 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOAT: A Scene- and Object-Aware Transformer for Vision-and-Language Navigation
Oct 27, 2021
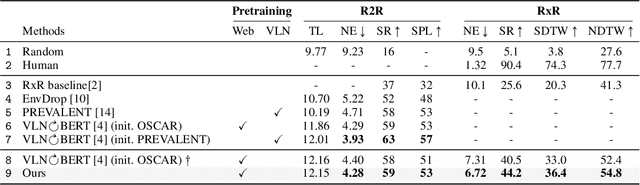
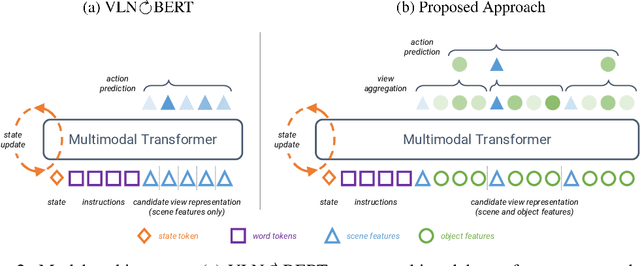
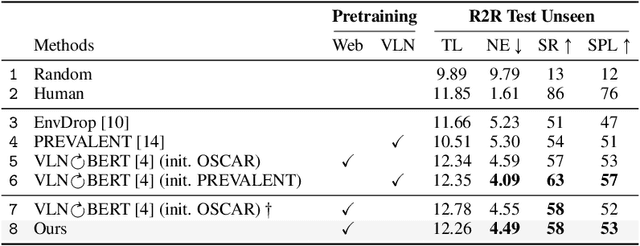
Natural language instructions for visual navigation often use scene descriptions (e.g., "bedroom") and object references (e.g., "green chairs") to provide a breadcrumb trail to a goal location. This work presents a transformer-based vision-and-language navigation (VLN) agent that uses two different visual encoders -- a scene classification network and an object detector -- which produce features that match these two distinct types of visual cues. In our method, scene features contribute high-level contextual information that supports object-level processing. With this design, our model is able to use vision-and-language pretraining (i.e., learning the alignment between images and text from large-scale web data) to substantially improve performance on the Room-to-Room (R2R) and Room-Across-Room (RxR) benchmarks. Specifically, our approach leads to improvements of 1.8% absolute in SPL on R2R and 3.7% absolute in SR on RxR. Our analysis reveals even larger gains for navigation instructions that contain six or more object references, which further suggests that our approach is better able to use object features and align them to references in the instructions.
Waypoint Models for Instruction-guided Navigation in Continuous Environments
Oct 05, 2021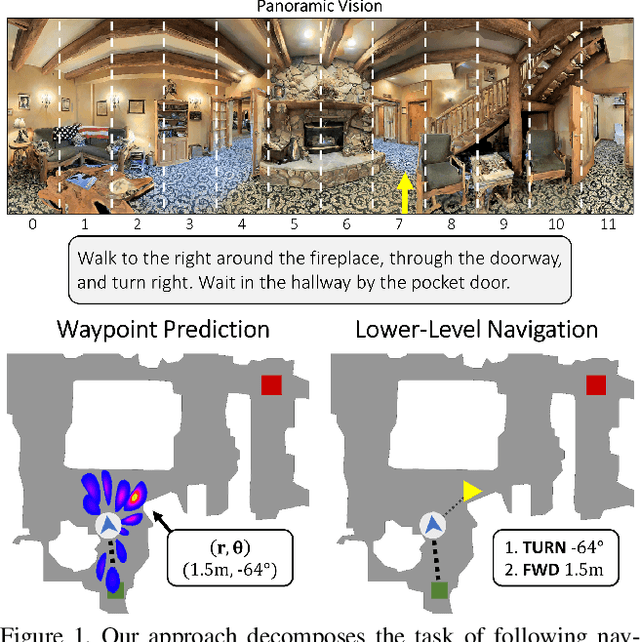
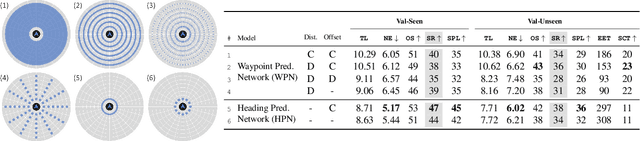
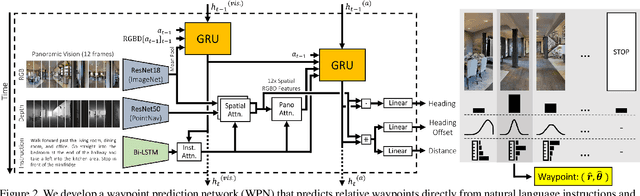

Little inquiry has explicitly addressed the role of action spaces in language-guided visual navigation -- either in terms of its effect on navigation success or the efficiency with which a robotic agent could execute the resulting trajectory. Building on the recently released VLN-CE setting for instruction following in continuous environments, we develop a class of language-conditioned waypoint prediction networks to examine this question. We vary the expressivity of these models to explore a spectrum between low-level actions and continuous waypoint prediction. We measure task performance and estimated execution time on a profiled LoCoBot robot. We find more expressive models result in simpler, faster to execute trajectories, but lower-level actions can achieve better navigation metrics by approximating shortest paths better. Further, our models outperform prior work in VLN-CE and set a new state-of-the-art on the public leaderboard -- increasing success rate by 4% with our best model on this challenging task.
