 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartially Observed Structural Causal Models
May 05, 2026Here we introduce Partially Observed Structural Causal Models (POSCMs) that formalize causal systems where latent contexts co-determine both the interaction structure and downstream mechanisms on observed variables. POSCMs provide an extension of structural causal models (SCMs), as a self-contained causal modeling framework for endogenous graphs, allowing for an intervention hierarchy spanning node- and edge-level context and endogenous variable interventions. To enable surgical edge interventions, we adopt a Kolmogorov-Arnold-Sprecher edge-functional decomposition, an existence theorem for representing each node mechanism as a sum of univariate functions of its parents, yielding an explicit parametrization of dyadic functional contributions. We provide an identifiability theory that clarifies which intervention families would suffice to disentangle structure formation from mechanisms. We empirically validate these predictions in a biophysically detailed virtual human retina simulator, constructing intervention protocols that (i) reproduce the non-identifiability predicted when context is latent and no context-level interventions are available, (ii) exhibit structure-mechanism confounding under latent edges when only node interventions are observed, and (iii) recover synaptic input-output relationships via targeted node interventions, consistent with our positive kernel identifiability result. Our work generalizes SCMs in a way that allows it to work in a world closer to the one we live in.
Dynamics-Aligned Shared Hypernetworks for Zero-Shot Actuator Inversion
Feb 06, 2026Zero-shot generalization in contextual reinforcement learning remains a core challenge, particularly when the context is latent and must be inferred from data. A canonical failure mode is actuator inversion, where identical actions produce opposite physical effects under a latent binary context. We propose DMA*-SH, a framework where a single hypernetwork, trained solely via dynamics prediction, generates a small set of adapter weights shared across the dynamics model, policy, and action-value function. This shared modulation imparts an inductive bias matched to actuator inversion, while input/output normalization and random input masking stabilize context inference, promoting directionally concentrated representations. We provide theoretical support via an expressivity separation result for hypernetwork modulation, and a variance decomposition with policy-gradient variance bounds that formalize how within-mode compression improves learning under actuator inversion. For evaluation, we introduce the Actuator Inversion Benchmark (AIB), a suite of environments designed to isolate discontinuous context-to-dynamics interactions. On AIB's held-out actuator-inversion tasks, DMA*-SH achieves zero-shot generalization, outperforming domain randomization by 111.8% and surpassing a standard context-aware baseline by 16.1%.
Rethinking Vision Transformer for Object Centric Foundation Models
Feb 04, 2025



Recent state-of-the-art object segmentation mechanisms, such as the Segment Anything Model (SAM) and FastSAM, first encode the full image over several layers and then focus on generating the mask for one particular object or area. We present an off-grid Fovea-Like Input Patching (FLIP) approach, which selects image input and encodes it from the beginning in an object-focused manner. While doing so, it separates locational encoding from an object-centric perceptual code. FLIP is more data-efficient and yields improved segmentation performance when masking relatively small objects in high-resolution visual scenes. On standard benchmarks such as Hypersim, KITTI-360, and OpenImages, FLIP achieves Intersection over Union (IoU) scores that approach the performance of SAM with much less compute effort. It surpasses FastSAM in all IoU measurements. We also introduce an additional semi-natural but highly intuitive dataset where FLIP outperforms SAM and FastSAM overall and particularly on relatively small objects. Seeing that FLIP is an end-to-end object-centric segmentation approach, it has high potential particularly for applications that benefit from computationally efficient, spatially highly selective object tracking.
Quick and Accurate Affordance Learning
May 13, 2024



Infants learn actively in their environments, shaping their own learning curricula. They learn about their environments' affordances, that is, how local circumstances determine how their behavior can affect the environment. Here we model this type of behavior by means of a deep learning architecture. The architecture mediates between global cognitive map exploration and local affordance learning. Inference processes actively move the simulated agent towards regions where they expect affordance-related knowledge gain. We contrast three measures of uncertainty to guide this exploration: predicted uncertainty of a model, standard deviation between the means of several models (SD), and the Jensen-Shannon Divergence (JSD) between several models. We show that the first measure gets fooled by aleatoric uncertainty inherent in the environment, while the two other measures focus learning on epistemic uncertainty. JSD exhibits the most balanced exploration strategy. From a computational perspective, our model suggests three key ingredients for coordinating the active generation of learning curricula: (1) Navigation behavior needs to be coordinated with local motor behavior for enabling active affordance learning. (2) Affordances need to be encoded locally for acquiring generalized knowledge. (3) Effective active affordance learning mechanisms should use density comparison techniques for estimating expected knowledge gain. Future work may seek collaborations with developmental psychology to model active play in children in more realistic scenarios.
