 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Interpretability of Codebooks in Model-Based Reinforcement Learning is Limited
Jul 28, 2024



Interpretability of deep reinforcement learning systems could assist operators with understanding how they interact with their environment. Vector quantization methods -- also called codebook methods -- discretize a neural network's latent space that is often suggested to yield emergent interpretability. We investigate whether vector quantization in fact provides interpretability in model-based reinforcement learning. Our experiments, conducted in the reinforcement learning environment Crafter, show that the codes of vector quantization models are inconsistent, have no guarantee of uniqueness, and have a limited impact on concept disentanglement, all of which are necessary traits for interpretability. We share insights on why vector quantization may be fundamentally insufficient for model interpretability.
External Model Motivated Agents: Reinforcement Learning for Enhanced Environment Sampling
Jun 28, 2024



Unlike reinforcement learning (RL) agents, humans remain capable multitaskers in changing environments. In spite of only experiencing the world through their own observations and interactions, people know how to balance focusing on tasks with learning about how changes may affect their understanding of the world. This is possible by choosing to solve tasks in ways that are interesting and generally informative beyond just the current task. Motivated by this, we propose an agent influence framework for RL agents to improve the adaptation efficiency of external models in changing environments without any changes to the agent's rewards. Our formulation is composed of two self-contained modules: interest fields and behavior shaping via interest fields. We implement an uncertainty-based interest field algorithm as well as a skill-sampling-based behavior-shaping algorithm to use in testing this framework. Our results show that our method outperforms the baselines in terms of external model adaptation on metrics that measure both efficiency and performance.
A Simple Way to Incorporate Novelty Detection in World Models
Oct 12, 2023



Reinforcement learning (RL) using world models has found significant recent successes. However, when a sudden change to world mechanics or properties occurs then agent performance and reliability can dramatically decline. We refer to the sudden change in visual properties or state transitions as {\em novelties}. Implementing novelty detection within generated world model frameworks is a crucial task for protecting the agent when deployed. In this paper, we propose straightforward bounding approaches to incorporate novelty detection into world model RL agents, by utilizing the misalignment of the world model's hallucinated states and the true observed states as an anomaly score. We first provide an ontology of novelty detection relevant to sequential decision making, then we provide effective approaches to detecting novelties in a distribution of transitions learned by an agent in a world model. Finally, we show the advantage of our work in a novel environment compared to traditional machine learning novelty detection methods as well as currently accepted RL focused novelty detection algorithms.
Neuro-Symbolic World Models for Adapting to Open World Novelty
Jan 16, 2023



Open-world novelty--a sudden change in the mechanics or properties of an environment--is a common occurrence in the real world. Novelty adaptation is an agent's ability to improve its policy performance post-novelty. Most reinforcement learning (RL) methods assume that the world is a closed, fixed process. Consequentially, RL policies adapt inefficiently to novelties. To address this, we introduce WorldCloner, an end-to-end trainable neuro-symbolic world model for rapid novelty adaptation. WorldCloner learns an efficient symbolic representation of the pre-novelty environment transitions, and uses this transition model to detect novelty and efficiently adapt to novelty in a single-shot fashion. Additionally, WorldCloner augments the policy learning process using imagination-based adaptation, where the world model simulates transitions of the post-novelty environment to help the policy adapt. By blending ''imagined'' transitions with interactions in the post-novelty environment, performance can be recovered with fewer total environment interactions. Using environments designed for studying novelty in sequential decision-making problems, we show that the symbolic world model helps its neural policy adapt more efficiently than model-based and model-based neural-only reinforcement learning methods.
