 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Non-Causal Factors are Out via Dataset Splitting for Domain Generalization Object Detection
Jan 27, 2026Open world object detection faces a significant challenge in domain-invariant representation, i.e., implicit non-causal factors. Most domain generalization (DG) methods based on domain adversarial learning (DAL) pay much attention to learn domain-invariant information, but often overlook the potential non-causal factors. We unveil two critical causes: 1) The domain discriminator-based DAL method is subject to the extremely sparse domain label, i.e., assigning only one domain label to each dataset, thus can only associate explicit non-causal factor, which is incredibly limited. 2) The non-causal factors, induced by unidentified data bias, are excessively implicit and cannot be solely discerned by conventional DAL paradigm. Based on these key findings, inspired by the Granular-Ball perspective, we propose an improved DAL method, i.e., GB-DAL. The proposed GB-DAL utilizes Prototype-based Granular Ball Splitting (PGBS) module to generate more dense domains from limited datasets, akin to more fine-grained granular balls, indicating more potential non-causal factors. Inspired by adversarial perturbations akin to non-causal factors, we propose a Simulated Non-causal Factors (SNF) module as a means of data augmentation to reduce the implicitness of non-causal factors, and facilitate the training of GB-DAL. Comparative experiments on numerous benchmarks demonstrate that our method achieves better generalization performance in novel circumstances.
Granular-ball Guided Masking: Structure-aware Data Augmentation
Dec 24, 2025Deep learning models have achieved remarkable success in computer vision, but they still rely heavily on large-scale labeled data and tend to overfit when data are limited or distributions shift. Data augmentation, particularly mask-based information dropping, can enhance robustness by forcing models to explore complementary cues; however, existing approaches often lack structural awareness and may discard essential semantics. We propose Granular-ball Guided Masking (GBGM), a structure-aware augmentation strategy guided by Granular-ball Computing (GBC). GBGM adaptively preserves semantically rich, structurally important regions while suppressing redundant areas through a coarse-to-fine hierarchical masking process, producing augmentations that are both representative and discriminative. Extensive experiments on multiple benchmarks demonstrate consistent improvements in classification accuracy and masked image reconstruction, confirming the effectiveness and broad applicability of the proposed method. Simple and model-agnostic, it integrates seamlessly into CNNs and Vision Transformers and provides a new paradigm for structure-aware data augmentation.
Finding Time Series Anomalies using Granular-ball Vector Data Description
Nov 15, 2025
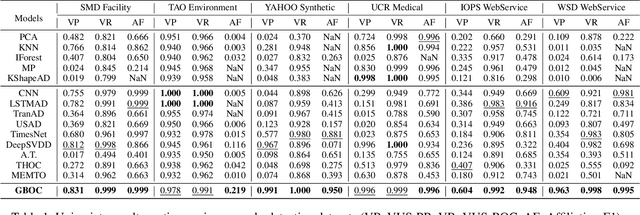
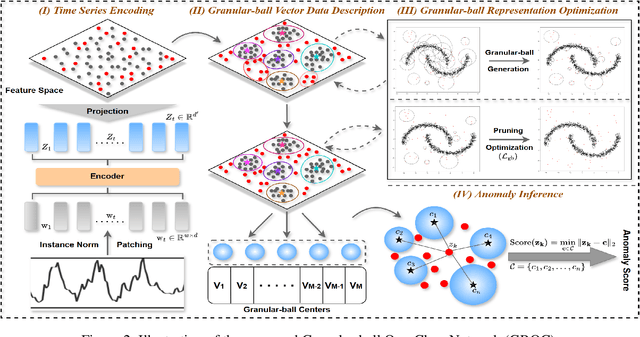
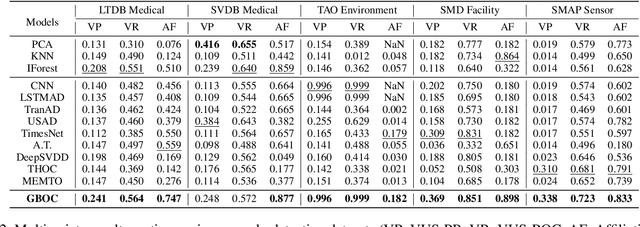
Modeling normal behavior in dynamic, nonlinear time series data is challenging for effective anomaly detection. Traditional methods, such as nearest neighbor and clustering approaches, often depend on rigid assumptions, such as a predefined number of reliable neighbors or clusters, which frequently break down in complex temporal scenarios. To address these limitations, we introduce the Granular-ball One-Class Network (GBOC), a novel approach based on a data-adaptive representation called Granular-ball Vector Data Description (GVDD). GVDD partitions the latent space into compact, high-density regions represented by granular-balls, which are generated through a density-guided hierarchical splitting process and refined by removing noisy structures. Each granular-ball serves as a prototype for local normal behavior, naturally positioning itself between individual instances and clusters while preserving the local topological structure of the sample set. During training, GBOC improves the compactness of representations by aligning samples with their nearest granular-ball centers. During inference, anomaly scores are computed based on the distance to the nearest granular-ball. By focusing on dense, high-quality regions and significantly reducing the number of prototypes, GBOC delivers both robustness and efficiency in anomaly detection. Extensive experiments validate the effectiveness and superiority of the proposed method, highlighting its ability to handle the challenges of time series anomaly detection.
GBGC: Efficient and Adaptive Graph Coarsening via Granular-ball Computing
Jun 24, 2025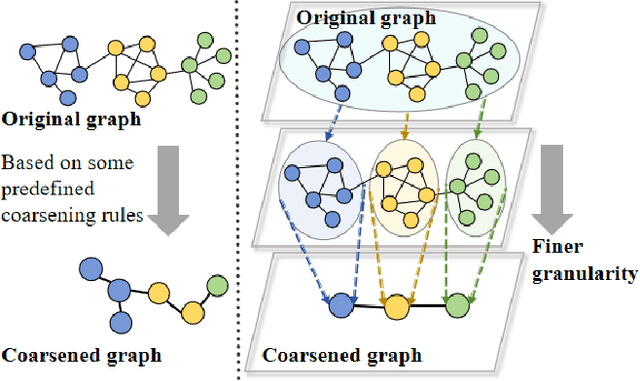
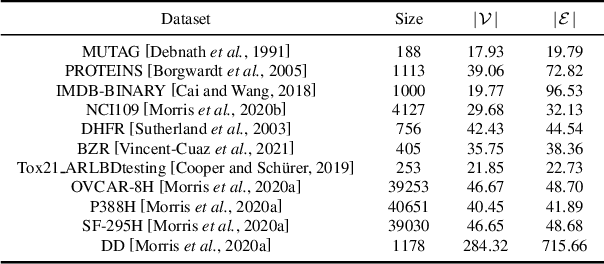
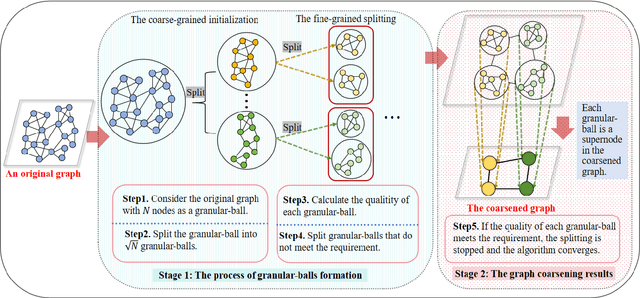

