 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusing Heterogeneous Factors with Triaffine Mechanism for Nested Named Entity Recognition
Oct 14, 2021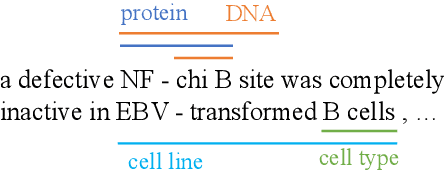
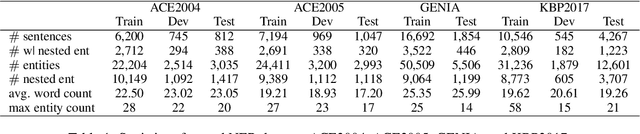
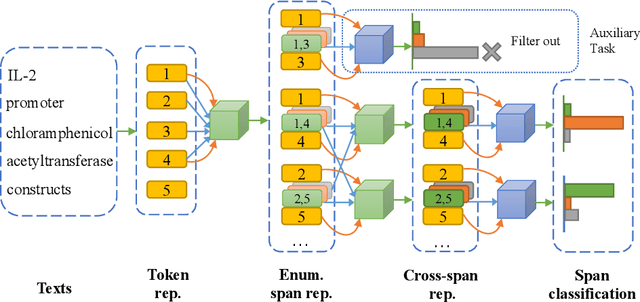
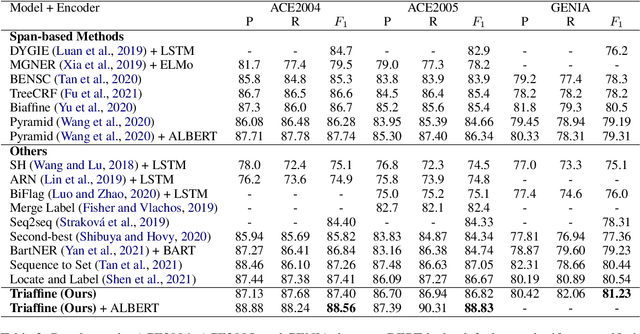
Nested entities are observed in many domains due to their compositionality, which cannot be easily recognized by the widely-used sequence labeling framework. A natural solution is to treat the task as a span classification problem. To increase performance on span representation and classification, it is crucial to effectively integrate all useful information of different formats, which we refer to heterogeneous factors including tokens, labels, boundaries, and related spans. To fuse these heterogeneous factors, we propose a novel triaffine mechanism including triaffine attention and scoring, which interacts with multiple factors in both the stages of representation and classification. Experiments results show that our proposed method achieves the state-of-the-art F1 scores on four nested NER datasets: ACE2004, ACE2005, GENIA, and KBP2017.
Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning
Sep 13, 2021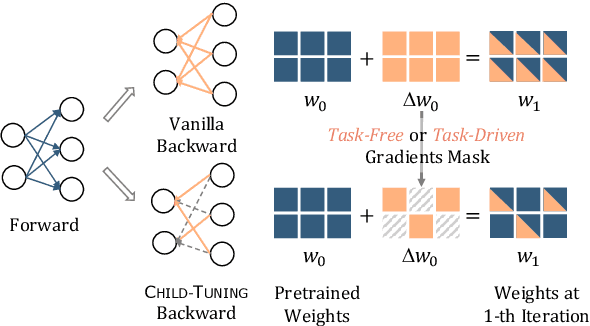
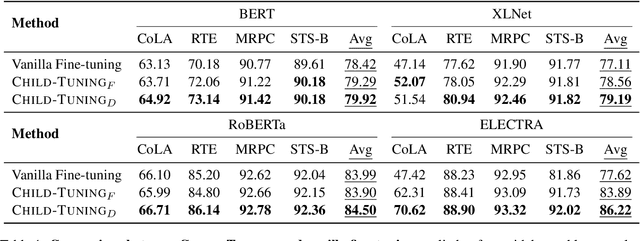
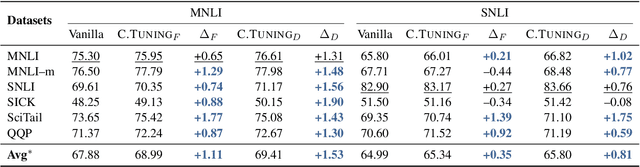
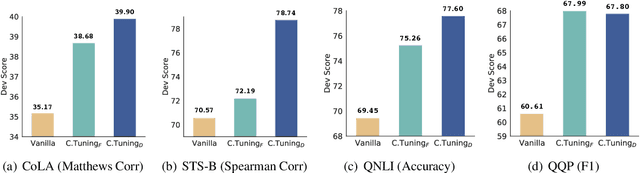
Recent pretrained language models extend from millions to billions of parameters. Thus the need to fine-tune an extremely large pretrained model with a limited training corpus arises in various downstream tasks. In this paper, we propose a straightforward yet effective fine-tuning technique, Child-Tuning, which updates a subset of parameters (called child network) of large pretrained models via strategically masking out the gradients of the non-child network during the backward