NovGrid: A Flexible Grid World for Evaluating Agent Response to Novelty
Mar 23, 2022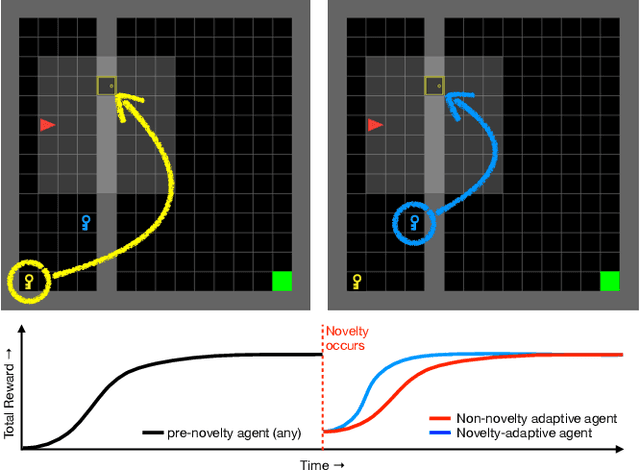
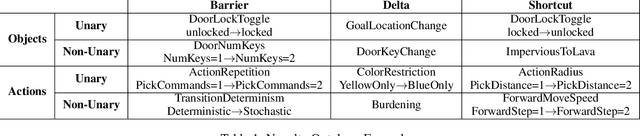
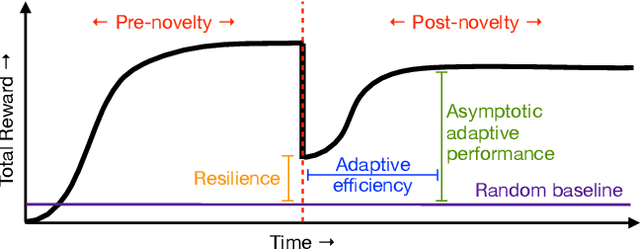
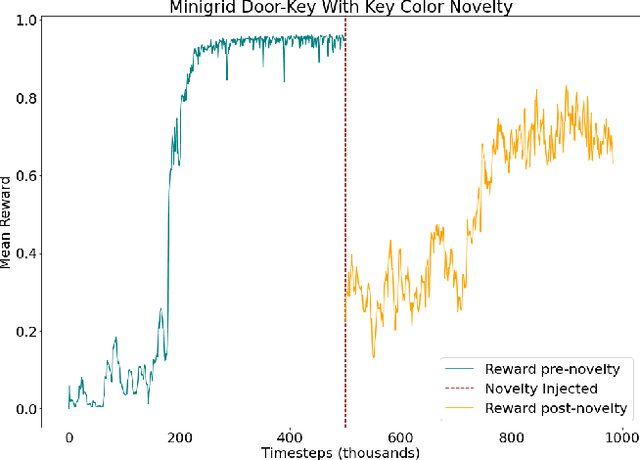
A robust body of reinforcement learning techniques have been developed to solve complex sequential decision making problems. However, these methods assume that train and evaluation tasks come from similarly or identically distributed environments. This assumption does not hold in real life where small novel changes to the environment can make a previously learned policy fail or introduce simpler solutions that might never be found. To that end we explore the concept of {\em novelty}, defined in this work as the sudden change to the mechanics or properties of environment. We provide an ontology of for novelties most relevant to sequential decision making, which distinguishes between novelties that affect objects versus actions, unary properties versus non-unary relations, and the distribution of solutions to a task. We introduce NovGrid, a novelty generation framework built on MiniGrid, acting as a toolkit for rapidly developing and evaluating novelty-adaptation-enabled reinforcement learning techniques. Along with the core NovGrid we provide exemplar novelties aligned with our ontology and instantiate them as novelty templates that can be applied to many MiniGrid-compliant environments. Finally, we present a set of metrics built into our framework for the evaluation of novelty-adaptation-enabled machine-learning techniques, and show characteristics of a baseline RL model using these metrics.
