 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent problem-solving as integrated hierarchical reinforcement learning
Aug 18, 2022According to cognitive psychology and related disciplines, the development of complex problem-solving behaviour in biological agents depends on hierarchical cognitive mechanisms. Hierarchical reinforcement learning is a promising computational approach that may eventually yield comparable problem-solving behaviour in artificial agents and robots. However, to date the problem-solving abilities of many human and non-human animals are clearly superior to those of artificial systems. Here, we propose steps to integrate biologically inspired hierarchical mechanisms to enable advanced problem-solving skills in artificial agents. Therefore, we first review the literature in cognitive psychology to highlight the importance of compositional abstraction and predictive processing. Then we relate the gained insights with contemporary hierarchical reinforcement learning methods. Interestingly, our results suggest that all identified cognitive mechanisms have been implemented individually in isolated computational architectures, raising the question of why there exists no single unifying architecture that integrates them. As our final contribution, we address this question by providing an integrative perspective on the computational challenges to develop such a unifying architecture. We expect our results to guide the development of more sophisticated cognitively inspired hierarchical machine learning architectures.
* Published as accepted article in Nature Machine Intelligence: https://www.nature.com/articles/s42256-021-00433-9. arXiv admin note: substantial text overlap with arXiv:2012.10147
Hierarchical principles of embodied reinforcement learning: A review
Dec 18, 2020
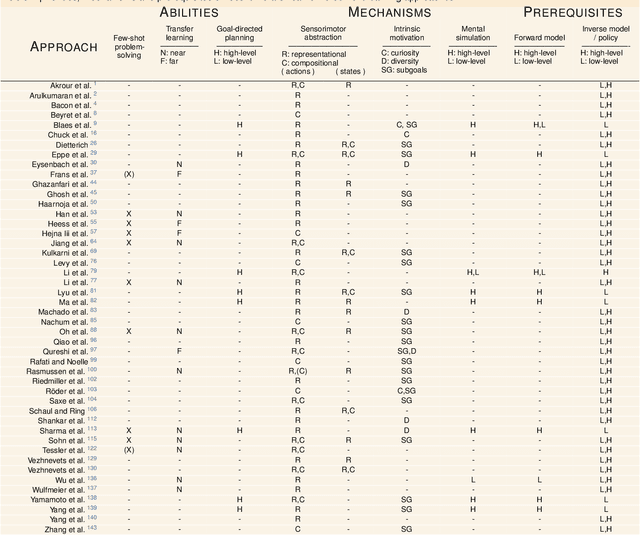
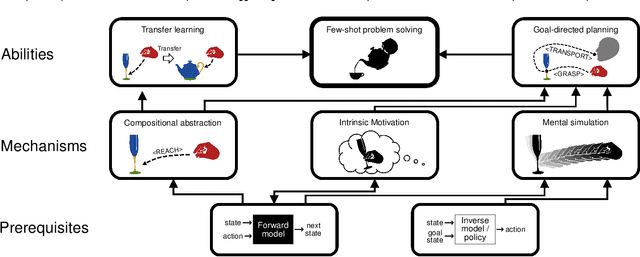
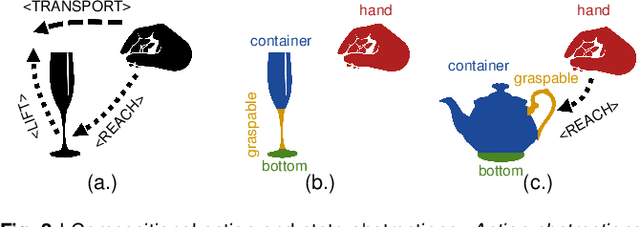
Cognitive Psychology and related disciplines have identified several critical mechanisms that enable intelligent biological agents to learn to solve complex problems. There exists pressing evidence that the cognitive mechanisms that enable problem-solving skills in these species build on hierarchical mental representations. Among the most promising computational approaches to provide comparable learning-based problem-solving abilities for artificial agents and robots is hierarchical reinforcement learning. However, so far the existing computational approaches have not been able to equip artificial agents with problem-solving abilities that are comparable to intelligent animals, including human and non-human primates, crows, or octopuses. Here, we first survey the literature in Cognitive Psychology, and related disciplines, and find that many important mental mechanisms involve compositional abstraction, curiosity, and forward models. We then relate these insights with contemporary hierarchical reinforcement learning methods, and identify the key machine intelligence approaches that realise these mechanisms. As our main result, we show that all important cognitive mechanisms have been implemented independently in isolated computational architectures, and there is simply a lack of approaches that integrate them appropriately. We expect our results to guide the development of more sophisticated cognitively inspired hierarchical methods, so that future artificial agents achieve a problem-solving performance on the level of intelligent animals.
