 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Brain MRI Foundation Models for the Clinic: Findings from the FOMO25 Challenge
Apr 13, 2026Clinical deployment of automated brain MRI analysis faces a fundamental challenge: clinical data is heterogeneous and noisy, and high-quality labels are prohibitively costly to obtain. Self-supervised learning (SSL) can address this by leveraging the vast amounts of unlabeled data produced in clinical workflows to train robust \textit{foundation models} that adapt out-of-domain with minimal supervision. However, the development of foundation models for brain MRI has been limited by small pretraining datasets and in-domain benchmarking focused on high-quality, research-grade data. To address this gap, we organized the FOMO25 challenge as a satellite event at MICCAI 2025. FOMO25 provided participants with a large pretraining dataset, FOMO60K, and evaluated models on data sourced directly from clinical workflows in few-shot and out-of-domain settings. Tasks covered infarct classification, meningioma segmentation, and brain age regression, and considered both models trained on FOMO60K (method track) and any data (open track). Nineteen foundation models from sixteen teams were evaluated using a standardized containerized pipeline. Results show that (a) self-supervised pretraining improves generalization on clinical data under domain shift, with the strongest models trained \textit{out-of-domain} surpassing supervised baselines trained \textit{in-domain}. (b) No single pretraining objective benefits all tasks: MAE favors segmentation, hybrid reconstruction-contrastive objectives favor classification, and (c) strong performance was achieved by small pretrained models, and improvements from scaling model size and training duration did not yield reliable benefits.
General Methods Make Great Domain-specific Foundation Models: A Case-study on Fetal Ultrasound
Jun 24, 2025With access to large-scale, unlabeled medical datasets, researchers are confronted with two questions: Should they attempt to pretrain a custom foundation model on this medical data, or use transfer-learning from an existing generalist model? And, if a custom model is pretrained, are novel methods required? In this paper we explore these questions by conducting a case-study, in which we train a foundation model on a large regional fetal ultrasound dataset of 2M images. By selecting the well-established DINOv2 method for pretraining, we achieve state-of-the-art results on three fetal ultrasound datasets, covering data from different countries, classification, segmentation, and few-shot tasks. We compare against a series of models pretrained on natural images, ultrasound images, and supervised baselines. Our results demonstrate two key insights: (i) Pretraining on custom data is worth it, even if smaller models are trained on less data, as scaling in natural image pretraining does not translate to ultrasound performance. (ii) Well-tuned methods from computer vision are making it feasible to train custom foundation models for a given medical domain, requiring no hyperparameter tuning and little methodological adaptation. Given these findings, we argue that a bias towards methodological innovation should be avoided when developing domain specific foundation models under common computational resource constraints.
A large-scale heterogeneous 3D magnetic resonance brain imaging dataset for self-supervised learning
Jun 17, 2025We present FOMO60K, a large-scale, heterogeneous dataset of 60,529 brain Magnetic Resonance Imaging (MRI) scans from 13,900 sessions and 11,187 subjects, aggregated from 16 publicly available sources. The dataset includes both clinical- and research-grade images, multiple MRI sequences, and a wide range of anatomical and pathological variability, including scans with large brain anomalies. Minimal preprocessing was applied to preserve the original image characteristics while reducing barriers to entry for new users. Accompanying code for self-supervised pretraining and finetuning is provided. FOMO60K is intended to support the development and benchmarking of self-supervised learning methods in medical imaging at scale.
Unsupervised Detection of Fetal Brain Anomalies using Denoising Diffusion Models
Aug 07, 2024Congenital malformations of the brain are among the most common fetal abnormalities that impact fetal development. Previous anomaly detection methods on ultrasound images are based on supervised learning, rely on manual annotations, and risk missing underrepresented categories. In this work, we frame fetal brain anomaly detection as an unsupervised task using diffusion models. To this end, we employ an inpainting-based Noise Agnostic Anomaly Detection approach that identifies the abnormality using diffusion-reconstructed fetal brain images from multiple noise levels. Our approach only requires normal fetal brain ultrasound images for training, addressing the limited availability of abnormal data. Our experiments on a real-world clinical dataset show the potential of using unsupervised methods for fetal brain anomaly detection. Additionally, we comprehensively evaluate how different noise types affect diffusion models in the fetal anomaly detection domain.
