 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bilingual Parallel Corpus with Discourse Annotations
Oct 26, 2022



Machine translation (MT) has almost achieved human parity at sentence-level translation. In response, the MT community has, in part, shifted its focus to document-level translation. However, the development of document-level MT systems is hampered by the lack of parallel document corpora. This paper describes BWB, a large parallel corpus first introduced in Jiang et al. (2022), along with an annotated test set. The BWB corpus consists of Chinese novels translated by experts into English, and the annotated test set is designed to probe the ability of machine translation systems to model various discourse phenomena. Our resource is freely available, and we hope it will serve as a guide and inspiration for more work in document-level machine translation.
Foundation Transformers
Oct 19, 2022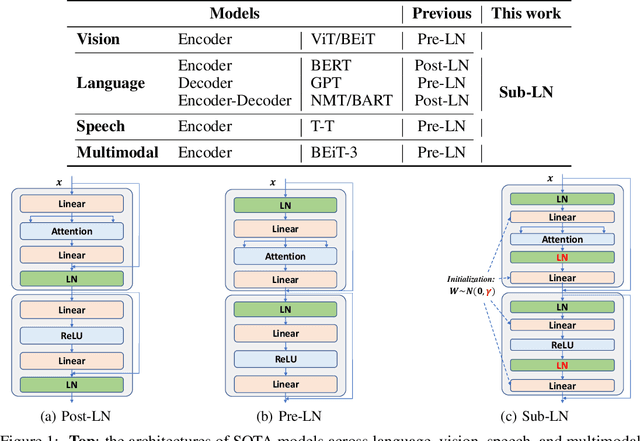
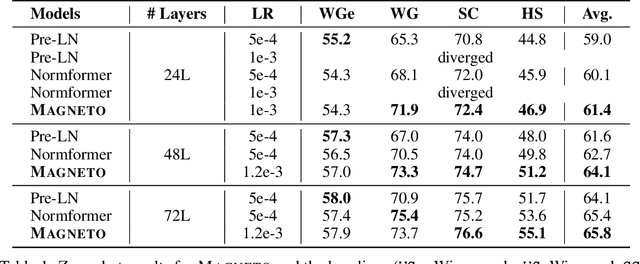
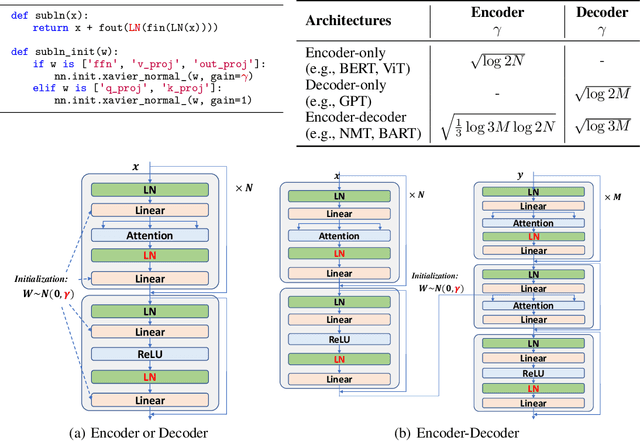
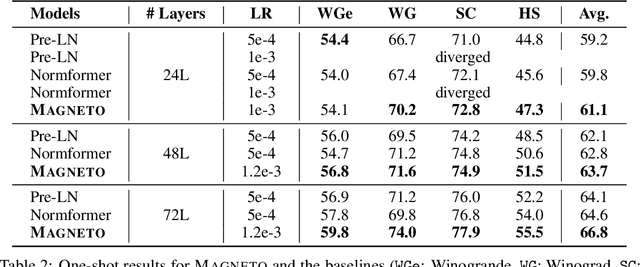
A big convergence of model architectures across language, vision, speech, and multimodal is emerging. However, under the same name "Transformers", the above areas use different implementations for better performance, e.g., Post-LayerNorm for BERT, and Pre-LayerNorm for GPT and vision Transformers. We call for the development of Foundation Transformer for true general-purpose modeling, which serves as a go-to architecture for various tasks and modalities with guaranteed training stability. In this work, we introduce a Transformer variant, named Magneto, to fulfill the goal. Specifically, we propose Sub-LayerNorm for good expressivity, and the initialization strategy theoretically derived from DeepNet for stable scaling up. Extensive experiments demonstrate its superior performance and better stability than the de facto Transformer variants designed for various applications, including language modeling (i.e., BERT, and GPT), machine translation, vision pretraining (i.e., BEiT), speech recognition, and multimodal pretraining (i.e., BEiT-3).
