 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlug In, Grade Right: Psychology-Inspired AGIQA
Dec 28, 2025Existing AGIQA models typically estimate image quality by measuring and aggregating the similarities between image embeddings and text embeddings derived from multi-grade quality descriptions. Although effective, we observe that such similarity distributions across grades usually exhibit multimodal patterns. For instance, an image embedding may show high similarity to both "excellent" and "poor" grade descriptions while deviating from the "good" one. We refer to this phenomenon as "semantic drift", where semantic inconsistencies between text embeddings and their intended descriptions undermine the reliability of text-image shared-space learning. To mitigate this issue, we draw inspiration from psychometrics and propose an improved Graded Response Model (GRM) for AGIQA. The GRM is a classical assessment model that categorizes a subject's ability across grades using test items with various difficulty levels. This paradigm aligns remarkably well with human quality rating, where image quality can be interpreted as an image's ability to meet various quality grades. Building on this philosophy, we design a two-branch quality grading module: one branch estimates image ability while the other constructs multiple difficulty levels. To ensure monotonicity in difficulty levels, we further model difficulty generation in an arithmetic manner, which inherently enforces a unimodal and interpretable quality distribution. Our Arithmetic GRM based Quality Grading (AGQG) module enjoys a plug-and-play advantage, consistently improving performance when integrated into various state-of-the-art AGIQA frameworks. Moreover, it also generalizes effectively to both natural and screen content image quality assessment, revealing its potential as a key component in future IQA models.
A Hierarchical, Model-Based System for High-Performance Humanoid Soccer
Dec 10, 2025



The development of athletic humanoid robots has gained significant attention as advances in actuation, sensing, and control enable increasingly dynamic, real-world capabilities. RoboCup, an international competition of fully autonomous humanoid robots, provides a uniquely challenging benchmark for such systems, culminating in the long-term goal of competing against human soccer players by 2050. This paper presents the hardware and software innovations underlying our team's victory in the RoboCup 2024 Adult-Sized Humanoid Soccer Competition. On the hardware side, we introduce an adult-sized humanoid platform built with lightweight structural components, high-torque quasi-direct-drive actuators, and a specialized foot design that enables powerful in-gait kicks while preserving locomotion robustness. On the software side, we develop an integrated perception and localization framework that combines stereo vision, object detection, and landmark-based fusion to provide reliable estimates of the ball, goals, teammates, and opponents. A mid-level navigation stack then generates collision-aware, dynamically feasible trajectories, while a centralized behavior manager coordinates high-level decision making, role selection, and kick execution based on the evolving game state. The seamless integration of these subsystems results in fast, precise, and tactically effective gameplay, enabling robust performance under the dynamic and adversarial conditions of real matches. This paper presents the design principles, system architecture, and experimental results that contributed to ARTEMIS's success as the 2024 Adult-Sized Humanoid Soccer champion.
MIMIC-SR-ICD11: A Dataset for Narrative-Based Diagnosis
Nov 07, 2025



Disease diagnosis is a central pillar of modern healthcare, enabling early detection and timely intervention for acute conditions while guiding lifestyle adjustments and medication regimens to prevent or slow chronic disease. Self-reports preserve clinically salient signals that templated electronic health record (EHR) documentation often attenuates or omits, especially subtle but consequential details. To operationalize this shift, we introduce MIMIC-SR-ICD11, a large English diagnostic dataset built from EHR discharge notes and natively aligned to WHO ICD-11 terminology. We further present LL-Rank, a likelihood-based re-ranking framework that computes a length-normalized joint likelihood of each label given the clinical report context and subtracts the corresponding report-free prior likelihood for that label. Across seven model backbones, LL-Rank consistently outperforms a strong generation-plus-mapping baseline (GenMap). Ablation experiments show that LL-Rank's gains primarily stem from its PMI-based scoring, which isolates semantic compatibility from label frequency bias.
