 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternational AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
Reinforcement Learning with Exogenous States and Rewards
Mar 22, 2023



Exogenous state variables and rewards can slow reinforcement learning by injecting uncontrolled variation into the reward signal. This paper formalizes exogenous state variables and rewards and shows that if the reward function decomposes additively into endogenous and exogenous components, the MDP can be decomposed into an exogenous Markov Reward Process (based on the exogenous reward) and an endogenous Markov Decision Process (optimizing the endogenous reward). Any optimal policy for the endogenous MDP is also an optimal policy for the original MDP, but because the endogenous reward typically has reduced variance, the endogenous MDP is easier to solve. We study settings where the decomposition of the state space into exogenous and endogenous state spaces is not given but must be discovered. The paper introduces and proves correctness of algorithms for discovering the exogenous and endogenous subspaces of the state space when they are mixed through linear combination. These algorithms can be applied during reinforcement learning to discover the exogenous space, remove the exogenous reward, and focus reinforcement learning on the endogenous MDP. Experiments on a variety of challenging synthetic MDPs show that these methods, applied online, discover large exogenous state spaces and produce substantial speedups in reinforcement learning.
Will My Robot Achieve My Goals? Predicting the Probability that an MDP Policy Reaches a User-Specified Behavior Target
Nov 29, 2022



As an autonomous system performs a task, it should maintain a calibrated estimate of the probability that it will achieve the user's goal. If that probability falls below some desired level, it should alert the user so that appropriate interventions can be made. This paper considers settings where the user's goal is specified as a target interval for a real-valued performance summary, such as the cumulative reward, measured at a fixed horizon $H$. At each time $t \in \{0, \ldots, H-1\}$, our method produces a calibrated estimate of the probability that the final cumulative reward will fall within a user-specified target interval $[y^-,y^+].