CROP: Zero-shot Cross-lingual Named Entity Recognition with Multilingual Labeled Sequence Translation
Oct 13, 2022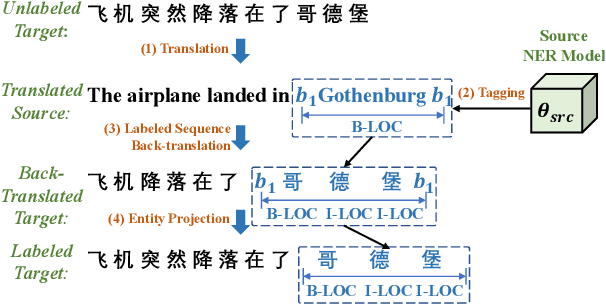
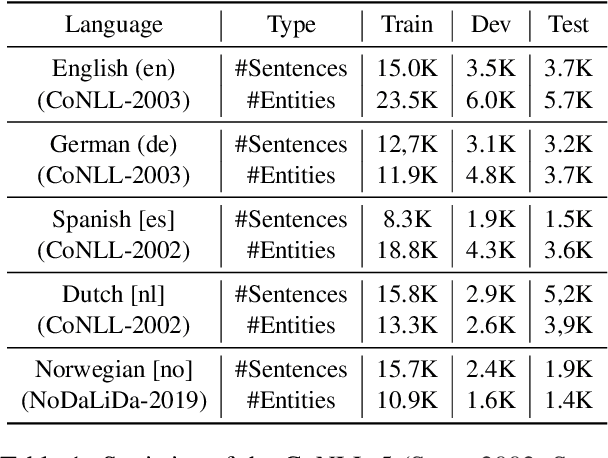
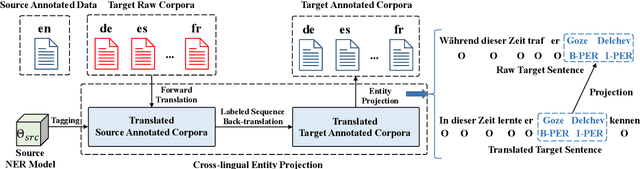
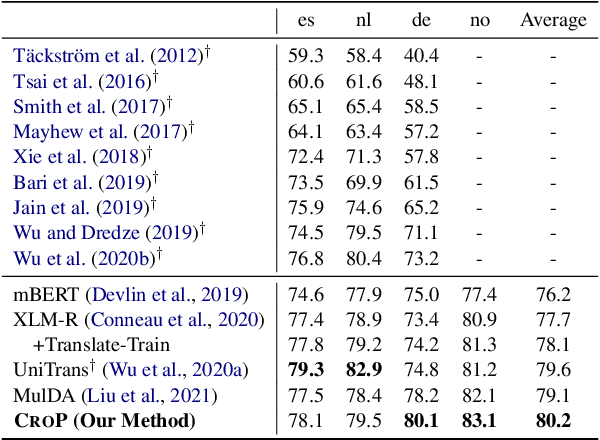
Named entity recognition (NER) suffers from the scarcity of annotated training data, especially for low-resource languages without labeled data. Cross-lingual NER has been proposed to alleviate this issue by transferring knowledge from high-resource languages to low-resource languages via aligned cross-lingual representations or machine translation results. However, the performance of cross-lingual NER methods is severely affected by the unsatisfactory quality of translation or label projection. To address these problems, we propose a Cross-lingual Entity Projection framework (CROP) to enable zero-shot cross-lingual NER with the help of a multilingual labeled sequence translation model. Specifically, the target sequence is first translated into the source language and then tagged by a source NER model. We further adopt a labeled sequence translation model to project the tagged sequence back to the target language and label the target raw sentence. Ultimately, the whole pipeline is integrated into an end-to-end model by the way of self-training. Experimental results on two benchmarks demonstrate that our method substantially outperforms the previous strong baseline by a large margin of +3~7 F1 scores and achieves state-of-the-art performance.
