 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Improving Visual Prompting: A Label-Mapping Perspective
Nov 21, 2022



We revisit and advance visual prompting (VP), an input prompting technique for vision tasks. VP can reprogram a fixed, pre-trained source model to accomplish downstream tasks in the target domain by simply incorporating universal prompts (in terms of input perturbation patterns) into downstream data points. Yet, it remains elusive why VP stays effective even given a ruleless label mapping (LM) between the source classes and the target classes. Inspired by the above, we ask: How is LM interrelated with VP? And how to exploit such a relationship to improve its accuracy on target tasks? We peer into the influence of LM on VP and provide an affirmative answer that a better 'quality' of LM (assessed by mapping precision and explanation) can consistently improve the effectiveness of VP. This is in contrast to the prior art where the factor of LM was missing. To optimize LM, we propose a new VP framework, termed ILM-VP (iterative label mapping-based visual prompting), which automatically re-maps the source labels to the target labels and progressively improves the target task accuracy of VP. Further, when using a contrastive language-image pretrained (CLIP) model, we propose to integrate an LM process to assist the text prompt selection of CLIP and to improve the target task accuracy. Extensive experiments demonstrate that our proposal significantly outperforms state-of-the-art VP methods. As highlighted below, we show that when reprogramming an ImageNet-pretrained ResNet-18 to 13 target tasks, our method outperforms baselines by a substantial margin, e.g., 7.9% and 6.7% accuracy improvements in transfer learning to the target Flowers102 and CIFAR100 datasets. Besides, our proposal on CLIP-based VP provides 13.7% and 7.1% accuracy improvements on Flowers102 and DTD respectively. Our code is available at https://github.com/OPTML-Group/ILM-VP.
Data-Model-Circuit Tri-Design for Ultra-Light Video Intelligence on Edge Devices
Oct 18, 2022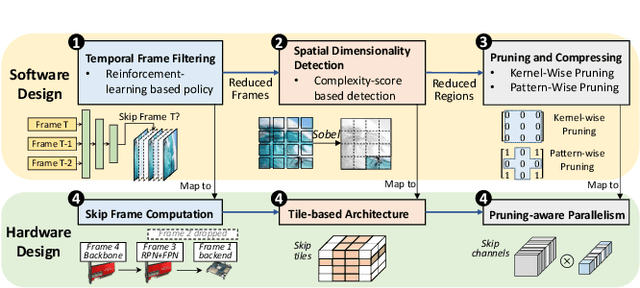
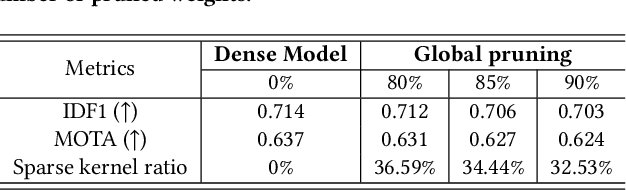


In this paper, we propose a data-model-hardware tri-design framework for high-throughput, low-cost, and high-accuracy multi-object tracking (MOT) on High-Definition (HD) video stream. First, to enable ultra-light video intelligence, we propose temporal frame-filtering and spatial saliency-focusing approaches to reduce the complexity of massive video data. Second, we exploit structure-aware weight sparsity to design a hardware-friendly model compression method. Third, assisted with data and model complexity reduction, we propose a sparsity-aware, scalable, and low-power accelerator design, aiming to deliver real-time performance with high energy efficiency. Different from existing works, we make a solid step towards the synergized software/hardware co-optimization for realistic MOT model implementation. Compared to the state-of-the-art MOT baseline, our tri-design approach can achieve 12.5x latency reduction, 20.9x effective frame rate improvement, 5.83x lower power, and 9.78x better energy efficiency, without much accuracy drop.