process. Experiments on various downstream tasks in GLUE benchmark show that Child-Tuning consistently outperforms the vanilla fine-tuning by 1.5~8.6 average score among four different pretrained models, and surpasses the prior fine-tuning techniques by 0.6~1.3 points. Furthermore, empirical results on domain transfer and task transfer show that Child-Tuning can obtain better generalization performance by large margins.
E2E-VLP: End-to-End Vision-Language Pre-training Enhanced by Visual Learning
Jun 04, 2021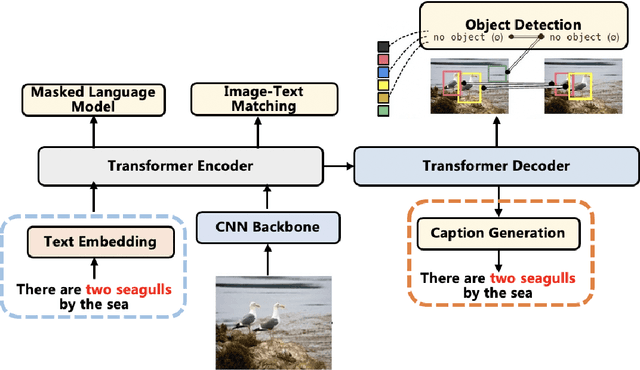
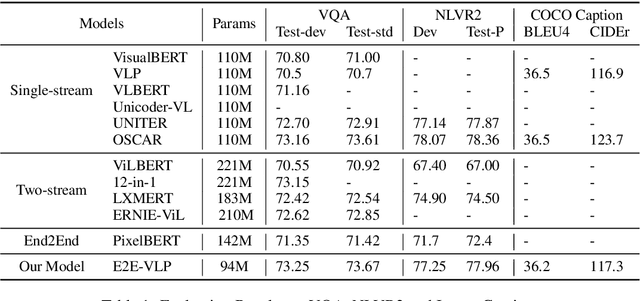
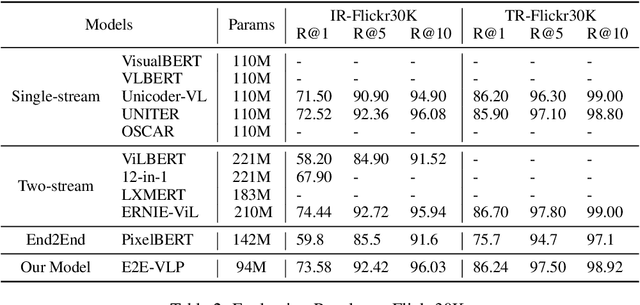
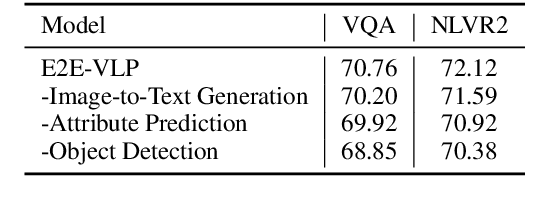
Vision-language pre-training (VLP) on large-scale image-text pairs has achieved huge success for the cross-modal downstream tasks. The most existing pre-training methods mainly adopt a two-step training procedure, which firstly employs a pre-trained object detector to extract region-based visual features, then concatenates the image representation and text embedding as the input of Transformer to train. However, these methods face problems of using task-specific visual representation of the specific object detector for generic cross-modal understanding, and the computation inefficiency of two-stage pipeline. In this paper, we propose the first end-to-end vision-language pre-trained model for both V+L understanding and generation, namely E2E-VLP, where we build a unified Transformer framework to jointly learn visual representation, and semantic alignments between image and text. We incorporate the tasks of object detection and image captioning into pre-training with a unified Transformer encoder-decoder architecture for enhancing visual learning. An extensive set of experiments have been conducted on well-established vision-language downstream tasks to demonstrate the effectiveness of this novel VLP paradigm.