Multilingual Transitivity and Bidirectional Multilingual Agreement for Multilingual Document-level Machine Translation
Oct 05, 2022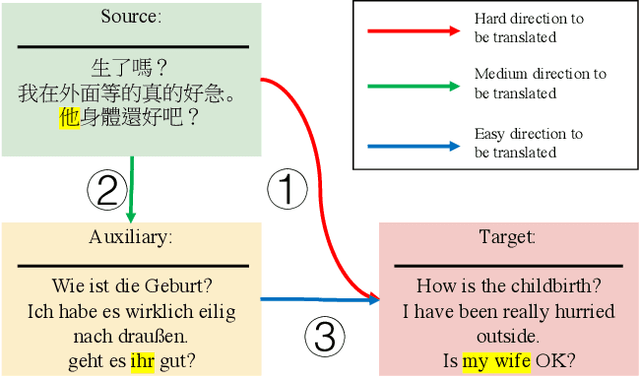
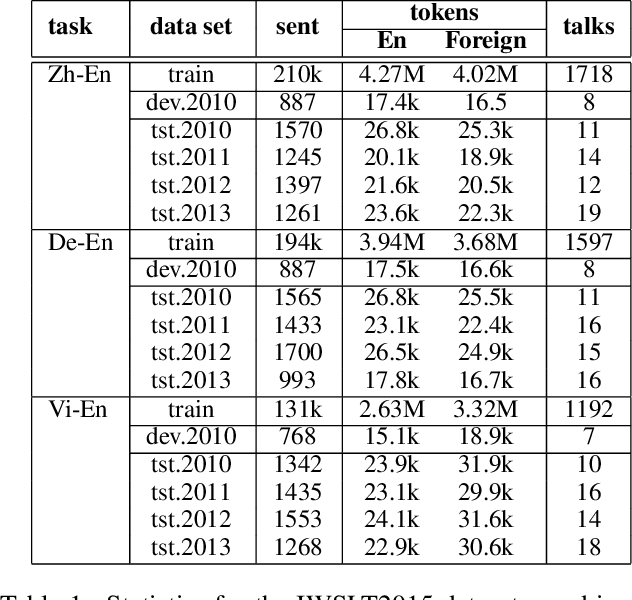
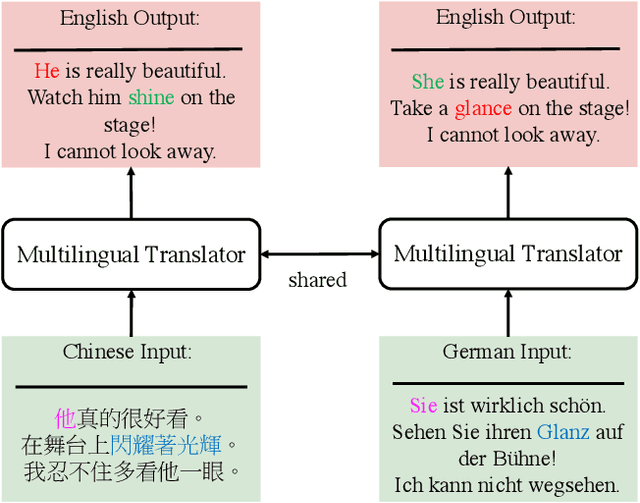

Multilingual machine translation has been proven an effective strategy to support translation between multiple languages with a single model. However, most studies focus on multilingual sentence translation without considering generating long documents across different languages, which requires an understanding of multilingual context dependency and is typically harder. In this paper, we first spot that naively incorporating auxiliary multilingual data either auxiliary-target or source-auxiliary brings no improvement to the source-target language pair in our interest. Motivated by this observation, we propose a novel framework called Multilingual Transitivity (MTrans) to find an implicit optimal route via source-auxiliary-target within the multilingual model. To encourage MTrans, we propose a novel method called Triplet Parallel Data (TPD), which uses parallel triplets that contain (source-auxiliary, auxiliary-target, and source-target) for training. The auxiliary language then serves as a pivot and automatically facilitates the implicit information transition flow which is easier to translate. We further propose a novel framework called Bidirectional Multilingual Agreement (Bi-MAgree) that encourages the bidirectional agreement between different languages. To encourage Bi-MAgree, we propose a novel method called Multilingual Kullback-Leibler Divergence (MKL) that forces the output distribution of the inputs with the same meaning but in different languages to be consistent with each other. The experimental results indicate that our methods bring consistent improvements over strong baselines on three document translation tasks: IWSLT2015 Zh-En, De-En, and Vi-En. Our analysis validates the usefulness and existence of MTrans and Bi-MAgree, and our frameworks and methods are effective on synthetic auxiliary data.
