 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion Growing Curriculum Generation for Reinforcement Learning
Paper and Code
Jul 04, 2018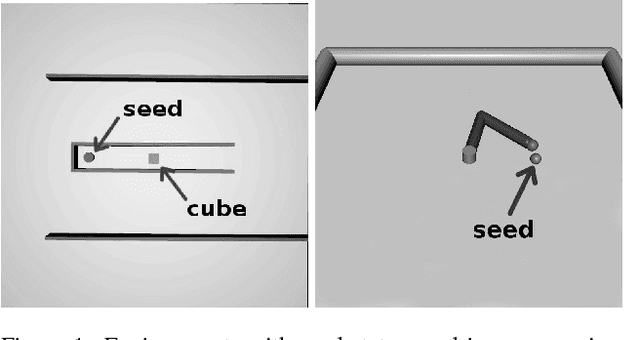
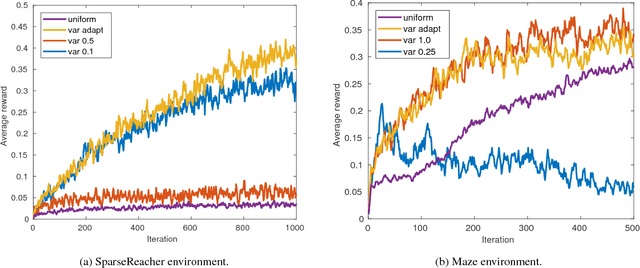
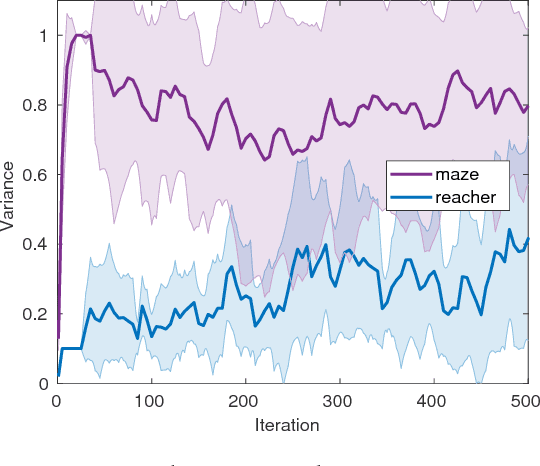
Learning a policy capable of moving an agent between any two states in the environment is important for many robotics problems involving navigation and manipulation. Due to the sparsity of rewards in such tasks, applying reinforcement learning in these scenarios can be challenging. Common approaches for tackling this problem include reward engineering with auxiliary rewards, requiring domain-specific knowledge or changing the objective. In this work, we introduce a method based on region-growing that allows learning in an environment with any pair of initial and goal states. Our algorithm first learns how to move between nearby states and then increases the difficulty of the start-goal transitions as the agent's performance improves. This approach creates an efficient curriculum for learning the objective behavior of reaching any goal from any initial state. In addition, we describe a method to adaptively adjust expansion of the growing region that allows automatic adjustment of the key exploration hyperparameter to environments with different requirements. We evaluate our approach on a set of simulated navigation and manipulation tasks, where we demonstrate that our algorithm can efficiently learn a policy in the presence of sparse rewards.