 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Arithmetic for Language Expansion in Speech Translation
Sep 17, 2024



Recent advances in large language models (LLMs) have gained interest in speech-text multimodal foundation models, achieving strong performance on instruction-based speech translation (ST). However, expanding language pairs from an existing instruction-tuned ST system is costly due to the necessity of re-training on a combination of new and previous datasets. We propose to expand new language pairs by merging the model trained on new language pairs and the existing model, using task arithmetic. We find that the direct application of task arithmetic for ST causes the merged model to fail to follow instructions; thus, generating translation in incorrect languages. To eliminate language confusion, we propose an augmented task arithmetic method that merges an additional language control model. It is trained to generate the correct target language token following the instructions. Our experiments demonstrate that our proposed language control model can achieve language expansion by eliminating language confusion. In our MuST-C and CoVoST-2 experiments, it shows up to 4.66 and 4.92 BLEU scores improvement, respectively. In addition, we demonstrate the use of our task arithmetic framework can expand to a language pair where neither paired ST training data nor a pre-trained ST model is available. We first synthesize the ST system from machine translation (MT) systems via task analogy, then merge the synthesized ST system to the existing ST model.
Exploring the Impact of Data Quantity on ASR in Extremely Low-resource Languages
Sep 13, 2024This study investigates the efficacy of data augmentation techniques for low-resource automatic speech recognition (ASR), focusing on two endangered Austronesian languages, Amis and Seediq. Recognizing the potential of self-supervised learning (SSL) in low-resource settings, we explore the impact of data volume on the continued pre-training of SSL models. We propose a novel data-selection scheme leveraging a multilingual corpus to augment the limited target language data. This scheme utilizes a language classifier to extract utterance embeddings and employs one-class classifiers to identify utterances phonetically and phonologically proximate to the target languages. Utterances are ranked and selected based on their decision scores, ensuring the inclusion of highly relevant data in the SSL-ASR pipeline. Our experimental results demonstrate the effectiveness of this approach, yielding substantial improvements in ASR performance for both Amis and Seediq. These findings underscore the feasibility and promise of data augmentation through cross-lingual transfer learning for low-resource language ASR.
Exploring Speech Recognition, Translation, and Understanding with Discrete Speech Units: A Comparative Study
Sep 27, 2023



Speech signals, typically sampled at rates in the tens of thousands per second, contain redundancies, evoking inefficiencies in sequence modeling. High-dimensional speech features such as spectrograms are often used as the input for the subsequent model. However, they can still be redundant. Recent investigations proposed the use of discrete speech units derived from self-supervised learning representations, which significantly compresses the size of speech data. Applying various methods, such as de-duplication and subword modeling, can further compress the speech sequence length. Hence, training time is significantly reduced while retaining notable performance. In this study, we undertake a comprehensive and systematic exploration into the application of discrete units within end-to-end speech processing models. Experiments on 12 automatic speech recognition, 3 speech translation, and 1 spoken language understanding corpora demonstrate that discrete units achieve reasonably good results in almost all the settings. We intend to release our configurations and trained models to foster future research efforts.
A Teacher-student Framework for Unsupervised Speech Enhancement Using Noise Remixing Training and Two-stage Inference
Oct 27, 2022



The lack of clean speech is a practical challenge to the development of speech enhancement systems, which means that the training of neural network models must be done in an unsupervised manner, and there is an inevitable mismatch between their training criterion and evaluation metric. In response to this unfavorable situation, we propose a teacher-student training strategy that does not require any subjective/objective speech quality metrics as learning reference by improving the previously proposed noisy-target training (NyTT). Because homogeneity between in-domain noise and extraneous noise is the key to the effectiveness of NyTT, we train various student models by remixing the teacher model's estimated speech and noise for clean-target training or raw noisy speech and the teacher model's estimated noise for noisy-target training. We use the NyTT model as the initial teacher model. Experimental results show that our proposed method outperforms several baselines, especially with two-stage inference, where clean speech is derived successively through the bootstrap model and the final student model.