GTrans: Grouping and Fusing Transformer Layers for Neural Machine Translation
Jul 29, 2022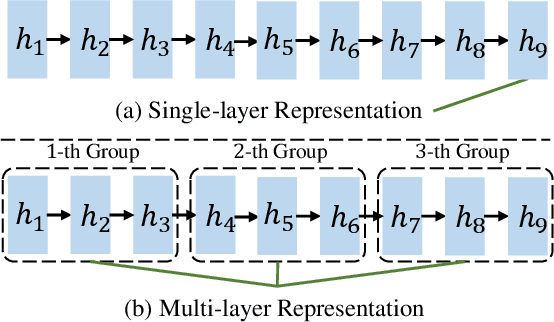
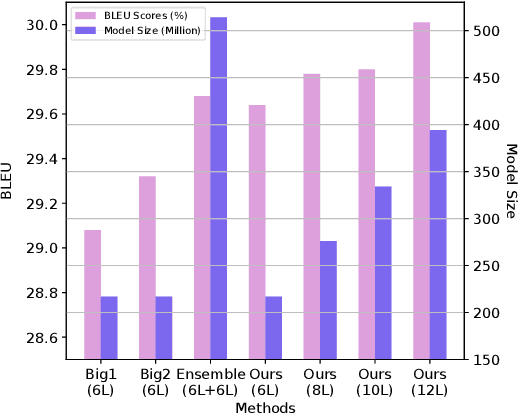
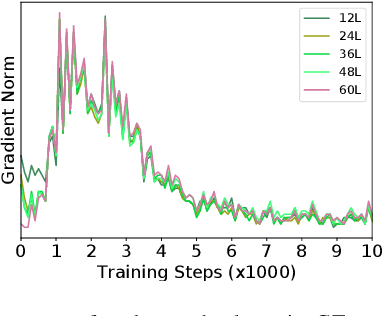
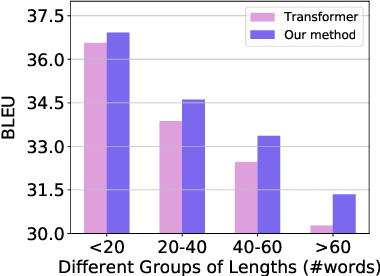
Transformer structure, stacked by a sequence of encoder and decoder network layers, achieves significant development in neural machine translation. However, vanilla Transformer mainly exploits the top-layer representation, assuming the lower layers provide trivial or redundant information and thus ignoring the bottom-layer feature that is potentially valuable. In this work, we propose the Group-Transformer model (GTrans) that flexibly divides multi-layer representations of both encoder and decoder into different groups and then fuses these group features to generate target words. To corroborate the effectiveness of the proposed method, extensive experiments and analytic experiments are conducted on three bilingual translation benchmarks and two multilingual translation tasks, including the IWLST-14, IWLST-17, LDC, WMT-14 and OPUS-100 benchmark. Experimental and analytical results demonstrate that our model outperforms its Transformer counterparts by a consistent gain. Furthermore, it can be successfully scaled up to 60 encoder layers and 36 decoder layers.