Sensorimotor representation learning for an "active self" in robots: A model survey
Nov 25, 2020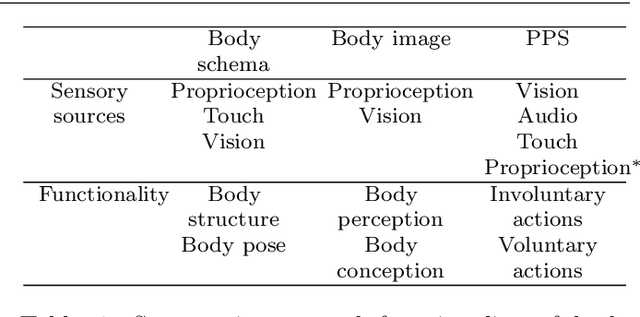

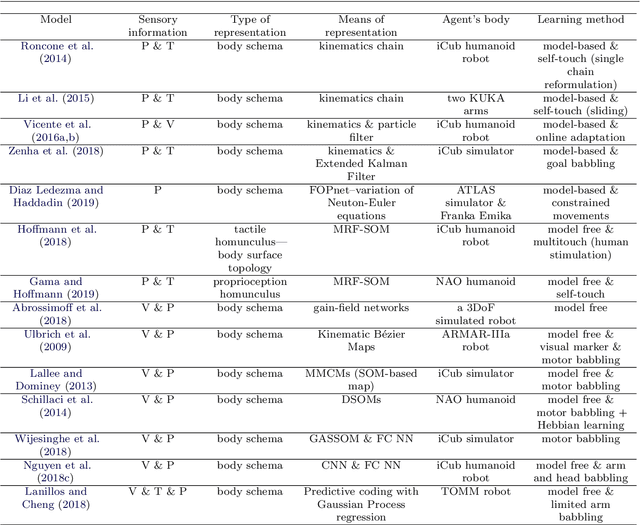
Safe human-robot interactions require robots to be able to learn how to behave appropriately in \sout{humans' world} \rev{spaces populated by people} and thus to cope with the challenges posed by our dynamic and unstructured environment, rather than being provided a rigid set of rules for operations. In humans, these capabilities are thought to be related to our ability to perceive our body in space, sensing the location of our limbs during movement, being aware of other objects and agents, and controlling our body parts to interact with them intentionally. Toward the next generation of robots with bio-inspired capacities, in this paper, we first review the developmental processes of underlying mechanisms of these abilities: The sensory representations of body schema, peripersonal space, and the active self in humans. Second, we provide a survey of robotics models of these sensory representations and robotics models of the self; and we compare these models with the human counterparts. Finally, we analyse what is missing from these robotics models and propose a theoretical computational framework, which aims to allow the emergence of the sense of self in artificial agents by developing sensory representations through self-exploration.
Robotic self-representation improves manipulation skills and transfer learning
Nov 13, 2020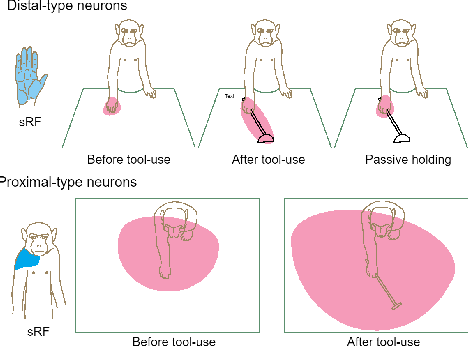
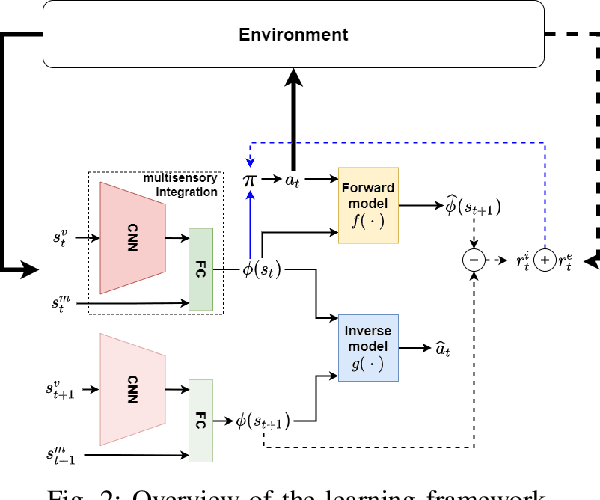
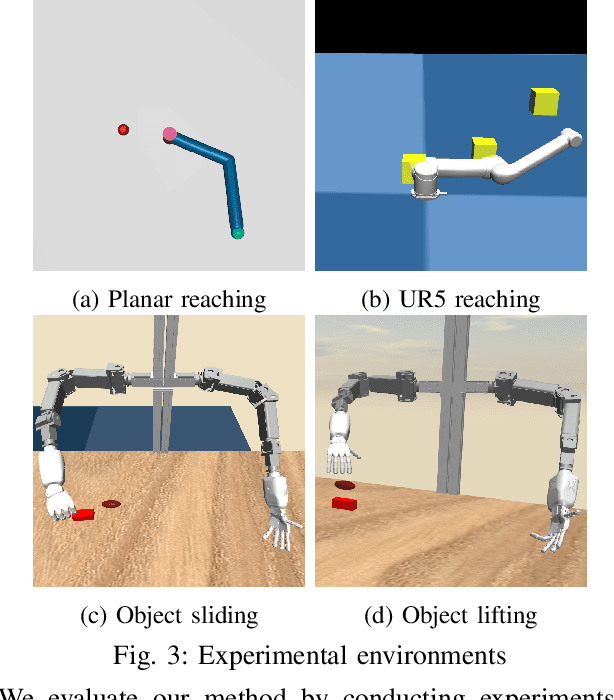
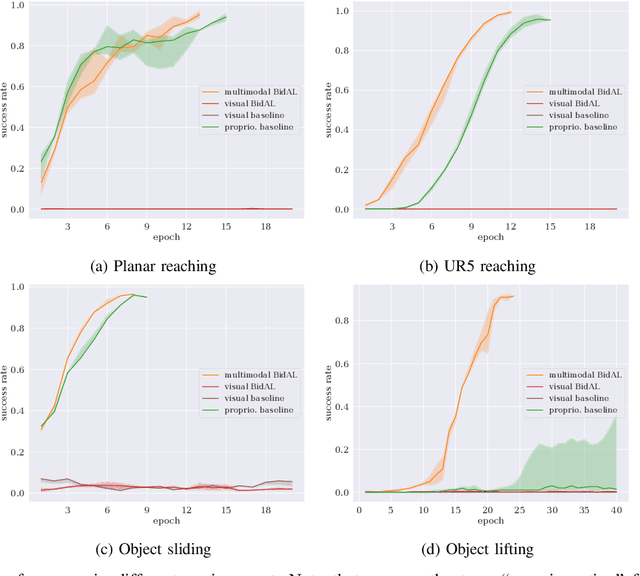
