 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Temporal-Spectral Fusion Transformer with Subject-specific Adapter for Enhancing RSVP-BCI Decoding
Jan 12, 2024The Rapid Serial Visual Presentation (RSVP)-based Brain-Computer Interface (BCI) is an efficient technology for target retrieval using electroencephalography (EEG) signals. The performance improvement of traditional decoding methods relies on a substantial amount of training data from new test subjects, which increases preparation time for BCI systems. Several studies introduce data from existing subjects to reduce the dependence of performance improvement on data from new subjects, but their optimization strategy based on adversarial learning with extensive data increases training time during the preparation procedure. Moreover, most previous methods only focus on the single-view information of EEG signals, but ignore the information from other views which may further improve performance. To enhance decoding performance while reducing preparation time, we propose a Temporal-Spectral fusion transformer with Subject-specific Adapter (TSformer-SA). Specifically, a cross-view interaction module is proposed to facilitate information transfer and extract common representations across two-view features extracted from EEG temporal signals and spectrogram images. Then, an attention-based fusion module fuses the features of two views to obtain comprehensive discriminative features for classification. Furthermore, a multi-view consistency loss is proposed to maximize the feature similarity between two views of the same EEG signal. Finally, we propose a subject-specific adapter to rapidly transfer the knowledge of the model trained on data from existing subjects to decode data from new subjects. Experimental results show that TSformer-SA significantly outperforms comparison methods and achieves outstanding performance with limited training data from new subjects. This facilitates efficient decoding and rapid deployment of BCI systems in practical use.
Posterior Sampling for Competitive RL: Function Approximation and Partial Observation
Oct 30, 2023This paper investigates posterior sampling algorithms for competitive reinforcement learning (RL) in the context of general function approximations. Focusing on zero-sum Markov games (MGs) under two critical settings, namely self-play and adversarial learning, we first propose the self-play and adversarial generalized eluder coefficient (GEC) as complexity measures for function approximation, capturing the exploration-exploitation trade-off in MGs. Based on self-play GEC, we propose a model-based self-play posterior sampling method to control both players to learn Nash equilibrium, which can successfully handle the partial observability of states. Furthermore, we identify a set of partially observable MG models fitting MG learning with the adversarial policies of the opponent. Incorporating the adversarial GEC, we propose a model-based posterior sampling method for learning adversarial MG with potential partial observability. We further provide low regret bounds for proposed algorithms that can scale sublinearly with the proposed GEC and the number of episodes $T$. To the best of our knowledge, we for the first time develop generic model-based posterior sampling algorithms for competitive RL that can be applied to a majority of tractable zero-sum MG classes in both fully observable and partially observable MGs with self-play and adversarial learning.
StairNetV3: Depth-aware Stair Modeling using Deep Learning
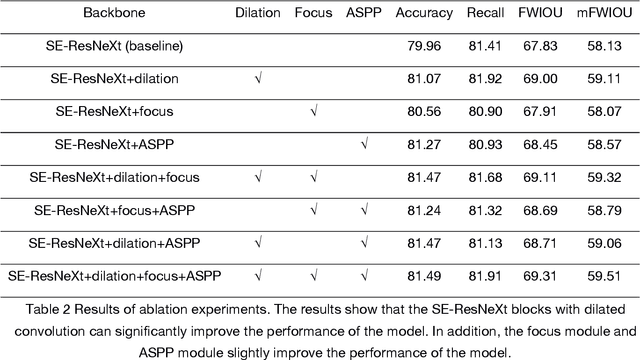
Aug 13, 2023Vision-based stair perception can help autonomous mobile robots deal with the challenge of climbing stairs, especially in unfamiliar environments. To address the problem that current monocular vision methods are difficult to model stairs accurately without depth information, this paper proposes a depth-aware stair modeling method for monocular vision. Specifically, we take the extraction of stair geometric features and the prediction of depth images as joint tasks in a convolutional neural network (CNN), with the designed information propagation architecture, we can achieve effective supervision for stair geometric feature learning by depth information. In addition, to complete the stair modeling, we take the convex lines, concave lines, tread surfaces and riser surfaces as stair geometric features and apply Gaussian kernels to enable the network to predict contextual information within the stair lines. Combined with the depth information obtained by depth sensors, we propose a stair point cloud reconstruction method that can quickly get point clouds belonging to the stair step surfaces. Experiments on our dataset show that our method has a significant improvement over the previous best monocular vision method, with an intersection over union (IOU) increase of 3.4 %, and the lightweight version has a fast detection speed and can meet the requirements of most real-time applications. Our dataset is available at https://data.mendeley.com/datasets/6kffmjt7g2/1.
