 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSituation Graph Prediction: Structured Perspective Inference for User Modeling
Feb 10, 2026Perspective-Aware AI requires modeling evolving internal states--goals, emotions, contexts--not merely preferences. Progress is limited by a data bottleneck: digital footprints are privacy-sensitive and perspective states are rarely labeled. We propose Situation Graph Prediction (SGP), a task that frames perspective modeling as an inverse inference problem: reconstructing structured, ontology-aligned representations of perspective from observable multimodal artifacts. To enable grounding without real labels, we use a structure-first synthetic generation strategy that aligns latent labels and observable traces by design. As a pilot, we construct a dataset and run a diagnostic study using retrieval-augmented in-context learning as a proxy for supervision. In our study with GPT-4o, we observe a gap between surface-level extraction and latent perspective inference--indicating latent-state inference is harder than surface extraction under our controlled setting. Results suggest SGP is non-trivial and provide evidence for the structure-first data synthesis strategy.
Structured Personalization: Modeling Constraints as Matroids for Data-Minimal LLM Agents
Dec 10, 2025Personalizing Large Language Model (LLM) agents requires conditioning them on user-specific data, creating a critical trade-off between task utility and data disclosure. While the utility of adding user data often exhibits diminishing returns (i.e., submodularity), enabling near-optimal greedy selection, real-world personalization is complicated by structural constraints. These include logical dependencies (e.g., selecting fact A requires fact B), categorical quotas (e.g., select at most one writing style), and hierarchical rules (e.g., select at most two social media preferences, of which at most one can be for a professional network). These constraints violate the assumptions of standard subset selection algorithms. We propose a principled method to formally model such constraints. We introduce a compilation process that transforms a user's knowledge graph with dependencies into a set of abstract macro-facets. Our central result is a proof that common hierarchical and quota-based constraints over these macro-facets form a valid laminar matroid. This theoretical characterization lets us cast structured personalization as submodular maximization under a matroid constraint, enabling greedy with constant-factor guarantees (and (1-1/e) via continuous greedy) for a much richer and more realistic class of problems.
SSET: Swapping-Sliding Explanation for Time Series Classifiers in Affect Detection
Oct 16, 2024



Local explanation of machine learning (ML) models has recently received significant attention due to its ability to reduce ambiguities about why the models make specific decisions. Extensive efforts have been invested to address explainability for different data types, particularly images. However, the work on multivariate time series data is limited. A possible reason is that the conflation of time and other variables in time series data can cause the generated explanations to be incomprehensible to humans. In addition, some efforts on time series fall short of providing accurate explanations as they either ignore a context in the time domain or impose differentiability requirements on the ML models. Such restrictions impede their ability to provide valid explanations in real-world applications and non-differentiable ML settings. In this paper, we propose a swapping--sliding decision explanation for multivariate time series classifiers, called SSET. The proposal consists of swapping and sliding stages, by which salient sub-sequences causing significant drops in the prediction score are presented as explanations. In the former stage, the important variables are detected by swapping the series of interest with close train data from target classes. In the latter stage, the salient observations of these variables are explored by sliding a window over each time step. Additionally, the model measures the importance of different variables over time in a novel way characterized by multiple factors. We leverage SSET on affect detection domain where evaluations are performed on two real-world physiological time series datasets, WESAD and MAHNOB-HCI, and a deep convolutional classifier, CN-Waterfall. This classifier has shown superior performance to prior models to detect human affective states. Comparing SSET with several benchmarks, including LIME, integrated gradients, and Dynamask, we found..