HLT-MT: High-resource Language-specific Training for Multilingual Neural Machine Translation
Jul 15, 2022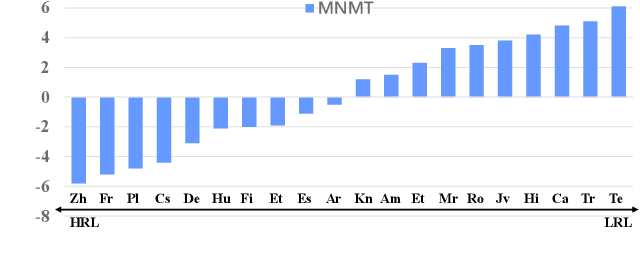
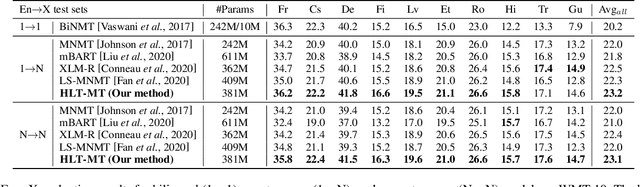
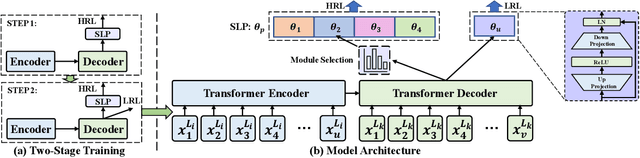

Multilingual neural machine translation (MNMT) trained in multiple language pairs has attracted considerable attention due to fewer model parameters and lower training costs by sharing knowledge among multiple languages. Nonetheless, multilingual training is plagued by language interference degeneration in shared parameters because of the negative interference among different translation directions, especially on high-resource languages. In this paper, we propose the multilingual translation model with the high-resource language-specific training (HLT-MT) to alleviate the negative interference, which adopts the two-stage training with the language-specific selection mechanism. Specifically, we first train the multilingual model only with the high-resource pairs and select the language-specific modules at the top of the decoder to enhance the translation quality of high-resource directions. Next, the model is further trained on all available corpora to transfer knowledge from high-resource languages (HRLs) to low-resource languages (LRLs). Experimental results show that HLT-MT outperforms various strong baselines on WMT-10 and OPUS-100 benchmarks. Furthermore, the analytic experiments validate the effectiveness of our method in mitigating the negative interference in multilingual training.
UM4: Unified Multilingual Multiple Teacher-Student Model for Zero-Resource Neural Machine Translation
Jul 11, 2022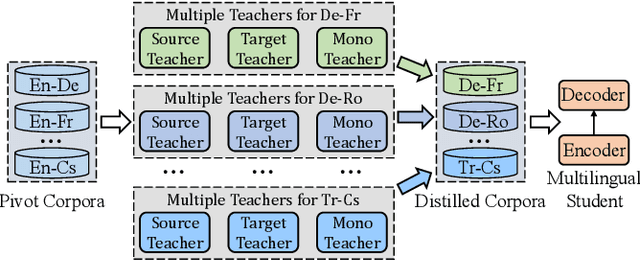
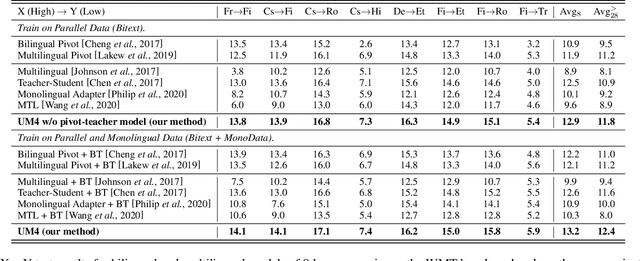
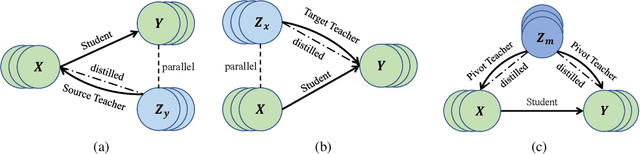
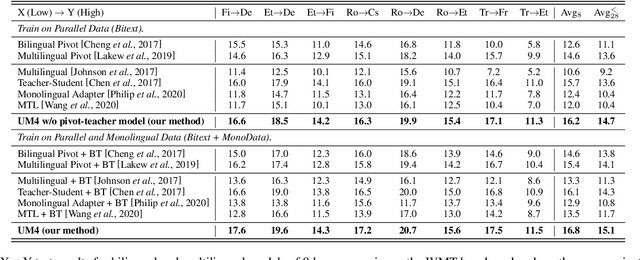
Most translation tasks among languages belong to the zero-resource translation problem where parallel corpora are unavailable. Multilingual neural machine translation (MNMT) enables one-pass translation using shared semantic space for all languages compared to the two-pass pivot translation but often underperforms the pivot-based method. In this paper, we propose a novel method, named as Unified Multilingual Multiple teacher-student Model for NMT (UM4). Our method unifies source-teacher, target-teacher, and pivot-teacher models to guide the student model for the zero-resource translation. The source teacher and target teacher force the student to learn the direct source to target translation by the distilled knowledge on both source and target sides. The monolingual corpus is further leveraged by the pivot-teacher model to enhance the student model. Experimental results demonstrate that our model of 72 directions significantly outperforms previous methods on the WMT benchmark.