CasNet: Investigating Channel Robustness for Speech Separation
Oct 27, 2022Recording channel mismatch between training and testing conditions has been shown to be a serious problem for speech separation. This situation greatly reduces the separation performance, and cannot meet the requirement of daily use. In this study, inheriting the use of our previously constructed TAT-2mix corpus, we address the channel mismatch problem by proposing a channel-aware audio separation network (CasNet), a deep learning framework for end-to-end time-domain speech separation. CasNet is implemented on top of TasNet. Channel embedding (characterizing channel information in a mixture of multiple utterances) generated by Channel Encoder is introduced into the separation module by the FiLM technique. Through two training strategies, we explore two roles that channel embedding may play: 1) a real-life noise disturbance, making the model more robust, or 2) a guide, instructing the separation model to retain the desired channel information. Experimental results on TAT-2mix show that CasNet trained with both training strategies outperforms the TasNet baseline, which does not use channel embeddings.
Chain-based Discriminative Autoencoders for Speech Recognition
Mar 28, 2022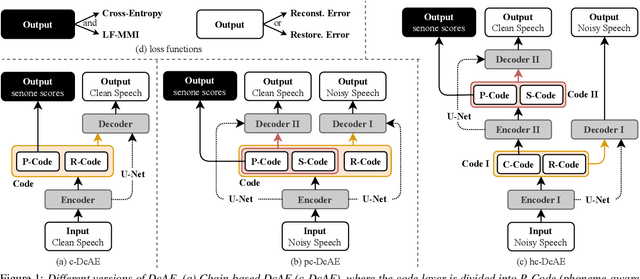
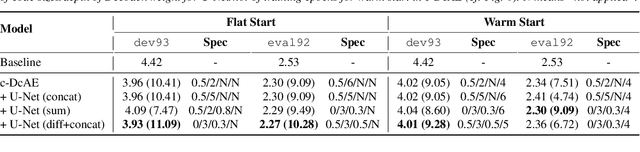
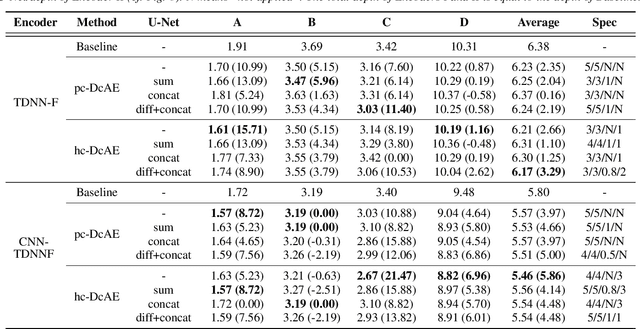
In our previous work, we proposed a discriminative autoencoder (DcAE) for speech recognition. DcAE combines two training schemes into one. First, since DcAE aims to learn encoder-decoder mappings, the squared error between the reconstructed speech and the input speech is minimized. Second, in the code layer, frame-based phonetic embeddings are obtained by minimizing the categorical cross-entropy between ground truth labels and predicted triphone-state scores. DcAE is developed based on the Kaldi toolkit by treating various TDNN models as encoders. In this paper, we further propose three new versions of DcAE. First, a new objective function that considers both categorical cross-entropy and mutual information between ground truth and predicted triphone-state sequences is used. The resulting DcAE is called a chain-based DcAE (c-DcAE). For application to robust speech recognition, we further extend c-DcAE to hierarchical and parallel structures, resulting in hc-DcAE and pc-DcAE. In these two models, both the error between the reconstructed noisy speech and the input noisy speech and the error between the enhanced speech and the reference clean speech are taken into the objective function. Experimental results on the WSJ and Aurora-4 corpora show that our DcAE models outperform baseline systems.