Advancing Model Pruning via Bi-level Optimization
Oct 12, 2022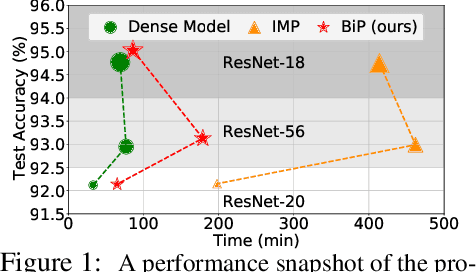
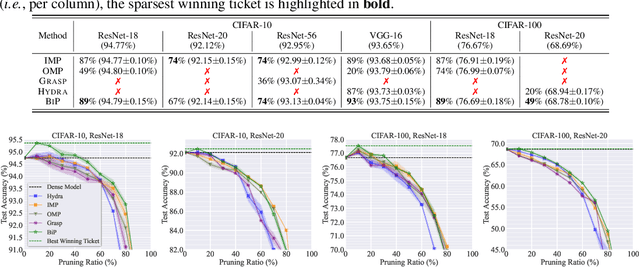
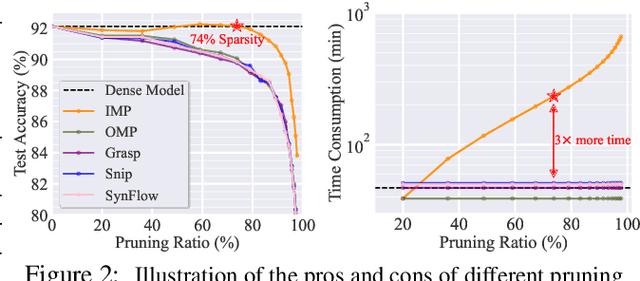
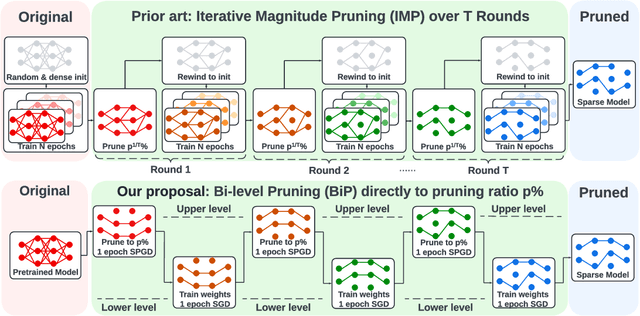
The deployment constraints in practical applications necessitate the pruning of large-scale deep learning models, i.e., promoting their weight sparsity. As illustrated by the Lottery Ticket Hypothesis (LTH), pruning also has the potential of improving their generalization ability. At the core of LTH, iterative magnitude pruning (IMP) is the predominant pruning method to successfully find 'winning tickets'. Yet, the computation cost of IMP grows prohibitively as the targeted pruning ratio increases. To reduce the computation overhead, various efficient 'one-shot' pruning methods have been developed, but these schemes are usually unable to find winning tickets as good as IMP. This raises the question of how to close the gap between pruning accuracy and pruning efficiency? To tackle it, we pursue the algorithmic advancement of model pruning. Specifically, we formulate the pruning problem from a fresh and novel viewpoint, bi-level optimization (BLO). We show that the BLO interpretation provides a technically-grounded optimization base for an efficient implementation of the pruning-retraining learning paradigm used in IMP. We also show that the proposed bi-level optimization-oriented pruning method (termed BiP) is a special class of BLO problems with a bi-linear problem structure. By leveraging such bi-linearity, we theoretically show that BiP can be solved as easily as first-order optimization, thus inheriting the computation efficiency. Through extensive experiments on both structured and unstructured pruning with 5 model architectures and 4 data sets, we demonstrate that BiP can find better winning tickets than IMP in most cases, and is computationally as efficient as the one-shot pruning schemes, demonstrating 2-7 times speedup over IMP for the same level of model accuracy and sparsity.
