 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDMuse: Stochastic Differential Music Editing and Generation via Hybrid Representation
Nov 02, 2022While deep generative models have empowered music generation, it remains a challenging and under-explored problem to edit an existing musical piece at fine granularity. In this paper, we propose SDMuse, a unified Stochastic Differential Music editing and generation framework, which can not only compose a whole musical piece from scratch, but also modify existing musical pieces in many ways, such as combination, continuation, inpainting, and style transferring. The proposed SDMuse follows a two-stage pipeline to achieve music generation and editing on top of a hybrid representation including pianoroll and MIDI-event. In particular, SDMuse first generates/edits pianoroll by iteratively denoising through a stochastic differential equation (SDE) based on a diffusion model generative prior, and then refines the generated pianoroll and predicts MIDI-event tokens auto-regressively. We evaluate the generated music of our method on ailabs1k7 pop music dataset in terms of quality and controllability on various music editing and generation tasks. Experimental results demonstrate the effectiveness of our proposed stochastic differential music editing and generation process, as well as the hybrid representations.
MetaFormer Baselines for Vision
Oct 24, 2022



MetaFormer, the abstracted architecture of Transformer, has been found to play a significant role in achieving competitive performance. In this paper, we further explore the capacity of MetaFormer, again, without focusing on token mixer design: we introduce several baseline models under MetaFormer using the most basic or common mixers, and summarize our observations as follows: (1) MetaFormer ensures solid lower bound of performance. By merely adopting identity mapping as the token mixer, the MetaFormer model, termed IdentityFormer, achieves >80% accuracy on ImageNet-1K. (2) MetaFormer works well with arbitrary token mixers. When specifying the token mixer as even a random matrix to mix tokens, the resulting model RandFormer yields an accuracy of >81%, outperforming IdentityFormer. Rest assured of MetaFormer's results when new token mixers are adopted. (3) MetaFormer effortlessly offers state-of-the-art results. With just conventional token mixers dated back five years ago, the models instantiated from MetaFormer already beat state of the art. (a) ConvFormer outperforms ConvNeXt. Taking the common depthwise separable convolutions as the token mixer, the model termed ConvFormer, which can be regarded as pure CNNs, outperforms the strong CNN model ConvNeXt. (b) CAFormer sets new record on ImageNet-1K. By simply applying depthwise separable convolutions as token mixer in the bottom stages and vanilla self-attention in the top stages, the resulting model CAFormer sets a new record on ImageNet-1K: it achieves an accuracy of 85.5% at 224x224 resolution, under normal supervised training without external data or distillation. In our expedition to probe MetaFormer, we also find that a new activation, StarReLU, reduces 71% FLOPs of activation compared with GELU yet achieves better performance. We expect StarReLU to find great potential in MetaFormer-like models alongside other neural networks.
RPM: Generalizable Behaviors for Multi-Agent Reinforcement Learning
Oct 18, 2022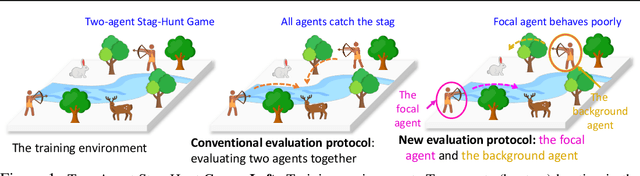


Despite the recent advancement in multi-agent reinforcement learning (MARL), the MARL agents easily overfit the training environment and perform poorly in the evaluation scenarios where other agents behave differently. Obtaining generalizable policies for MARL agents is thus necessary but challenging mainly due to complex multi-agent interactions. In this work, we model the problem with Markov Games and propose a simple yet effective method, ranked policy memory (RPM), to collect diverse multi-agent trajectories for training MARL policies with good generalizability. The main idea of RPM is to maintain a look-up memory of policies. In particular, we try to acquire various levels of behaviors by saving policies via ranking the training episode return, i.e., the episode return of agents in the training environment; when an episode starts, the learning agent can then choose a policy from the RPM as the behavior policy. This innovative self-play training framework leverages agents' past policies and guarantees the diversity of multi-agent interaction in the training data. We implement RPM on top of MARL algorithms and conduct extensive experiments on Melting Pot. It has been demonstrated that RPM enables MARL agents to interact with unseen agents in multi-agent generalization evaluation scenarios and complete given tasks, and it significantly boosts the performance up to 402% on average.