CLEVR-POC: Reasoning-Intensive Visual Question Answering in Partially Observable Environments
Mar 05, 2024The integration of learning and reasoning is high on the research agenda in AI. Nevertheless, there is only a little attention to use existing background knowledge for reasoning about partially observed scenes to answer questions about the scene. Yet, we as humans use such knowledge frequently to infer plausible answers to visual questions (by eliminating all inconsistent ones). Such knowledge often comes in the form of constraints about objects and it tends to be highly domain or environment-specific. We contribute a novel benchmark called CLEVR-POC for reasoning-intensive visual question answering (VQA) in partially observable environments under constraints. In CLEVR-POC, knowledge in the form of logical constraints needs to be leveraged to generate plausible answers to questions about a hidden object in a given partial scene. For instance, if one has the knowledge that all cups are colored either red, green or blue and that there is only one green cup, it becomes possible to deduce the color of an occluded cup as either red or blue, provided that all other cups, including the green one, are observed. Through experiments, we observe that the low performance of pre-trained vision language models like CLIP (~ 22%) and a large language model (LLM) like GPT-4 (~ 46%) on CLEVR-POC ascertains the necessity for frameworks that can handle reasoning-intensive tasks where environment-specific background knowledge is available and crucial. Furthermore, our demonstration illustrates that a neuro-symbolic model, which integrates an LLM like GPT-4 with a visual perception network and a formal logical reasoner, exhibits exceptional performance on CLEVR-POC.
Neuro-Symbolic Spatio-Temporal Reasoning
Nov 28, 2022Knowledge about space and time is necessary to solve problems in the physical world: An AI agent situated in the physical world and interacting with objects often needs to reason about positions of and relations between objects; and as soon as the agent plans its actions to solve a task, it needs to consider the temporal aspect (e.g., what actions to perform over time). Spatio-temporal knowledge, however, is required beyond interacting with the physical world, and is also often transferred to the abstract world of concepts through analogies and metaphors (e.g., "a threat that is hanging over our heads"). As spatial and temporal reasoning is ubiquitous, different attempts have been made to integrate this into AI systems. In the area of knowledge representation, spatial and temporal reasoning has been largely limited to modeling objects and relations and developing reasoning methods to verify statements about objects and relations. On the other hand, neural network researchers have tried to teach models to learn spatial relations from data with limited reasoning capabilities. Bridging the gap between these two approaches in a mutually beneficial way could allow us to tackle many complex real-world problems, such as natural language processing, visual question answering, and semantic image segmentation. In this chapter, we view this integration problem from the perspective of Neuro-Symbolic AI. Specifically, we propose a synergy between logical reasoning and machine learning that will be grounded on spatial and temporal knowledge. Describing some successful applications, remaining challenges, and evaluation datasets pertaining to this direction is the main topic of this contribution.
Semantic Referee: A Neural-Symbolic Framework for Enhancing Geospatial Semantic Segmentation
Apr 30, 2019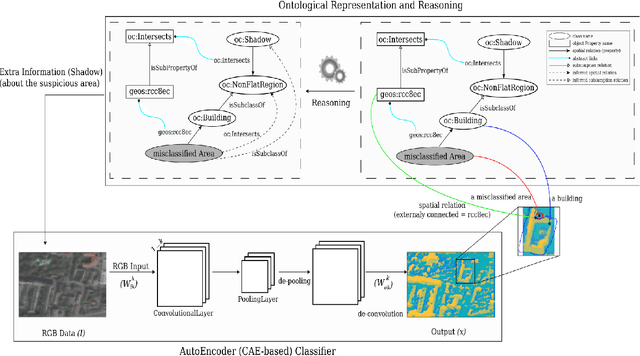
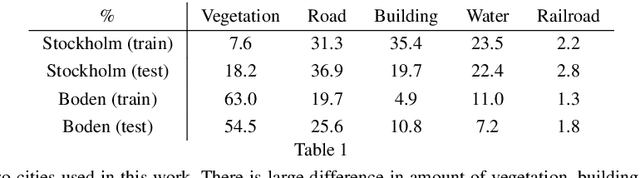

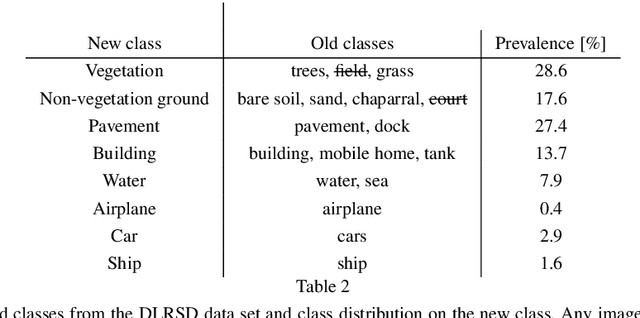
Understanding why machine learning algorithms may fail is usually the task of the human expert that uses domain knowledge and contextual information to discover systematic shortcomings in either the data or the algorithm. In this paper, we propose a semantic referee, which is able to extract qualitative features of the errors emerging from deep machine learning frameworks and suggest corrections. The semantic referee relies on ontological reasoning about spatial knowledge in order to characterize errors in terms of their spatial relations with the environment. Using semantics, the reasoner interacts with the learning algorithm as a supervisor. In this paper, the proposed method of the interaction between a neural network classifier and a semantic referee shows how to improve the performance of semantic segmentation for satellite imagery data.
