 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Models as a Source of Rewards
Dec 14, 2023



Building generalist agents that can accomplish many goals in rich open-ended environments is one of the research frontiers for reinforcement learning. A key limiting factor for building generalist agents with RL has been the need for a large number of reward functions for achieving different goals. We investigate the feasibility of using off-the-shelf vision-language models, or VLMs, as sources of rewards for reinforcement learning agents. We show how rewards for visual achievement of a variety of language goals can be derived from the CLIP family of models, and used to train RL agents that can achieve a variety of language goals. We showcase this approach in two distinct visual domains and present a scaling trend showing how larger VLMs lead to more accurate rewards for visual goal achievement, which in turn produces more capable RL agents.
Structured State Space Models for In-Context Reinforcement Learning
Mar 09, 2023



Structured state space sequence (S4) models have recently achieved state-of-the-art performance on long-range sequence modeling tasks. These models also have fast inference speeds and parallelisable training, making them potentially useful in many reinforcement learning settings. We propose a modification to a variant of S4 that enables us to initialise and reset the hidden state in parallel, allowing us to tackle reinforcement learning tasks. We show that our modified architecture runs asymptotically faster than Transformers and performs better than LSTM models on a simple memory-based task. Then, by leveraging the model's ability to handle long-range sequences, we achieve strong performance on a challenging meta-learning task in which the agent is given a randomly-sampled continuous control environment, combined with a randomly-sampled linear projection of the environment's observations and actions. Furthermore, we show the resulting model can adapt to out-of-distribution held-out tasks. Overall, the results presented in this paper suggest that the S4 models are a strong contender for the default architecture used for in-context reinforcement learning
Human-Timescale Adaptation in an Open-Ended Task Space
Jan 18, 2023



Foundation models have shown impressive adaptation and scalability in supervised and self-supervised learning problems, but so far these successes have not fully translated to reinforcement learning (RL). In this work, we demonstrate that training an RL agent at scale leads to a general in-context learning algorithm that can adapt to open-ended novel embodied 3D problems as quickly as humans. In a vast space of held-out environment dynamics, our adaptive agent (AdA) displays on-the-fly hypothesis-driven exploration, efficient exploitation of acquired knowledge, and can successfully be prompted with first-person demonstrations. Adaptation emerges from three ingredients: (1) meta-reinforcement learning across a vast, smooth and diverse task distribution, (2) a policy parameterised as a large-scale attention-based memory architecture, and (3) an effective automated curriculum that prioritises tasks at the frontier of an agent's capabilities. We demonstrate characteristic scaling laws with respect to network size, memory length, and richness of the training task distribution. We believe our results lay the foundation for increasingly general and adaptive RL agents that perform well across ever-larger open-ended domains.
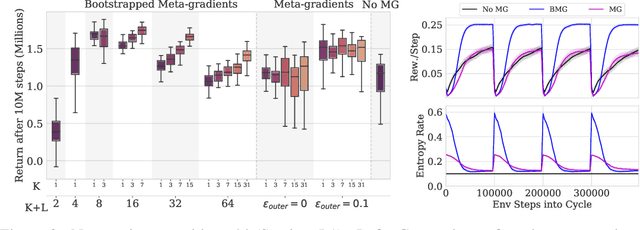
Meta-Gradients in Non-Stationary Environments
Sep 13, 2022
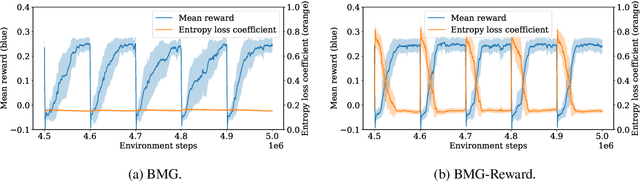
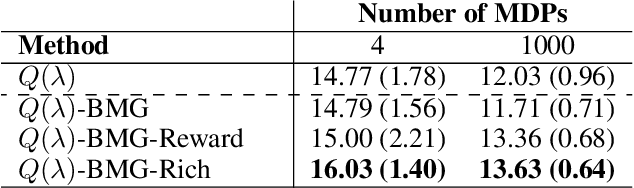
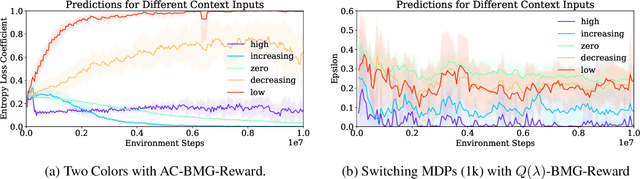
Meta-gradient methods (Xu et al., 2018; Zahavy et al., 2020) offer a promising solution to the problem of hyperparameter selection and adaptation in non-stationary reinforcement learning problems. However, the properties of meta-gradients in such environments have not been systematically studied. In this work, we bring new clarity to meta-gradients in non-stationary environments. Concretely, we ask: (i) how much information should be given to the learned optimizers, so as to enable faster adaptation and generalization over a lifetime, (ii) what meta-optimizer functions are learned in this process, and (iii) whether meta-gradient methods provide a bigger advantage in highly non-stationary environments. To study the effect of information provided to the meta-optimizer, as in recent works (Flennerhag et al., 2021; Almeida et al., 2021), we replace the tuned meta-parameters of fixed update rules with learned meta-parameter functions of selected context features. The context features carry information about agent performance and changes in the environment and hence can inform learned meta-parameter schedules. We find that adding more contextual information is generally beneficial, leading to faster adaptation of meta-parameter values and increased performance over a lifetime. We support these results with a qualitative analysis of resulting meta-parameter schedules and learned functions of context features. Lastly, we find that without context, meta-gradients do not provide a consistent advantage over the baseline in highly non-stationary environments. Our findings suggest that contextualizing meta-gradients can play a pivotal role in extracting high performance from meta-gradients in non-stationary settings.