On the Value of Myopic Behavior in Policy Reuse
May 28, 2023



Leveraging learned strategies in unfamiliar scenarios is fundamental to human intelligence. In reinforcement learning, rationally reusing the policies acquired from other tasks or human experts is critical for tackling problems that are difficult to learn from scratch. In this work, we present a framework called Selective Myopic bEhavior Control~(SMEC), which results from the insight that the short-term behaviors of prior policies are sharable across tasks. By evaluating the behaviors of prior policies via a hybrid value function architecture, SMEC adaptively aggregates the sharable short-term behaviors of prior policies and the long-term behaviors of the task policy, leading to coordinated decisions. Empirical results on a collection of manipulation and locomotion tasks demonstrate that SMEC outperforms existing methods, and validate the ability of SMEC to leverage related prior policies.
RGB-D-based Stair Detection using Deep Learning for Autonomous Stair Climbing
Dec 09, 2022Stairs are common building structures in urban environments, and stair detection is an important part of environment perception for autonomous mobile robots. Most existing algorithms have difficulty combining the visual information from binocular sensors effectively and ensuring reliable detection at night and in the case of extremely fuzzy visual clues. To solve these problems, we propose a neural network architecture with RGB and depth map inputs. Specifically, we design a selective module, which can make the network learn the complementary relationship between the RGB map and the depth map and effectively combine the information from the RGB map and the depth map in different scenes. In addition, we design a line clustering algorithm for the postprocessing of detection results, which can make full use of the detection results to obtain the geometric stair parameters. Experiments on our dataset show that our method can achieve better accuracy and recall compared with existing state-of-the-art deep learning methods, which are 5.64% and 7.97%, respectively, and our method also has extremely fast detection speed. A lightweight version can achieve 300 + frames per second with the same resolution, which can meet the needs of most real-time detection scenes.
Contrastive UCB: Provably Efficient Contrastive Self-Supervised Learning in Online Reinforcement Learning
Jul 29, 2022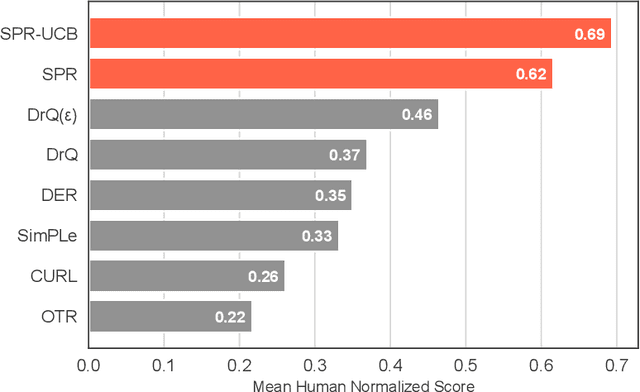

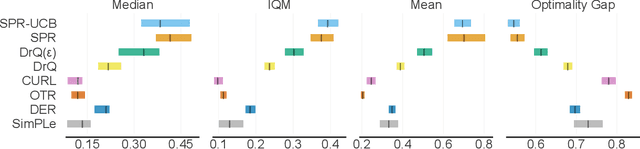
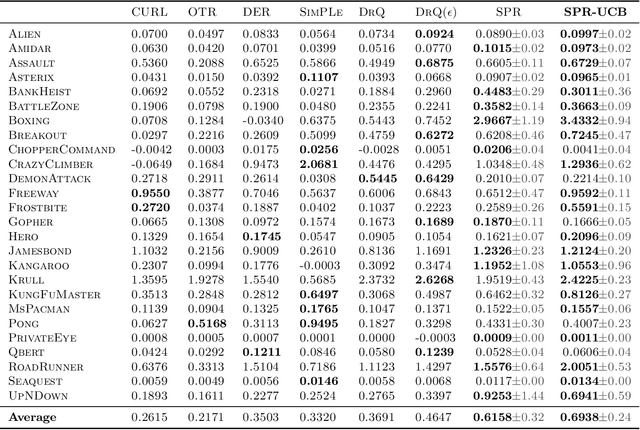
In view of its power in extracting feature representation, contrastive self-supervised learning has been successfully integrated into the practice of (deep) reinforcement learning (RL), leading to efficient policy learning in various applications. Despite its tremendous empirical successes, the understanding of contrastive learning for RL remains elusive. To narrow such a gap, we study how RL can be empowered by contrastive learning in a class of Markov decision processes (MDPs) and Markov games (MGs) with low-rank transitions. For both models, we propose to extract the correct feature representations of the low-rank model by minimizing a contrastive loss. Moreover, under the online setting, we propose novel upper confidence bound (UCB)-type algorithms that incorporate such a contrastive loss with online RL algorithms for MDPs or MGs. We further theoretically prove that our algorithm recovers the true representations and simultaneously achieves sample efficiency in learning the optimal policy and Nash equilibrium in MDPs and MGs. We also provide empirical studies to demonstrate the efficacy of the UCB-based contrastive learning method for RL. To the best of our knowledge, we provide the first provably efficient online RL algorithm that incorporates contrastive learning for representation learning. Our codes are available at https://github.com/Baichenjia/Contrastive-UCB.