Boosting Offline Reinforcement Learning via Data Rebalancing
Oct 17, 2022
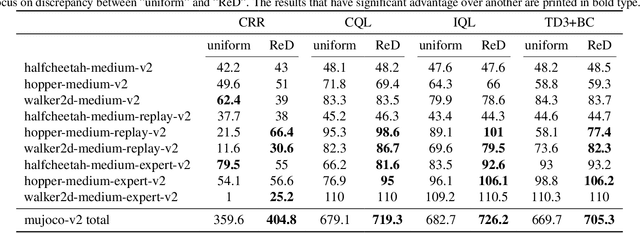
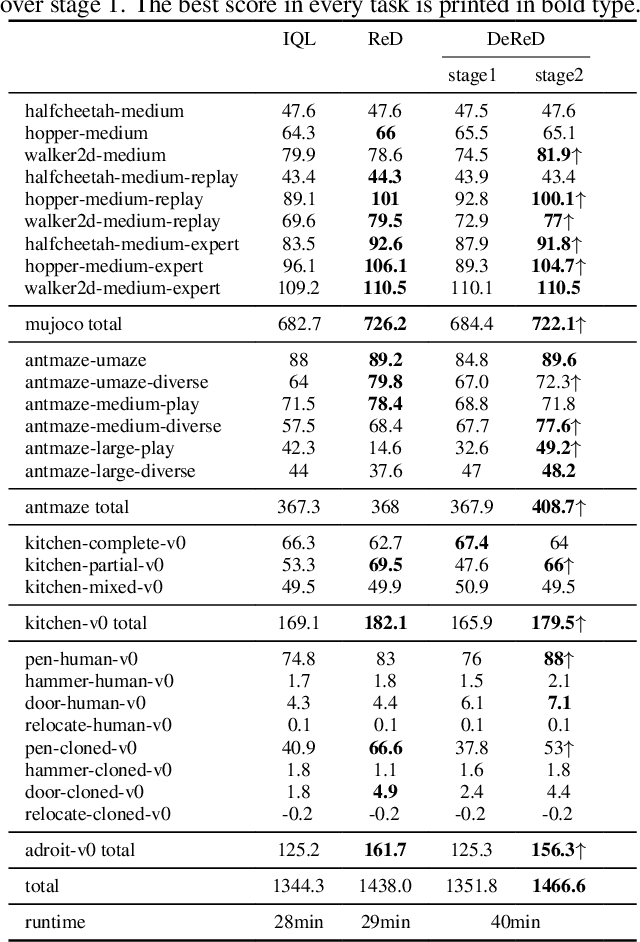
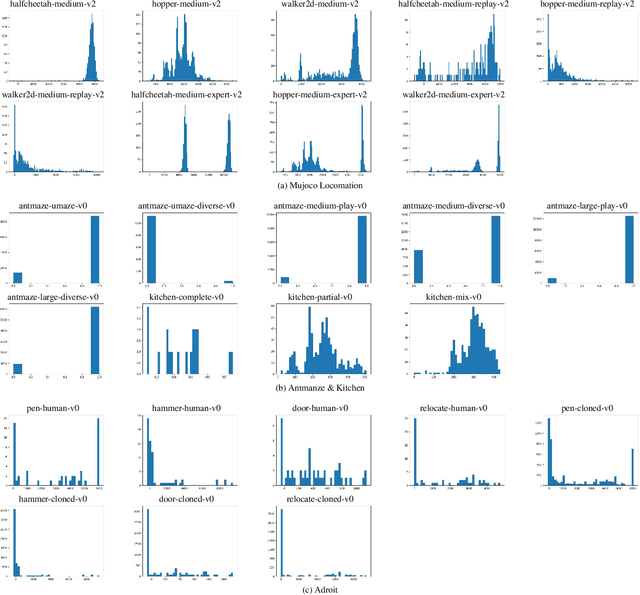
Offline reinforcement learning (RL) is challenged by the distributional shift between learning policies and datasets. To address this problem, existing works mainly focus on designing sophisticated algorithms to explicitly or implicitly constrain the learned policy to be close to the behavior policy. The constraint applies not only to well-performing actions but also to inferior ones, which limits the performance upper bound of the learned policy. Instead of aligning the densities of two distributions, aligning the supports gives a relaxed constraint while still being able to avoid out-of-distribution actions. Therefore, we propose a simple yet effective method to boost offline RL algorithms based on the observation that resampling a dataset keeps the distribution support unchanged. More specifically, we construct a better behavior policy by resampling each transition in an old dataset according to its episodic return. We dub our method ReD (Return-based Data Rebalance), which can be implemented with less than 10 lines of code change and adds negligible running time. Extensive experiments demonstrate that ReD is effective at boosting offline RL performance and orthogonal to decoupling strategies in long-tailed classification. New state-of-the-arts are achieved on the D4RL benchmark.
Mutual Information Regularized Offline Reinforcement Learning
Oct 14, 2022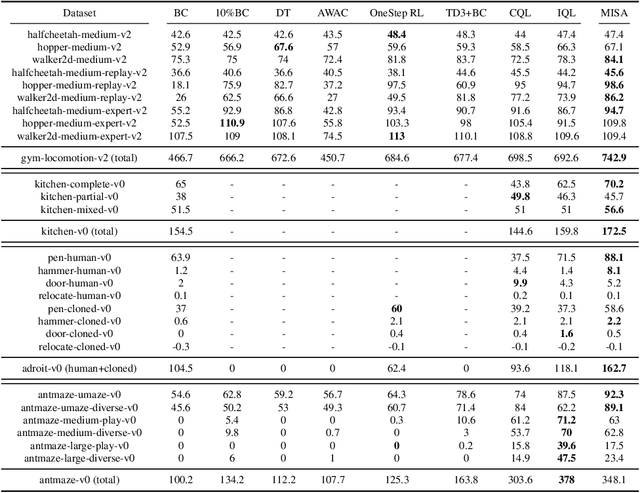
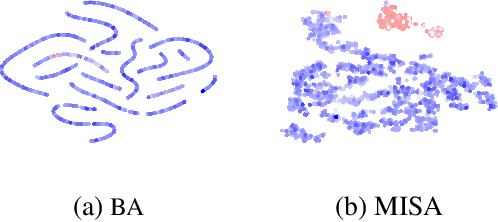
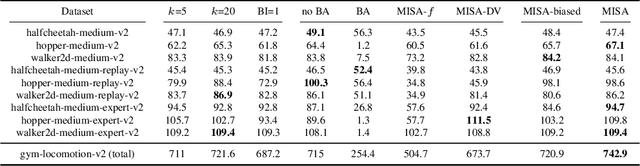