Discovering Policies with DOMiNO: Diversity Optimization Maintaining Near Optimality
May 26, 2022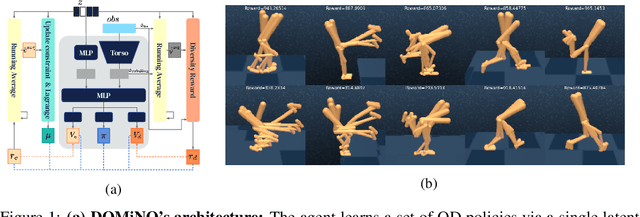
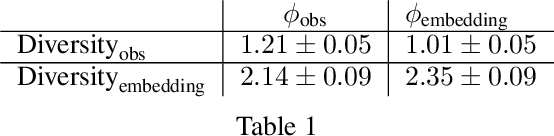
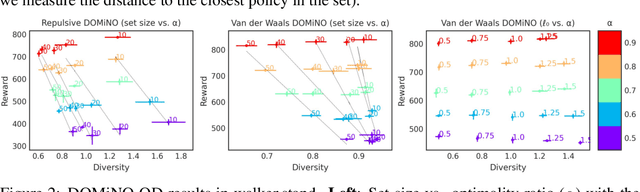
Finding different solutions to the same problem is a key aspect of intelligence associated with creativity and adaptation to novel situations. In reinforcement learning, a set of diverse policies can be useful for exploration, transfer, hierarchy, and robustness. We propose DOMiNO, a method for Diversity Optimization Maintaining Near Optimality. We formalize the problem as a Constrained Markov Decision Process where the objective is to find diverse policies, measured by the distance between the state occupancies of the policies in the set, while remaining near-optimal with respect to the extrinsic reward. We demonstrate that the method can discover diverse and meaningful behaviors in various domains, such as different locomotion patterns in the DeepMind Control Suite. We perform extensive analysis of our approach, compare it with other multi-objective baselines, demonstrate that we can control both the quality and the diversity of the set via interpretable hyperparameters, and show that the discovered set is robust to perturbations.