Cognitive science suggests that the self-representation is critical for learning and problem-solving. However, there is a lack of computational methods that relate this claim to cognitively plausible robots and reinforcement learning. In this paper, we bridge this gap by developing a model that learns bidirectional action-effect associations to encode the representations of body schema and the peripersonal space from multisensory information, which is named multimodal BidAL. Through three different robotic experiments, we demonstrate that this approach significantly stabilizes the learning-based problem-solving under noisy conditions and that it improves transfer learning of robotic manipulation skills.
Reinforcement Learning with Time-dependent Goals for Robotic Musicians
Nov 11, 2020

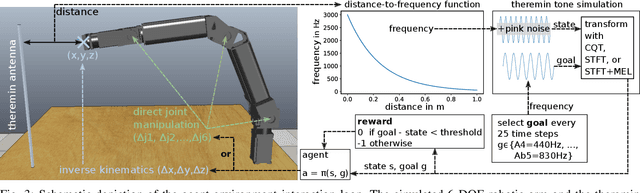

Reinforcement learning is a promising method to accomplish robotic control tasks. The task of playing musical instruments is, however, largely unexplored because it involves the challenge of achieving sequential goals - melodies - that have a temporal dimension. In this paper, we address robotic musicianship by introducing a temporal extension to goal-conditioned reinforcement learning: Time-dependent goals. We demonstrate that these can be used to train a robotic musician to play the theremin instrument. We train the robotic agent in simulation and transfer the acquired policy to a real-world robotic thereminist. Supplemental video: https://youtu.be/jvC9mPzdQN4
Curious Hierarchical Actor-Critic Reinforcement Learning
May 27, 2020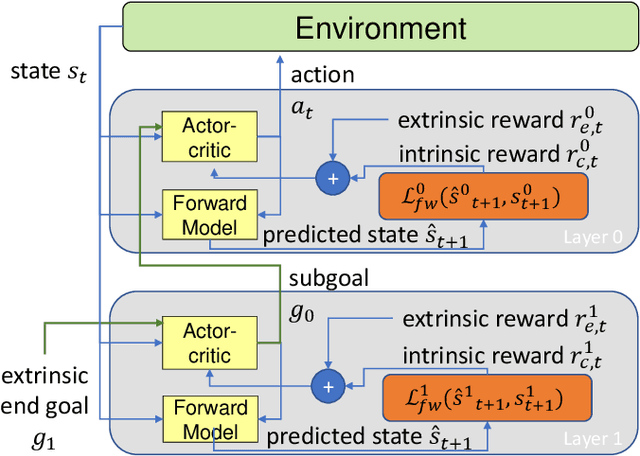
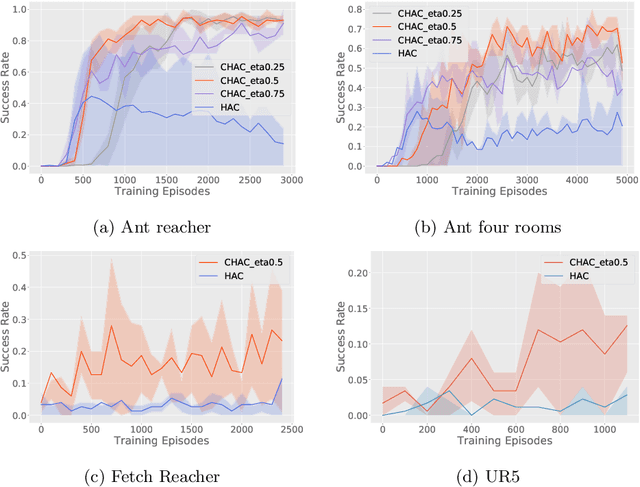
Hierarchical abstraction and curiosity-driven exploration are two common paradigms in current reinforcement learning approaches to break down difficult problems into a sequence of simpler ones and to overcome reward sparsity. However, there is a lack of approaches that combine these paradigms, and it is currently unknown whether curiosity also helps to perform the hierarchical