$ Using this estimate, the autonomous system can raise an alarm if the probability drops below a specified threshold. We compute the probability estimates by inverting conformal prediction. Our starting point is the Conformalized Quantile Regression (CQR) method of Romano et al., which applies split-conformal prediction to the results of quantile regression. CQR is not invertible, but by using the conditional cumulative distribution function (CDF) as the non-conformity measure, we show how to obtain an invertible modification that we call \textbf{P}robability-space \textbf{C}onformalized \textbf{Q}uantile \textbf{R}egression (PCQR). Like CQR, PCQR produces well-calibrated conditional prediction intervals with finite-sample marginal guarantees. By inverting PCQR, we obtain marginal guarantees for the probability that the cumulative reward of an autonomous system will fall within an arbitrary user-specified target intervals. Experiments on two domains confirm that these probabilities are well-calibrated.
Oracle Analysis of Representations for Deep Open Set Detection
Sep 22, 2022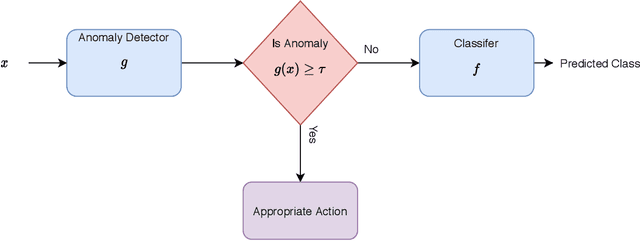
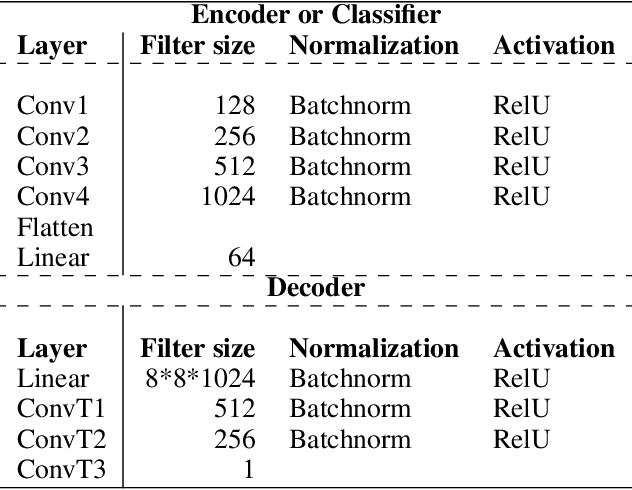
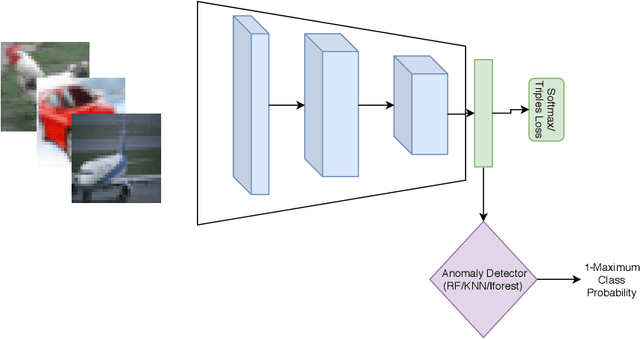
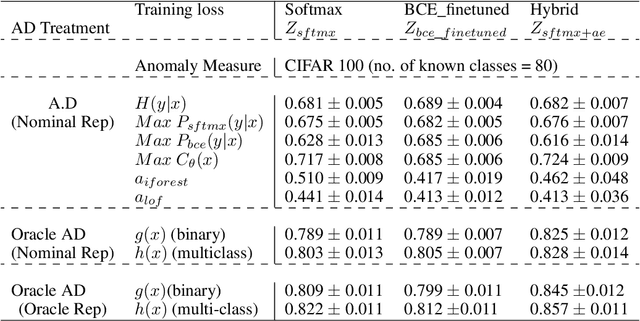
The problem of detecting a novel class at run time is known as Open Set Detection & is important for various real-world applications like medical application, autonomous driving, etc. Open Set Detection within context of deep learning involves solving two problems: (i) Must map the input images into a latent representation that contains enough information to detect the outliers, and (ii) Must learn an anomaly scoring function that can extract this information from the latent representation to identify the anomalies. Research in deep anomaly detection methods has progressed slowly. One reason may be that most papers simultaneously introduce new representation learning techniques and new anomaly scoring approaches. The goal of this work is to improve this methodology by providing ways of separately measuring the effectiveness of the representation learning and anomaly scoring. This work makes two methodological contributions. The first is to introduce the notion of Oracle anomaly detection for quantifying the information available in a learned latent representation. The second is to introduce Oracle representation learning, which produces a representation that is guaranteed to be sufficient for accurate anomaly detection. These two techniques help researchers to separate the quality of the learned representation from the performance of the anomaly scoring mechanism so that they can debug and improve their systems. The methods also provide an upper limit on how much open category detection can be improved through better anomaly scoring mechanisms. The combination of the two oracles gives an upper limit on the performance that any open category detection method could achieve. This work introduces these two oracle techniques and demonstrates their utility by applying them to several leading open category detection methods.
