 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMPflow: A Geometric Framework for Generation of Multi-Task Motion Policies
Jul 25, 2020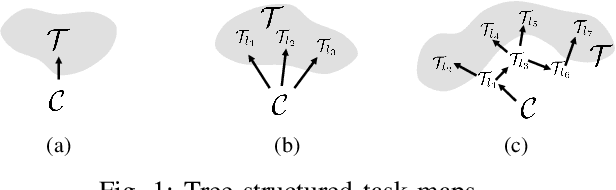
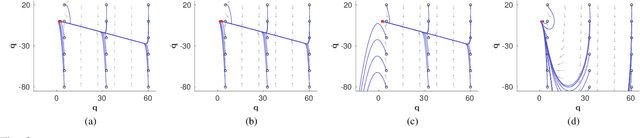
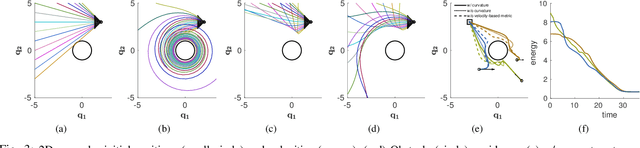
Generating robot motion for multiple tasks in dynamic environments is challenging, requiring an algorithm to respond reactively while accounting for complex nonlinear relationships between tasks. In this paper, we develop a novel policy synthesis algorithm, RMPflow, based on geometrically consistent transformations of Riemannian Motion Policies (RMPs). RMPs are a class of reactive motion policies that parameterize non-Euclidean behaviors as dynamical systems in intrinsically nonlinear task spaces. Given a set of RMPs designed for individual tasks, RMPflow can combine these policies to generate an expressive global policy, while simultaneously exploiting sparse structure for computational efficiency. We study the geometric properties of RMPflow and provide sufficient conditions for stability. Finally, we experimentally demonstrate that accounting for the natural Riemannian geometry of task policies can simplify classically difficult problems, such as planning through clutter on high-DOF manipulation systems.
MVLidarNet: Real-Time Multi-Class Scene Understanding for Autonomous Driving Using Multiple Views
Jun 09, 2020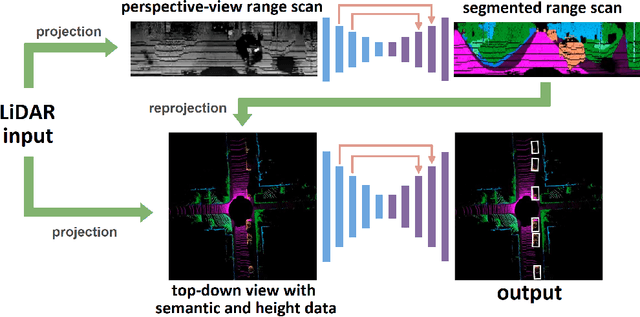
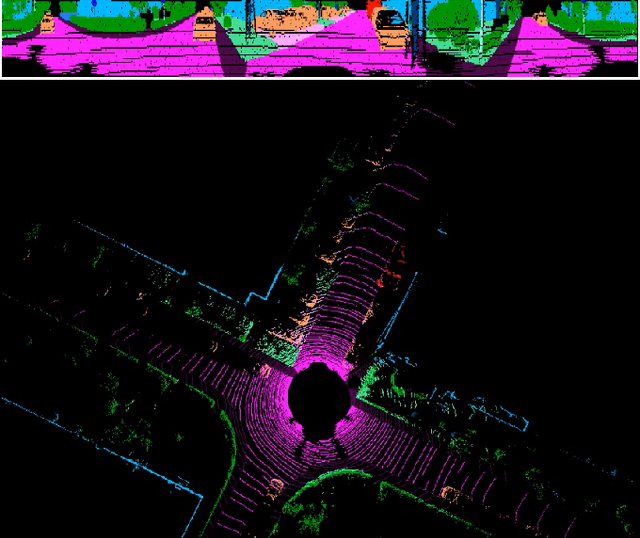


Autonomous driving requires the inference of actionable information such as detecting and classifying objects, and determining the drivable space. To this end, we present a two-stage deep neural network (MVLidarNet) for multi-class object detection and drivable segmentation using multiple views of a single LiDAR point cloud. The first stage processes the point cloud projected onto a perspective view in order to semantically segment the scene. The second stage then processes the point cloud (along with semantic labels from the first stage) projected onto a bird's eye view, to detect and classify objects. Both stages are simple encoder-decoders. We show that our multi-view, multi-stage, multi-class approach is able to detect and classify objects while simultaneously determining the drivable space using a single LiDAR scan as input, in challenging scenes with more than one hundred vehicles and pedestrians at a time. The system operates efficiently at 150 fps on an embedded GPU designed for a self-driving car, including a postprocessing step to maintain identities over time. We show results on both KITTI and a much larger internal dataset, thus demonstrating the method's ability to scale by an order of magnitude.