Automated Story Generation as Question-Answering
Dec 07, 2021
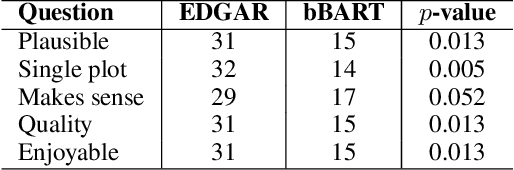
Neural language model-based approaches to automated story generation suffer from two important limitations. First, language model-based story generators generally do not work toward a given goal or ending. Second, they often lose coherence as the story gets longer. We propose a novel approach to automated story generation that treats the problem as one of generative question-answering. Our proposed story generation system starts with sentences encapsulating the final event of the story. The system then iteratively (1) analyzes the text describing the most recent event, (2) generates a question about "why" a character is doing the thing they are doing in the event, and then (3) attempts to generate another, preceding event that answers this question.
Always Be Dreaming: A New Approach for Data-Free Class-Incremental Learning
Jun 17, 2021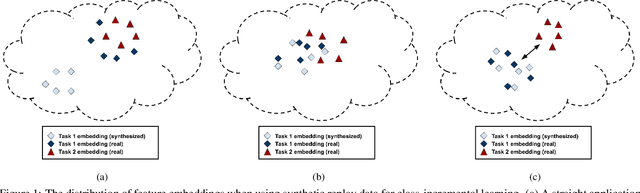
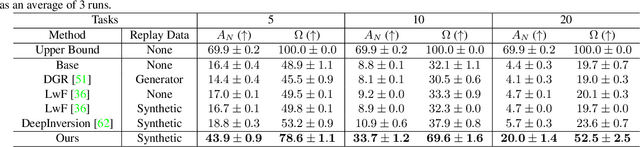
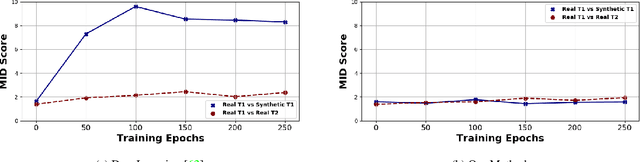

Modern computer vision applications suffer from catastrophic forgetting when incrementally learning new concepts over time. The most successful approaches to alleviate this forgetting require extensive replay of previously seen data, which is problematic when memory constraints or data legality concerns exist. In this work, we consider the high-impact problem of Data-Free Class-Incremental Learning (DFCIL), where an incremental learning agent must learn new concepts over time without storing generators or training data from past tasks. One approach for DFCIL is to replay synthetic images produced by inverting a frozen copy of the learner's classification model, but we show this approach fails for common class-incremental benchmarks when using standard distillation strategies. We diagnose the cause of this failure and propose a novel incremental distillation strategy for DFCIL, contributing a modified cross-entropy training and importance-weighted feature distillation, and show that our method results in up to a 25.1% increase in final task accuracy (absolute difference) compared to SOTA DFCIL methods for common class-incremental benchmarks. Our method even outperforms several standard replay based methods which store a coreset of images.