Looping LOCI: Developing Object Permanence from Videos
Oct 16, 2023Recent compositional scene representation learning models have become remarkably good in segmenting and tracking distinct objects within visual scenes. Yet, many of these models require that objects are continuously, at least partially, visible. Moreover, they tend to fail on intuitive physics tests, which infants learn to solve over the first months of their life. Our goal is to advance compositional scene representation algorithms with an embedded algorithm that fosters the progressive learning of intuitive physics, akin to infant development. As a fundamental component for such an algorithm, we introduce Loci-Looped, which advances a recently published unsupervised object location, identification, and tracking neural network architecture (Loci, Traub et al., ICLR 2023) with an internal processing loop. The loop is designed to adaptively blend pixel-space information with anticipations yielding information-fused activities as percepts. Moreover, it is designed to learn compositional representations of both individual object dynamics and between-objects interaction dynamics. We show that Loci-Looped learns to track objects through extended periods of object occlusions, indeed simulating their hidden trajectories and anticipating their reappearance, without the need for an explicit history buffer. We even find that Loci-Looped surpasses state-of-the-art models on the ADEPT and the CLEVRER dataset, when confronted with object occlusions or temporary sensory data interruptions. This indicates that Loci-Looped is able to learn the physical concepts of object permanence and inertia in a fully unsupervised emergent manner. We believe that even further architectural advancements of the internal loop - also in other compositional scene representation learning models - can be developed in the near future.
Loci-Segmented: Improving Scene Segmentation Learning
Oct 16, 2023



Slot-oriented processing approaches for compositional scene representation have recently undergone a tremendous development. We present Loci-Segmented (Loci-s), an advanced scene segmentation neural network that extends the slot-based location and identity tracking architecture Loci (Traub et al., ICLR 2023). The main advancements are (i) the addition of a pre-trained dynamic background module; (ii) a hyper-convolution encoder module, which enables object-focused bottom-up processing; and (iii) a cascaded decoder module, which successively generates object masks, masked depth maps, and masked, depth-map-informed RGB reconstructions. The background module features the learning of both a foreground identifying module and a background re-generator. We further improve performance via (a) the integration of depth information as well as improved slot assignments via (b) slot-location-entity regularization and (b) a prior segmentation network. Even without these latter improvements, the results reveal superior segmentation performance in the MOVi datasets and in another established dataset collection. With all improvements, Loci-s achieves a 32% better intersection over union (IoU) score in MOVi-E than the previous best. We furthermore show that Loci-s generates well-interpretable latent representations. We believe that these representations may serve as a foundation-model-like interpretable basis for solving downstream tasks, such as grounding language and context- and goal-conditioned event processing.
Inductive biases in deep learning models for weather prediction
Apr 06, 2023Deep learning has recently gained immense popularity in the Earth sciences as it enables us to formulate purely data-driven models of complex Earth system processes. Deep learning-based weather prediction (DLWP) models have made significant progress in the last few years, achieving forecast skills comparable to established numerical weather prediction (NWP) models with comparatively lesser computational costs. In order to train accurate, reliable, and tractable DLWP models with several millions of parameters, the model design needs to incorporate suitable inductive biases that encode structural assumptions about the data and modelled processes. When chosen appropriately, these biases enable faster learning and better generalisation to unseen data. Although inductive biases play a crucial role in successful DLWP models, they are often not stated explicitly and how they contribute to model performance remains unclear. Here, we review and analyse the inductive biases of six state-of-the-art DLWP models, involving a deeper look at five key design elements: input data, forecasting objective, loss components, layered design of the deep learning architectures, and optimisation methods. We show how the design choices made in each of the five design elements relate to structural assumptions. Given recent developments in the broader DL community, we anticipate that the future of DLWP will likely see a wider use of foundation models -- large models pre-trained on big databases with self-supervised learning -- combined with explicit physics-informed inductive biases that allow the models to provide competitive forecasts even at the more challenging subseasonal-to-seasonal scales.