Visual Prompting for Adversarial Robustness
Oct 12, 2022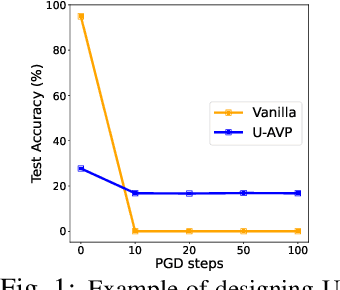
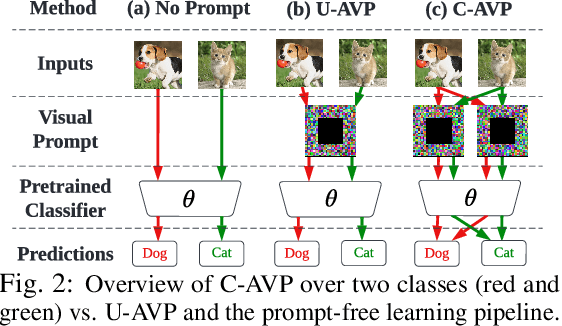


In this work, we leverage visual prompting (VP) to improve adversarial robustness of a fixed, pre-trained model at testing time. Compared to conventional adversarial defenses, VP allows us to design universal (i.e., data-agnostic) input prompting templates, which have plug-and-play capabilities at testing time to achieve desired model performance without introducing much computation overhead. Although VP has been successfully applied to improving model generalization, it remains elusive whether and how it can be used to defend against adversarial attacks. We investigate this problem and show that the vanilla VP approach is not effective in adversarial defense since a universal input prompt lacks the capacity for robust learning against sample-specific adversarial perturbations. To circumvent it, we propose a new VP method, termed Class-wise Adversarial Visual Prompting (C-AVP), to generate class-wise visual prompts so as to not only leverage the strengths of ensemble prompts but also optimize their interrelations to improve model robustness. Our experiments show that C-AVP outperforms the conventional VP method, with 2.1X standard accuracy gain and 2X robust accuracy gain. Compared to classical test-time defenses, C-AVP also yields a 42X inference time speedup.
Fairness Reprogramming
Sep 21, 2022
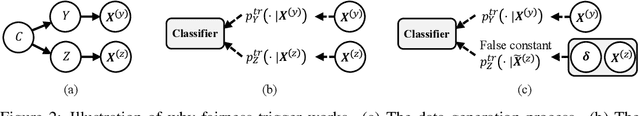
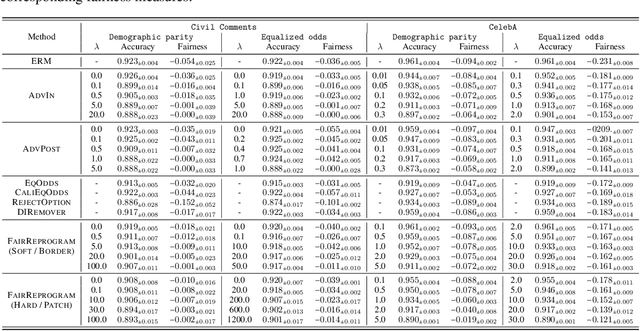
Despite a surge of recent advances in promoting machine Learning (ML) fairness, the existing mainstream approaches mostly require training or finetuning the entire weights of the neural network to meet the fairness criteria. However, this is often infeasible in practice for those large-scale trained models due to large computational and storage costs, low data efficiency, and model privacy issues. In this paper, we propose a new generic fairness learning paradigm, called FairReprogram, which incorporates the model reprogramming technique. Specifically, FairReprogram considers the neural model fixed, and instead appends to the input a set of perturbations, called the fairness trigger, which is tuned towards the fairness criteria under a min-max formulation. We further introduce an information-theoretic framework that explains why and under what conditions fairness goals can be achieved using the fairness trigger. We show both theoretically and empirically that the fairness trigger can effectively obscure demographic biases in the output prediction of fixed ML models by providing false demographic information that hinders the model from utilizing the correct demographic information to make the prediction. Extensive experiments on both NLP and CV datasets demonstrate that our method can achieve better fairness improvements than retraining-based methods with far less training cost and data dependency under two widely-used fairness criteria.