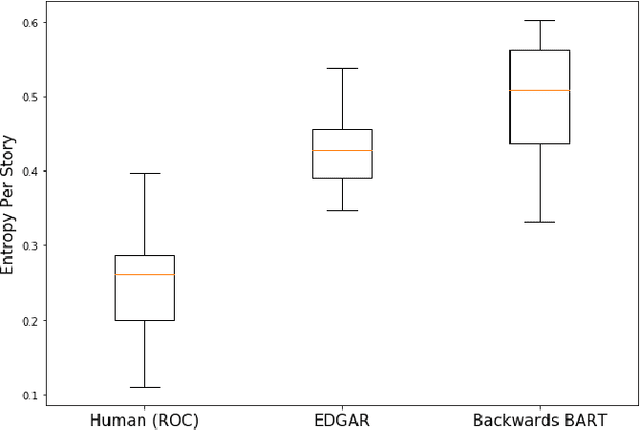
Fabula Entropy Indexing: Objective Measures of Story Coherence
Mar 23, 2021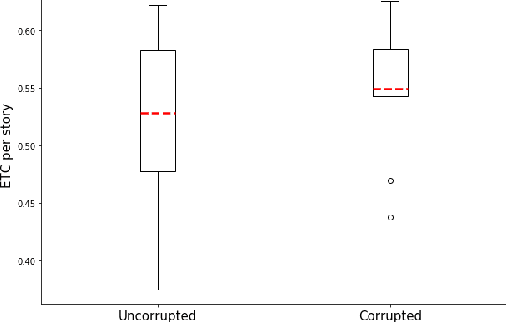
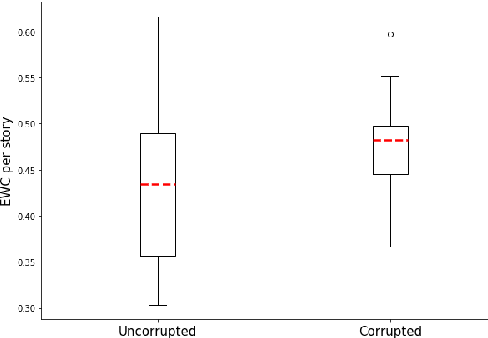
Automated story generation remains a difficult area of research because it lacks strong objective measures. Generated stories may be linguistically sound, but in many cases suffer poor narrative coherence required for a compelling, logically-sound story. To address this, we present Fabula Entropy Indexing (FEI), an evaluation method to assess story coherence by measuring the degree to which human participants agree with each other when answering true/false questions about stories. We devise two theoretically grounded measures of reader question-answering entropy, the entropy of world coherence (EWC), and the entropy of transitional coherence (ETC), focusing on global and local coherence, respectively. We evaluate these metrics by testing them on human-written stories and comparing against the same stories that have been corrupted to introduce incoherencies. We show that in these controlled studies, our entropy indices provide a reliable objective measure of story coherence.
Memory-Efficient Semi-Supervised Continual Learning: The World is its Own Replay Buffer
Jan 23, 2021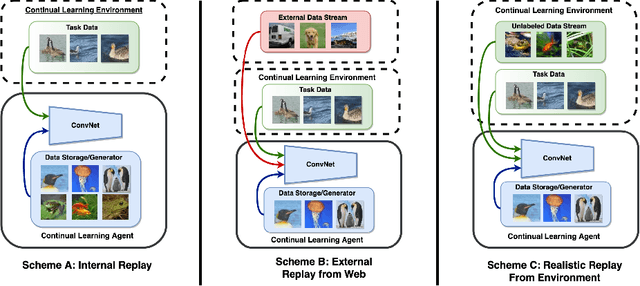
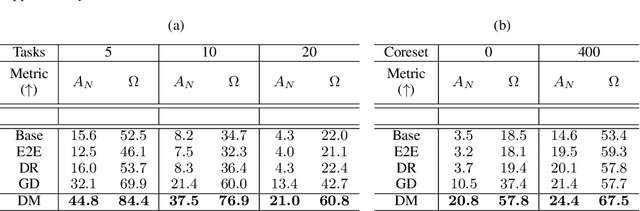
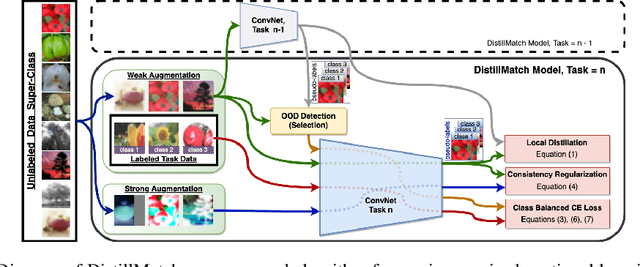
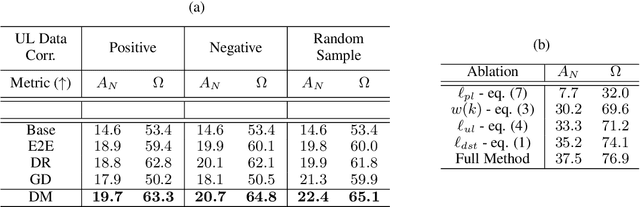
Rehearsal is a critical component for class-incremental continual learning, yet it requires a substantial memory budget. Our work investigates whether we can significantly reduce this memory budget by leveraging unlabeled data from an agent's environment in a realistic and challenging continual learning paradigm. Specifically, we explore and formalize a novel semi-supervised continual learning (SSCL) setting, where labeled data is scarce yet non-i.i.d. unlabeled data from the agent's environment is plentiful. Importantly, data