Offline reinforcement learning (RL) aims at learning an effective policy from offline datasets without active interactions with the environment. The major challenge of offline RL is the distribution shift that appears when out-of-distribution actions are queried, which makes the policy improvement direction biased by extrapolation errors. Most existing methods address this problem by penalizing the policy for deviating from the behavior policy during policy improvement or making conservative updates for value functions during policy evaluation. In this work, we propose a novel MISA framework to approach offline RL from the perspective of Mutual Information between States and Actions in the dataset by directly constraining the policy improvement direction. Intuitively, mutual information measures the mutual dependence of actions and states, which reflects how a behavior agent reacts to certain environment states during data collection. To effectively utilize this information to facilitate policy learning, MISA constructs lower bounds of mutual information parameterized by the policy and Q-values. We show that optimizing this lower bound is equivalent to maximizing the likelihood of a one-step improved policy on the offline dataset. In this way, we constrain the policy improvement direction to lie in the data manifold. The resulting algorithm simultaneously augments the policy evaluation and improvement by adding a mutual information regularization. MISA is a general offline RL framework that unifies conservative Q-learning (CQL) and behavior regularization methods (e.g., TD3+BC) as special cases. Our experiments show that MISA performs significantly better than existing methods and achieves new state-of-the-art on various tasks of the D4RL benchmark.