A Universal Banach--Bregman Framework for Stochastic Iterations: Unifying Stochastic Mirror Descent, Learning and LLM Training
Sep 17, 2025Stochastic optimization powers the scalability of modern artificial intelligence, spanning machine learning, deep learning, reinforcement learning, and large language model training. Yet, existing theory remains largely confined to Hilbert spaces, relying on inner-product frameworks and orthogonality. This paradigm fails to capture non-Euclidean settings, such as mirror descent on simplices, Bregman proximal methods for sparse learning, natural gradient descent in information geometry, or Kullback--Leibler-regularized language model training. Unlike Euclidean-based Hilbert-space methods, this approach embraces general Banach spaces. This work introduces a pioneering Banach--Bregman framework for stochastic iterations, establishing Bregman geometry as a foundation for next-generation optimization. It (i) provides a unified template via Bregman projections and Bregman--Fejer monotonicity, encompassing stochastic approximation, mirror descent, natural gradient, adaptive methods, and mirror-prox; (ii) establishes super-relaxations ($\lambda > 2$) in non-Hilbert settings, enabling flexible geometries and elucidating their acceleration effect; and (iii) delivers convergence theorems spanning almost-sure boundedness to geometric rates, validated on synthetic and real-world tasks. Empirical studies across machine learning (UCI benchmarks), deep learning (e.g., Transformer training), reinforcement learning (actor--critic), and large language models (WikiText-2 with distilGPT-2) show up to 20% faster convergence, reduced variance, and enhanced accuracy over classical baselines. These results position Banach--Bregman geometry as a cornerstone unifying optimization theory and practice across core AI paradigms.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
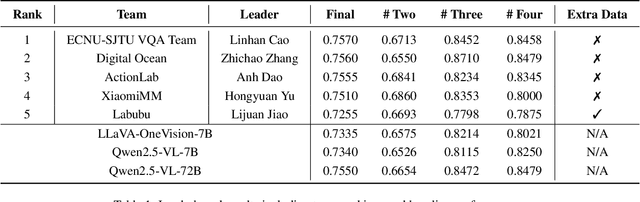
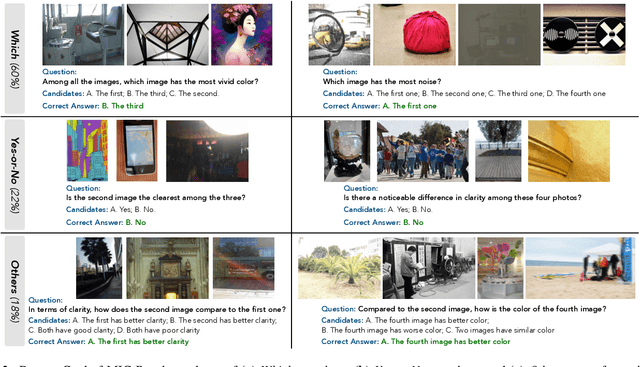
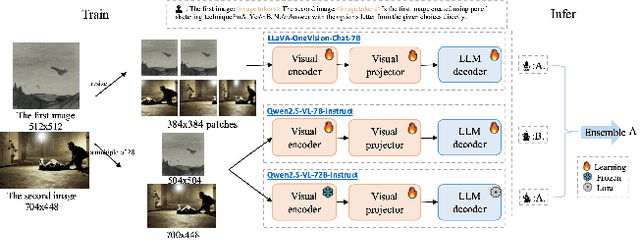
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
LMVC: An End-to-End Learned Multiview Video Coding Framework
Sep 04, 2025Multiview video is a key data source for volumetric video, enabling immersive 3D scene reconstruction but posing significant challenges in storage and transmission due to its massive data volume. Recently, deep learning-based end-to-end video coding has achieved great success, yet most focus on single-view or stereo videos, leaving general multiview scenarios underexplored. This paper proposes an end-to-end learned multiview video coding (LMVC) framework that ensures random access and backward compatibility while enhancing compression efficiency. Our key innovation lies in effectively leveraging independent-view motion and content information to enhance dependent-view compression. Specifically, to exploit the inter-view motion correlation, we propose a feature-based inter-view motion vector prediction method that conditions dependent-view motion encoding on decoded independent-view motion features, along with an inter-view motion entropy model that learns inter-view motion priors. To exploit the inter-view content correlation, we propose a disparity-free inter-view context prediction module that predicts inter-view contexts from decoded independent-view content features, combined with an inter-view contextual entropy model that captures inter-view context priors. Experimental results show that our proposed LMVC framework outperforms the reference software of the traditional MV-HEVC standard by a large margin, establishing a strong baseline for future research in this field.