StructuralLM: Structural Pre-training for Form Understanding
May 24, 2021
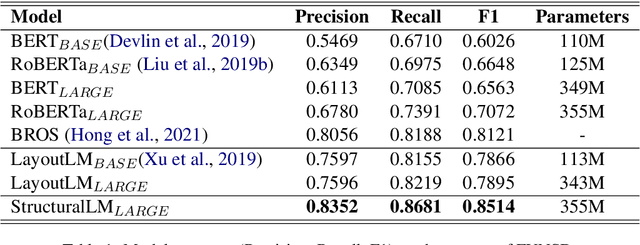
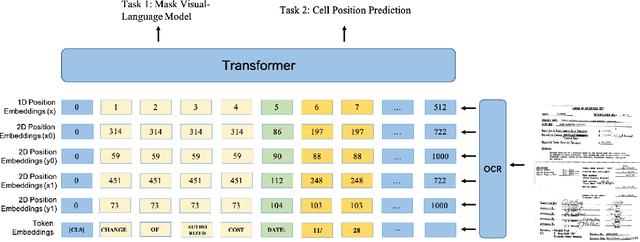
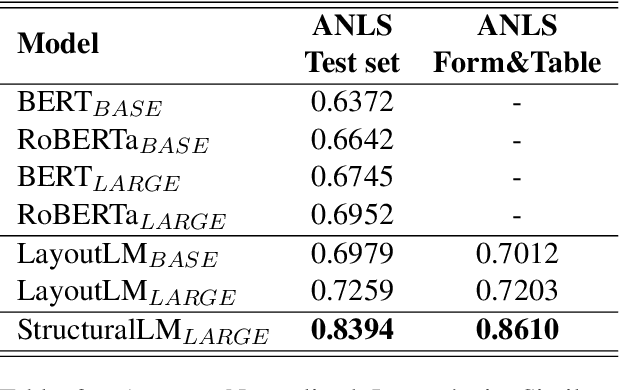
Large pre-trained language models achieve state-of-the-art results when fine-tuned on downstream NLP tasks. However, they almost exclusively focus on text-only representation, while neglecting cell-level layout information that is important for form image understanding. In this paper, we propose a new pre-training approach, StructuralLM, to jointly leverage cell and layout information from scanned documents. Specifically, we pre-train StructuralLM with two new designs to make the most of the interactions of cell and layout information: 1) each cell as a semantic unit; 2) classification of cell positions. The pre-trained StructuralLM achieves new state-of-the-art results in different types of downstream tasks, including form understanding (from 78.95 to 85.14), document visual question answering (from 72.59 to 83.94) and document image classification (from 94.43 to 96.08).