The objective of graph coarsening is to generate smaller, more manageable graphs while preserving key information of the original graph. Previous work were mainly based on the perspective of spectrum-preserving, using some predefined coarsening rules to make the eigenvalues of the Laplacian matrix of the original graph and the coarsened graph match as much as possible. However, they largely overlooked the fact that the original graph is composed of subregions at different levels of granularity, where highly connected and similar nodes should be more inclined to be aggregated together as nodes in the coarsened graph. By combining the multi-granularity characteristics of the graph structure, we can generate coarsened graph at the optimal granularity. To this end, inspired by the application of granular-ball computing in multi-granularity, we propose a new multi-granularity, efficient, and adaptive coarsening method via granular-ball (GBGC), which significantly improves the coarsening results and efficiency. Specifically, GBGC introduces an adaptive granular-ball graph refinement mechanism, which adaptively splits the original graph from coarse to fine into granular-balls of different sizes and optimal granularity, and constructs the coarsened graph using these granular-balls as supernodes. In addition, compared with other state-of-the-art graph coarsening methods, the processing speed of this method can be increased by tens to hundreds of times and has lower time complexity. The accuracy of GBGC is almost always higher than that of the original graph due to the good robustness and generalization of the granular-ball computing, so it has the potential to become a standard graph data preprocessing method.
Efficient Quantum Approximate $k$NN Algorithm via Granular-Ball Computing
May 29, 2025



High time complexity is one of the biggest challenges faced by $k$-Nearest Neighbors ($k$NN). Although current classical and quantum $k$NN algorithms have made some improvements, they still have a speed bottleneck when facing large amounts of data. To address this issue, we propose an innovative algorithm called Granular-Ball based Quantum $k$NN(GB-Q$k$NN). This approach achieves higher efficiency by first employing granular-balls, which reduces the data size needed to processed. The search process is then accelerated by adopting a Hierarchical Navigable Small World (HNSW) method. Moreover, we optimize the time-consuming steps, such as distance calculation, of the HNSW via quantization, further reducing the time complexity of the construct and search process. By combining the use of granular-balls and quantization of the HNSW method, our approach manages to take advantage of these treatments and significantly reduces the time complexity of the $k$NN-like algorithms, as revealed by a comprehensive complexity analysis.
GBFRS: Robust Fuzzy Rough Sets via Granular-ball Computing
Jan 30, 2025