Bootstrapped Meta-Learning
Sep 09, 2021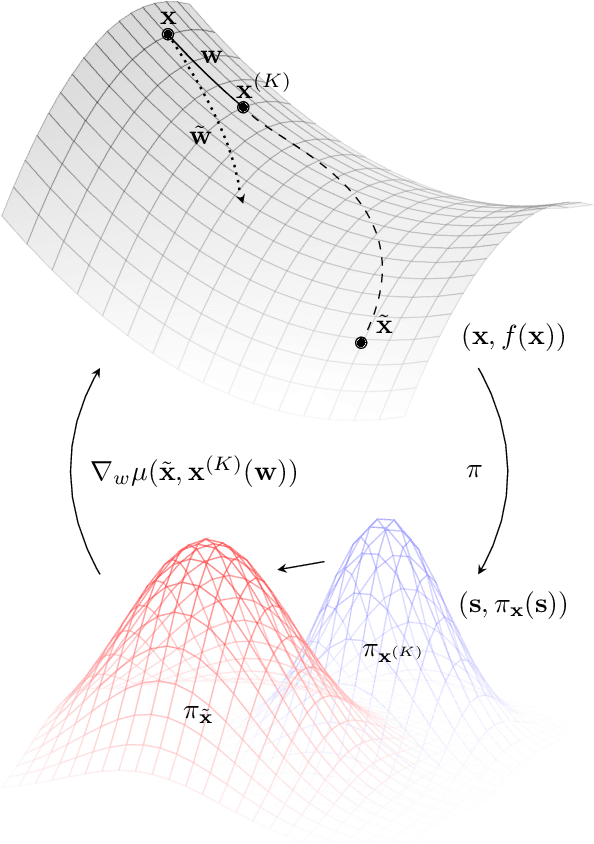

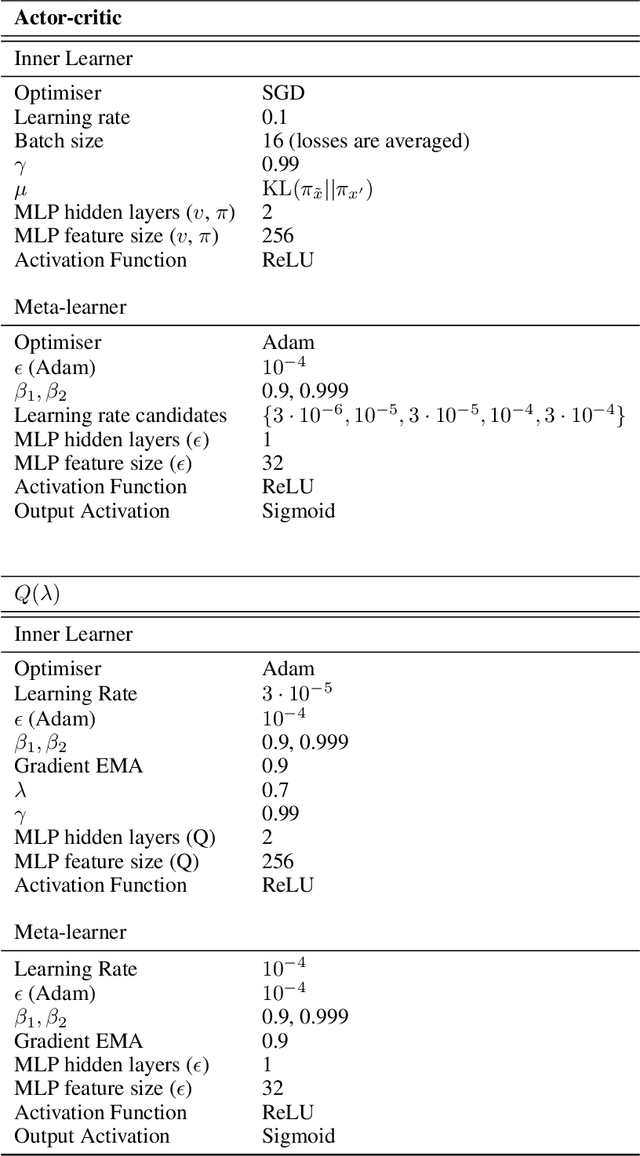
Meta-learning empowers artificial intelligence to increase its efficiency by learning how to learn. Unlocking this potential involves overcoming a challenging meta-optimisation problem that often exhibits ill-conditioning, and myopic meta-objectives. We propose an algorithm that tackles these issues by letting the meta-learner teach itself. The algorithm first bootstraps a target from the meta-learner, then optimises the meta-learner by minimising the distance to that target under a chosen (pseudo-)metric. Focusing on meta-learning with gradients, we establish conditions that guarantee performance improvements and show that the improvement is related to the target distance. Thus, by controlling curvature, the distance measure can be used to ease meta-optimization, for instance by reducing ill-conditioning. Further, the bootstrapping mechanism can extend the effective meta-learning horizon without requiring backpropagation through all updates. The algorithm is versatile and easy to implement. We achieve a new state-of-the art for model-free agents on the Atari ALE benchmark, improve upon MAML in few-shot learning, and demonstrate how our approach opens up new possibilities by meta-learning efficient exploration in a Q-learning agent.