Improving Multilingual Translation by Representation and Gradient Regularization
Sep 10, 2021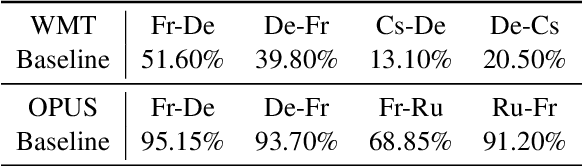
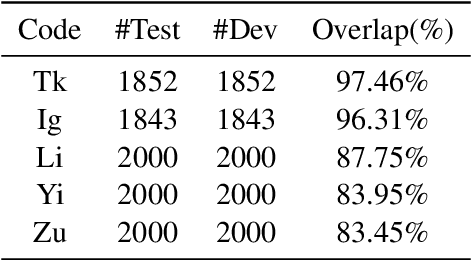
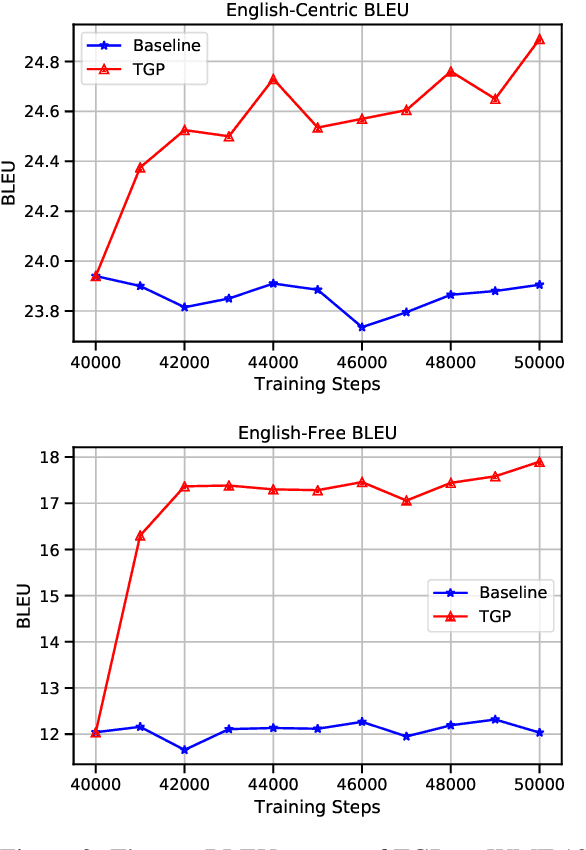
Multilingual Neural Machine Translation (NMT) enables one model to serve all translation directions, including ones that are unseen during training, i.e. zero-shot translation. Despite being theoretically attractive, current models often produce low quality translations -- commonly failing to even produce outputs in the right target language. In this work, we observe that off-target translation is dominant even in strong multilingual systems, trained on massive multilingual corpora. To address this issue, we propose a joint approach to regularize NMT models at both representation-level and gradient-level. At the representation level, we leverage an auxiliary target language prediction task to regularize decoder outputs to retain information about the target language. At the gradient level, we leverage a small amount of direct data (in thousands of sentence pairs) to regularize model gradients. Our results demonstrate that our approach is highly effective in both reducing off-target translation occurrences and improving zero-shot translation performance by +5.59 and +10.38 BLEU on WMT and OPUS datasets respectively. Moreover, experiments show that our method also works well when the small amount of direct data is not available.