Improving Biomedical Pretrained Language Models with Knowledge
Apr 21, 2021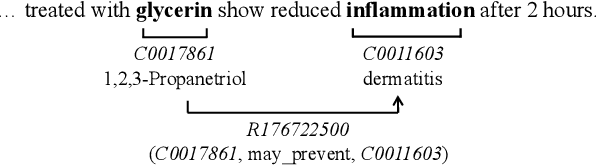
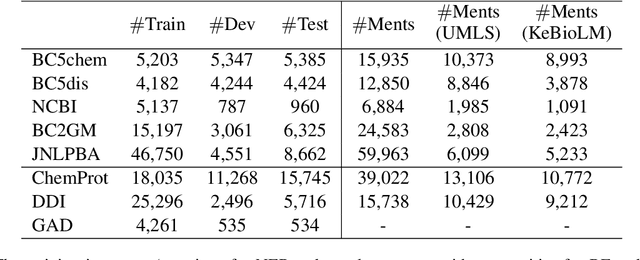
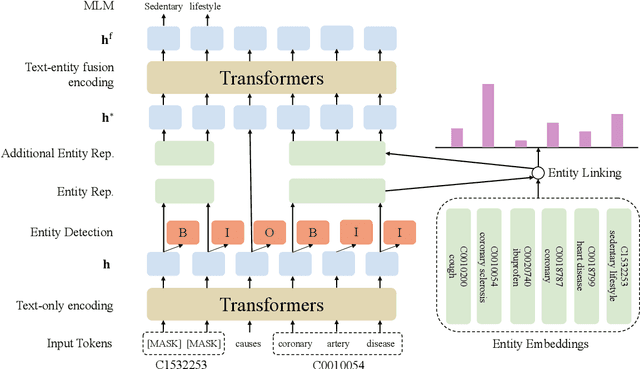
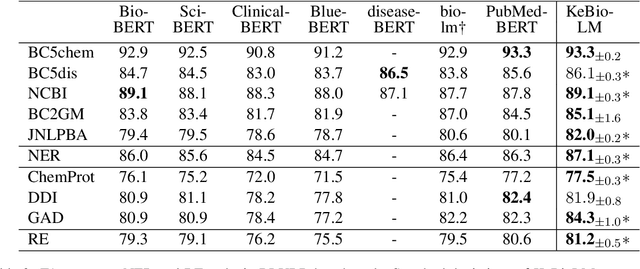
Pretrained language models have shown success in many natural language processing tasks. Many works explore incorporating knowledge into language models. In the biomedical domain, experts have taken decades of effort on building large-scale knowledge bases. For example, the Unified Medical Language System (UMLS) contains millions of entities with their synonyms and defines hundreds of relations among entities. Leveraging this knowledge can benefit a variety of downstream tasks such as named entity recognition and relation extraction. To this end, we propose KeBioLM, a biomedical pretrained language model that explicitly leverages knowledge from the UMLS knowledge bases. Specifically, we extract entities from PubMed abstracts and link them to UMLS. We then train a knowledge-aware language model that firstly applies a text-only encoding layer to learn entity representation and applies a text-entity fusion encoding to aggregate entity representation. Besides, we add two training objectives as entity detection and entity linking. Experiments on the named entity recognition and relation extraction from the BLURB benchmark demonstrate the effectiveness of our approach. Further analysis on a collected probing dataset shows that our model has better ability to model medical knowledge.
