 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling High Data Throughput Reinforcement Learning on GPUs: A Domain Agnostic Framework for Data-Driven Scientific Research
Aug 01, 2024We introduce WarpSci, a domain agnostic framework designed to overcome crucial system bottlenecks encountered in the application of reinforcement learning to intricate environments with vast datasets featuring high-dimensional observation or action spaces. Notably, our framework eliminates the need for data transfer between the CPU and GPU, enabling the concurrent execution of thousands of simulations on a single or multiple GPUs. This high data throughput architecture proves particularly advantageous for data-driven scientific research, where intricate environment models are commonly essential.
Shared Imagination: LLMs Hallucinate Alike
Jul 23, 2024



Despite the recent proliferation of large language models (LLMs), their training recipes -- model architecture, pre-training data and optimization algorithm -- are often very similar. This naturally raises the question of the similarity among the resulting models. In this paper, we propose a novel setting, imaginary question answering (IQA), to better understand model similarity. In IQA, we ask one model to generate purely imaginary questions (e.g., on completely made-up concepts in physics) and prompt another model to answer. Surprisingly, despite the total fictionality of these questions, all models can answer each other's questions with remarkable success, suggesting a "shared imagination space" in which these models operate during such hallucinations. We conduct a series of investigations into this phenomenon and discuss implications on model homogeneity, hallucination, and computational creativity.
APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets
Jun 26, 2024



The advancement of function-calling agent models requires diverse, reliable, and high-quality datasets. This paper presents APIGen, an automated data generation pipeline designed to synthesize verifiable high-quality datasets for function-calling applications. We leverage APIGen and collect 3,673 executable APIs across 21 different categories to generate diverse function-calling datasets in a scalable and structured manner. Each data in our dataset is verified through three hierarchical stages: format checking, actual function executions, and semantic verification, ensuring its reliability and correctness. We demonstrate that models trained with our curated datasets, even with only 7B parameters, can achieve state-of-the-art performance on the Berkeley Function-Calling Benchmark, outperforming multiple GPT-4 models. Moreover, our 1B model achieves exceptional performance, surpassing GPT-3.5-Turbo and Claude-3 Haiku. We release a dataset containing 60,000 high-quality entries, aiming to advance the field of function-calling agent domains. The dataset is available on Huggingface: https://huggingface.co/datasets/Salesforce/xlam-function-calling-60k and the project homepage: https://apigen-pipeline.github.io/
INDICT: Code Generation with Internal Dialogues of Critiques for Both Security and Helpfulness
Jun 23, 2024



Large language models (LLMs) for code are typically trained to align with natural language instructions to closely follow their intentions and requirements. However, in many practical scenarios, it becomes increasingly challenging for these models to navigate the intricate boundary between helpfulness and safety, especially against highly complex yet potentially malicious instructions. In this work, we introduce INDICT: a new framework that empowers LLMs with Internal Dialogues of Critiques for both safety and helpfulness guidance. The internal dialogue is a dual cooperative system between a safety-driven critic and a helpfulness-driven critic. Each critic provides analysis against the given task and corresponding generated response, equipped with external knowledge queried through relevant code snippets and tools like web search and code interpreter. We engage the dual critic system in both code generation stage as well as code execution stage, providing preemptive and post-hoc guidance respectively to LLMs. We evaluated INDICT on 8 diverse tasks across 8 programming languages from 5 benchmarks, using LLMs from 7B to 70B parameters. We observed that our approach can provide an advanced level of critiques of both safety and helpfulness analysis, significantly improving the quality of output codes ($+10\%$ absolute improvements in all models).
MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens
Jun 17, 2024



Multimodal interleaved datasets featuring free-form interleaved sequences of images and text are crucial for training frontier large multimodal models (LMMs). Despite the rapid progression of open-source LMMs, there remains a pronounced scarcity of large-scale, diverse open-source multimodal interleaved datasets. In response, we introduce MINT-1T, the most extensive and diverse open-source Multimodal INTerleaved dataset to date. MINT-1T comprises one trillion text tokens and three billion images, a 10x scale-up from existing open-source datasets. Additionally, we include previously untapped sources such as PDFs and ArXiv papers. As scaling multimodal interleaved datasets requires substantial engineering effort, sharing the data curation process and releasing the dataset greatly benefits the community. Our experiments show that LMMs trained on MINT-1T rival the performance of models trained on the previous leading dataset, OBELICS. Our data and code will be released at https://github.com/mlfoundations/MINT-1T.
MobileAIBench: Benchmarking LLMs and LMMs for On-Device Use Cases
Jun 12, 2024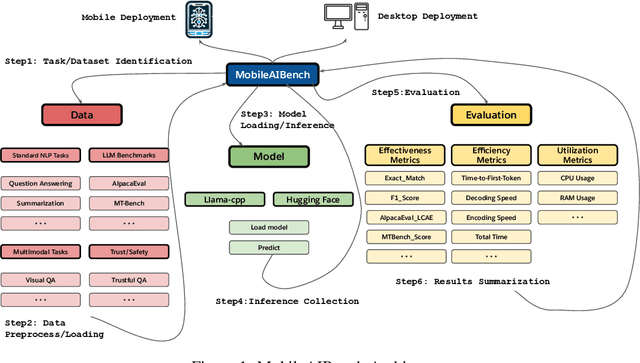