Conformal Prediction Intervals for Markov Decision Process Trajectories
Jun 21, 2022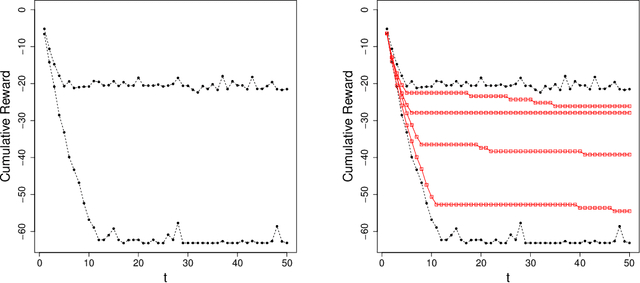
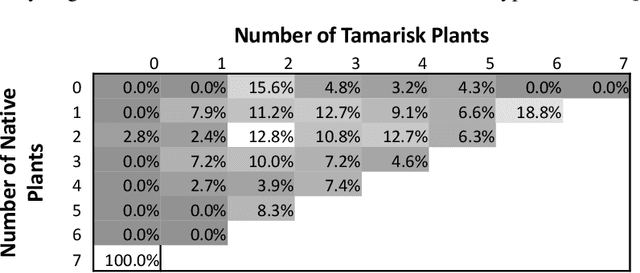
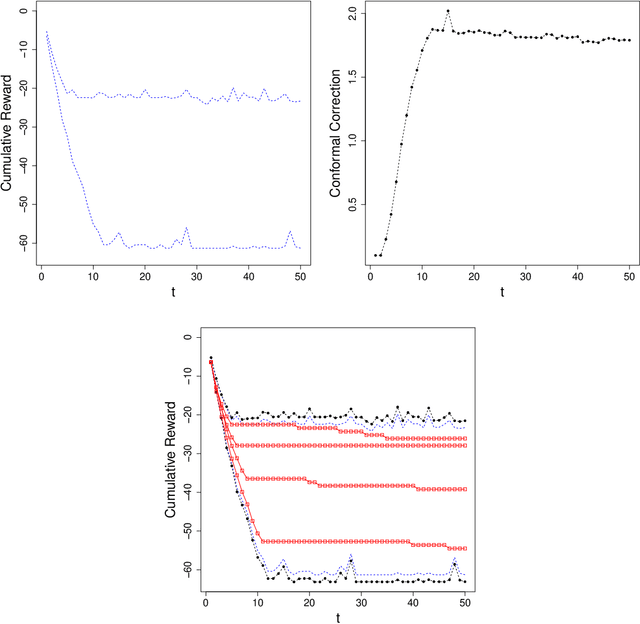
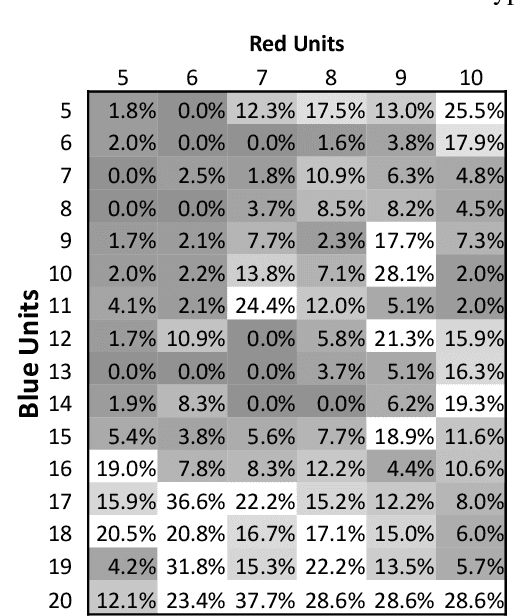
Before delegating a task to an autonomous system, a human operator may want a guarantee about the behavior of the system. This paper extends previous work on conformal prediction for functional data and conformalized quantile regression to provide conformal prediction intervals over the future behavior of an autonomous system executing a fixed control policy on a Markov Decision Process (MDP). The prediction intervals are constructed by applying conformal corrections to prediction intervals computed by quantile regression. The resulting intervals guarantee that with probability $1-\delta$ the observed trajectory will lie inside the prediction interval, where the probability is computed with respect to the starting state distribution and the stochasticity of the MDP. The method is illustrated on MDPs for invasive species management and StarCraft2 battles.
The Familiarity Hypothesis: Explaining the Behavior of Deep Open Set Methods
Mar 04, 2022
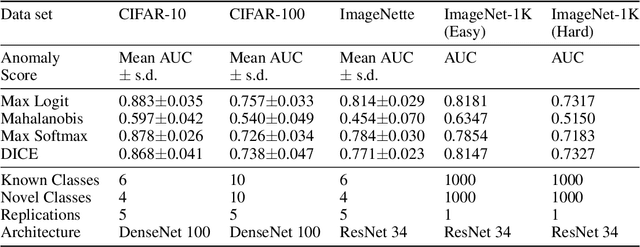
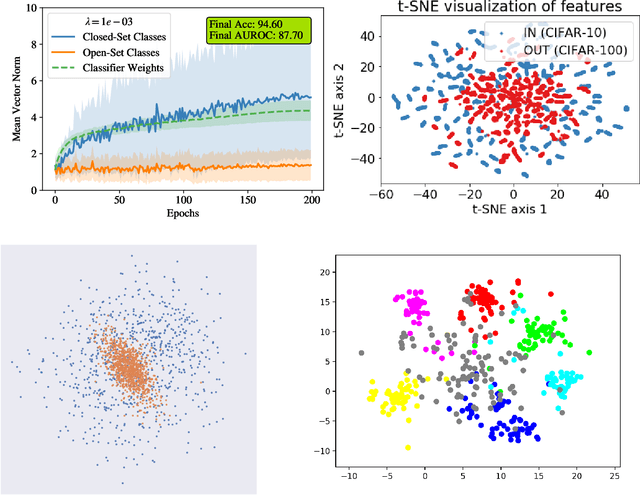
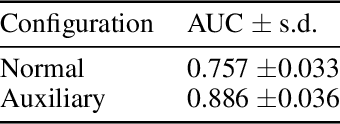
In many object recognition applications, the set of possible categories is an open set, and the deployed recognition system will encounter novel objects belonging to categories unseen during training. Detecting such "novel category" objects is usually formulated as an anomaly detection problem. Anomaly detection algorithms for feature-vector data identify anomalies as outliers, but outlier detection has not worked well in deep learning. Instead, methods based on the computed logits of visual object classifiers give state-of-the-art performance. This paper proposes the Familiarity Hypothesis that these methods succeed because they are detecting the absence of familiar learned features rather than the presence of novelty. The paper reviews evidence from the literature and presents additional evidence from our own experiments that provide strong support for this hypothesis. The paper concludes with a discussion of whether familiarity detection is an inevitable consequence of representation learning.
