 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI for System Failures: Generating Explanations that Improve Human Assistance in Fault Recovery
Nov 19, 2020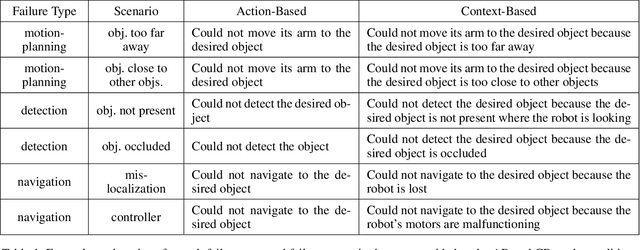

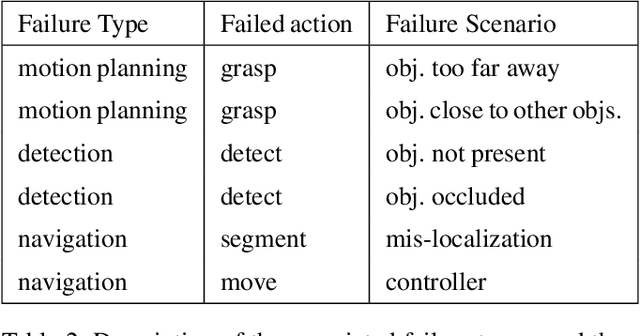
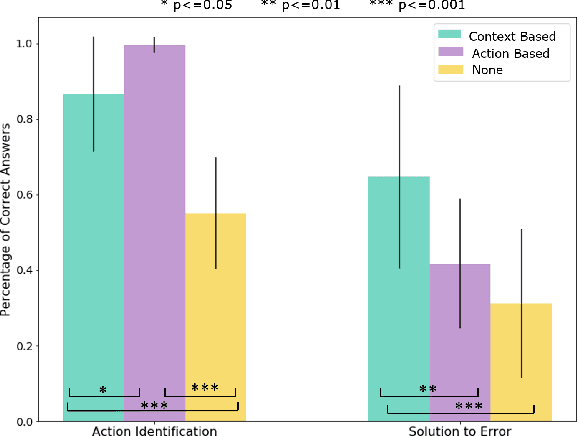
With the growing capabilities of intelligent systems, the integration of artificial intelligence (AI) and robots in everyday life is increasing. However, when interacting in such complex human environments, the failure of intelligent systems, such as robots, can be inevitable, requiring recovery assistance from users. In this work, we develop automated, natural language explanations for failures encountered during an AI agents' plan execution. These explanations are developed with a focus of helping non-expert users understand different point of failures to better provide recovery assistance. Specifically, we introduce a context-based information type for explanations that can both help non-expert users understand the underlying cause of a system failure, and select proper failure recoveries. Additionally, we extend an existing sequence-to-sequence methodology to automatically generate our context-based explanations. By doing so, we are able develop a model that can generalize context-based explanations over both different failure types and failure scenarios.