Efficient Offline Policy Optimization with a Learned Model
Oct 12, 2022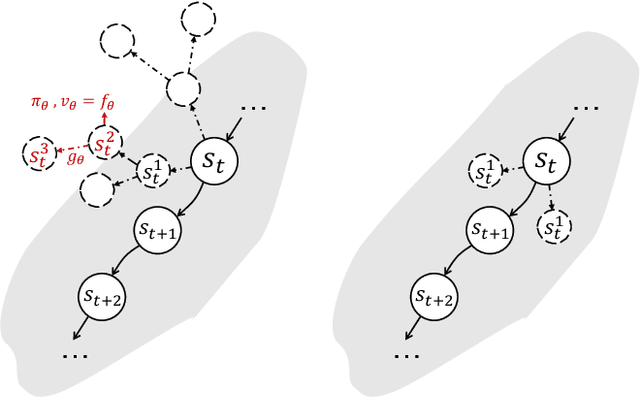
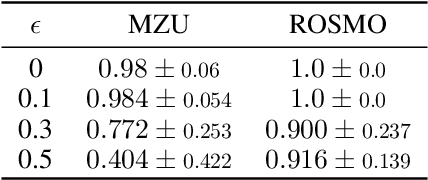
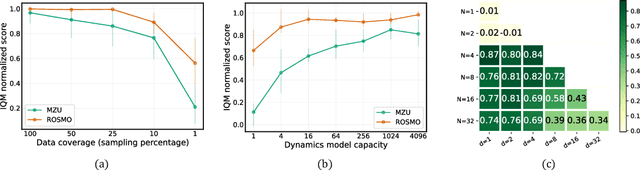
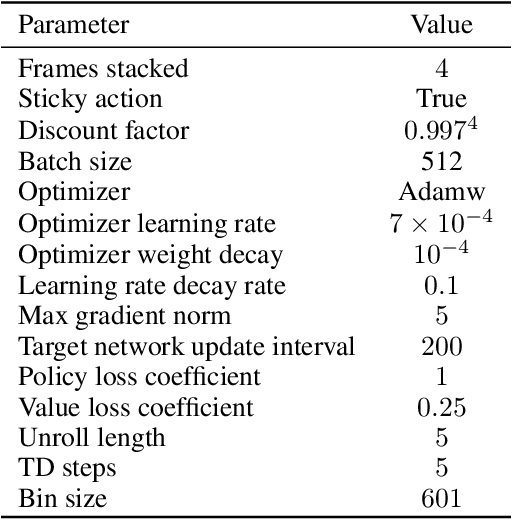
MuZero Unplugged presents a promising approach for offline policy learning from logged data. It conducts Monte-Carlo Tree Search (MCTS) with a learned model and leverages Reanalyze algorithm to learn purely from offline data. For good performance, MCTS requires accurate learned models and a large number of simulations, thus costing huge computing time. This paper investigates a few hypotheses where MuZero Unplugged may not work well under the offline RL settings, including 1) learning with limited data coverage; 2) learning from offline data of stochastic environments; 3) improperly parameterized models given the offline data; 4) with a low compute budget. We propose to use a regularized one-step look-ahead approach to tackle the above issues. Instead of planning with the expensive MCTS, we use the learned model to construct an advantage estimation based on a one-step rollout. Policy improvements are towards the direction that maximizes the estimated advantage with regularization of the dataset. We conduct extensive empirical studies with BSuite environments to verify the hypotheses and then run our algorithm on the RL Unplugged Atari benchmark. Experimental results show that our proposed approach achieves stable performance even with an inaccurate learned model. On the large-scale Atari benchmark, the proposed method outperforms MuZero Unplugged by 43%. Most significantly, it uses only 5.6% wall-clock time (i.e., 1 hour) compared to MuZero Unplugged (i.e., 17.8 hours) to achieve a 150% IQM normalized score with the same hardware and software stacks.