Saliency Guided Adversarial Training for Learning Generalizable Features with Applications to Medical Imaging Classification System
Sep 09, 2022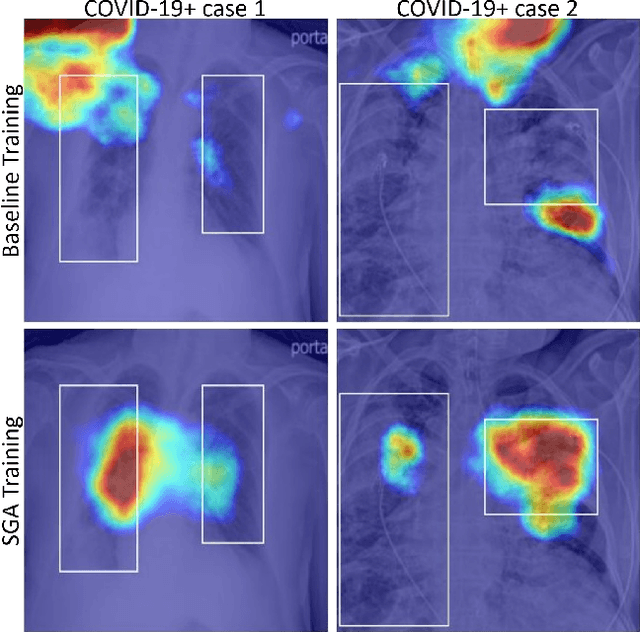
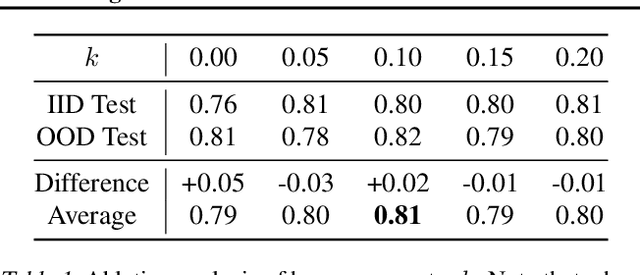
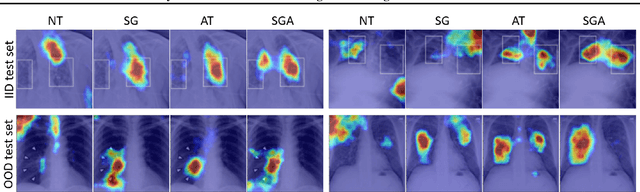
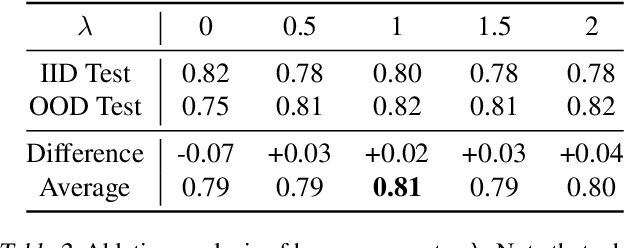
This work tackles a central machine learning problem of performance degradation on out-of-distribution (OOD) test sets. The problem is particularly salient in medical imaging based diagnosis system that appears to be accurate but fails when tested in new hospitals/datasets. Recent studies indicate the system might learn shortcut and non-relevant features instead of generalizable features, so-called good features. We hypothesize that adversarial training can eliminate shortcut features whereas saliency guided training can filter out non-relevant features; both are nuisance features accounting for the performance degradation on OOD test sets. With that, we formulate a novel model training scheme for the deep neural network to learn good features for classification and/or detection tasks ensuring a consistent generalization performance on OOD test sets. The experimental results qualitatively and quantitatively demonstrate the superior performance of our method using the benchmark CXR image data sets on classification tasks.