distributions in the SSCL setting are realistic and therefore reflect object class correlations between, and among, the labeled and unlabeled data distributions. We show that a strategy built on pseudo-labeling, consistency regularization, Out-of-Distribution (OoD) detection, and knowledge distillation reduces forgetting in this setting. Our approach, DistillMatch, increases performance over the state-of-the-art by no less than 8.7% average task accuracy and up to a 54.5% increase in average task accuracy in SSCL CIFAR-100 experiments. Moreover, we demonstrate that DistillMatch can save up to 0.23 stored images per processed unlabeled image compared to the next best method which only saves 0.08. Our results suggest that focusing on realistic correlated distributions is a significantly new perspective, which accentuates the importance of leveraging the world's structure as a continual learning strategy.
Taking Recoveries to Task: Recovery-Driven Development for Recipe-based Robot Tasks
Jan 28, 2020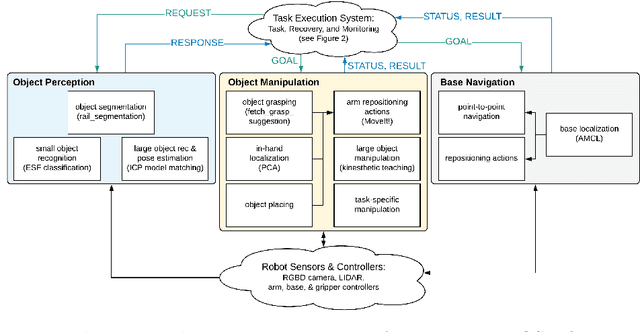
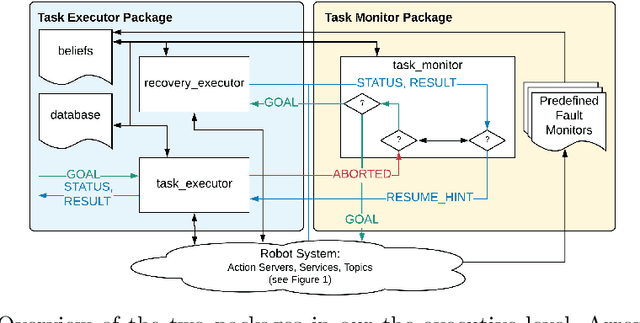

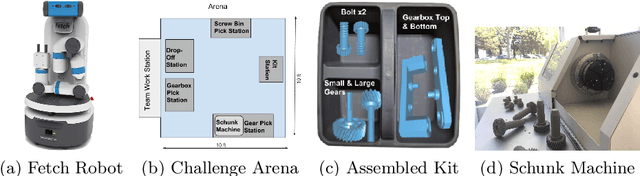
Robot task execution when situated in real-world environments is fragile. As such, robot architectures must rely on robust error recovery, adding non-trivial complexity to highly-complex robot systems. To handle this complexity in development, we introduce Recovery-Driven Development (RDD), an iterative task scripting process that facilitates rapid task and recovery development by leveraging hierarchical specification, separation of nominal task and recovery development, and situated testing. We validate our approach with our challenge-winning mobile manipulator software architecture developed using RDD for the FetchIt! Challenge at the IEEE 2019 International Conference on Robotics and Automation. We attribute the success of our system to the level of robustness achieved using RDD, and conclude with lessons learned for developing such systems.