Universal Value Density Estimation for Imitation Learning and Goal-Conditioned Reinforcement Learning
Feb 15, 2020
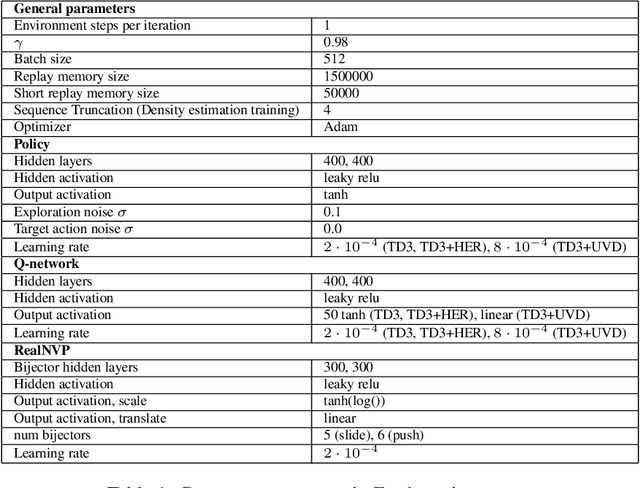
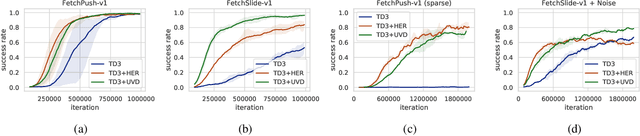
This work considers two distinct settings: imitation learning and goal-conditioned reinforcement learning. In either case, effective solutions require the agent to reliably reach a specified state (a goal), or set of states (a demonstration). Drawing a connection between probabilistic long-term dynamics and the desired value function, this work introduces an approach which utilizes recent advances in density estimation to effectively learn to reach a given state. As our first contribution, we use this approach for goal-conditioned reinforcement learning and show that it is both efficient and does not suffer from hindsight bias in stochastic domains. As our second contribution, we extend the approach to imitation learning and show that it achieves state-of-the art demonstration sample-efficiency on standard benchmark tasks.
Active Learning within Constrained Environments through Imitation of an Expert Questioner
Jul 01, 2019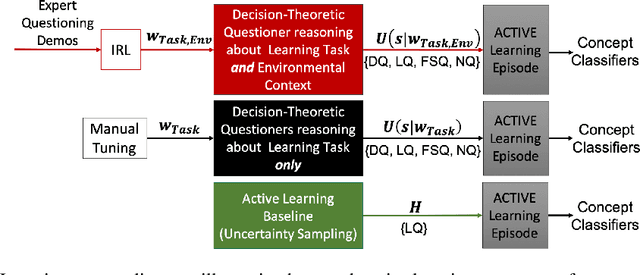

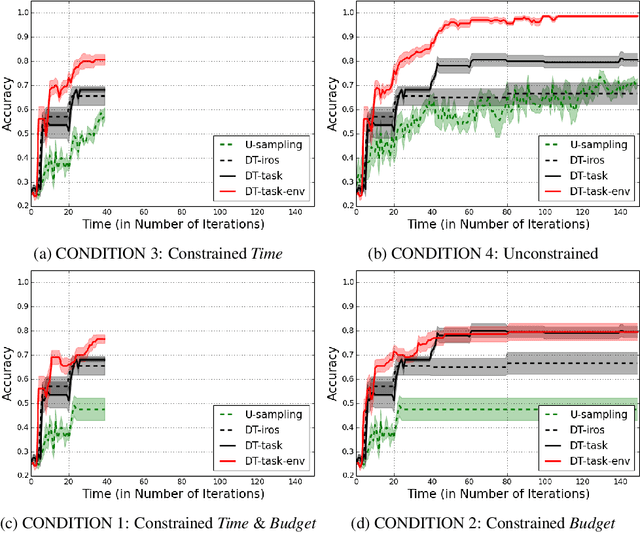
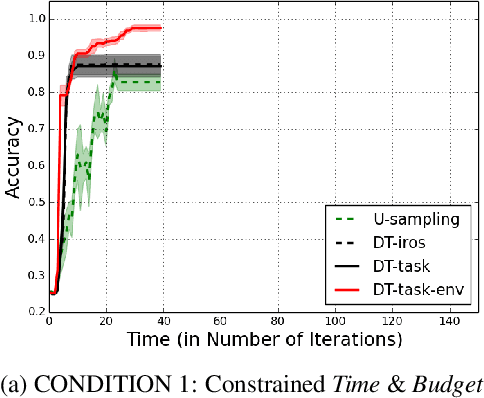
Active learning agents typically employ a query selection algorithm which solely considers the agent's learning objectives. However, this may be insufficient in more realistic human domains. This work uses imitation learning to enable an agent in a constrained environment to concurrently reason about both its internal learning goals and environmental constraints externally imposed, all within its objective function. Experiments are conducted on a concept learning task to test generalization of the proposed algorithm to different environmental conditions and analyze how time and resource constraints impact efficacy of solving the learning problem. Our findings show the environmentally-aware learning agent is able to statistically outperform all other active learners explored under most of the constrained conditions. A key implication is adaptation for active learning agents to more realistic human environments, where constraints are often externally imposed on the learner.