* 9 pages, 3 figures
Improving Bot Response Contradiction Detection via Utterance Rewriting
Jul 25, 2022
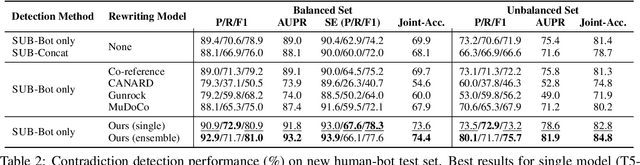
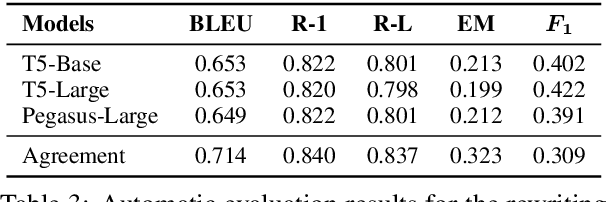
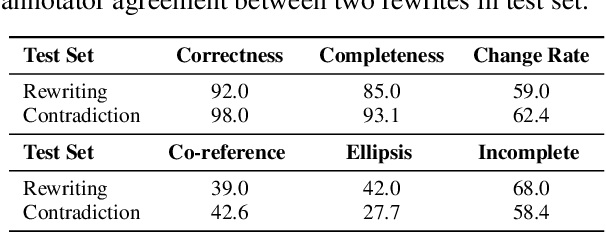
Though chatbots based on large neural models can often produce fluent responses in open domain conversations, one salient error type is contradiction or inconsistency with the preceding conversation turns. Previous work has treated contradiction detection in bot responses as a task similar to natural language inference, e.g., detect the contradiction between a pair of bot utterances. However, utterances in conversations may contain co-references or ellipsis, and using these utterances as is may not always be sufficient for identifying contradictions. This work aims to improve the contradiction detection via rewriting all bot utterances to restore antecedents and ellipsis. We curated a new dataset for utterance rewriting and built a rewriting model on it. We empirically demonstrate that this model can produce satisfactory rewrites to make bot utterances more complete. Furthermore, using rewritten utterances improves contradiction detection performance significantly, e.g., the AUPR and joint accuracy scores (detecting contradiction along with evidence) increase by 6.5% and 4.5% (absolute increase), respectively.
Generalization Guarantee of Training Graph Convolutional Networks with Graph Topology Sampling
Jul 07, 2022
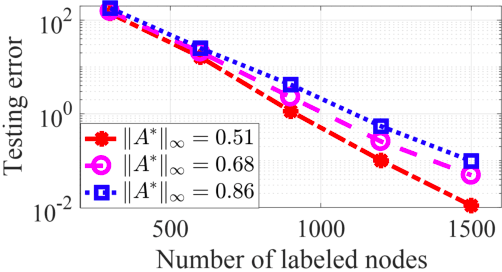
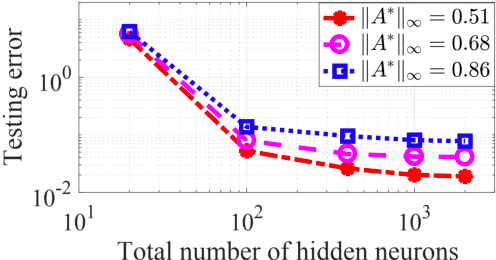

Graph convolutional networks (GCNs) have recently achieved great empirical success in learning graph-structured data. To address its scalability issue due to the recursive embedding of neighboring features, graph topology sampling has been proposed to reduce the memory and computational cost of training GCNs, and it has achieved comparable test performance to those without topology sampling in many empirical studies. To the best of our knowledge, this paper provides the first theoretical justification of graph topology sampling in training (up to) three-layer GCNs for semi-supervised node classification. We formally characterize some sufficient conditions on graph topology sampling such that GCN training leads to a diminishing generalization error. Moreover, our method tackles the nonconvex interaction of weights across layers, which is under-explored in the existing theoretical analyses of GCNs. This paper characterizes the impact of graph structures and topology sampling on the generalization performance and sample complexity explicitly, and the theoretical findings are also justified through numerical experiments.