Copyright Protection for 3D Molecular Structures with Watermarking
Aug 25, 2025



Artificial intelligence (AI) revolutionizes molecule generation in bioengineering and biological research, significantly accelerating discovery processes. However, this advancement introduces critical concerns regarding intellectual property protection. To address these challenges, we propose the first robust watermarking method designed for molecules, which utilizes atom-level features to preserve molecular integrity and invariant features to ensure robustness against affine transformations. Comprehensive experiments validate the effectiveness of our method using the datasets QM9 and GEOM-DRUG, and generative models GeoBFN and GeoLDM. We demonstrate the feasibility of embedding watermarks, maintaining basic properties higher than 90.00\% while achieving watermark accuracy greater than 95.00\%. Furthermore, downstream docking simulations reveal comparable performance between original and watermarked molecules, with binding affinities reaching -6.00 kcal/mol and root mean square deviations below 1.602 \AA. These results confirm that our watermarking technique effectively safeguards molecular intellectual property without compromising scientific utility, enabling secure and responsible AI integration in molecular discovery and research applications.
Capturing Stable HDR Videos Using a Dual-Camera System
Jul 09, 2025In HDR video reconstruction, exposure fluctuations in reference images from alternating exposure methods often result in flickering. To address this issue, we propose a dual-camera system (DCS) for HDR video acquisition, where one camera is assigned to capture consistent reference sequences, while the other is assigned to capture non-reference sequences for information supplementation. To tackle the challenges posed by video data, we introduce an exposure-adaptive fusion network (EAFNet) to achieve more robust results. EAFNet introduced a pre-alignment subnetwork to explore the influence of exposure, selectively emphasizing the valuable features across different exposure levels. Then, the enhanced features are fused by the asymmetric cross-feature fusion subnetwork, which explores reference-dominated attention maps to improve image fusion by aligning cross-scale features and performing cross-feature fusion. Finally, the reconstruction subnetwork adopts a DWT-based multiscale architecture to reduce ghosting artifacts and refine features at different resolutions. Extensive experimental evaluations demonstrate that the proposed method achieves state-of-the-art performance on different datasets, validating the great potential of the DCS in HDR video reconstruction. The codes and data captured by DCS will be available at https://github.com/zqqqyu/DCS.
KEPLA: A Knowledge-Enhanced Deep Learning Framework for Accurate Protein-Ligand Binding Affinity Prediction
Jun 16, 2025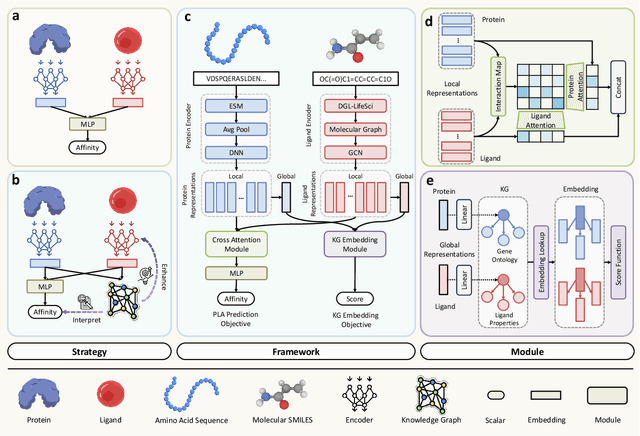
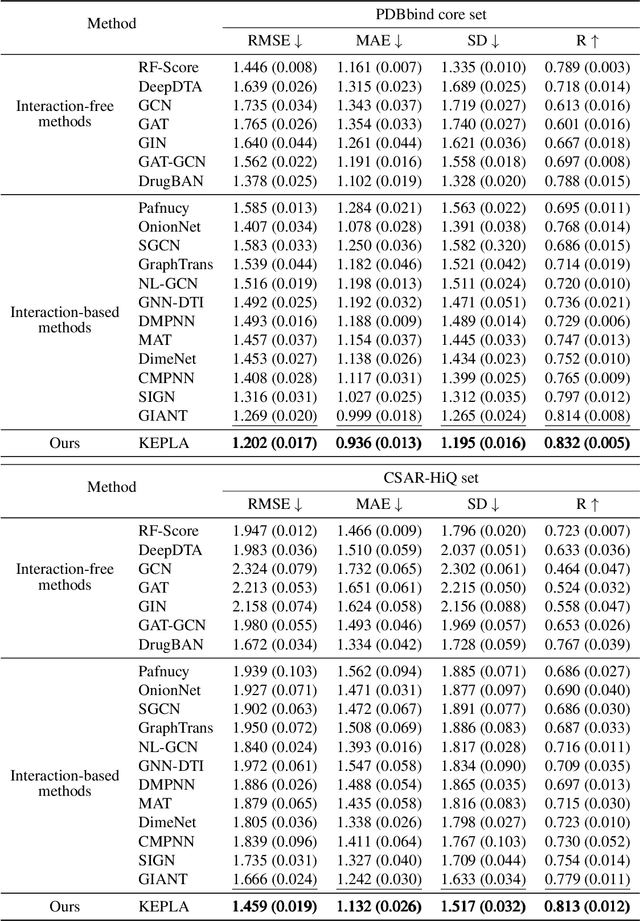