Language Models are General-Purpose Interfaces
Jun 13, 2022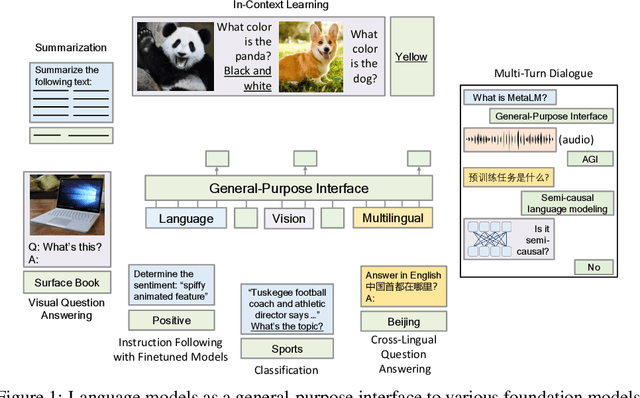

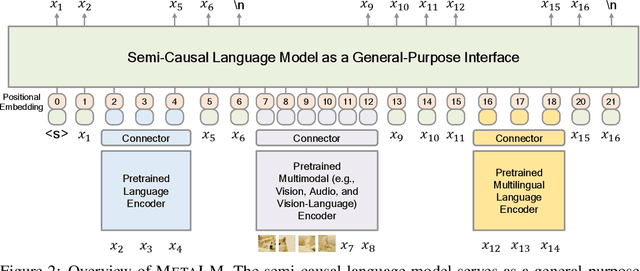
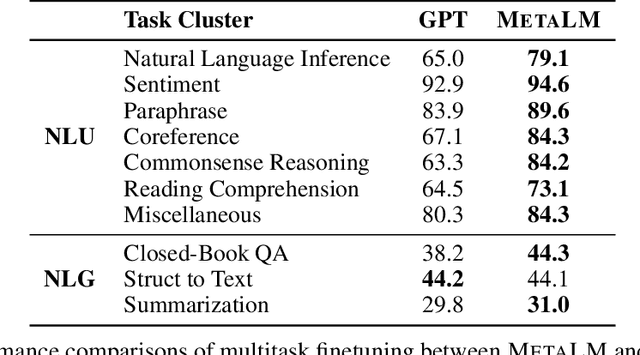
Foundation models have received much attention due to their effectiveness across a broad range of downstream applications. Though there is a big convergence in terms of architecture, most pretrained models are typically still developed for specific tasks or modalities. In this work, we propose to use language models as a general-purpose interface to various foundation models. A collection of pretrained encoders perceive diverse modalities (such as vision, and language), and they dock with a language model that plays the role of a universal task layer. We propose a semi-causal language modeling objective to jointly pretrain the interface and the modular encoders. We subsume the advantages and capabilities from both causal and non-causal modeling, thereby combining the best of two worlds. Specifically, the proposed method not only inherits the capabilities of in-context learning and open-ended generation from causal language modeling, but also is conducive to finetuning because of the bidirectional encoders. More importantly, our approach seamlessly unlocks the combinations of the above capabilities, e.g., enabling in-context learning or instruction following with finetuned encoders. Experimental results across various language-only and vision-language benchmarks show that our model outperforms or is competitive with specialized models on finetuning, zero-shot generalization, and few-shot learning.
