to the given language signal. Moreover, with the option to use a pretrained language model as the language encoder, our model has the potential to recognise unseen natural language input. Another capability of our model is that it can recognise and imitate actions of another agent by utilising robot demonstrations. The experiment results highlight the flexible bidirectional translation capabilities of our approach alongside with the ability to generalise to the actions of the opposite-sitting agent.