Reasoning for Improved Sensor Data Interpretation in a Smart Home
Dec 26, 2014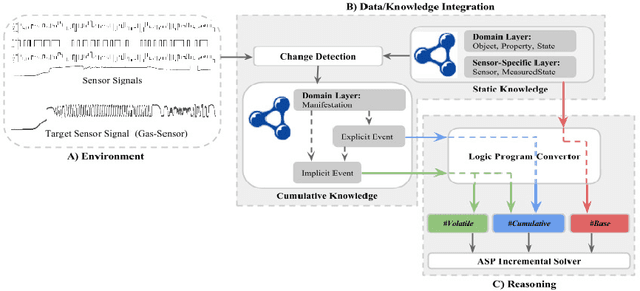
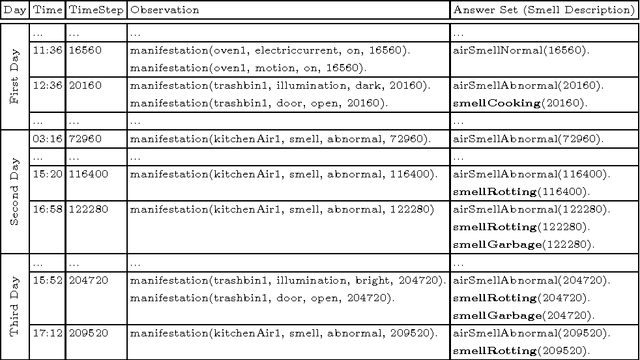
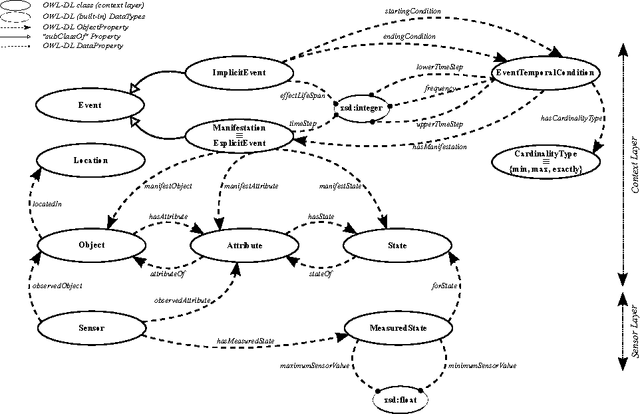
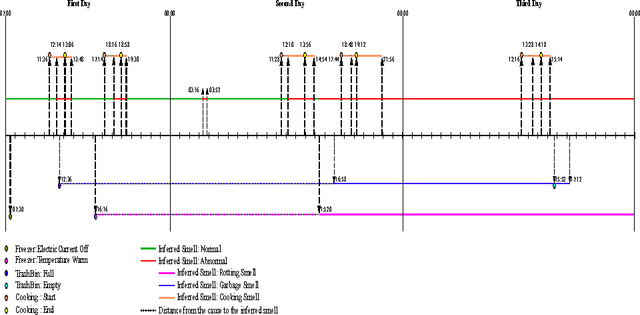
In this paper an ontological representation and reasoning paradigm has been proposed for interpretation of time-series signals. The signals come from sensors observing a smart environment. The signal chosen for the annotation process is a set of unintuitive and complex gas sensor data. The ontology of this paradigm is inspired form the SSN ontology (Semantic Sensor Network) and used for representation of both the sensor data and the contextual information. The interpretation process is mainly done by an incremental ASP solver which as input receives a logic program that is generated from the contents of the ontology. The contextual information together with high level domain knowledge given in the ontology are used to infer explanations (answer sets) for changes in the ambient air detected by the gas sensors.