PAMTRI: Pose-Aware Multi-Task Learning for Vehicle Re-Identification Using Highly Randomized Synthetic Data
May 02, 2020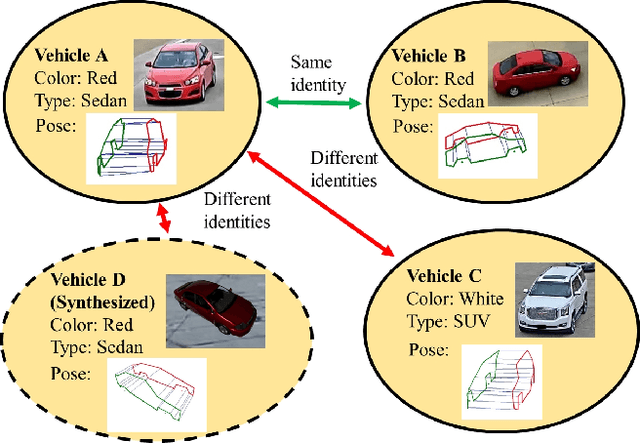
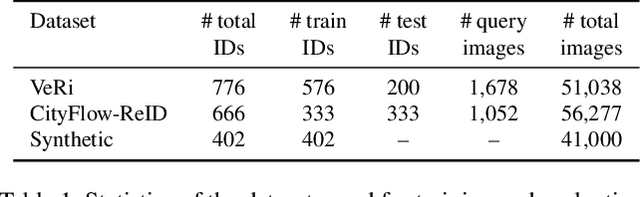
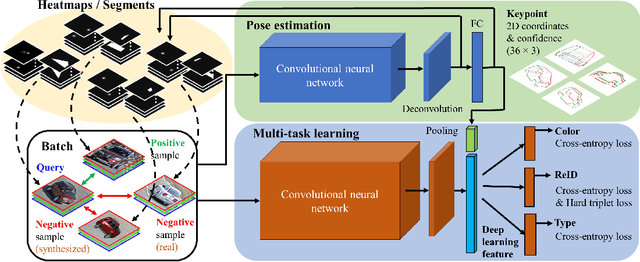
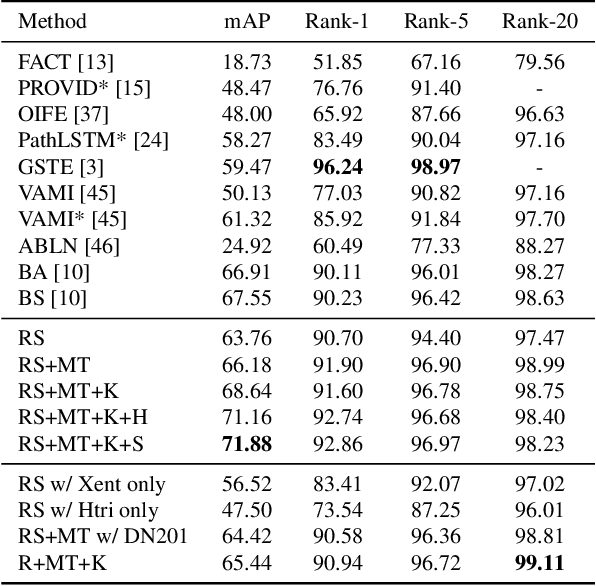
In comparison with person re-identification (ReID), which has been widely studied in the research community, vehicle ReID has received less attention. Vehicle ReID is challenging due to 1) high intra-class variability (caused by the dependency of shape and appearance on viewpoint), and 2) small inter-class variability (caused by the similarity in shape and appearance between vehicles produced by different manufacturers). To address these challenges, we propose a Pose-Aware Multi-Task Re-Identification (PAMTRI) framework. This approach includes two innovations compared with previous methods. First, it overcomes viewpoint-dependency by explicitly reasoning about vehicle pose and shape via keypoints, heatmaps and segments from pose estimation. Second, it jointly classifies semantic vehicle attributes (colors and types) while performing ReID, through multi-task learning with the embedded pose representations. Since manually labeling images with detailed pose and attribute information is prohibitive, we create a large-scale highly randomized synthetic dataset with automatically annotated vehicle attributes for training. Extensive experiments validate the effectiveness of each proposed component, showing that PAMTRI achieves significant improvement over state-of-the-art on two mainstream vehicle ReID benchmarks: VeRi and CityFlow-ReID. Code and models are available at https://github.com/NVlabs/PAMTRI.