AMAES: Augmented Masked Autoencoder Pretraining on Public Brain MRI Data for 3D-Native Segmentation
Aug 01, 2024This study investigates the impact of self-supervised pretraining of 3D semantic segmentation models on a large-scale, domain-specific dataset. We introduce BRAINS-45K, a dataset of 44,756 brain MRI volumes from public sources, the largest public dataset available, and revisit a number of design choices for pretraining modern segmentation architectures by simplifying and optimizing state-of-the-art methods, and combining them with a novel augmentation strategy. The resulting AMAES framework is based on masked-image-modeling and intensity-based augmentation reversal and balances memory usage, runtime, and finetuning performance. Using the popular U-Net and the recent MedNeXt architecture as backbones, we evaluate the effect of pretraining on three challenging downstream tasks, covering single-sequence, low-resource settings, and out-of-domain generalization. The results highlight that pretraining on the proposed dataset with AMAES significantly improves segmentation performance in the majority of evaluated cases, and that it is beneficial to pretrain the model with augmentations, despite pretraing on a large-scale dataset. Code and model checkpoints for reproducing results, as well as the BRAINS-45K dataset are available at \url{https://github.com/asbjrnmunk/amaes}.
Yucca: A Deep Learning Framework For Medical Image Analysis
Jul 29, 2024


Medical image analysis using deep learning frameworks has advanced healthcare by automating complex tasks, but many existing frameworks lack flexibility, modularity, and user-friendliness. To address these challenges, we introduce Yucca, an open-source AI framework available at https://github.com/Sllambias/yucca, designed specifically for medical imaging applications and built on PyTorch and PyTorch Lightning. Yucca features a three-tiered architecture: Functional, Modules, and Pipeline, providing a comprehensive and customizable solution. Evaluated across diverse tasks such as cerebral microbleeds detection, white matter hyperintensity segmentation, and hippocampus segmentation, Yucca achieves state-of-the-art results, demonstrating its robustness and versatility. Yucca offers a powerful, flexible, and user-friendly platform for medical image analysis, inviting community contributions to advance its capabilities and impact.
Learning semantic image quality for fetal ultrasound from noisy ranking annotation
Feb 13, 2024



We introduce the notion of semantic image quality for applications where image quality relies on semantic requirements. Working in fetal ultrasound, where ranking is challenging and annotations are noisy, we design a robust coarse-to-fine model that ranks images based on their semantic image quality and endow our predicted rankings with an uncertainty estimate. To annotate rankings on training data, we design an efficient ranking annotation scheme based on the merge sort algorithm. Finally, we compare our ranking algorithm to a number of state-of-the-art ranking algorithms on a challenging fetal ultrasound quality assessment task, showing the superior performance of our method on the majority of rank correlation metrics.
Benchmarking Faithfulness: Towards Accurate Natural Language Explanations in Vision-Language Tasks
Apr 03, 2023



With deep neural models increasingly permeating our daily lives comes a need for transparent and comprehensible explanations of their decision-making. However, most explanation methods that have been developed so far are not intuitively understandable for lay users. In contrast, natural language explanations (NLEs) promise to enable the communication of a model's decision-making in an easily intelligible way. While current models successfully generate convincing explanations, it is an open question how well the NLEs actually represent the reasoning process of the models - a property called faithfulness. Although the development of metrics to measure faithfulness is crucial to designing more faithful models, current metrics are either not applicable to NLEs or are not designed to compare different model architectures across multiple modalities. Building on prior research on faithfulness measures and based on a detailed rationale, we address this issue by proposing three faithfulness metrics: Attribution-Similarity, NLE-Sufficiency, and NLE-Comprehensiveness. The efficacy of the metrics is evaluated on the VQA-X and e-SNLI-VE datasets of the e-ViL benchmark for vision-language NLE generation by systematically applying modifications to the performant e-UG model for which we expect changes in the measured explanation faithfulness. We show on the e-SNLI-VE dataset that the removal of redundant inputs to the explanation-generation module of e-UG successively increases the model's faithfulness on the linguistic modality as measured by Attribution-Similarity. Further, our analysis demonstrates that NLE-Sufficiency and -Comprehensiveness are not necessarily correlated to Attribution-Similarity, and we discuss how the two metrics can be utilized to gain further insights into the explanation generation process.