Provably Efficient Fictitious Play Policy Optimization for Zero-Sum Markov Games with Structured Transitions
Jul 25, 2022
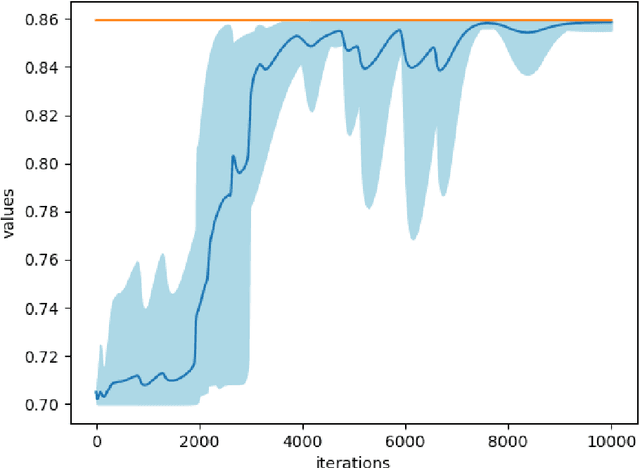
While single-agent policy optimization in a fixed environment has attracted a lot of research attention recently in the reinforcement learning community, much less is known theoretically when there are multiple agents playing in a potentially competitive environment. We take steps forward by proposing and analyzing new fictitious play policy optimization algorithms for zero-sum Markov games with structured but unknown transitions. We consider two classes of transition structures: factored independent transition and single-controller transition. For both scenarios, we prove tight $\widetilde{\mathcal{O}}(\sqrt{K})$ regret bounds after $K$ episodes in a two-agent competitive game scenario. The regret of each agent is measured against a potentially adversarial opponent who can choose a single best policy in hindsight after observing the full policy sequence. Our algorithms feature a combination of Upper Confidence Bound (UCB)-type optimism and fictitious play under the scope of simultaneous policy optimization in a non-stationary environment. When both players adopt the proposed algorithms, their overall optimality gap is $\widetilde{\mathcal{O}}(\sqrt{K})$.