Piecewise-constant Neural ODEs
Jun 11, 2021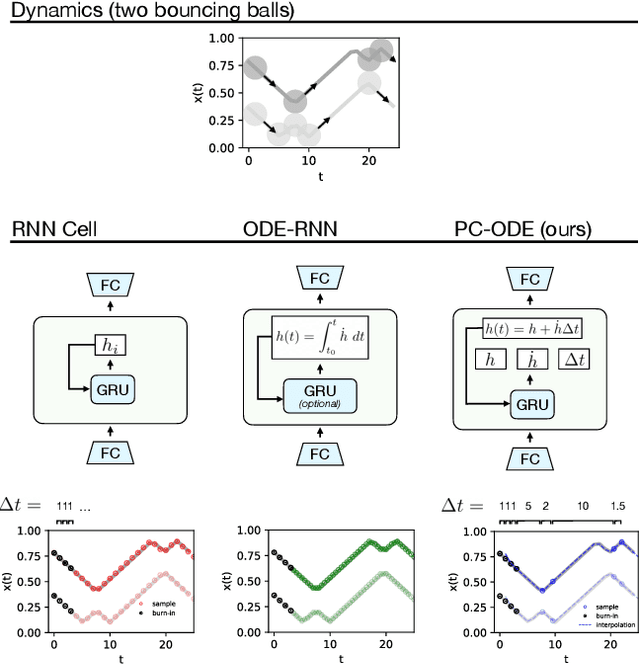
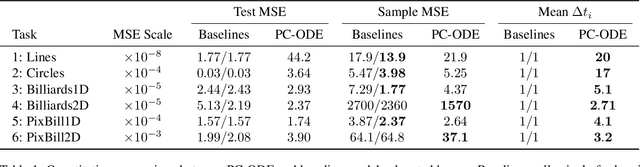
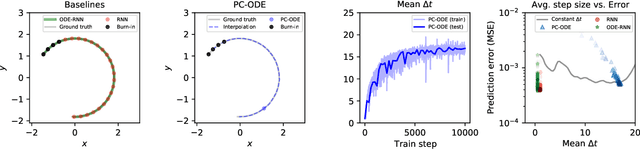
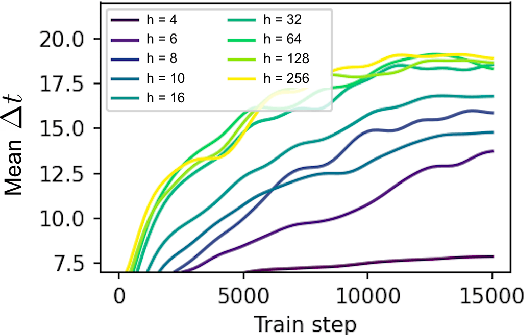
Neural networks are a popular tool for modeling sequential data but they generally do not treat time as a continuous variable. Neural ODEs represent an important exception: they parameterize the time derivative of a hidden state with a neural network and then integrate over arbitrary amounts of time. But these parameterizations, which have arbitrary curvature, can be hard to integrate and thus train and evaluate. In this paper, we propose making a piecewise-constant approximation to Neural ODEs to mitigate these issues. Our model can be integrated exactly via Euler integration and can generate autoregressive samples in 3-20 times fewer steps than comparable RNN and ODE-RNN models. We evaluate our model on several synthetic physics tasks and a planning task inspired by the game of billiards. We find that it matches the performance of baseline approaches while requiring less time to train and evaluate.
Deep Convolution for Irregularly Sampled Temporal Point Clouds
May 01, 2021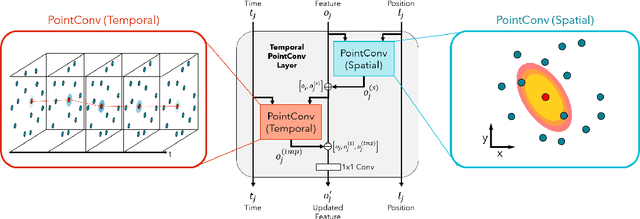

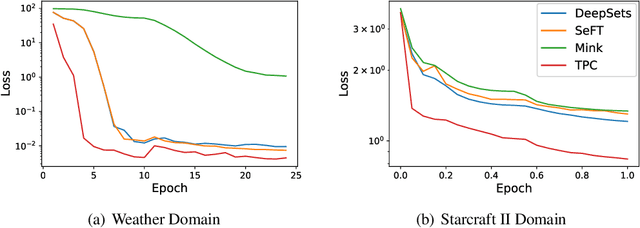

We consider the problem of modeling the dynamics of continuous spatial-temporal processes represented by irregular samples through both space and time. Such processes occur in sensor networks, citizen science, multi-robot systems, and many others. We propose a new deep model that is able to directly learn and predict over this irregularly sampled data, without voxelization, by leveraging a recent convolutional architecture for static point clouds. The model also easily incorporates the notion of multiple entities in the process. In particular, the model can flexibly answer prediction queries about arbitrary space-time points for different entities regardless of the distribution of the training or test-time data. We present experiments on real-world weather station data and battles between large armies in StarCraft II. The results demonstrate the model's flexibility in answering a variety of query types and demonstrate improved performance and efficiency compared to state-of-the-art baselines.