Same Object, Different Grasps: Data and Semantic Knowledge for Task-Oriented Grasping
Nov 13, 2020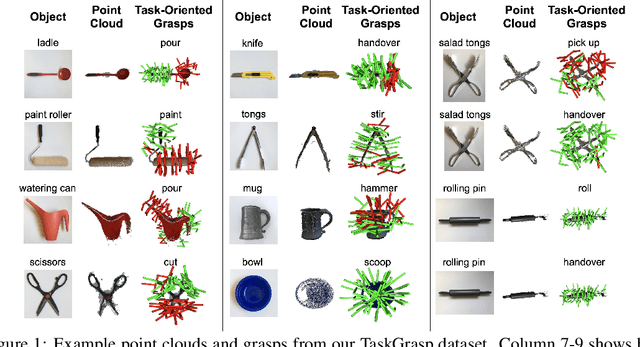

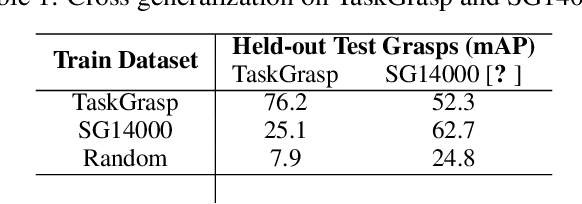

Despite the enormous progress and generalization in robotic grasping in recent years, existing methods have yet to scale and generalize task-oriented grasping to the same extent. This is largely due to the scale of the datasets both in terms of the number of objects and tasks studied. We address these concerns with the TaskGrasp dataset which is more diverse both in terms of objects and tasks, and an order of magnitude larger than previous datasets. The dataset contains 250K task-oriented grasps for 56 tasks and 191 objects along with their RGB-D information. We take advantage of this new breadth and diversity in the data and present the GCNGrasp framework which uses the semantic knowledge of objects and tasks encoded in a knowledge graph to generalize to new object instances, classes and even new tasks. Our framework shows a significant improvement of around 12% on held-out settings compared to baseline methods which do not use semantics. We demonstrate that our dataset and model are applicable for the real world by executing task-oriented grasps on a real robot on unknown objects. Code, data and supplementary video could be found at https://sites.google.com/view/taskgrasp
Rearrangement: A Challenge for Embodied AI
Nov 03, 2020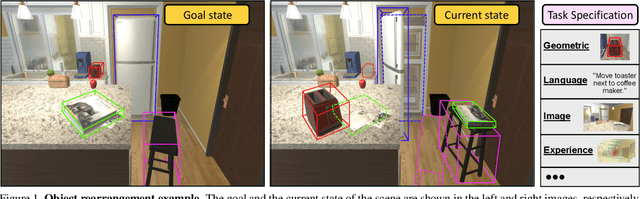
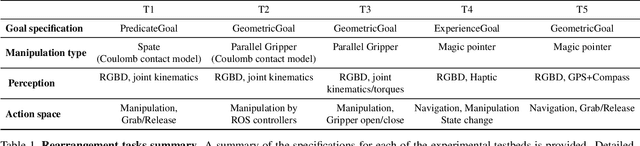


We describe a framework for research and evaluation in Embodied AI. Our proposal is based on a canonical task: Rearrangement. A standard task can focus the development of new techniques and serve as a source of trained models that can be transferred to other settings. In the rearrangement task, the goal is to bring a given physical environment into a specified state. The goal state can be specified by object poses, by images, by a description in language, or by letting the agent experience the environment in the goal state. We characterize rearrangement scenarios along different axes and describe metrics for benchmarking rearrangement performance. To facilitate research and exploration, we present experimental testbeds of rearrangement scenarios in four different simulation environments. We anticipate that other datasets will be released and new simulation platforms will be built to support training of rearrangement agents and their deployment on physical systems.
Feature Guided Search for Creative Problem Solving Through Tool Construction
Aug 24, 2020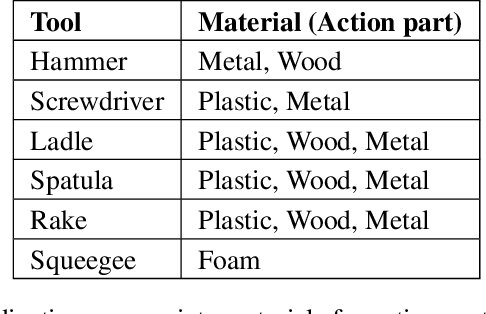


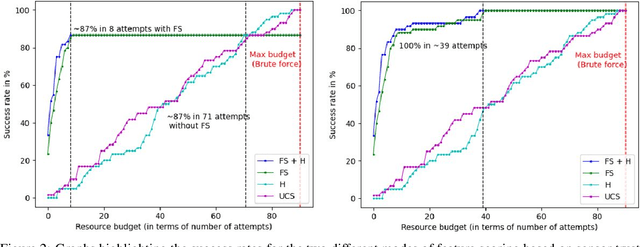
Robots in the real world should be able to adapt to unforeseen circumstances. Particularly in the context of tool use, robots may not have access to the tools they need for completing a task. In this paper, we focus on the problem of tool construction in the context of task planning. We seek to enable robots to construct replacements for missing tools using available objects, in order to complete the given task. We introduce the Feature Guided Search (FGS) algorithm that enables the application of existing heuristic search approaches in the context of task planning, to perform tool construction efficiently. FGS accounts for physical attributes of objects (e.g., shape, material) during the search for a valid task plan. Our results demonstrate that FGS significantly reduces the search effort over standard heuristic search approaches by approximately 93% for tool construction.