Stochastic Gradient Descent without Full Data Shuffle
Jun 12, 2022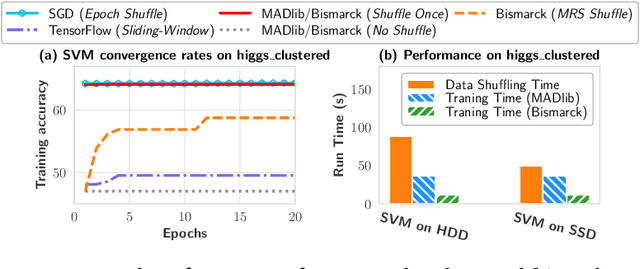

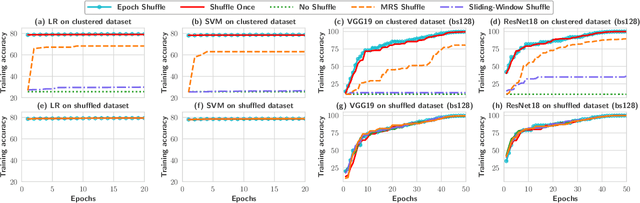
Stochastic gradient descent (SGD) is the cornerstone of modern machine learning (ML) systems. Despite its computational efficiency, SGD requires random data access that is inherently inefficient when implemented in systems that rely on block-addressable secondary storage such as HDD and SSD, e.g., TensorFlow/PyTorch and in-DB ML systems over large files. To address this impedance mismatch, various data shuffling strategies have been proposed to balance the convergence rate of SGD (which favors randomness) and its I/O performance (which favors sequential access). In this paper, we first conduct a systematic empirical study on existing data shuffling strategies, which reveals that all existing strategies have room for improvement -- they all suffer in terms of I/O performance or convergence rate. With this in mind, we propose a simple but novel hierarchical data shuffling strategy, CorgiPile. Compared with existing strategies, CorgiPile avoids a full data shuffle while maintaining comparable convergence rate of SGD as if a full shuffle were performed. We provide a non-trivial theoretical analysis of CorgiPile on its convergence behavior. We further integrate CorgiPile into PyTorch by designing new parallel/distributed shuffle operators inside a new CorgiPileDataSet API. We also integrate CorgiPile into PostgreSQL by introducing three new physical operators with optimizations. Our experimental results show that CorgiPile can achieve comparable convergence rate with the full shuffle based SGD for both deep learning and generalized linear models. For deep learning models on ImageNet dataset, CorgiPile is 1.5X faster than PyTorch with full data shuffle. For in-DB ML with linear models, CorgiPile is 1.6X-12.8X faster than two state-of-the-art in-DB ML systems, Apache MADlib and Bismarck, on both HDD and SSD.
Learning Dynamic Mechanisms in Unknown Environments: A Reinforcement Learning Approach
Feb 25, 2022
Dynamic mechanism design studies how mechanism designers should allocate resources among agents in a time-varying environment. We consider the problem where the agents interact with the mechanism designer according to an unknown Markov Decision Process (MDP), where agent rewards and the mechanism designer's state evolve according to an episodic MDP with unknown reward functions and transition kernels. We focus on the online setting with linear function approximation and attempt to recover the dynamic Vickrey-Clarke-Grove (VCG) mechanism over multiple rounds of interaction. A key contribution of our work is incorporating reward-free online Reinforcement Learning (RL) to aid exploration over a rich policy space to estimate prices in the dynamic VCG mechanism. We show that the regret of our proposed method is upper bounded by $\tilde{\mathcal{O}}(T^{2/3})$ and further devise a lower bound to show that our algorithm is efficient, incurring the same $\tilde{\mathcal{O}}(T^{2 / 3})$ regret as the lower bound, where $T$ is the total number of rounds. Our work establishes the regret guarantee for online RL in solving dynamic mechanism design problems without prior knowledge of the underlying model.
Deep Leaning-Based Ultra-Fast Stair Detection
Feb 04, 2022

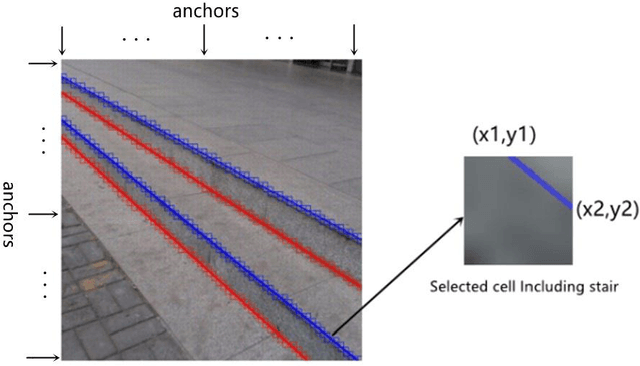
Staircases are some of the most common building structures in urban environments. Stair detection is an important task for various applications, including the environmental perception of exoskeleton robots, humanoid robots, and rescue robots and the navigation of visually impaired people. Most existing stair detection algorithms have difficulty dealing with the diversity of stair structure materials, extreme light and serious occlusion. Inspired by human perception, we propose an end-to-end method based on deep learning. Specifically, we treat the process of stair line detection as a multitask involving coarse-grained semantic segmentation and object detection. The input images are divided into cells, and a simple neural network is used to judge whether each cell contains stair lines. For cells containing stair lines, the locations of the stair lines relative to each cell are regressed. Extensive experiments on our dataset show that our method can achieve high performance in terms of both speed and accuracy. A lightweight version can even achieve 300+ frames per second with the same resolution. Our code and dataset will be soon available at GitHub.