Where Are You? Localization from Embodied Dialog
Nov 16, 2020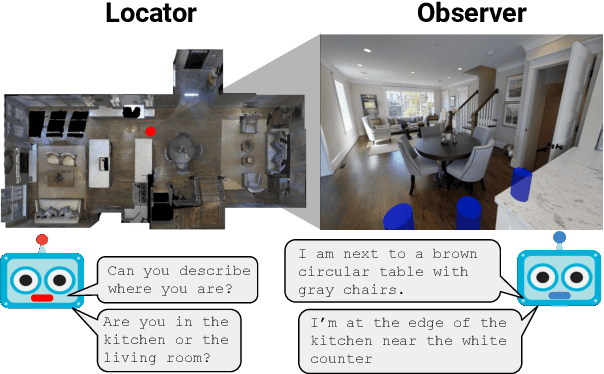
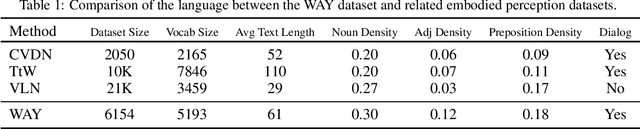
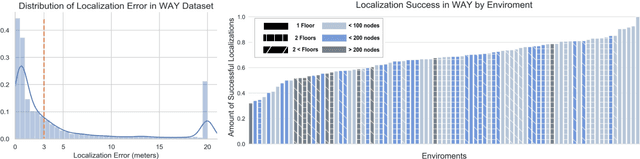
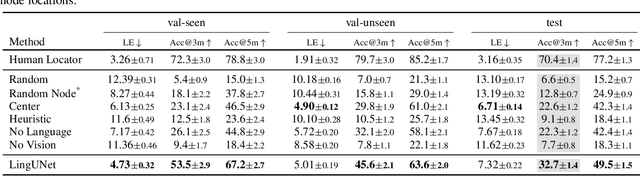
We present Where Are You? (WAY), a dataset of ~6k dialogs in which two humans -- an Observer and a Locator -- complete a cooperative localization task. The Observer is spawned at random in a 3D environment and can navigate from first-person views while answering questions from the Locator. The Locator must localize the Observer in a detailed top-down map by asking questions and giving instructions. Based on this dataset, we define three challenging tasks: Localization from Embodied Dialog or LED (localizing the Observer from dialog history), Embodied Visual Dialog (modeling the Observer), and Cooperative Localization (modeling both agents). In this paper, we focus on the LED task -- providing a strong baseline model with detailed ablations characterizing both dataset biases and the importance of various modeling choices. Our best model achieves 32.7% success at identifying the Observer's location within 3m in unseen buildings, vs. 70.4% for human Locators.