Hidden Heterogeneity: When to Choose Similarity-Based Calibration
Feb 03, 2022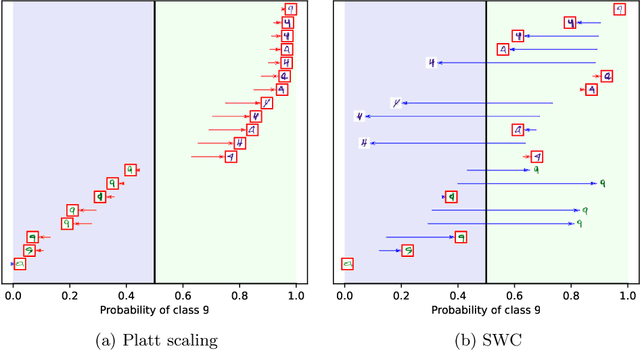

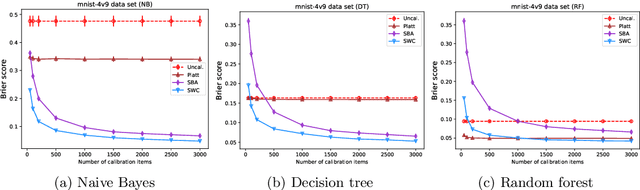
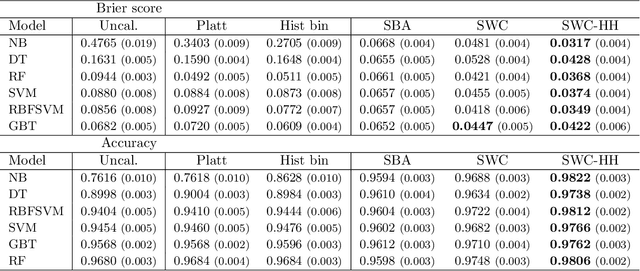
Trustworthy classifiers are essential to the adoption of machine learning predictions in many real-world settings. The predicted probability of possible outcomes can inform high-stakes decision making, particularly when assessing the expected value of alternative decisions or the risk of bad outcomes. These decisions require well calibrated probabilities, not just the correct prediction of the most likely class. Black-box classifier calibration methods can improve the reliability of a classifier's output without requiring retraining. However, these methods are unable to detect subpopulations where calibration could improve prediction accuracy. Such subpopulations are said to exhibit "hidden heterogeneity" (HH), because the original classifier did not detect them. The paper proposes a quantitative measure for HH. It also introduces two similarity-weighted calibration methods that can address HH by adapting locally to each test item: SWC weights the calibration set by similarity to the test item, and SWC-HH explicitly incorporates hidden heterogeneity to filter the calibration set. Experiments show that the improvements in calibration achieved by similarity-based calibration methods correlate with the amount of HH present and, given sufficient calibration data, generally exceed calibration achieved by global methods. HH can therefore serve as a useful diagnostic tool for identifying when local calibration methods are needed.