AdaptivePose++: A Powerful Single-Stage Network for Multi-Person Pose Regression
Oct 08, 2022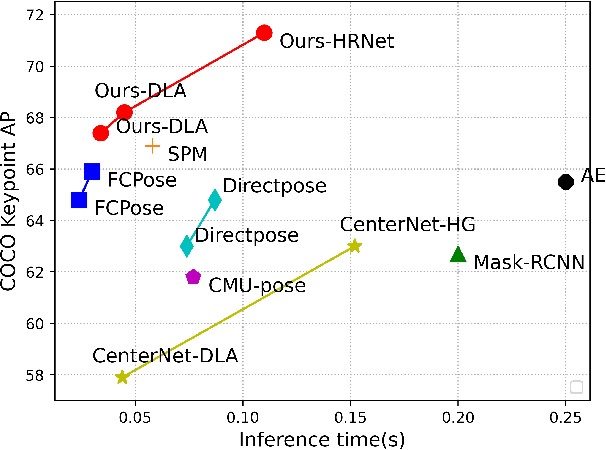

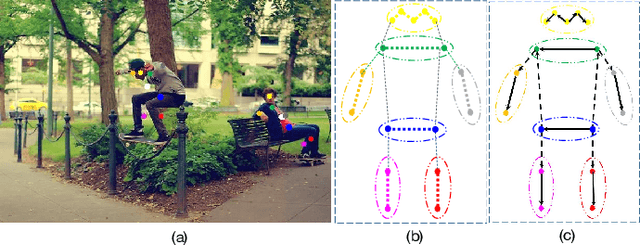
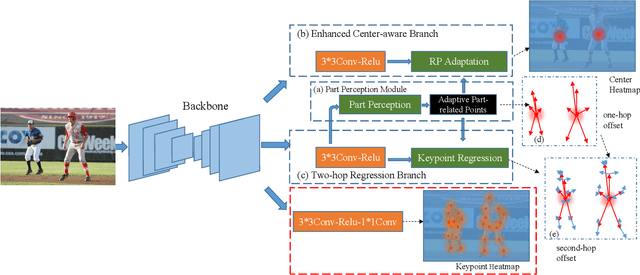
Multi-person pose estimation generally follows top-down and bottom-up paradigms. Both of them use an extra stage ($\boldsymbol{e.g.,}$ human detection in top-down paradigm or grouping process in bottom-up paradigm) to build the relationship between the human instance and corresponding keypoints, thus leading to the high computation cost and redundant two-stage pipeline. To address the above issue, we propose to represent the human parts as adaptive points and introduce a fine-grained body representation method. The novel body representation is able to sufficiently encode the diverse pose information and effectively model the relationship between the human instance and corresponding keypoints in a single-forward pass. With the proposed body representation, we further deliver a compact single-stage multi-person pose regression network, termed as AdaptivePose. During inference, our proposed network only needs a single-step decode operation to form the multi-person pose without complex post-processes and refinements. We employ AdaptivePose for both 2D/3D multi-person pose estimation tasks to verify the effectiveness of AdaptivePose. Without any bells and whistles, we achieve the most competitive performance on MS COCO and CrowdPose in terms of accuracy and speed. Furthermore, the outstanding performance on MuCo-3DHP and MuPoTS-3D further demonstrates the effectiveness and generalizability on 3D scenes. Code is available at https://github.com/buptxyb666/AdaptivePose.