AlloST: Low-resource Speech Translation without Source Transcription
May 01, 2021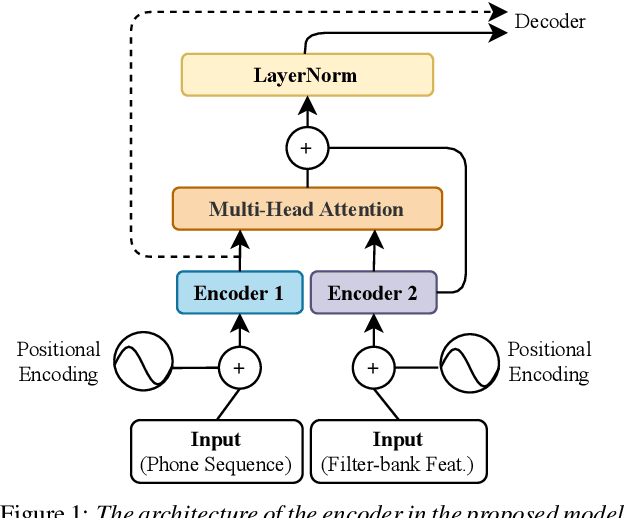
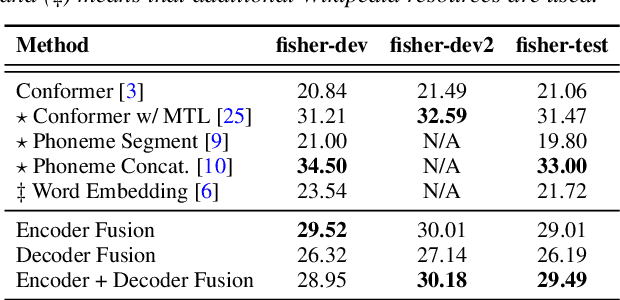
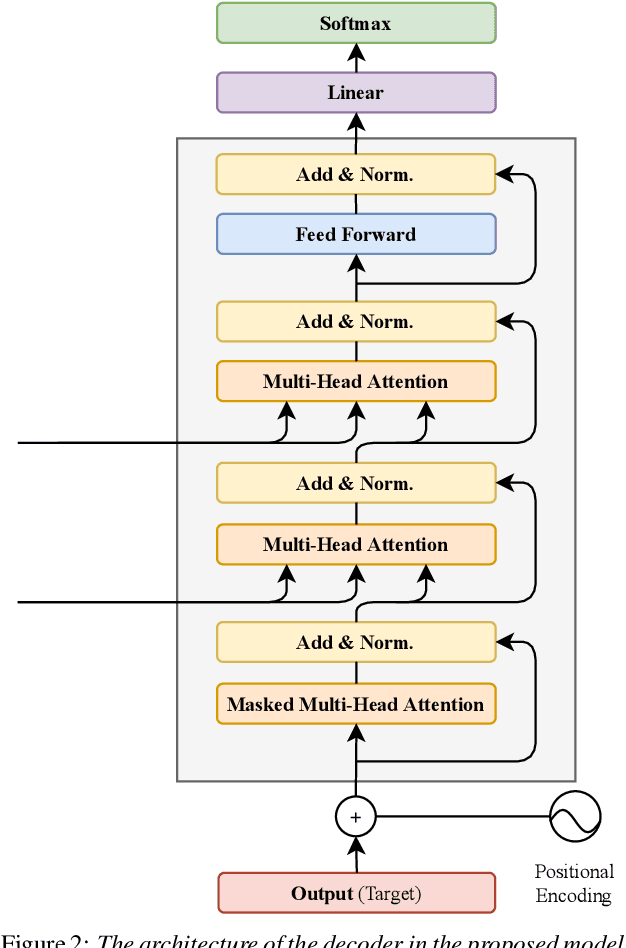

The end-to-end architecture has made promising progress in speech translation (ST). However, the ST task is still challenging under low-resource conditions. Most ST models have shown unsatisfactory results, especially in the absence of word information from the source speech utterance. In this study, we survey methods to improve ST performance without using source transcription, and propose a learning framework that utilizes a language-independent universal phone recognizer. The framework is based on an attention-based sequence-to-sequence model, where the encoder generates the phonetic embeddings and phone-aware acoustic representations, and the decoder controls the fusion of the two embedding streams to produce the target token sequence. In addition to investigating different fusion strategies, we explore the specific usage of byte pair encoding (BPE), which compresses a phone sequence into a syllable-like segmented sequence with semantic information. Experiments conducted on the Fisher Spanish-English and Taigi-Mandarin drama corpora show that our method outperforms the conformer-based baseline, and the performance is close to that of the existing best method using source transcription.