Harnessing the Power of Multi-Task Pretraining for Ground-Truth Level Natural Language Explanations
Dec 08, 2022Natural language explanations promise to offer intuitively understandable explanations of a neural network's decision process in complex vision-language tasks, as pursued in recent VL-NLE models. While current models offer impressive performance on task accuracy and explanation plausibility, they suffer from a range of issues: Some models feature a modular design where the explanation generation module is poorly integrated with a separate module for task-answer prediction, employ backbone models trained on limited sets of tasks, or incorporate ad hoc solutions to increase performance on single datasets. We propose to evade these limitations by applying recent advances in large-scale multi-task pretraining of generative Transformer models to the problem of VL-NLE tasks. Our approach outperforms recent models by a large margin, with human annotators preferring the generated explanations over the ground truth in two out of three evaluated datasets. As a novel challenge in VL-NLE research, we propose the problem of multi-task VL-NLE and show that jointly training on multiple tasks can increase the explanation quality. We discuss the ethical implications of high-quality NLE generation and other issues in recent VL-NLE research.
Explain yourself! Effects of Explanations in Human-Robot Interaction
Apr 09, 2022

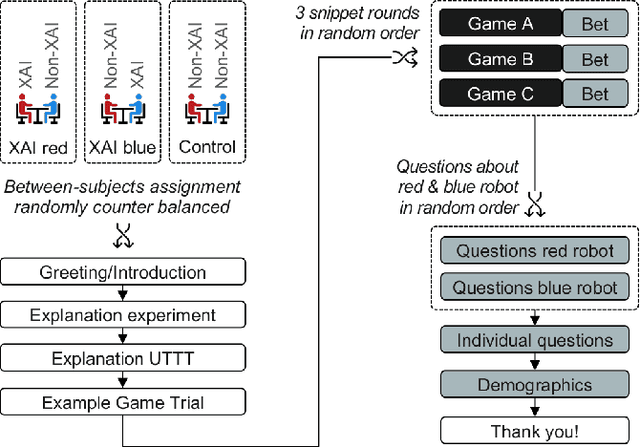
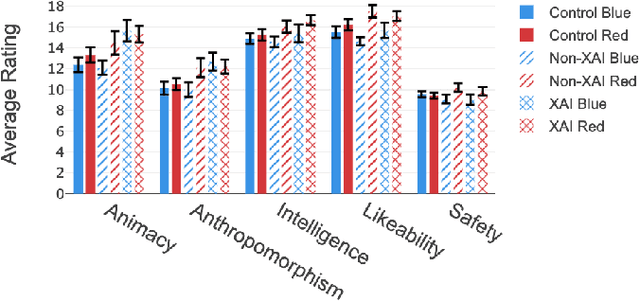
Recent developments in explainable artificial intelligence promise the potential to transform human-robot interaction: Explanations of robot decisions could affect user perceptions, justify their reliability, and increase trust. However, the effects on human perceptions of robots that explain their decisions have not been studied thoroughly. To analyze the effect of explainable robots, we conduct a study in which two simulated robots play a competitive board game. While one robot explains its moves, the other robot only announces them. Providing explanations for its actions was not sufficient to change the perceived competence, intelligence, likeability or safety ratings of the robot. However, the results show that the robot that explains its moves is perceived as more lively and human-like. This study demonstrates the need for and potential of explainable human-robot interaction and the wider assessment of its effects as a novel research direction.