Seeing Through The Noisy Dark: Toward Real-world Low-Light Image Enhancement and Denoising
Oct 07, 2022
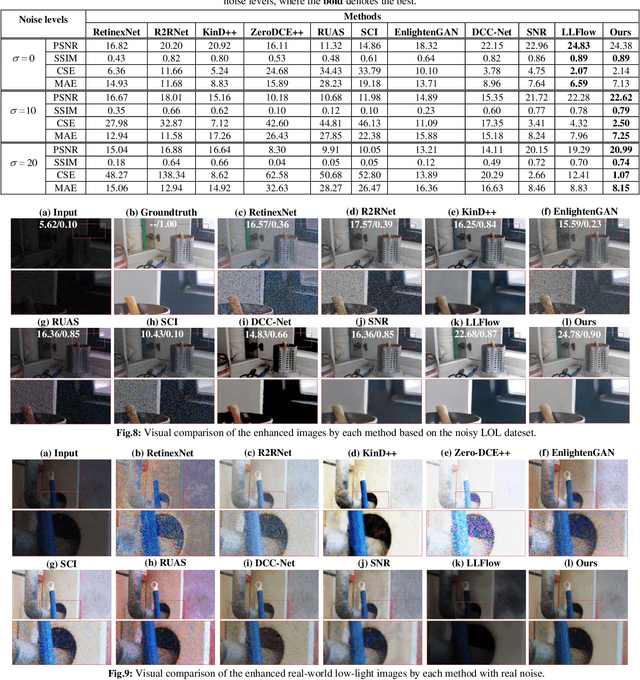
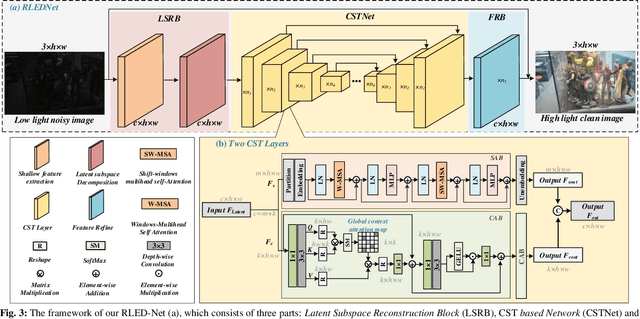
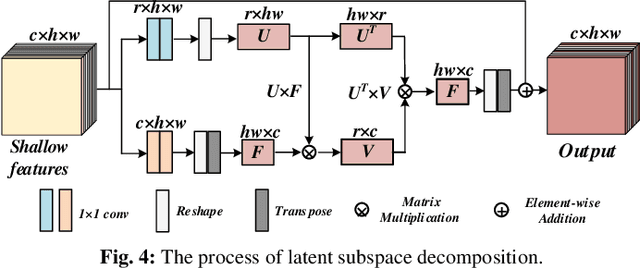
Images collected in real-world low-light environment usually suffer from lower visibility and heavier noise, due to the insufficient light or hardware limitation. While existing low-light image enhancement (LLIE) methods basically ignored the noise interference and mainly focus on refining the illumination of the low-light images based on benchmarked noise-negligible datasets. Such operations will make them inept for the real-world LLIE (RLLIE) with heavy noise, and result in speckle noise and blur in the enhanced images. Although several LLIE methods considered the noise in low-light image, they are trained on the raw data and hence cannot be used for sRGB images, since the domains of data are different and lack of expertise or unknown protocols. In this paper, we clearly consider the task of seeing through the noisy dark in sRGB color space, and propose a novel end-to-end method termed Real-world Low-light Enhancement & Denoising Network (RLED-Net). Since natural images can usually be characterized by low-rank subspaces in which the redundant information and noise can be removed, we design a Latent Subspace Reconstruction Block (LSRB) for feature extraction and denoising. To reduce the loss of global feature (e.g., color/shape information) and extract more accurate local features (e.g., edge/texture information), we also present a basic layer with two branches, called Cross-channel & Shift-window Transformer (CST). Based on the CST, we further present a new backbone to design a U-structure Network (CSTNet) for deep feature recovery, and also design a Feature Refine Block (FRB) to refine the final features. Extensive experiments on real noisy images and public databases verified the effectiveness of our RLED-Net for both RLLIE and denoising.