abstraction. As a novelty and scientific contribution, we tackle this issue and develop a method that combines hierarchical reinforcement learning with curiosity. Herein, we extend a contemporary hierarchical actor-critic approach with a forward model to develop a hierarchical notion of curiosity. We demonstrate in several continuous-space environments that curiosity approximately doubles the learning performance and success rates for most of the investigated benchmarking problems.
From semantics to execution: Integrating action planning with reinforcement learning for robotic tool use
May 23, 2019
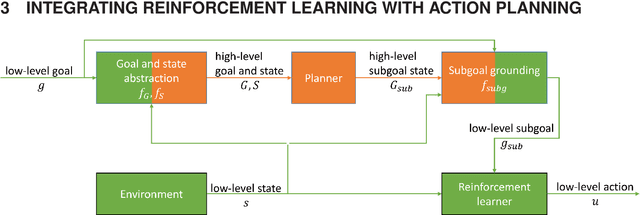
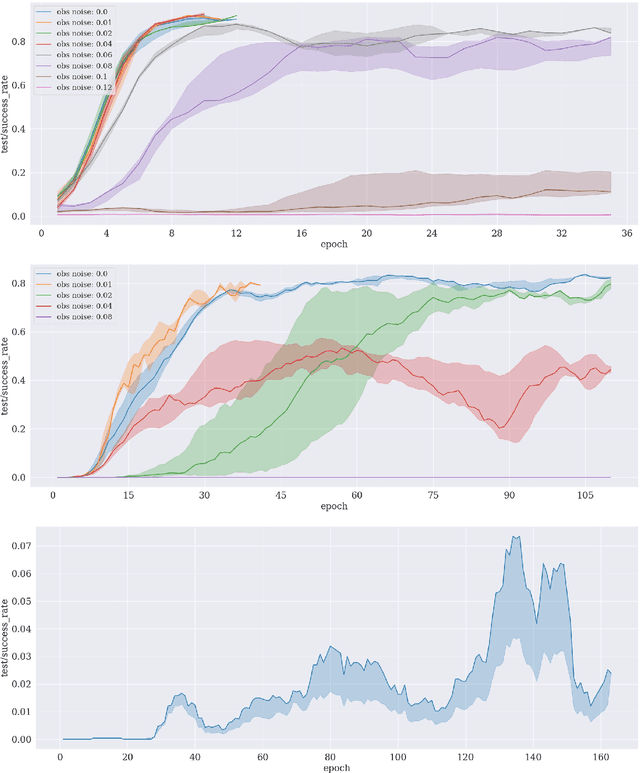
Reinforcement learning is an appropriate and successful method to robustly perform low-level robot control under noisy conditions. Symbolic action planning is useful to resolve causal dependencies and to break a causally complex problem down into a sequence of simpler high-level actions. A problem with the integration of both approaches is that action planning is based on discrete high-level action- and state spaces, whereas reinforcement learning is usually driven by a continuous reward function. However, recent advances in reinforcement learning, specifically, universal value function approximators and hindsight experience replay, have focused on goal-independent methods based on sparse rewards. In this article, we build on these novel methods to facilitate the integration of action planning with reinforcement learning by exploiting the reward-sparsity as a bridge between the high-level and low-level state- and control spaces. As a result, we demonstrate that the integrated neuro-symbolic method is able to solve object manipulation problems that involve tool use and non-trivial causal dependencies under noisy conditions, exploiting both data and knowledge.