Lattice-BERT: Leveraging Multi-Granularity Representations in Chinese Pre-trained Language Models
Apr 15, 2021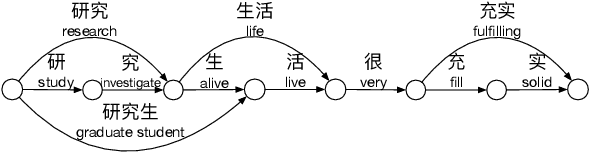
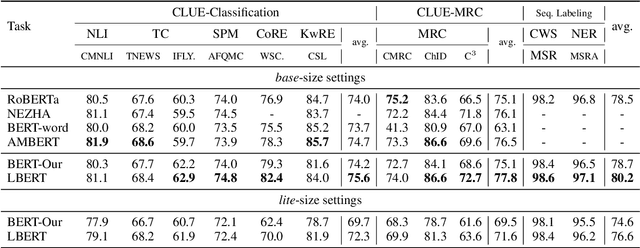
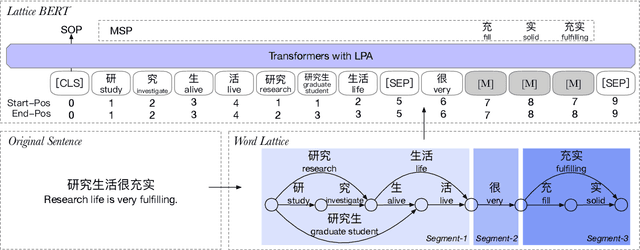
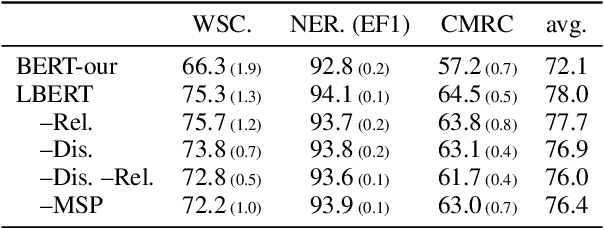
Chinese pre-trained language models usually process text as a sequence of characters, while ignoring more coarse granularity, e.g., words. In this work, we propose a novel pre-training paradigm for Chinese -- Lattice-BERT, which explicitly incorporates word representations along with characters, thus can model a sentence in a multi-granularity manner. Specifically, we construct a lattice graph from the characters and words in a sentence and feed all these text units into transformers. We design a lattice position attention mechanism to exploit the lattice structures in self-attention layers. We further propose a masked segment prediction task to push the model to learn from rich but redundant information inherent in lattices, while avoiding learning unexpected tricks. Experiments on 11 Chinese natural language understanding tasks show that our model can bring an average increase of 1.5% under the 12-layer setting, which achieves new state-of-the-art among base-size models on the CLUE benchmarks. Further analysis shows that Lattice-BERT can harness the lattice structures, and the improvement comes from the exploration of redundant information and multi-granularity representations. Our code will be available at https://github.com/alibaba/pretrained-language-models/LatticeBERT.
Noisy-Labeled NER with Confidence Estimation
Apr 12, 2021
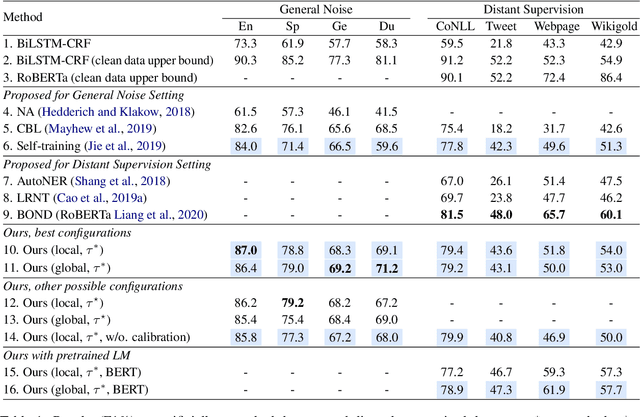
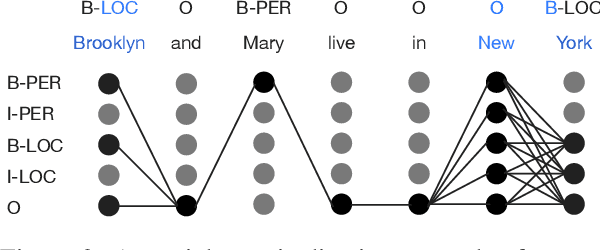
Recent studies in deep learning have shown significant progress in named entity recognition (NER). Most existing works assume clean data annotation, yet a fundamental challenge in real-world scenarios is the large amount of noise from a variety of sources (e.g., pseudo, weak, or distant annotations). This work studies NER under a noisy labeled setting with calibrated confidence estimation. Based on empirical observations of