LPT: Long-tailed Prompt Tuning for Image Classification
Oct 03, 2022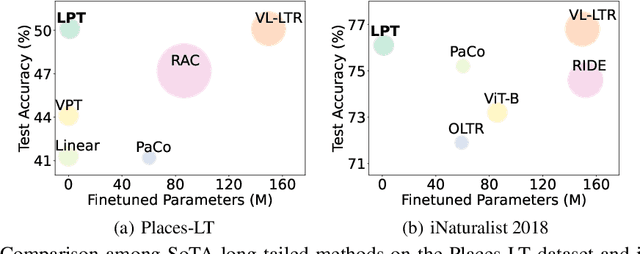
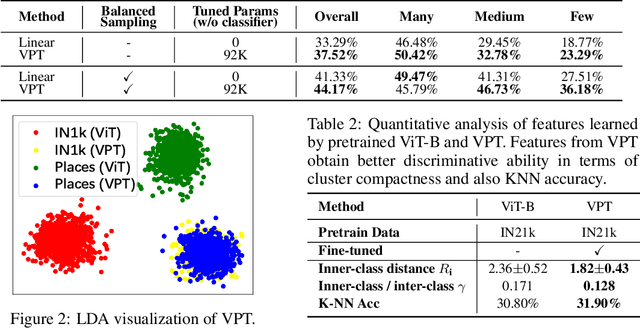
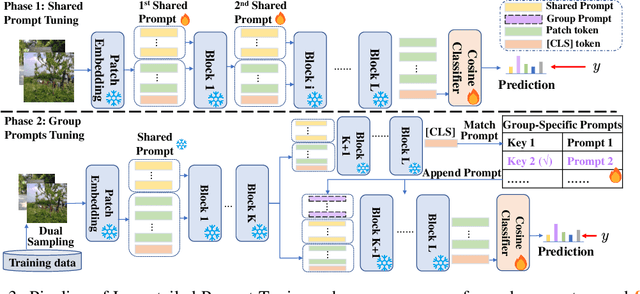
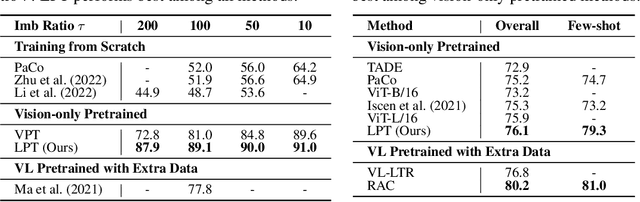
For long-tailed classification, most works often pretrain a big model on a large-scale dataset, and then fine-tune the whole model for adapting to long-tailed data. Though promising, fine-tuning the whole pretrained model tends to suffer from high cost in computation and deployment of different models for different tasks, as well as weakened generalization ability for overfitting to certain features of long-tailed data. To alleviate these issues, we propose an effective Long-tailed Prompt Tuning method for long-tailed classification. LPT introduces several trainable prompts into a frozen pretrained model to adapt it to long-tailed data. For better effectiveness, we divide prompts into two groups: 1) a shared prompt for the whole long-tailed dataset to learn general features and to adapt a pretrained model into target domain; and 2) group-specific prompts to gather group-specific features for the samples which have similar features and also to empower the pretrained model with discrimination ability. Then we design a two-phase training paradigm to learn these prompts. In phase 1, we train the shared prompt via supervised prompt tuning to adapt a pretrained model to the desired long-tailed domain. In phase 2, we use the learnt shared prompt as query to select a small best matched set for a group of similar samples from the group-specific prompt set to dig the common features of these similar samples, then optimize these prompts with dual sampling strategy and asymmetric GCL loss. By only fine-tuning a few prompts while fixing the pretrained model, LPT can reduce training and deployment cost by storing a few prompts, and enjoys a strong generalization ability of the pretrained model. Experiments show that on various long-tailed benchmarks, with only ~1.1% extra parameters, LPT achieves comparable performance than previous whole model fine-tuning methods, and is more robust to domain-shift.