The NLP Sandbox: an efficient model-to-data system to enable federated and unbiased evaluation of clinical NLP models
Jun 28, 2022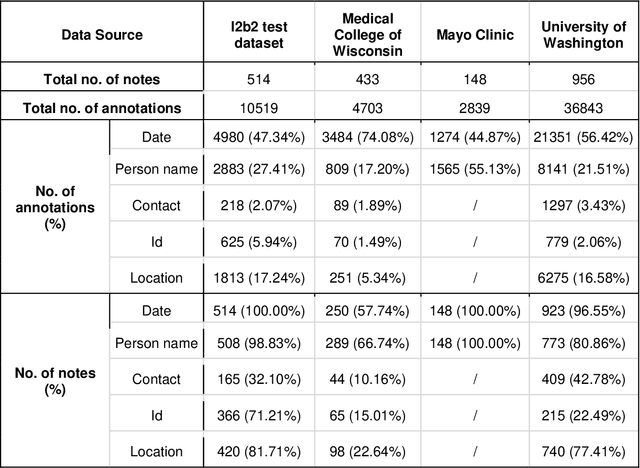
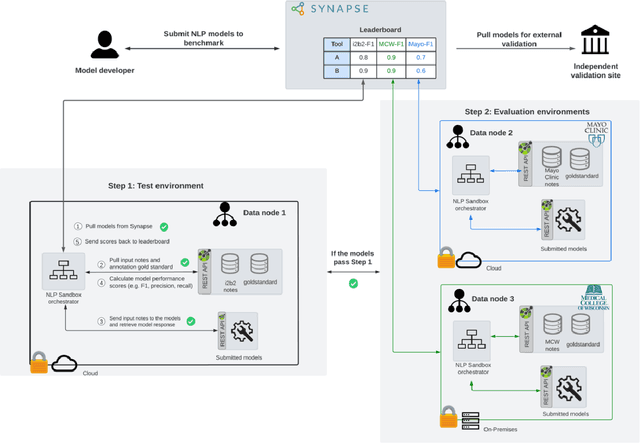
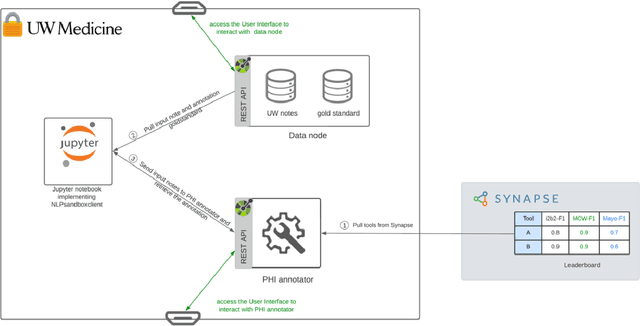
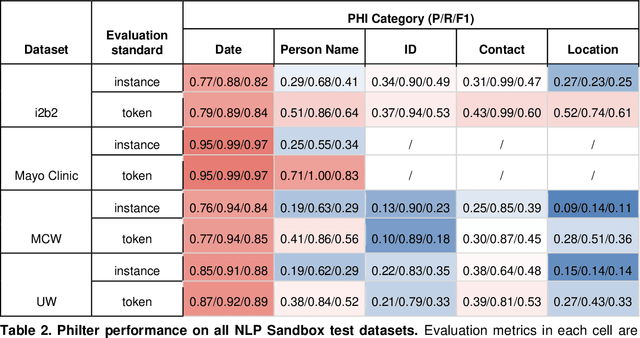
Objective The evaluation of natural language processing (NLP) models for clinical text de-identification relies on the availability of clinical notes, which is often restricted due to privacy concerns. The NLP Sandbox is an approach for alleviating the lack of data and evaluation frameworks for NLP models by adopting a federated, model-to-data approach. This enables unbiased federated model evaluation without the need for sharing sensitive data from multiple institutions. Materials and Methods We leveraged the Synapse collaborative framework, containerization software, and OpenAPI generator to build the NLP Sandbox (nlpsandbox.io). We evaluated two state-of-the-art NLP de-identification focused annotation models, Philter and NeuroNER, using data from three institutions. We further validated model performance using data from an external validation site. Results We demonstrated the usefulness of the NLP Sandbox through de-identification clinical model evaluation. The external developer was able to incorporate their model into the NLP Sandbox template and provide user experience feedback. Discussion We demonstrated the feasibility of using the NLP Sandbox to conduct a multi-site evaluation of clinical text de-identification models without the sharing of data. Standardized model and data schemas enable smooth model transfer and implementation. To generalize the NLP Sandbox, work is required on the part of data owners and model developers to develop suitable and standardized schemas and to adapt their data or model to fit the schemas. Conclusions The NLP Sandbox lowers the barrier to utilizing clinical data for NLP model evaluation and facilitates federated, multi-site, unbiased evaluation of NLP models.