The deployment of Large Language Models (LLMs) and Large Multimodal Models (LMMs) on mobile devices has gained significant attention due to the benefits of enhanced privacy, stability, and personalization. However, the hardware constraints of mobile devices necessitate the use of models with fewer parameters and model compression techniques like quantization. Currently, there is limited understanding of quantization's impact on various task performances, including LLM tasks, LMM tasks, and, critically, trust and safety. There is a lack of adequate tools for systematically testing these models on mobile devices. To address these gaps, we introduce MobileAIBench, a comprehensive benchmarking framework for evaluating mobile-optimized LLMs and LMMs. MobileAIBench assesses models across different sizes, quantization levels, and tasks, measuring latency and resource consumption on real devices. Our two-part open-source framework includes a library for running evaluations on desktops and an iOS app for on-device latency and hardware utilization measurements. Our thorough analysis aims to accelerate mobile AI research and deployment by providing insights into the performance and feasibility of deploying LLMs and LMMs on mobile platforms.
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Apr 11, 2024



Autonomous agents that accomplish complex computer tasks with minimal human interventions have the potential to transform human-computer interaction, significantly enhancing accessibility and productivity. However, existing benchmarks either lack an interactive environment or are limited to environments specific to certain applications or domains, failing to reflect the diverse and complex nature of real-world computer use, thereby limiting the scope of tasks and agent scalability. To address this issue, we introduce OSWorld, the first-of-its-kind scalable, real computer environment for multimodal agents, supporting task setup, execution-based evaluation, and interactive learning across various operating systems such as Ubuntu, Windows, and macOS. OSWorld can serve as a unified, integrated computer environment for assessing open-ended computer tasks that involve arbitrary applications. Building upon OSWorld, we create a benchmark of 369 computer tasks involving real web and desktop apps in open domains, OS file I/O, and workflows spanning multiple applications. Each task example is derived from real-world computer use cases and includes a detailed initial state setup configuration and a custom execution-based evaluation script for reliable, reproducible evaluation. Extensive evaluation of state-of-the-art LLM/VLM-based agents on OSWorld reveals significant deficiencies in their ability to serve as computer assistants. While humans can accomplish over 72.36% of the tasks, the best model achieves only 12.24% success, primarily struggling with GUI grounding and operational knowledge. Comprehensive analysis using OSWorld provides valuable insights for developing multimodal generalist agents that were not possible with previous benchmarks. Our code, environment, baseline models, and data are publicly available at https://os-world.github.io.
BEHAVIOR-1K: A Human-Centered, Embodied AI Benchmark with 1,000 Everyday Activities and Realistic Simulation
Mar 14, 2024



We present BEHAVIOR-1K, a comprehensive simulation benchmark for human-centered robotics. BEHAVIOR-1K includes two components, guided and motivated by the results of an extensive survey on "what do you want robots to do for you?". The first is the definition of 1,000 everyday activities, grounded in 50 scenes (houses, gardens, restaurants, offices, etc.) with more than 9,000 objects annotated with rich physical and semantic properties. The second is OMNIGIBSON, a novel simulation environment that supports these activities via realistic physics simulation and rendering of rigid bodies, deformable bodies, and liquids. Our experiments indicate that the activities in BEHAVIOR-1K are long-horizon and dependent on complex manipulation skills, both of which remain a challenge for even state-of-the-art robot learning solutions. To calibrate the simulation-to-reality gap of BEHAVIOR-1K, we provide an initial study on transferring solutions learned with a mobile manipulator in a simulated apartment to its real-world counterpart. We hope that BEHAVIOR-1K's human-grounded nature, diversity, and realism make it valuable for embodied AI and robot learning research. Project website: https://behavior.stanford.edu.
AgentOhana: Design Unified Data and Training Pipeline for Effective Agent Learning
Feb 26, 2024



Autonomous agents powered by large language models (LLMs) have garnered significant research attention. However, fully harnessing the potential of LLMs for agent-based tasks presents inherent challenges due to the heterogeneous nature of diverse data sources featuring multi-turn trajectories. In this paper, we introduce \textbf{AgentOhana} as a comprehensive solution to address these challenges. \textit{AgentOhana} aggregates agent trajectories from distinct environments, spanning a wide array of scenarios. It meticulously standardizes and unifies these trajectories into a consistent format, streamlining the creation of a generic data loader optimized for agent training. Leveraging the data unification, our training pipeline maintains equilibrium across different data sources and preserves independent randomness across devices during dataset partitioning and model training. Additionally, we present \textbf{xLAM-v0.1}, a large action model tailored for AI agents, which demonstrates exceptional performance across various benchmarks.
AgentLite: A Lightweight Library for Building and Advancing Task-Oriented LLM Agent System
Feb 23, 2024



The booming success of LLMs initiates rapid development in LLM agents. Though the foundation of an LLM agent is the generative model, it is critical to devise the optimal reasoning strategies and agent architectures. Accordingly, LLM agent research advances from the simple chain-of-thought prompting to more complex ReAct and Reflection reasoning strategy; agent architecture also evolves from single agent generation to multi-agent conversation, as well as multi-LLM multi-agent group chat. However, with the existing intricate frameworks and libraries, creating and evaluating new reasoning strategies and agent architectures has become a complex challenge, which hinders research investigation into LLM agents. Thus, we open-source a new AI agent library, AgentLite, which simplifies this process by offering a lightweight, user-friendly platform for innovating LLM agent reasoning, architectures, and applications with ease. AgentLite is a task-oriented framework designed to enhance the ability of agents to break down tasks and facilitate the development of multi-agent systems. Furthermore, we introduce multiple practical applications developed with AgentLite to demonstrate its convenience and flexibility. Get started now at: \url{https://github.com/SalesforceAIResearch/AgentLite}.