 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Vision and Language to 3D Masks for Long-Horizon Box Rearrangement
Mar 24, 2026We study long-horizon planning in 3D environments from under-specified natural-language goals using only visual observations, focusing on multi-step 3D box rearrangement tasks. Existing approaches typically rely on symbolic planners with brittle relational grounding of states and goals, or on direct action-sequence generation from 2D vision-language models (VLMs). Both approaches struggle with reasoning over many objects, rich 3D geometry, and implicit semantic constraints. Recent advances in 3D VLMs demonstrate strong grounding of natural-language referents to 3D segmentation masks, suggesting the potential for more general planning capabilities. We extend existing 3D grounding models and propose Reactive Action Mask Planner (RAMP-3D), which formulates long-horizon planning as sequential reactive prediction of paired 3D masks: a "which-object" mask indicating what to pick and a "which-target-region" mask specifying where to place it. The resulting system processes RGB-D observations and natural-language task specifications to reactively generate multi-step pick-and-place actions for 3D box rearrangement. We conduct experiments across 11 task variants in warehouse-style environments with 1-30 boxes and diverse natural-language constraints. RAMP-3D achieves 79.5% success rate on long-horizon rearrangement tasks and significantly outperforms 2D VLM-based baselines, establishing mask-based reactive policies as a promising alternative to symbolic pipelines for long-horizon planning.
Humanoid Hanoi: Investigating Shared Whole-Body Control for Skill-Based Box Rearrangement
Feb 14, 2026We investigate a skill-based framework for humanoid box rearrangement that enables long-horizon execution by sequencing reusable skills at the task level. In our architecture, all skills execute through a shared, task-agnostic whole-body controller (WBC), providing a consistent closed-loop interface for skill composition, in contrast to non-shared designs that use separate low-level controllers per skill. We find that naively reusing the same pretrained WBC can reduce robustness over long horizons, as new skills and their compositions induce shifted state and command distributions. We address this with a simple data aggregation procedure that augments shared-WBC training with rollouts from closed-loop skill execution under domain randomization. To evaluate the approach, we introduce \emph{Humanoid Hanoi}, a long-horizon Tower-of-Hanoi box rearrangement benchmark, and report results in simulation and on the Digit V3 humanoid robot, demonstrating fully autonomous rearrangement over extended horizons and quantifying the benefits of the shared-WBC approach over non-shared baselines.
Generating Physically Realistic and Directable Human Motions from Multi-Modal Inputs
Feb 08, 2025This work focuses on generating realistic, physically-based human behaviors from multi-modal inputs, which may only partially specify the desired motion. For example, the input may come from a VR controller providing arm motion and body velocity, partial key-point animation, computer vision applied to videos, or even higher-level motion goals. This requires a versatile low-level humanoid controller that can handle such sparse, under-specified guidance, seamlessly switch between skills, and recover from failures. Current approaches for learning humanoid controllers from demonstration data capture some of these characteristics, but none achieve them all. To this end, we introduce the Masked Humanoid Controller (MHC), a novel approach that applies multi-objective imitation learning on augmented and selectively masked motion demonstrations. The training methodology results in an MHC that exhibits the key capabilities of catch-up to out-of-sync input commands, combining elements from multiple motion sequences, and completing unspecified parts of motions from sparse multimodal input. We demonstrate these key capabilities for an MHC learned over a dataset of 87 diverse skills and showcase different multi-modal use cases, including integration with planning frameworks to highlight MHC's ability to solve new user-defined tasks without any finetuning.
Revisiting Reward Design and Evaluation for Robust Humanoid Standing and Walking
Apr 30, 2024



A necessary capability for humanoid robots is the ability to stand and walk while rejecting natural disturbances. Recent progress has been made using sim-to-real reinforcement learning (RL) to train such locomotion controllers, with approaches differing mainly in their reward functions. However, prior works lack a clear method to systematically test new reward functions and compare controller performance through repeatable experiments. This limits our understanding of the trade-offs between approaches and hinders progress. To address this, we propose a low-cost, quantitative benchmarking method to evaluate and compare the real-world performance of standing and walking (SaW) controllers on metrics like command following, disturbance recovery, and energy efficiency. We also revisit reward function design and construct a minimally constraining reward function to train SaW controllers. We experimentally verify that our benchmarking framework can identify areas for improvement, which can be systematically addressed to enhance the policies. We also compare our new controller to state-of-the-art controllers on the Digit humanoid robot. The results provide clear quantitative trade-offs among the controllers and suggest directions for future improvements to the reward functions and expansion of the benchmarks.
DeepAveragers: Offline Reinforcement Learning by Solving Derived Non-Parametric MDPs
Oct 18, 2020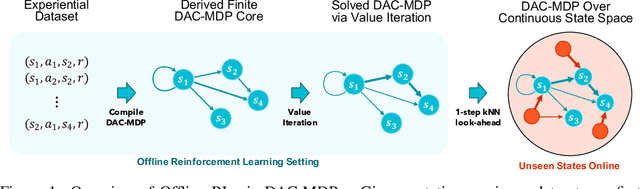

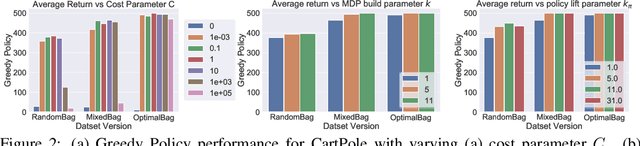
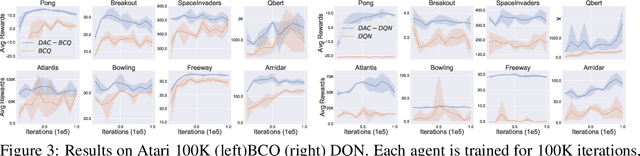
We study an approach to offline reinforcement learning (RL) based on optimally solving finitely-represented MDPs derived from a static dataset of experience. This approach can be applied on top of any learned representation and has the potential to easily support multiple solution objectives as well as zero-shot adjustment to changing environments and goals. Our main contribution is to introduce the Deep Averagers with Costs MDP (DAC-MDP) and to investigate its solutions for offline RL. DAC-MDPs are a non-parametric model that can leverage deep representations and account for limited data by introducing costs for exploiting under-represented parts of the model. In theory, we show conditions that allow for lower-bounding the performance of DAC-MDP solutions. We also investigate the empirical behavior in a number of environments, including those with image-based observations. Overall, the experiments demonstrate that the framework can work in practice and scale to large complex offline RL problems.