Tool Macgyvering: A Novel Framework for Combining Tool Substitution and Construction
Aug 24, 2020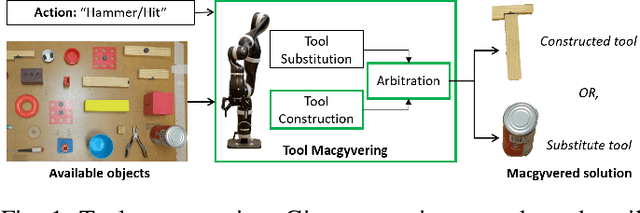
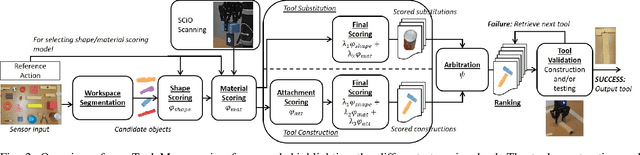
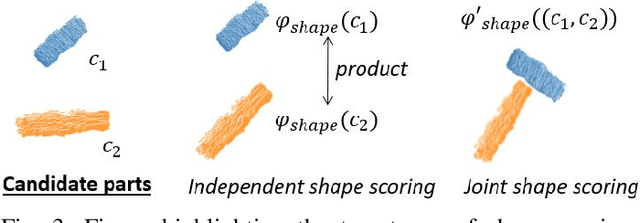
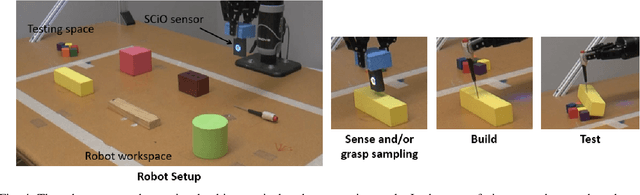
Macgyvering refers to solving problems inventively by using whatever objects are available at hand. Tool Macgyvering is a subset of macgyvering tasks involving a missing tool that is either substituted (tool substitution) or constructed (tool construction), from available objects. In this paper, we introduce a novel Tool Macgyvering framework that combines tool substitution and construction using arbitration that decides between the two options to output a final macgyvering solution. Our tool construction approach reasons about the shape, material, and different ways of attaching objects to construct a desired tool. We further develop value functions that enable the robot to effectively arbitrate between substitution and construction. Our results show that our tool construction approach is able to successfully construct working tools with an accuracy of 96.67%, and our arbitration strategy successfully chooses between substitution and construction with an accuracy of 83.33%.