Spikformer: When Spiking Neural Network Meets Transformer
Sep 29, 2022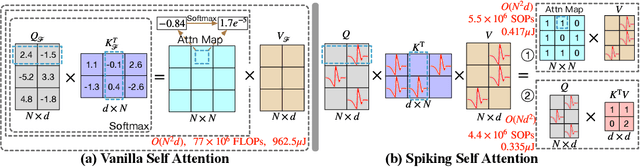
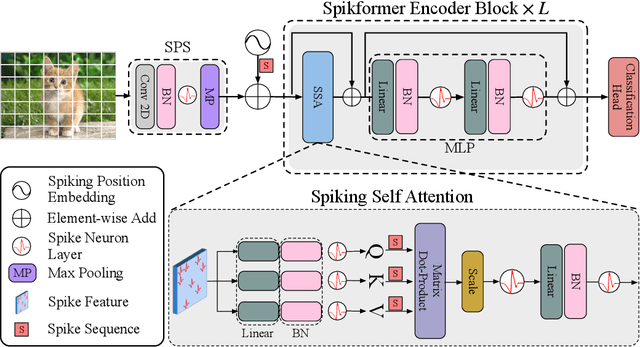
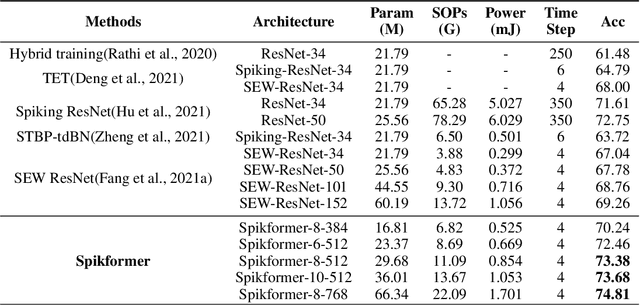
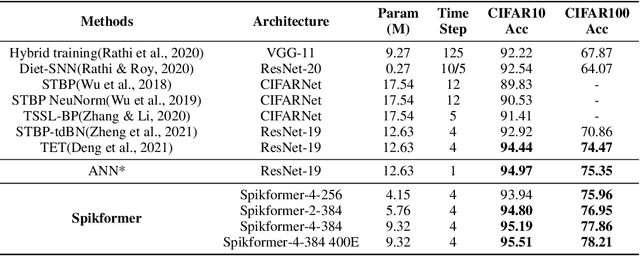
We consider two biologically plausible structures, the Spiking Neural Network (SNN) and the self-attention mechanism. The former offers an energy-efficient and event-driven paradigm for deep learning, while the latter has the ability to capture feature dependencies, enabling Transformer to achieve good performance. It is intuitively promising to explore the marriage between them. In this paper, we consider leveraging both self-attention capability and biological properties of SNNs, and propose a novel Spiking Self Attention (SSA) as well as a powerful framework, named Spiking Transformer (Spikformer). The SSA mechanism in Spikformer models the sparse visual feature by using spike-form Query, Key, and Value without softmax. Since its computation is sparse and avoids multiplication, SSA is efficient and has low computational energy consumption. It is shown that Spikformer with SSA can outperform the state-of-the-art SNNs-like frameworks in image classification on both neuromorphic and static datasets. Spikformer (66.3M parameters) with comparable size to SEW-ResNet-152 (60.2M,69.26%) can achieve 74.81% top1 accuracy on ImageNet using 4 time steps, which is the state-of-the-art in directly trained SNNs models.