different training dynamics of noisy and clean labels, we propose strategies for estimating confidence scores based on local and global independence assumptions. We partially marginalize out labels of low confidence with a CRF model. We further propose a calibration method for confidence scores based on the structure of entity labels. We integrate our approach into a self-training framework for boosting performance. Experiments in general noisy settings with four languages and distantly labeled settings demonstrate the effectiveness of our method. Our code can be found at https://github.com/liukun95/Noisy-NER-Confidence-Estimation
SemVLP: Vision-Language Pre-training by Aligning Semantics at Multiple Levels
Mar 14, 2021
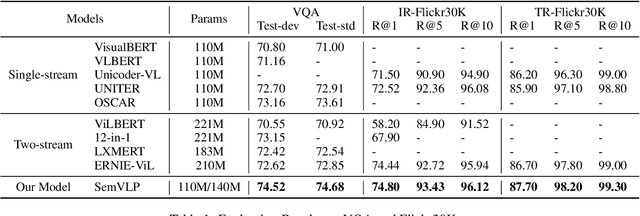
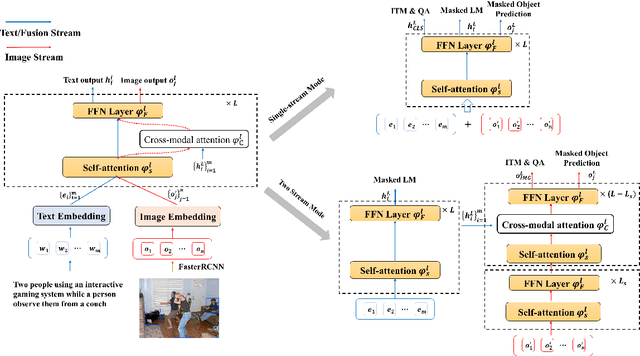

Vision-language pre-training (VLP) on large-scale image-text pairs has recently witnessed rapid progress for learning cross-modal representations. Existing pre-training methods either directly concatenate image representation and text representation at a feature level as input to a single-stream Transformer, or use a two-stream cross-modal Transformer to align the image-text representation at a high-level semantic space. In real-world image-text data, we observe that it is easy for some of the image-text pairs to align simple semantics on both modalities, while others may be related after higher-level abstraction. Therefore, in this paper, we propose a new pre-training method SemVLP, which jointly aligns both the low-level and high-level semantics between image and text representations. The model is pre-trained iteratively with two prevalent fashions: single-stream pre-training to align at a fine-grained feature level and two-stream pre-training to align high-level semantics, by employing a shared Transformer network with a pluggable cross-modal attention module. An extensive set of experiments have been conducted on four well-established vision-language understanding tasks to demonstrate the effectiveness of the proposed SemVLP in aligning cross-modal representations towards different semantic granularities.