Anticipatory Human-Robot Collaboration via Multi-Objective Trajectory Optimization
Jun 05, 2020
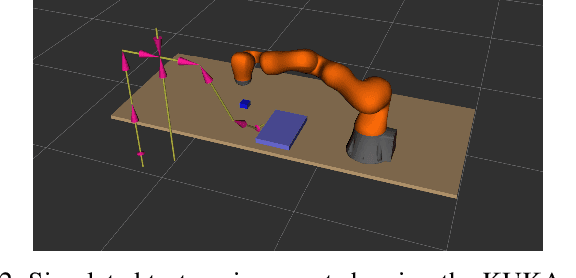

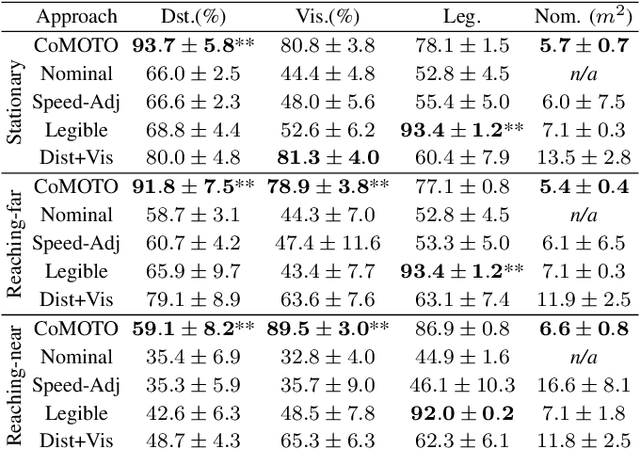
We address the problem of adapting robot trajectories to improve safety, comfort, and efficiency in human-robot collaborative tasks. To this end, we propose CoMOTO, a trajectory optimization framework that utilizes stochastic motion prediction models to anticipate the human's motion and adapt the robot's joint trajectory accordingly. We design a multi-objective cost function that simultaneously optimizes for i) separation distance, ii) visibility of the end-effector, iii) legibility, iv) efficiency, and v) smoothness. We evaluate CoMOTO against three existing methods for robot trajectory generation when in close proximity to humans. Our experimental results indicate that our approach consistently outperforms existing methods over a combined set of safety, comfort, and efficiency metrics.
Human-Centric Active Perception for Autonomous Observation
May 29, 2020

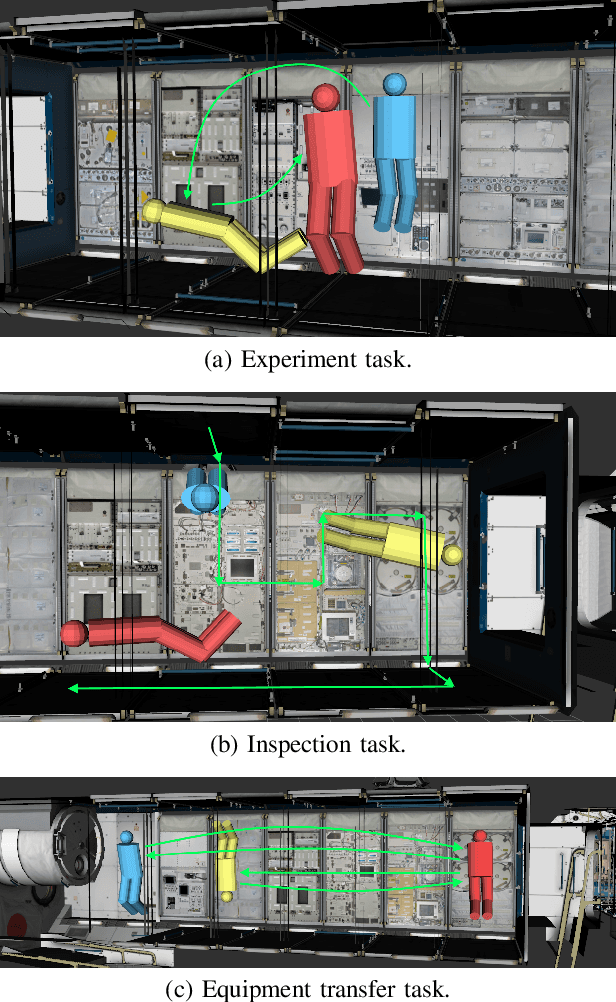
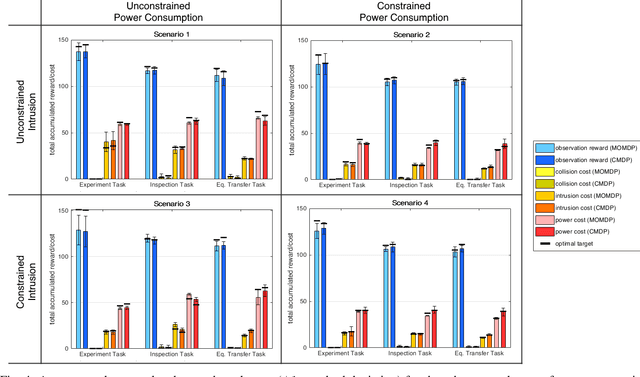
As robot autonomy improves, robots are increasingly being considered in the role of autonomous observation systems -- free-flying cameras capable of actively tracking human activity within some predefined area of interest. In this work, we formulate the autonomous observation problem through multi-objective optimization, presenting a novel Semi-MDP formulation of the autonomous human observation problem that maximizes observation rewards while accounting for both human- and robot-centric costs. We demonstrate that the problem can be solved with both scalarization-based Multi-Objective MDP methods and Constrained MDP methods, and discuss the relative benefits of each approach. We validate our work on activity tracking using a NASA Astrobee robot operating within a simulated International Space Station environment.