Intelligent problem-solving as integrated hierarchical reinforcement learning
Aug 18, 2022According to cognitive psychology and related disciplines, the development of complex problem-solving behaviour in biological agents depends on hierarchical cognitive mechanisms. Hierarchical reinforcement learning is a promising computational approach that may eventually yield comparable problem-solving behaviour in artificial agents and robots. However, to date the problem-solving abilities of many human and non-human animals are clearly superior to those of artificial systems. Here, we propose steps to integrate biologically inspired hierarchical mechanisms to enable advanced problem-solving skills in artificial agents. Therefore, we first review the literature in cognitive psychology to highlight the importance of compositional abstraction and predictive processing. Then we relate the gained insights with contemporary hierarchical reinforcement learning methods. Interestingly, our results suggest that all identified cognitive mechanisms have been implemented individually in isolated computational architectures, raising the question of why there exists no single unifying architecture that integrates them. As our final contribution, we address this question by providing an integrative perspective on the computational challenges to develop such a unifying architecture. We expect our results to guide the development of more sophisticated cognitively inspired hierarchical machine learning architectures.
* Published as accepted article in Nature Machine Intelligence: https://www.nature.com/articles/s42256-021-00433-9. arXiv admin note: substantial text overlap with arXiv:2012.10147
Developing hierarchical anticipations via neural network-based event segmentation
Jun 04, 2022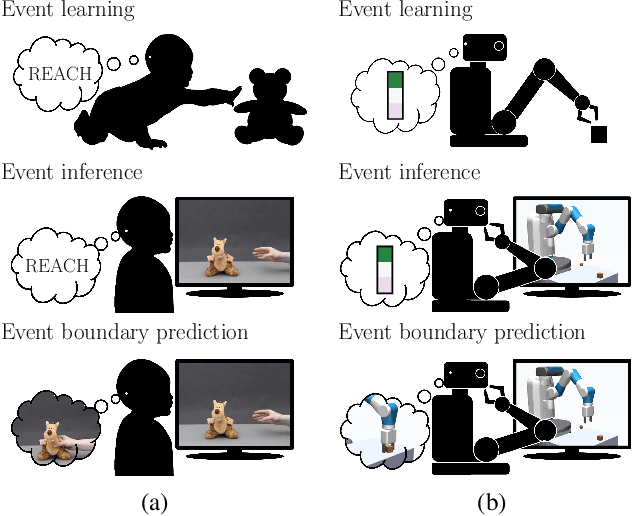
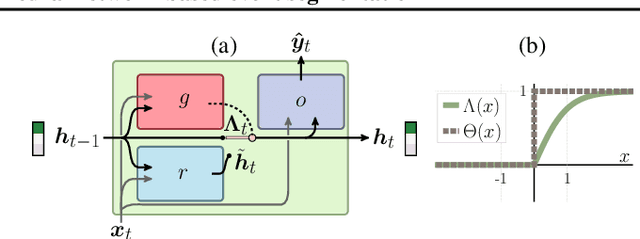
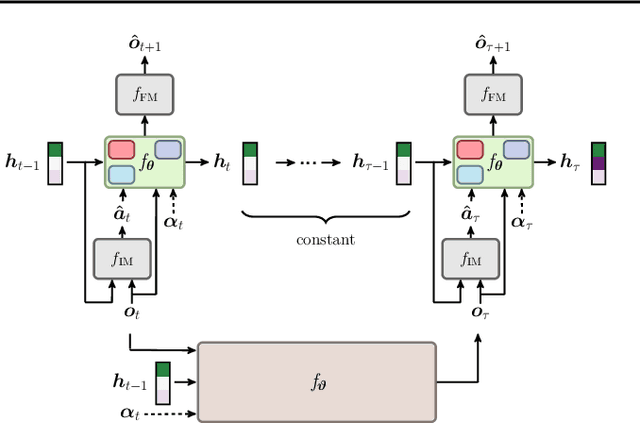
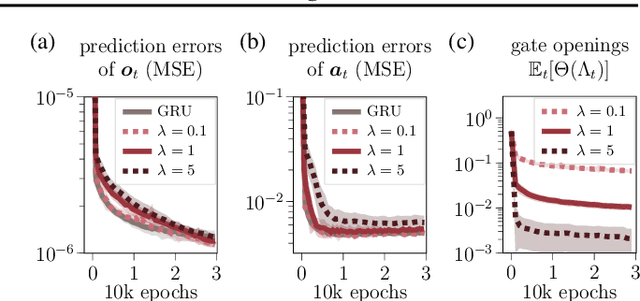
Humans can make predictions on various time scales and hierarchical levels. Thereby, the learning of event encodings seems to play a crucial role. In this work we model the development of hierarchical predictions via autonomously learned latent event codes. We present a hierarchical recurrent neural network architecture, whose inductive learning biases foster the development of sparsely changing latent state that compress sensorimotor sequences. A higher level network learns to predict the situations in which the latent states tend to change. Using a simulated robotic manipulator, we demonstrate that the system (i) learns latent states that accurately reflect the event structure of the data, (ii) develops meaningful temporal abstract predictions on the higher level, and (iii) generates goal-anticipatory behavior similar to gaze behavior found in eye-tracking studies with infants. The architecture offers a step towards autonomous, self-motivated learning of compressed hierarchical encodings of gathered experiences and the exploitation of these encodings for the generation of highly versatile, adaptive behavior.