Biomedical Question Answering: A Comprehensive Review
Feb 10, 2021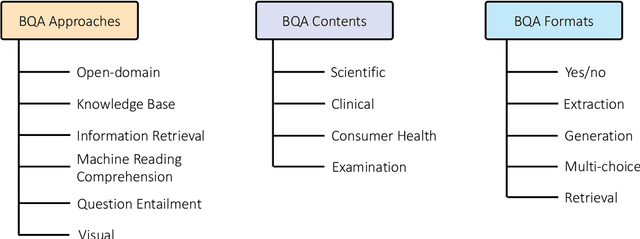
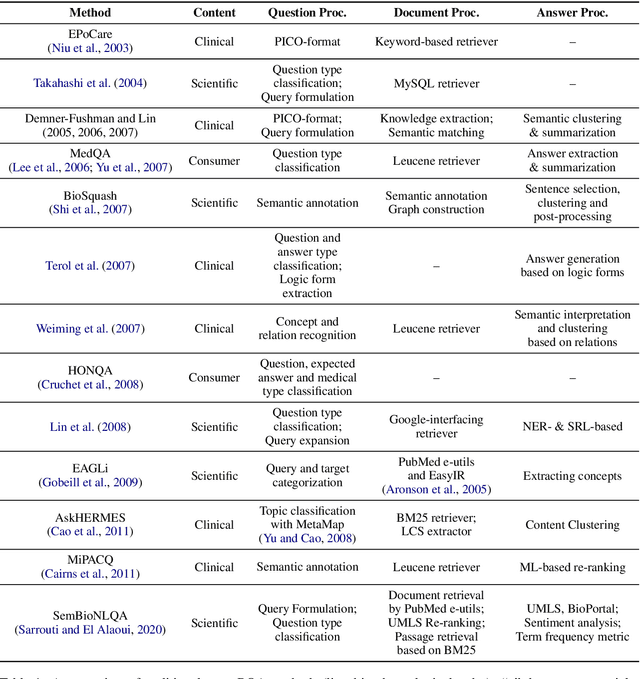
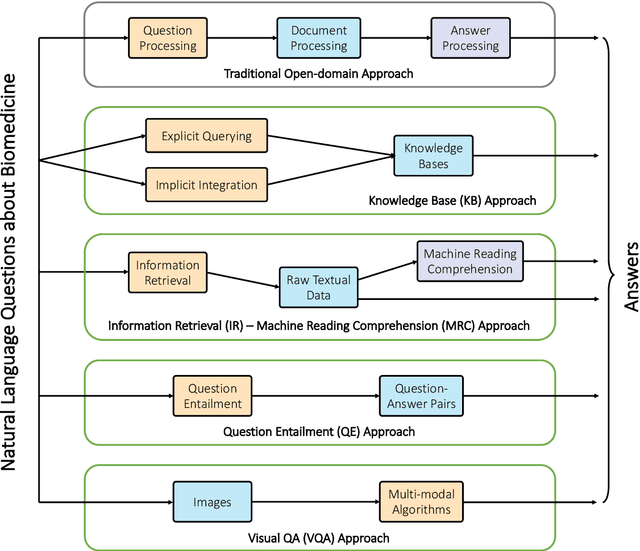
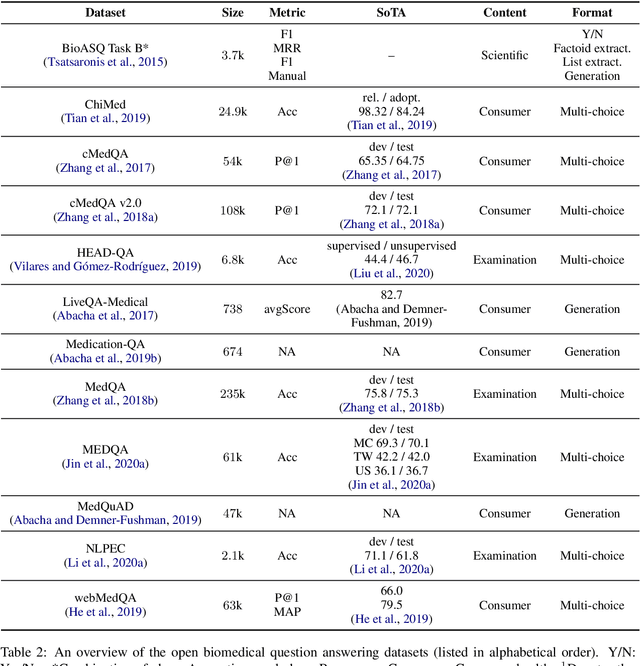
Question Answering (QA) is a benchmark Natural Language Processing (NLP) task where models predict the answer for a given question using related documents, images, knowledge bases and question-answer pairs. Automatic QA has been successfully applied in various domains like search engines and chatbots. However, for specific domains like biomedicine, QA systems are still rarely used in real-life settings. Biomedical QA (BQA), as an emerging QA task, enables innovative applications to effectively perceive, access and understand complex biomedical knowledge. In this work, we provide a critical review of recent efforts in BQA. We comprehensively investigate prior BQA approaches, which are classified into 6 major methodologies (open-domain, knowledge base, information retrieval, machine reading comprehension, question entailment and visual QA), 4 topics of contents (scientific, clinical, consumer health and examination) and 5 types of formats (yes/no, extraction, generation, multi-choice and retrieval). In the end, we highlight several key challenges of BQA and explore potential directions for future works.