Multimodal Material Classification for Robots using Spectroscopy and High Resolution Texture Imaging
Apr 02, 2020



Material recognition can help inform robots about how to properly interact with and manipulate real-world objects. In this paper, we present a multimodal sensing technique, leveraging near-infrared spectroscopy and close-range high resolution texture imaging, that enables robots to estimate the materials of household objects. We release a dataset of high resolution texture images and spectral measurements collected from a mobile manipulator that interacted with 144 household objects. We then present a neural network architecture that learns a compact multimodal representation of spectral measurements and texture images. When generalizing material classification to new objects, we show that this multimodal representation enables a robot to recognize materials with greater performance as compared to prior state-of-the-art approaches. Finally, we present how a robot can combine this high resolution local sensing with images from the robot's head-mounted camera to achieve accurate material classification over a scene of objects on a table.
Leveraging Rationales to Improve Human Task Performance
Feb 11, 2020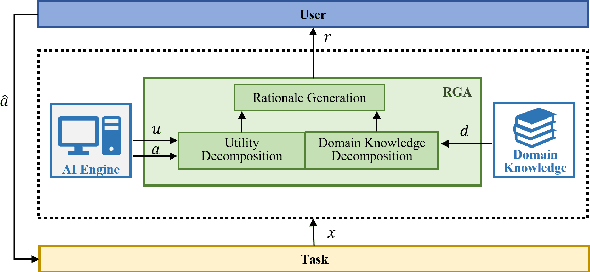
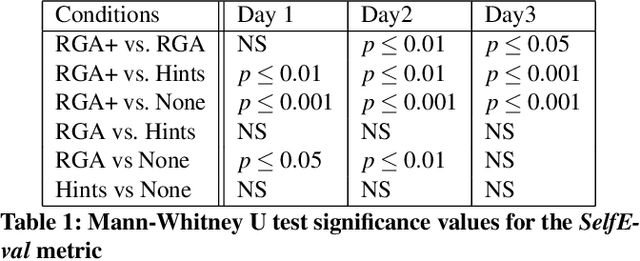
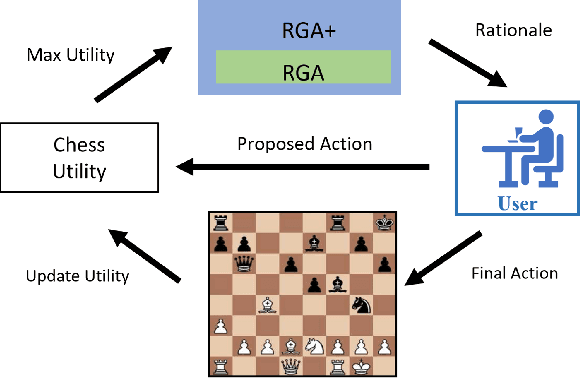
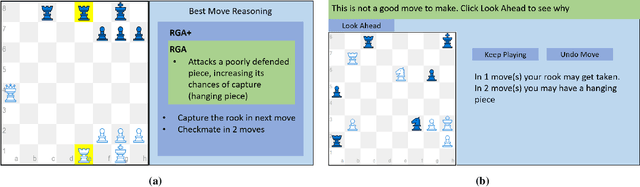
Machine learning (ML) systems across many application areas are increasingly demonstrating performance that is beyond that of humans. In response to the proliferation of such models, the field of Explainable AI (XAI) has sought to develop techniques that enhance the transparency and interpretability of machine learning methods. In this work, we consider a question not previously explored within the XAI and ML communities: Given a computational system whose performance exceeds that of its human