Camera-to-Robot Pose Estimation from a Single Image
Dec 05, 2019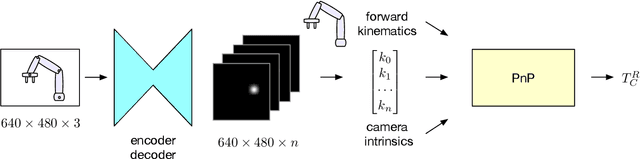

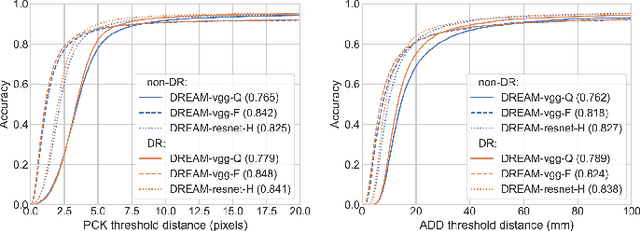
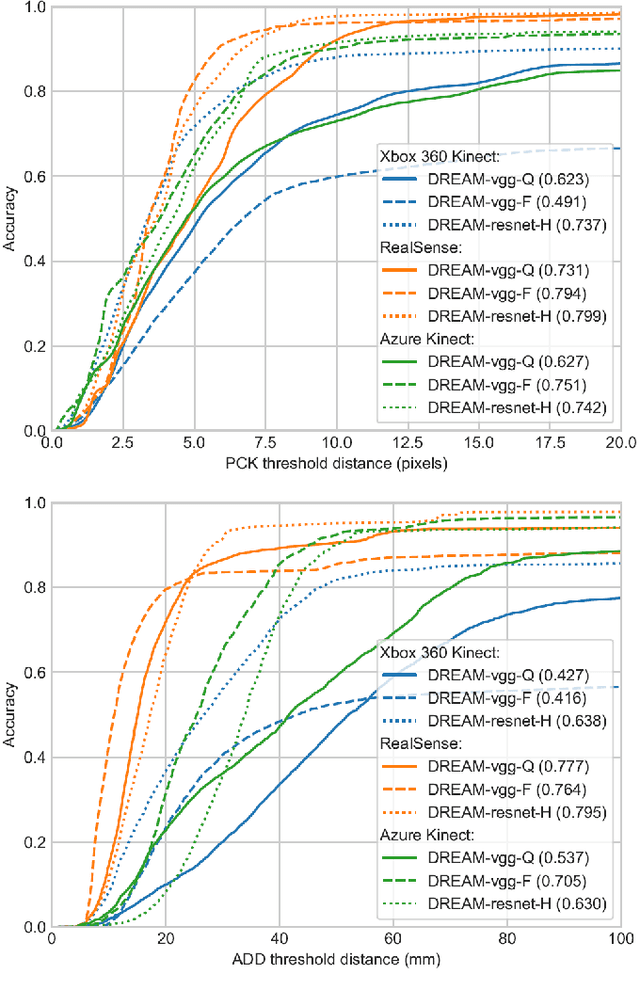
We present an approach for estimating the pose of a camera with respect to a robot from a single image. Our method uses a deep neural network to process an RGB image from the camera to detect 2D keypoints on the robot. The network is trained entirely on simulated data using domain randomization. Perspective-$n$-point (P$n$P) is then used to recover the camera extrinsics, assuming that the joint configuration of the robot manipulator is known. Unlike classic hand-eye calibration systems, our method does not require an off-line calibration step but rather is capable of computing the camera extrinsics from a single frame, thus opening the possibility of on-line calibration. We show experimental results for three different camera sensors, demonstrating that our approach is able to achieve accuracy with a single frame that is better than that of classic off-line hand-eye calibration using multiple frames. With additional frames, accuracy improves even further. Code, datasets, and pretrained models for three widely-used robot manipulators will be made available.