Deep Convolution for Irregularly Sampled Temporal Point Clouds
May 01, 2021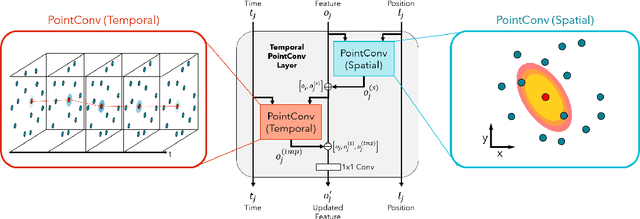

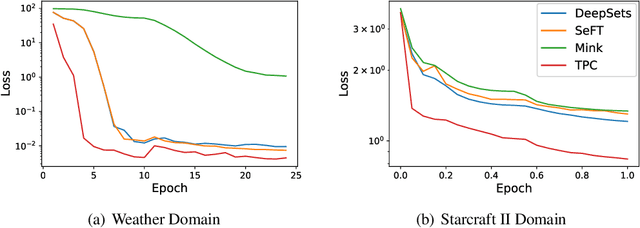

We consider the problem of modeling the dynamics of continuous spatial-temporal processes represented by irregular samples through both space and time. Such processes occur in sensor networks, citizen science, multi-robot systems, and many others. We propose a new deep model that is able to directly learn and predict over this irregularly sampled data, without voxelization, by leveraging a recent convolutional architecture for static point clouds. The model also easily incorporates the notion of multiple entities in the process. In particular, the model can flexibly answer prediction queries about arbitrary space-time points for different entities regardless of the distribution of the training or test-time data. We present experiments on real-world weather station data and battles between large armies in StarCraft II. The results demonstrate the model's flexibility in answering a variety of query types and demonstrate improved performance and efficiency compared to state-of-the-art baselines.
Confidence Calibration for Domain Generalization under Covariate Shift
Apr 01, 2021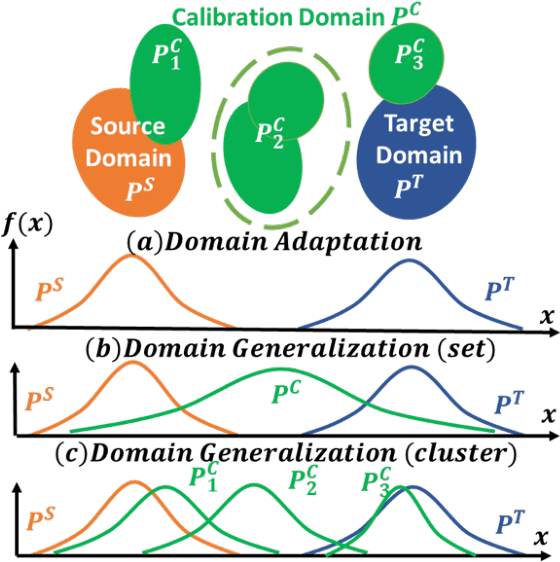
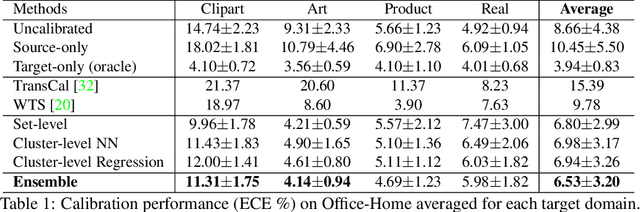
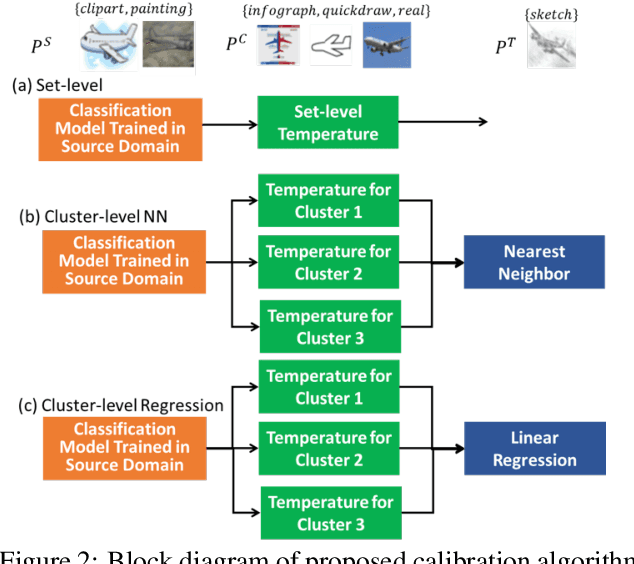
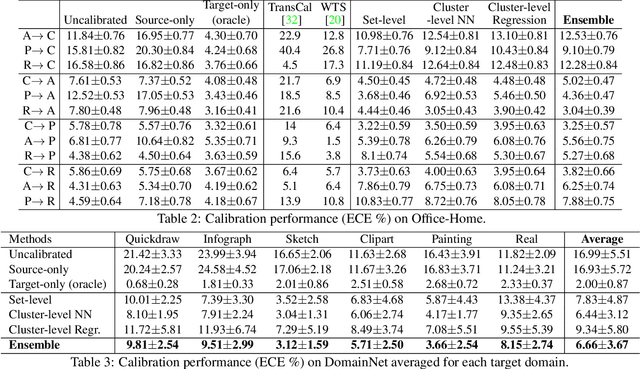
Existing calibration algorithms address the problem of covariate shift via unsupervised domain adaptation. However, these methods suffer from the following limitations: 1) they require unlabeled data from the target domain, which may not be available at the stage of calibration in real-world applications and 2) their performances heavily depend on the disparity between the distributions of the source and target domains. To address these two limitations, we present novel calibration solutions via domain generalization which, to the best of our knowledge, are the first of their kind. Our core idea is to leverage multiple calibration domains to reduce the effective distribution disparity between the target and calibration domains for improved calibration transfer without needing any data from the target domain. We provide theoretical justification and empirical experimental results to demonstrate the effectiveness of our proposed algorithms. Compared against the state-of-the-art calibration methods designed for domain adaptation, we observe a decrease of 8.86 percentage points in expected calibration error, equivalently an increase of 35 percentage points in improvement ratio, for multi-class classification on the Office-Home dataset.