user, can explainable AI capabilities be leveraged to improve the performance of the human? We study this question in the context of the game of Chess, for which computational game engines that surpass the performance of the average player are widely available. We introduce the Rationale-Generating Algorithm, an automated technique for generating rationales for utility-based computational methods, which we evaluate with a multi-day user study against two baselines. The results show that our approach produces rationales that lead to statistically significant improvement in human task performance, demonstrating that rationales automatically generated from an AI's internal task model can be used not only to explain what the system is doing, but also to instruct the user and ultimately improve their task performance.
Taking Recoveries to Task: Recovery-Driven Development for Recipe-based Robot Tasks
Jan 28, 2020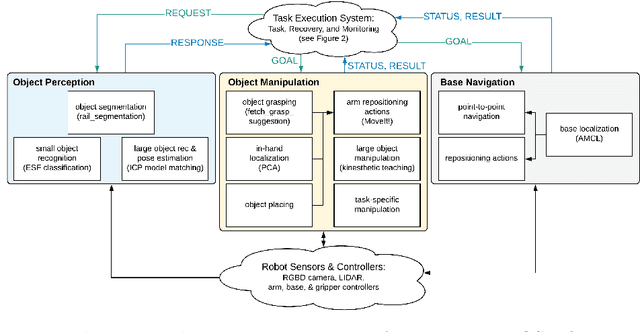
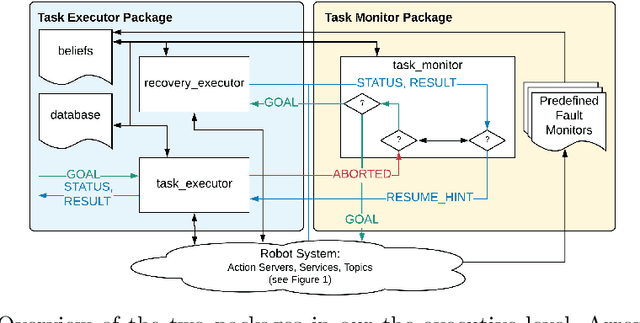

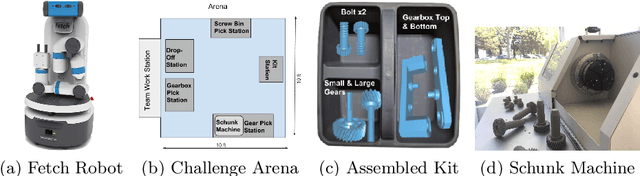
Robot task execution when situated in real-world environments is fragile. As such, robot architectures must rely on robust error recovery, adding non-trivial complexity to highly-complex robot systems. To handle this complexity in development, we introduce Recovery-Driven Development (RDD), an iterative task scripting process that facilitates rapid task and recovery development by leveraging hierarchical specification, separation of nominal task and recovery development, and situated testing. We validate our approach with our challenge-winning mobile manipulator software architecture developed using RDD for the FetchIt! Challenge at the IEEE 2019 International Conference on Robotics and Automation. We attribute the success of our system to the level of robustness achieved using RDD, and conclude with lessons learned for developing such systems.