Contextual Reinforcement Learning of Visuo-tactile Multi-fingered Grasping Policies
Nov 24, 2019
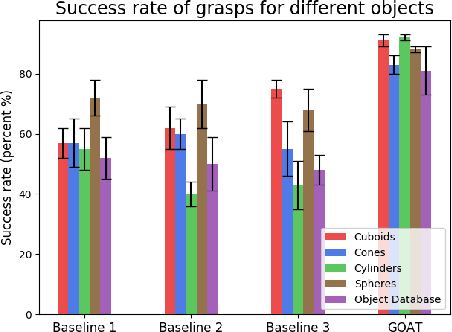
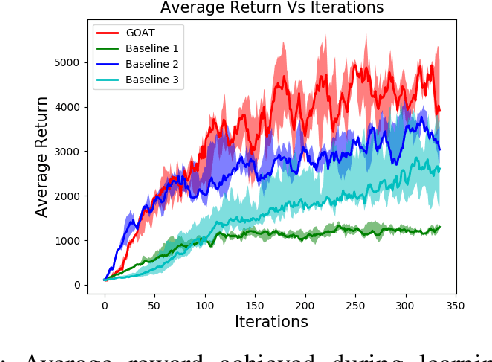
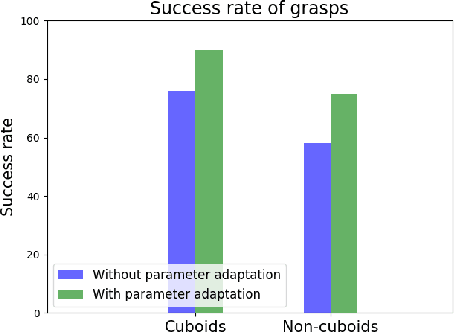
Using simulation to train robot manipulation policies holds the promise of an almost unlimited amount of training data, generated safely out of harm's way. One of the key challenges of using simulation, to date, has been to bridge the reality gap, so that policies trained in simulation can be deployed in the real world. We explore the reality gap in the context of learning a contextual policy for multi-fingered robotic grasping. We propose a Grasping Objects Approach for Tactile (GOAT) robotic hands, learning to overcome the reality gap problem. In our approach we use human hand motion demonstration to initialize and reduce the search space for learning. We contextualize our policy with the bounding cuboid dimensions of the object of interest, which allows the policy to work on a more flexible representation than directly using an image or point cloud. Leveraging fingertip touch sensors in the hand allows the policy to overcome the reduction in geometric information introduced by the coarse bounding box, as well as pose estimation uncertainty. We show our learned policy successfully runs on a real robot without any fine tuning, thus bridging the reality gap.
DexPilot: Vision Based Teleoperation of Dexterous Robotic Hand-Arm System
Oct 14, 2019



Teleoperation offers the possibility of imparting robotic systems with sophisticated reasoning skills, intuition, and creativity to perform tasks. However, current teleoperation solutions for high degree-of-actuation (DoA), multi-fingered robots are generally cost-prohibitive, while low-cost offerings usually provide reduced degrees of control. Herein, a low-cost, vision based teleoperation system, DexPilot, was developed that allows for complete control over the full 23 DoA robotic system by merely observing the bare human hand. DexPilot enables operators to carry out a variety of complex manipulation tasks that go beyond simple pick-and-place operations. This allows for collection of high dimensional, multi-modality, state-action data that can be leveraged in the future to learn sensorimotor policies for challenging manipulation tasks. The system performance was measured through speed and reliability metrics across two human demonstrators on a variety of tasks. The videos of the experiments can be found at https://sites.google.com/view/dex-pilot.