Sim-to-Real Transfer for Vision-and-Language Navigation
Nov 07, 2020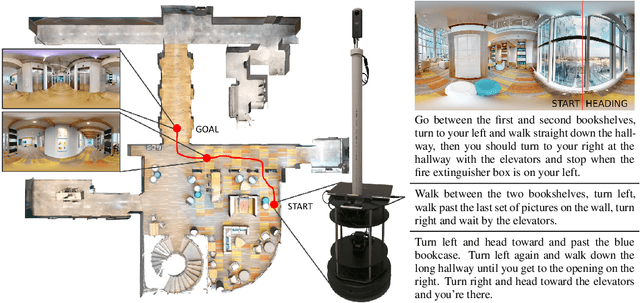

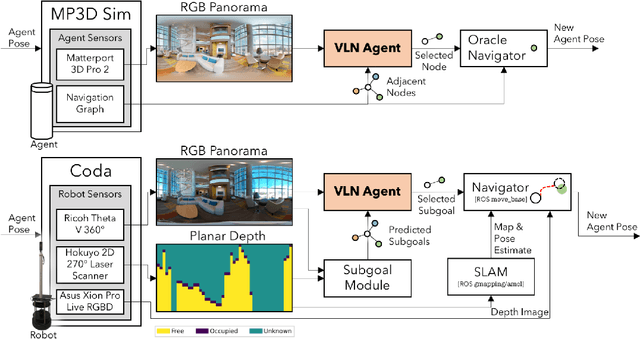

We study the challenging problem of releasing a robot in a previously unseen environment, and having it follow unconstrained natural language navigation instructions. Recent work on the task of Vision-and-Language Navigation (VLN) has achieved significant progress in simulation. To assess the implications of this work for robotics, we transfer a VLN agent trained in simulation to a physical robot. To bridge the gap between the high-level discrete action space learned by the VLN agent, and the robot's low-level continuous action space, we propose a subgoal model to identify nearby waypoints, and use domain randomization to mitigate visual domain differences. For accurate sim and real comparisons in parallel environments, we annotate a 325m2 office space with 1.3km of navigation instructions, and create a digitized replica in simulation. We find that sim-to-real transfer to an environment not seen in training is successful if an occupancy map and navigation graph can be collected and annotated in advance (success rate of 46.8% vs. 55.9% in sim), but much more challenging in the hardest setting with no prior mapping at all (success rate of 22.5%).
Language-Conditioned Imitation Learning for Robot Manipulation Tasks
Oct 22, 2020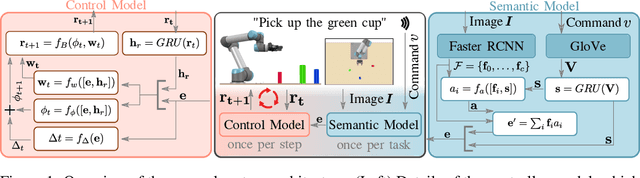
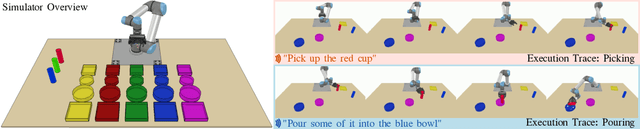
Imitation learning is a popular approach for teaching motor skills to robots. However, most approaches focus on extracting policy parameters from execution traces alone (i.e., motion trajectories and perceptual data). No adequate communication channel exists between the human expert and the robot to describe critical aspects of the task, such as the properties of the target object or the intended shape of the motion. Motivated by insights into the human teaching process, we introduce a method for incorporating unstructured natural language into imitation learning. At training time, the expert can provide demonstrations along with verbal descriptions in order to describe the underlying intent (e.g., "go to the large green bowl"). The training process then interrelates these two modalities to encode the correlations between language, perception, and motion. The resulting language-conditioned visuomotor policies can be conditioned at runtime on new human commands and instructions, which allows for more fine-grained control over the trained policies while also reducing situational ambiguity. We demonstrate in a set of simulation experiments how our approach can learn language-conditioned manipulation policies for a seven-degree-of-freedom robot arm and compare the results to a variety of alternative methods.