Generative predecessor models for sample-efficient imitation learning
Apr 01, 2019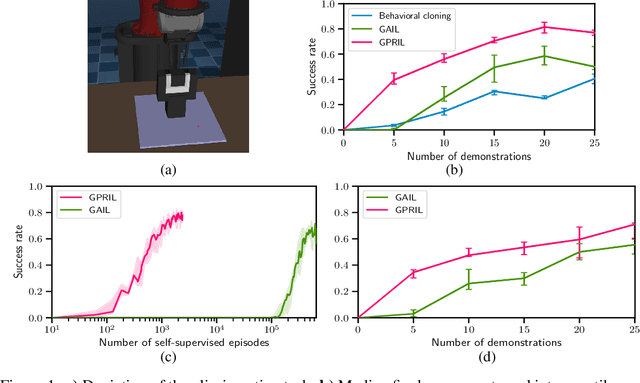
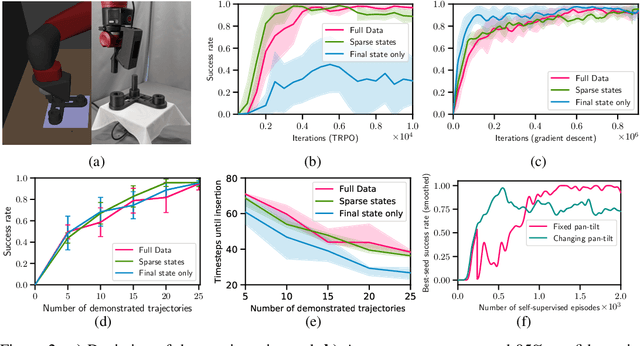
We propose Generative Predecessor Models for Imitation Learning (GPRIL), a novel imitation learning algorithm that matches the state-action distribution to the distribution observed in expert demonstrations, using generative models to reason probabilistically about alternative histories of demonstrated states. We show that this approach allows an agent to learn robust policies using only a small number of expert demonstrations and self-supervised interactions with the environment. We derive this approach from first principles and compare it empirically to a state-of-the-art imitation learning method, showing that it outperforms or matches its performance on two simulated robot manipulation tasks and demonstrate significantly higher sample efficiency by applying the algorithm on a real robot.
Imitating Latent Policies from Observation
May 24, 2018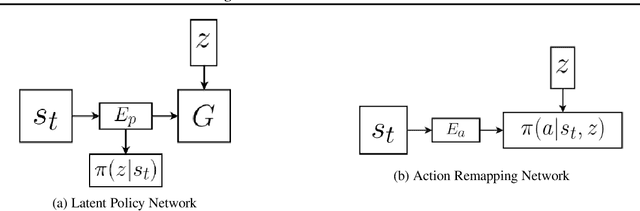
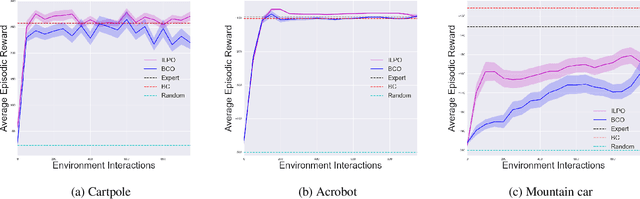
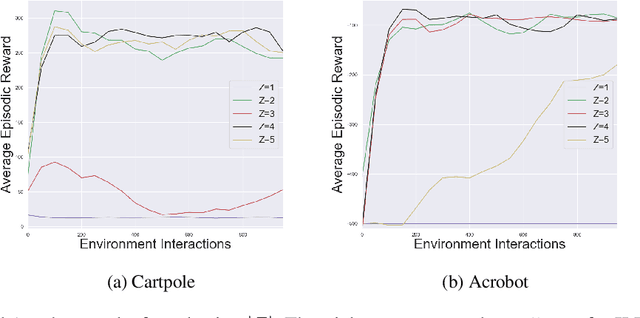
We describe a novel approach to imitation learning that infers latent policies directly from state observations. We introduce a method that characterizes the causal effects of unknown actions on observations while simultaneously predicting their likelihood. We then outline an action alignment procedure that leverages a small amount of environment interactions to determine a mapping between latent and real-world actions. We show that this corrected labeling can be used for imitating the observed behavior, even though no expert actions are given. We evaluate our approach within classic control and photo-realistic visual environments and demonstrate that it performs well when compared to standard approaches.