Directional Semantic Grasping of Real-World Objects: From Simulation to Reality
Sep 04, 2019


We present a deep reinforcement learning approach to grasp semantically meaningful objects from a particular direction. The system is trained entirely in simulation, with sim-to-real transfer accomplished by using a simulator that models physical contact and produces photorealistic imagery with domain randomized backgrounds. The system is an example of end-to-end (mapping input monocular RGB images to output Cartesian motor commands) grasping of objects from multiple pre-defined object-centric orientations, such as from the side or top. Coupled with a real-time 6-DoF object pose estimator, the eye-in-hand system is capable of grasping objects anywhere within the graspable workspace. Results are shown in both simulation and the real world, demonstrating the effectiveness of the approach.
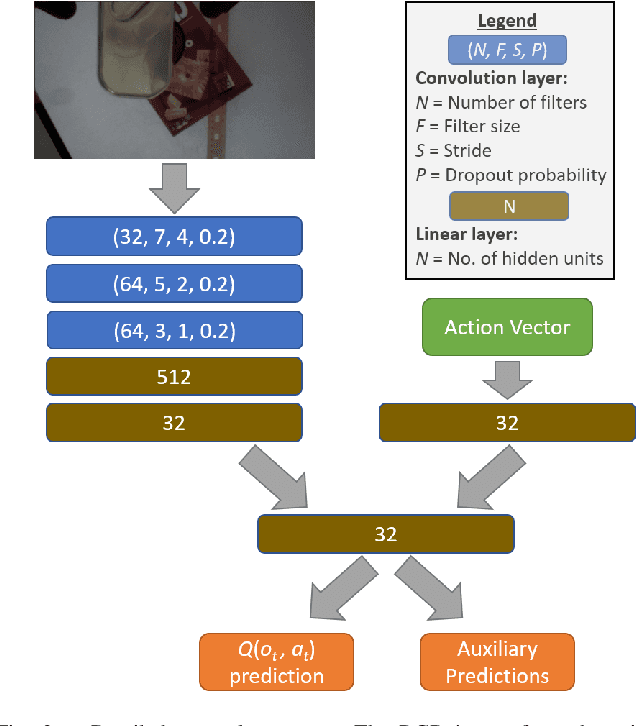
Few-Shot Viewpoint Estimation
May 13, 2019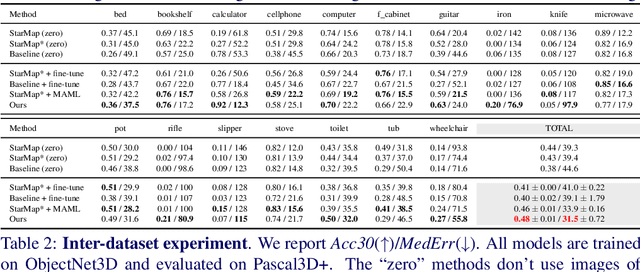
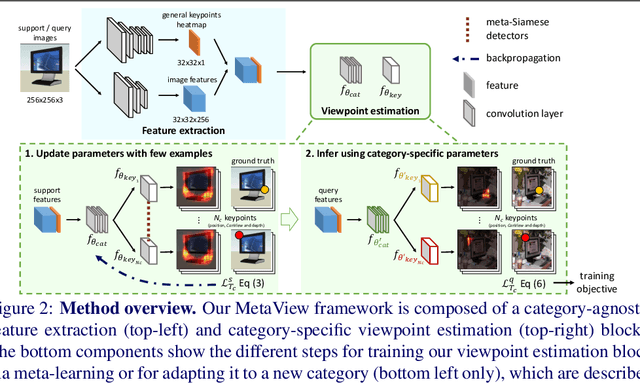
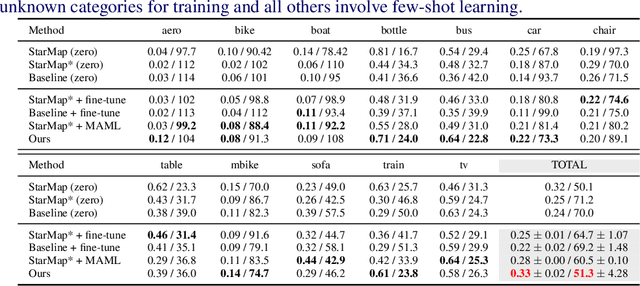
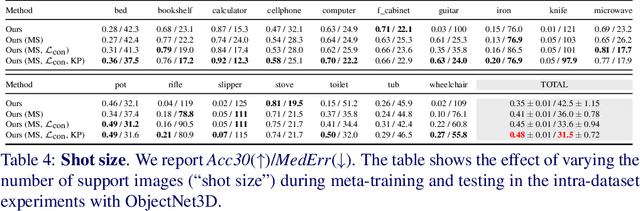
Viewpoint estimation for known categories of objects has been improved significantly thanks to deep networks and large datasets, but generalization to unknown categories is still very challenging. With an aim towards improving performance on unknown categories, we introduce the problem of category-level few-shot viewpoint estimation. We design a novel framework to successfully train viewpoint networks for new categories with few examples (10 or less). We formulate the problem as one of learning to estimate category-specific 3D canonical shapes, their associated depth estimates, and semantic 2D keypoints. We apply meta-learning to learn weights for our network that are amenable to category-specific few-shot fine-tuning. Furthermore, we design a flexible meta-Siamese network that maximizes information sharing during meta-learning. Through extensive experimentation on the ObjectNet3D and Pascal3D+ benchmark datasets, we demonstrate that our framework, which we call MetaView, significantly outperforms fine-tuning the state-of-the-art models with few examples, and that the specific architectural innovations of our method are crucial to achieving good performance.