DeepAveragers: Offline Reinforcement Learning by Solving Derived Non-Parametric MDPs
Oct 18, 2020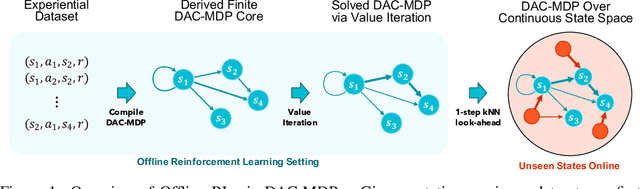

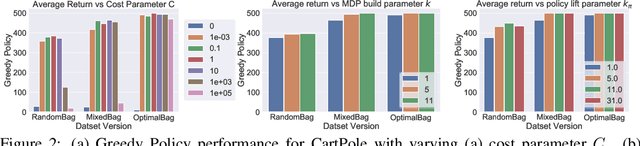
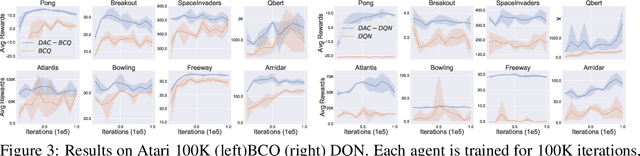
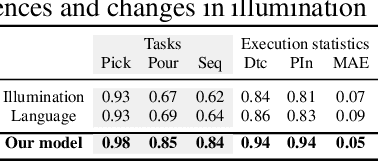
We study an approach to offline reinforcement learning (RL) based on optimally solving finitely-represented MDPs derived from a static dataset of experience. This approach can be applied on top of any learned representation and has the potential to easily support multiple solution objectives as well as zero-shot adjustment to changing environments and goals. Our main contribution is to introduce the Deep Averagers with Costs MDP (DAC-MDP) and to investigate its solutions for offline RL. DAC-MDPs are a non-parametric model that can leverage deep representations and account for limited data by introducing costs for exploiting under-represented parts of the model. In theory, we show conditions that allow for lower-bounding the performance of DAC-MDP solutions. We also investigate the empirical behavior in a number of environments, including those with image-based observations. Overall, the experiments demonstrate that the framework can work in practice and scale to large complex offline RL problems.
On the Sub-Layer Functionalities of Transformer Decoder
Oct 06, 2020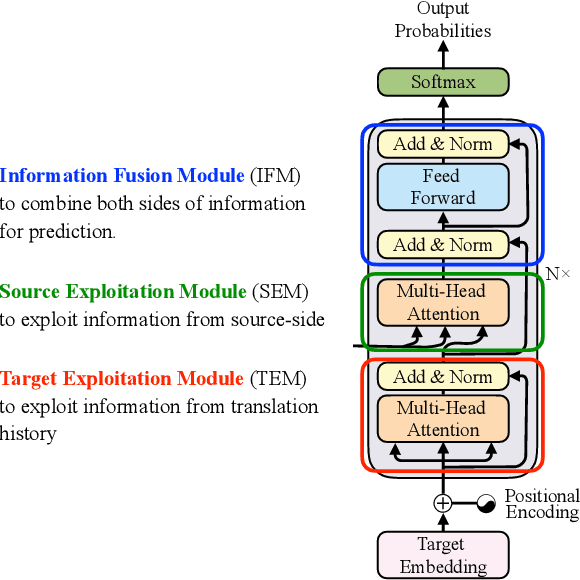
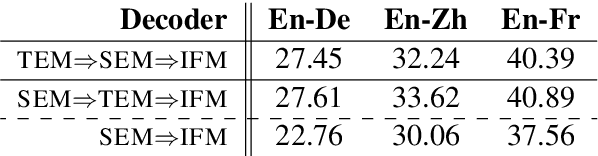
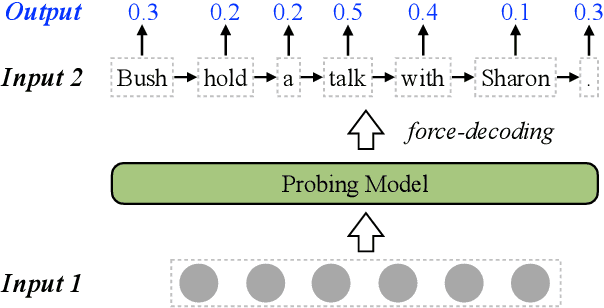
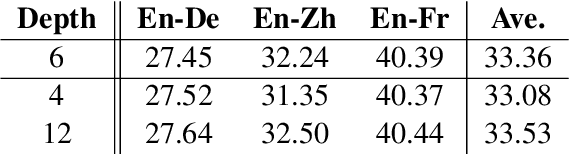
There have been significant efforts to interpret the encoder of Transformer-based encoder-decoder architectures for neural machine translation (NMT); meanwhile, the decoder remains largely unexamined despite its critical role. During translation, the decoder must predict output tokens by considering both the source-language text from the encoder and the target-language prefix produced in previous steps. In this work, we study how Transformer-based decoders leverage information from the source and target languages -- developing a universal probe task to assess how information is propagated through each module of each decoder layer. We perform extensive experiments on three major translation datasets (WMT En-De, En-Fr, and En-Zh). Our analysis provides insight on when and where decoders leverage different sources. Based on these insights, we demonstrate that the residual feed-forward module in each Transformer decoder layer can be dropped with minimal loss of performance -- a significant reduction in computation and number of parameters, and consequently a significant boost to both training and inference speed.