On the Representation Collapse of Sparse Mixture of Experts
Apr 20, 2022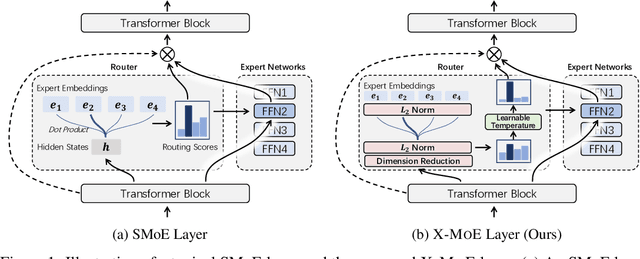
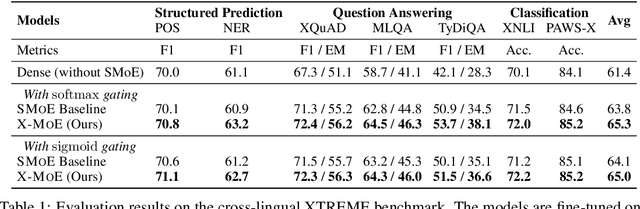
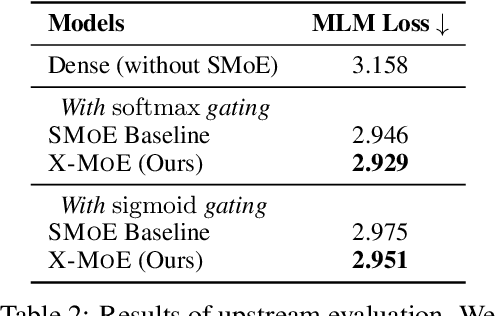
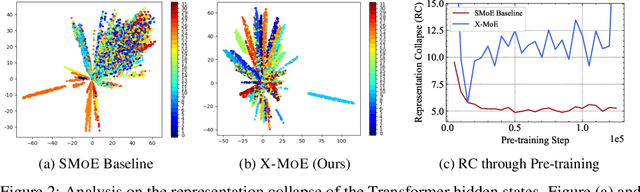
Sparse mixture of experts provides larger model capacity while requiring a constant computational overhead. It employs the routing mechanism to distribute input tokens to the best-matched experts according to their hidden representations. However, learning such a routing mechanism encourages token clustering around expert centroids, implying a trend toward representation collapse. In this work, we propose to estimate the routing scores between tokens and experts on a low-dimensional hypersphere. We conduct extensive experiments on cross-lingual language model pre-training and fine-tuning on downstream tasks. Experimental results across seven multilingual benchmarks show that our method achieves consistent gains. We also present a comprehensive analysis on the representation and routing behaviors of our models. Our method alleviates the representation collapse issue and achieves more consistent routing than the baseline mixture-of-experts methods.
StableMoE: Stable Routing Strategy for Mixture of Experts
Apr 18, 2022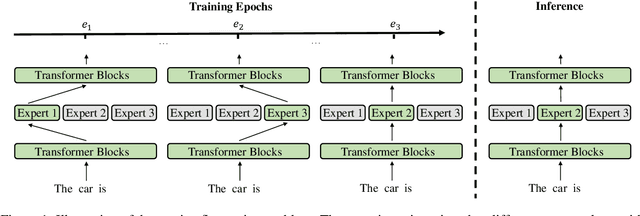

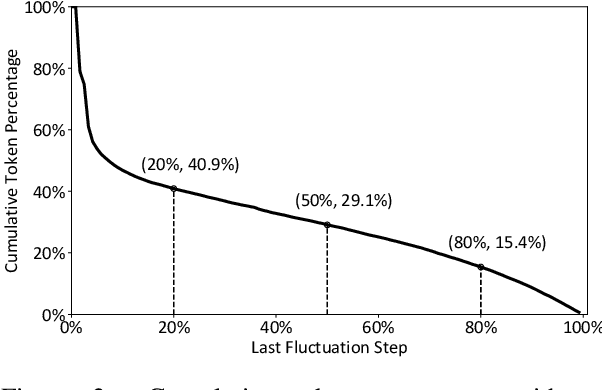
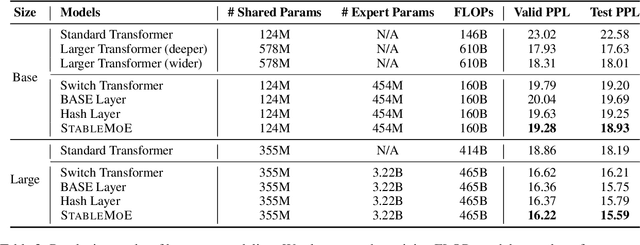
The Mixture-of-Experts (MoE) technique can scale up the model size of Transformers with an affordable computational overhead. We point out that existing learning-to-route MoE methods suffer from the routing fluctuation issue, i.e., the target expert of the same input may change along with training, but only one expert will be activated for the input during inference. The routing fluctuation tends to harm sample efficiency because the same input updates different experts but only one is finally used. In this paper, we propose StableMoE with two training stages to address the routing fluctuation problem. In the first training stage, we learn a balanced and cohesive routing strategy and distill it into a lightweight router decoupled from the backbone model. In the second training stage, we utilize the distilled router to determine the token-to-expert assignment and freeze it for a stable routing strategy. We validate our method on language modeling and multilingual machine translation. The results show that StableMoE outperforms existing MoE methods in terms of both convergence speed and performance.