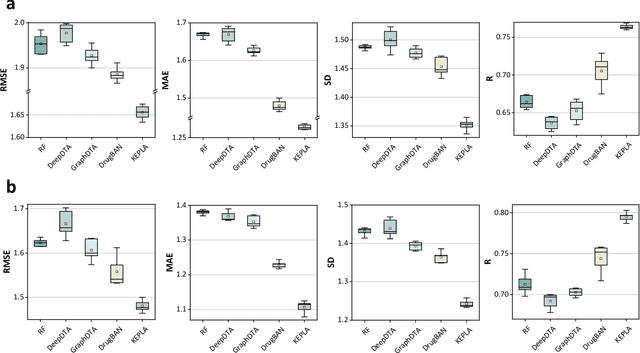
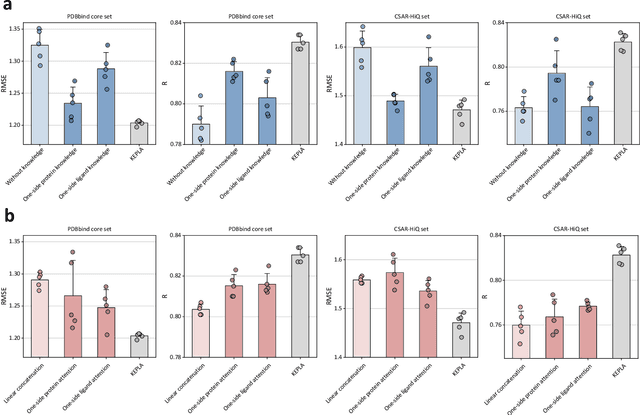
Accurate prediction of protein-ligand binding affinity is critical for drug discovery. While recent deep learning approaches have demonstrated promising results, they often rely solely on structural features, overlooking valuable biochemical knowledge associated with binding affinity. To address this limitation, we propose KEPLA, a novel deep learning framework that explicitly integrates prior knowledge from Gene Ontology and ligand properties of proteins and ligands to enhance prediction performance. KEPLA takes protein sequences and ligand molecular graphs as input and optimizes two complementary objectives: (1) aligning global representations with knowledge graph relations to capture domain-specific biochemical insights, and (2) leveraging cross attention between local representations to construct fine-grained joint embeddings for prediction. Experiments on two benchmark datasets across both in-domain and cross-domain scenarios demonstrate that KEPLA consistently outperforms state-of-the-art baselines. Furthermore, interpretability analyses based on knowledge graph relations and cross attention maps provide valuable insights into the underlying predictive mechanisms.
Structural Similarity-Inspired Unfolding for Lightweight Image Super-Resolution
Jun 13, 2025Major efforts in data-driven image super-resolution (SR) primarily focus on expanding the receptive field of the model to better capture contextual information. However, these methods are typically implemented by stacking deeper networks or leveraging transformer-based attention mechanisms, which consequently increases model complexity. In contrast, model-driven methods based on the unfolding paradigm show promise in improving performance while effectively maintaining model compactness through sophisticated module design. Based on these insights, we propose a Structural Similarity-Inspired Unfolding (SSIU) method for efficient image SR. This method is designed through unfolding an SR optimization function constrained by structural similarity, aiming to combine the strengths of both data-driven and model-driven approaches. Our model operates progressively following the unfolding paradigm. Each iteration consists of multiple Mixed-Scale Gating Modules (MSGM) and an Efficient Sparse Attention Module (ESAM). The former implements comprehensive constraints on features, including a structural similarity constraint, while the latter aims to achieve sparse activation. In addition, we design a Mixture-of-Experts-based Feature Selector (MoE-FS) that fully utilizes multi-level feature information by combining features from different steps. Extensive experiments validate the efficacy and efficiency of our unfolding-inspired network. Our model outperforms current state-of-the-art models, boasting lower parameter counts and reduced memory consumption. Our code will be available at: https://github.com/eezkni/SSIU