CityFlow: A City-Scale Benchmark for Multi-Target Multi-Camera Vehicle Tracking and Re-Identification
Apr 05, 2019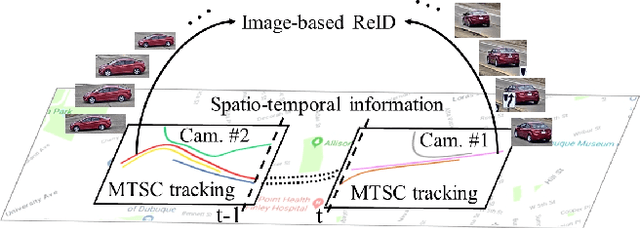
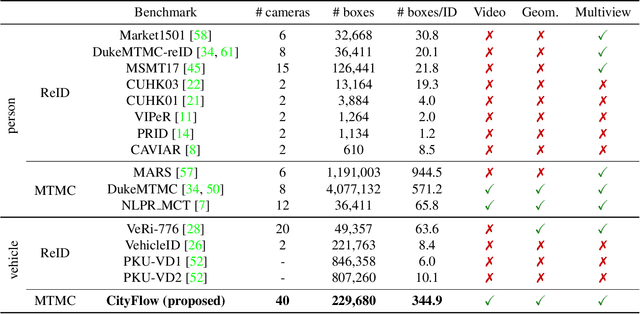
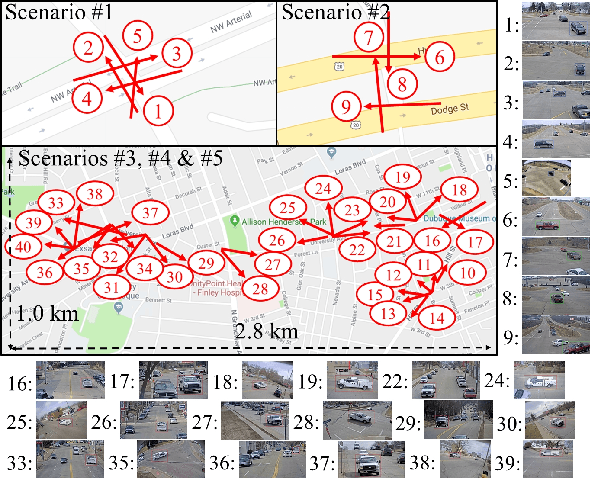
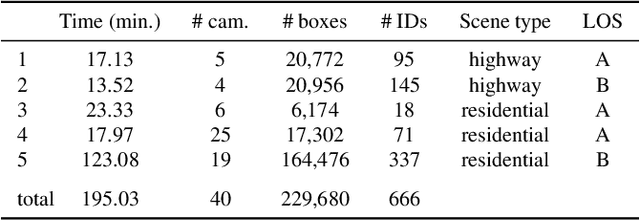
Urban traffic optimization using traffic cameras as sensors is driving the need to advance state-of-the-art multi-target multi-camera (MTMC) tracking. This work introduces CityFlow, a city-scale traffic camera dataset consisting of more than 3 hours of synchronized HD videos from 40 cameras across 10 intersections, with the longest distance between two simultaneous cameras being 2.5 km. To the best of our knowledge, CityFlow is the largest-scale dataset in terms of spatial coverage and the number of cameras/videos in an urban environment. The dataset contains more than 200K annotated bounding boxes covering a wide range of scenes, viewing angles, vehicle models, and urban traffic flow conditions. Camera geometry and calibration information are provided to aid spatio-temporal analysis. In addition, a subset of the benchmark is made available for the task of image-based vehicle re-identification (ReID). We conducted an extensive experimental evaluation of baselines/state-of-the-art approaches in MTMC tracking, multi-target single-camera (MTSC) tracking, object detection, and image-based ReID on this dataset, analyzing the impact of different network architectures, loss functions, spatio-temporal models and their combinations on task effectiveness. An evaluation server is launched with the release of our benchmark at the 2019 AI City Challenge (https://www.aicitychallenge.org/) that allows researchers to compare the performance of their newest techniques. We expect this dataset to catalyze research in this field, propel the state-of-the-art forward, and lead to deployed traffic optimization(s) in the real world.