Binding Dancers Into Attractors
Jun 01, 2022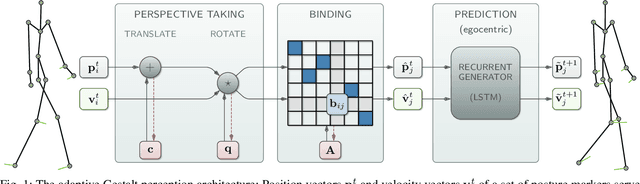
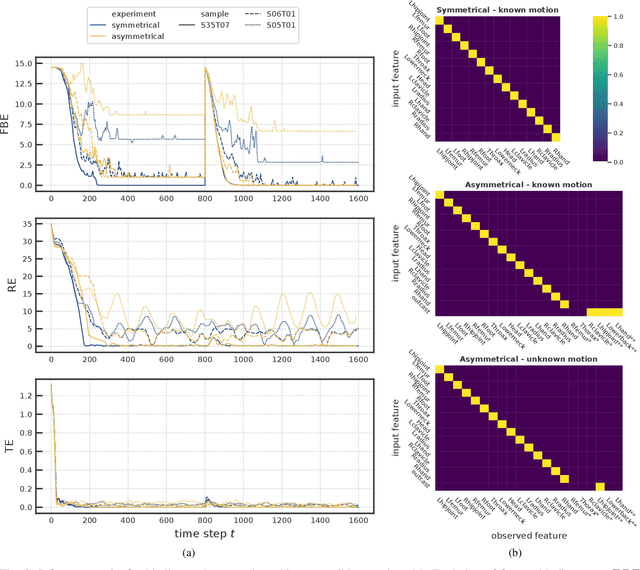
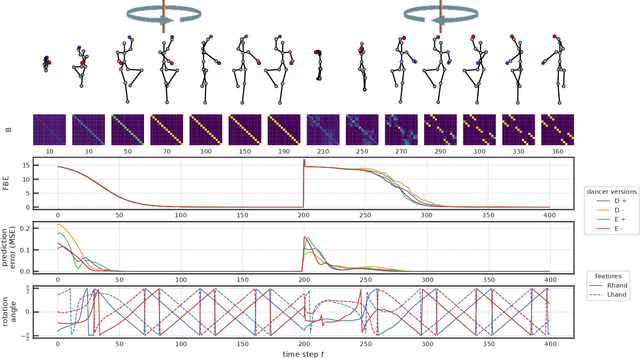

To effectively perceive and process observations in our environment, feature binding and perspective taking are crucial cognitive abilities. Feature binding combines observed features into one entity, called a Gestalt. Perspective taking transfers the percept into a canonical, observer-centered frame of reference. Here we propose a recurrent neural network model that solves both challenges. We first train an LSTM to predict 3D motion dynamics from a canonical perspective. We then present similar motion dynamics with novel viewpoints and feature arrangements. Retrospective inference enables the deduction of the canonical perspective. Combined with a robust mutual-exclusive softmax selection scheme, random feature arrangements are reordered and precisely bound into known Gestalt percepts. To corroborate evidence for the architecture's cognitive validity, we examine its behavior on the silhouette illusion, which elicits two competitive Gestalt interpretations of a rotating dancer. Our system flexibly binds the information of the rotating figure into the alternative attractors resolving the illusion's ambiguity and imagining the respective depth interpretation and the corresponding direction of rotation. We finally discuss the potential universality of the proposed mechanisms.