Queried Unlabeled Data Improves and Robustifies Class-Incremental Learning
Jun 17, 2022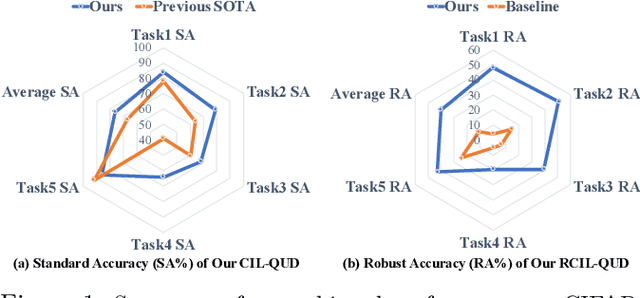
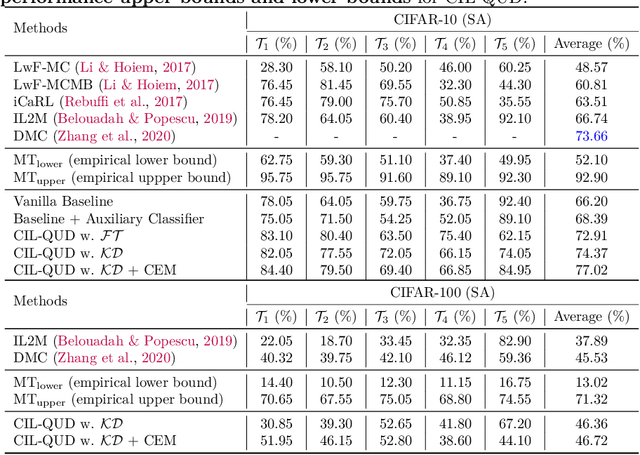
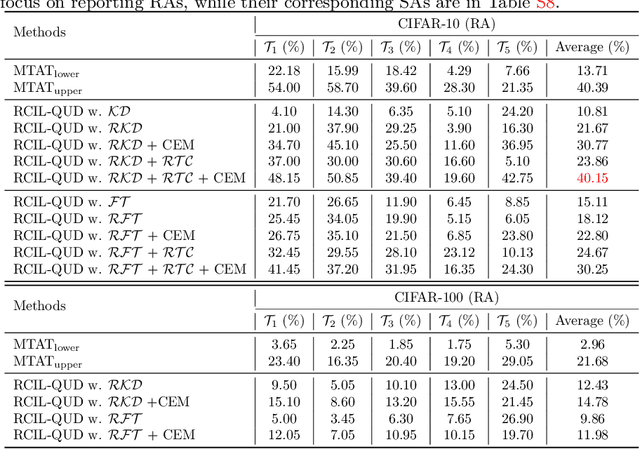
Class-incremental learning (CIL) suffers from the notorious dilemma between learning newly added classes and preserving previously learned class knowledge. That catastrophic forgetting issue could be mitigated by storing historical data for replay, which yet would cause memory overheads as well as imbalanced prediction updates. To address this dilemma, we propose to leverage "free" external unlabeled data querying in continual learning. We first present a CIL with Queried Unlabeled Data (CIL-QUD) scheme, where we only store a handful of past training samples as anchors and use them to query relevant unlabeled examples each time. Along with new and past stored data, the queried unlabeled are effectively utilized, through learning-without-forgetting (LwF) regularizers and class-balance training. Besides preserving model generalization over past and current tasks, we next study the problem of adversarial robustness for CIL-QUD. Inspired by the recent success of learning robust models with unlabeled data, we explore a new robustness-aware CIL setting, where the learned adversarial robustness has to resist forgetting and be transferred as new tasks come in continually. While existing options easily fail, we show queried unlabeled data can continue to benefit, and seamlessly extend CIL-QUD into its robustified versions, RCIL-QUD. Extensive experiments demonstrate that CIL-QUD achieves substantial accuracy gains on CIFAR-10 and CIFAR-100, compared to previous state-of-the-art CIL approaches. Moreover, RCIL-QUD establishes the first strong milestone for robustness-aware CIL. Codes are available in https://github.com/VITA-Group/CIL-QUD.