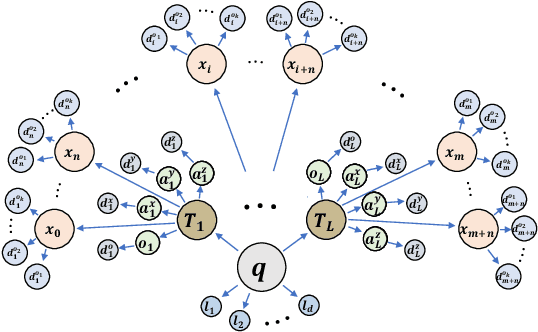
RMPflow: A Computational Graph for Automatic Motion Policy Generation
Apr 05, 2019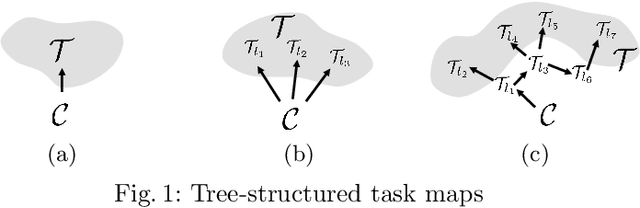
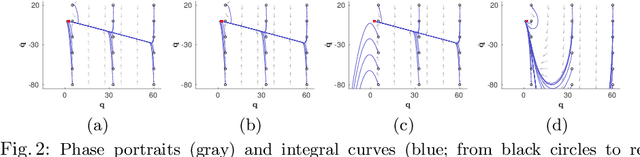
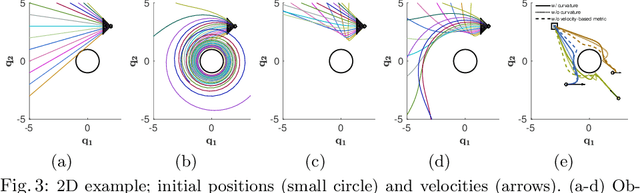
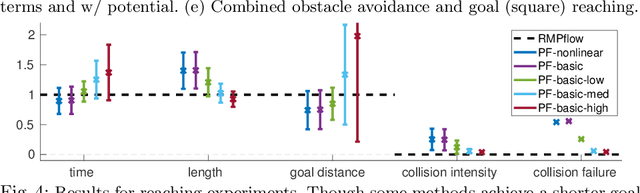
We develop a novel policy synthesis algorithm, RMPflow, based on geometrically consistent transformations of Riemannian Motion Policies (RMPs). RMPs are a class of reactive motion policies designed to parameterize non-Euclidean behaviors as dynamical systems in intrinsically nonlinear task spaces. Given a set of RMPs designed for individual tasks, RMPflow can consistently combine these local policies to generate an expressive global policy, while simultaneously exploiting sparse structure for computational efficiency. We study the geometric properties of RMPflow and provide sufficient conditions for stability. Finally, we experimentally demonstrate that accounting for the geometry of task policies can simplify classically difficult problems, such as planning through clutter on high-DOF manipulation systems.