Contrastive Prototype Learning with Augmented Embeddings for Few-Shot Learning
Jan 23, 2021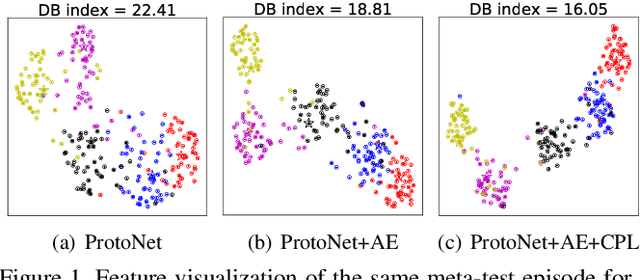
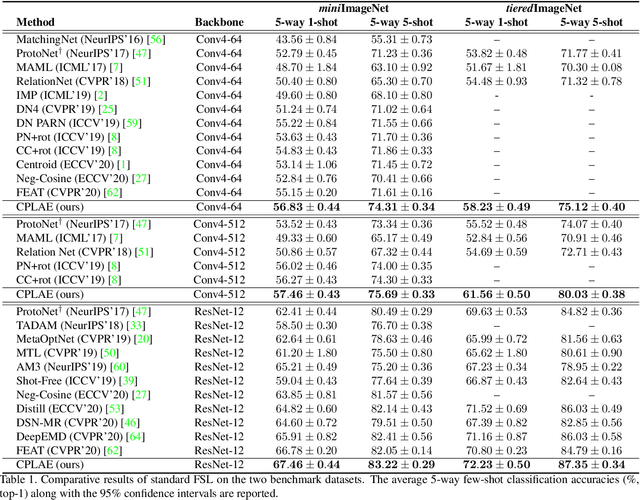
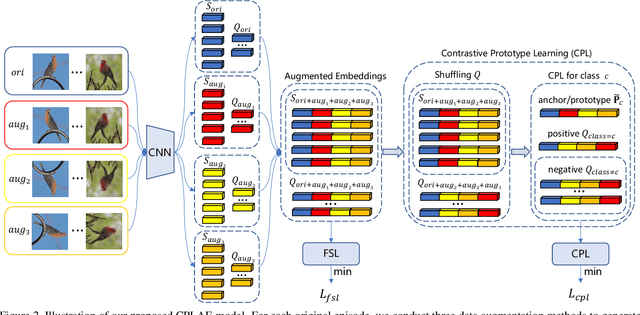

Most recent few-shot learning (FSL) methods are based on meta-learning with episodic training. In each meta-training episode, a discriminative feature embedding and/or classifier are first constructed from a support set in an inner loop, and then evaluated in an outer loop using a query set for model updating. This query set sample centered learning objective is however intrinsically limited in addressing the lack of training data problem in the support set. In this paper, a novel contrastive prototype learning with augmented embeddings (CPLAE) model is proposed to overcome this limitation. First, data augmentations are introduced to both the support and query sets with each sample now being represented as an augmented embedding (AE) composed of concatenated embeddings of both the original and augmented versions. Second, a novel support set class prototype centered contrastive loss is proposed for contrastive prototype learning (CPL). With a class prototype as an anchor, CPL aims to pull the query samples of the same class closer and those of different classes further away. This support set sample centered loss is highly complementary to the existing query centered loss, fully exploiting the limited training data in each episode. Extensive experiments on several benchmarks demonstrate that our proposed CPLAE achieves new state-of-the-art.