Fuzzy rough set theory is effective for processing datasets with complex attributes, supported by a solid mathematical foundation and closely linked to kernel methods in machine learning. Attribute reduction algorithms and classifiers based on fuzzy rough set theory exhibit promising performance in the analysis of high-dimensional multivariate complex data. However, most existing models operate at the finest granularity, rendering them inefficient and sensitive to noise, especially for high-dimensional big data. Thus, enhancing the robustness of fuzzy rough set models is crucial for effective feature selection. Muiti-garanularty granular-ball computing, a recent development, uses granular-balls of different sizes to adaptively represent and cover the sample space, performing learning based on these granular-balls. This paper proposes integrating multi-granularity granular-ball computing into fuzzy rough set theory, using granular-balls to replace sample points. The coarse-grained characteristics of granular-balls make the model more robust. Additionally, we propose a new method for generating granular-balls, scalable to the entire supervised method based on granular-ball computing. A forward search algorithm is used to select feature sequences by defining the correlation between features and categories through dependence functions. Experiments demonstrate the proposed model's effectiveness and superiority over baseline methods.
A New Perspective on Privacy Protection in Federated Learning with Granular-Ball Computing
Jan 09, 2025Federated Learning (FL) facilitates collaborative model training while prioritizing privacy by avoiding direct data sharing. However, most existing articles attempt to address challenges within the model's internal parameters and corresponding outputs, while neglecting to solve them at the input level. To address this gap, we propose a novel framework called Granular-Ball Federated Learning (GrBFL) for image classification. GrBFL diverges from traditional methods that rely on the finest-grained input data. Instead, it segments images into multiple regions with optimal coarse granularity, which are then reconstructed into a graph structure. We designed a two-dimensional binary search segmentation algorithm based on variance constraints for GrBFL, which effectively removes redundant information while preserving key representative features. Extensive theoretical analysis and experiments demonstrate that GrBFL not only safeguards privacy and enhances efficiency but also maintains robust utility, consistently outperforming other state-of-the-art FL methods. The code is available at https://github.com/AIGNLAI/GrBFL.
Multi-Granularity Open Intent Classification via Adaptive Granular-Ball Decision Boundary
Dec 18, 2024



Open intent classification is critical for the development of dialogue systems, aiming to accurately classify known intents into their corresponding classes while identifying unknown intents. Prior boundary-based methods assumed known intents fit within compact spherical regions, focusing on coarse-grained representation and precise spherical decision boundaries. However, these assumptions are often violated in practical scenarios, making it difficult to distinguish known intent classes from unknowns using a single spherical boundary. To tackle these issues, we propose a Multi-granularity Open intent classification method via adaptive Granular-Ball decision boundary (MOGB). Our MOGB method consists of two modules: representation learning and decision boundary acquiring. To effectively represent the intent distribution, we design a hierarchical representation learning method. This involves iteratively alternating between adaptive granular-ball clustering and nearest sub-centroid classification to capture fine-grained semantic structures within known intent classes. Furthermore, multi-granularity decision boundaries are constructed for open intent classification by employing granular-balls with varying centroids and radii. Extensive experiments conducted on three public datasets demonstrate the effectiveness of our proposed method.
* This paper has been Accepted on AAAI2025
Graph Coarsening via Supervised Granular-Ball for Scalable Graph Neural Network Training
Dec 18, 2024



Graph Neural Networks (GNNs) have demonstrated significant achievements in processing graph data, yet scalability remains a substantial challenge. To address this, numerous graph coarsening methods have been developed. However, most existing coarsening methods are training-dependent, leading to lower efficiency, and they all require a predefined coarsening rate, lacking an adaptive approach. In this paper, we employ granular-ball computing to effectively compress graph data. We construct a coarsened graph network by iteratively splitting the graph into granular-balls based on a purity threshold and using these granular-balls as super vertices. This granulation process significantly reduces the size of the original graph, thereby greatly enhancing the training efficiency and scalability of GNNs. Additionally, our algorithm can adaptively perform splitting without requiring a predefined coarsening rate. Experimental results demonstrate that our method achieves accuracy comparable to training on the original graph. Noise injection experiments further indicate that our method exhibits robust performance. Moreover, our approach can reduce the graph size by up to 20 times without compromising test accuracy, substantially enhancing the scalability of GNNs.
EvoSampling: A Granular Ball-based Evolutionary Hybrid Sampling with Knowledge Transfer for Imbalanced Learning
Dec 12, 2024



Class imbalance would lead to biased classifiers that favor the majority class and disadvantage the minority class. Unfortunately, from a practical perspective, the minority class is of importance in many real-life applications. Hybrid sampling methods address this by oversampling the minority class to increase the number of its instances, followed by undersampling to remove low-quality instances. However, most existing sampling methods face difficulties in generating diverse high-quality instances and often fail to remove noise or low-quality instances on a larger scale effectively. This paper therefore proposes an evolutionary multi-granularity hybrid sampling method, called EvoSampling. During the oversampling process, genetic programming (GP) is used with multi-task learning to effectively and efficiently generate diverse high-quality instances. During the undersampling process, we develop a granular ball-based undersampling method that removes noise in a multi-granular fashion, thereby enhancing data quality. Experiments on 20 imbalanced datasets demonstrate that EvoSampling effectively enhances the performance of various classification algorithms by providing better datasets than existing sampling methods. Besides, ablation studies further indicate that allowing knowledge transfer accelerates the GP's evolutionary learning process.