Three-quarter Sibling Regression for Denoising Observational Data
Dec 31, 2020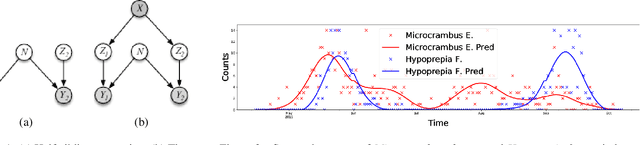
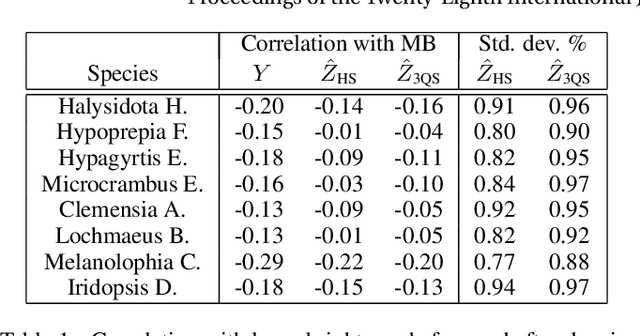
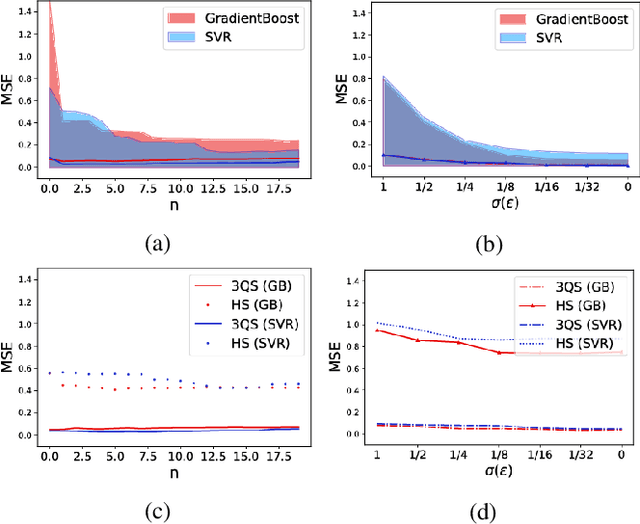
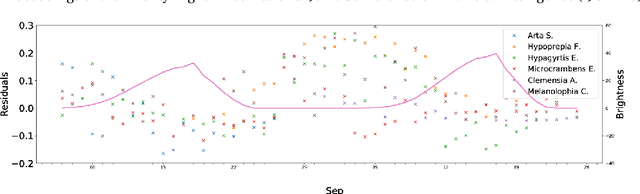
Many ecological studies and conservation policies are based on field observations of species, which can be affected by systematic variability introduced by the observation process. A recently introduced causal modeling technique called 'half-sibling regression' can detect and correct for systematic errors in measurements of multiple independent random variables. However, it will remove intrinsic variability if the variables are dependent, and therefore does not apply to many situations, including modeling of species counts that are controlled by common causes. We present a technique called 'three-quarter sibling regression' to partially overcome this limitation. It can filter the effect of systematic noise when the latent variables have observed common causes. We provide theoretical justification of this approach, demonstrate its effectiveness on synthetic data, and show that it reduces systematic detection variability due to moon brightness in moth surveys.