 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Seeded Sequence Growing for Weakly-Supervised Temporal Action Localization
Aug 07, 2019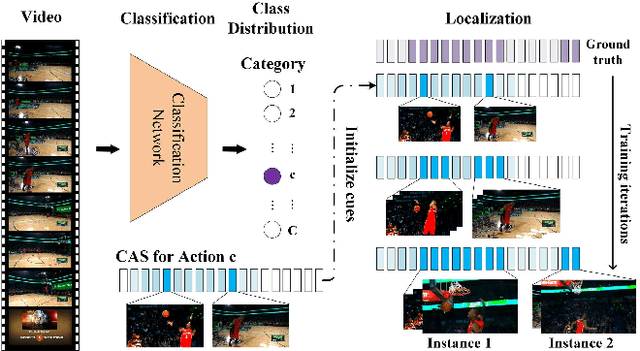
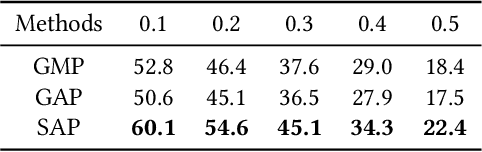
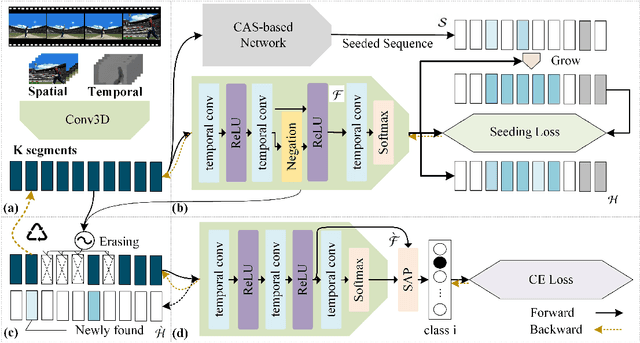
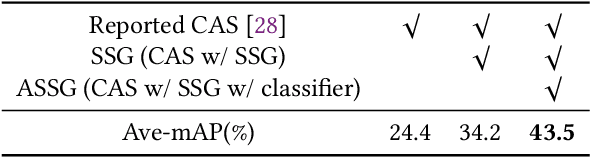
Temporal action localization is an important yet challenging research topic due to its various applications. Since the frame-level or segment-level annotations of untrimmed videos require amounts of labor expenditure, studies on the weakly-supervised action detection have been springing up. However, most of existing frameworks rely on Class Activation Sequence (CAS) to localize actions by minimizing the video-level classification loss, which exploits the most discriminative parts of actions but ignores the minor regions. In this paper, we propose a novel weakly-supervised framework by adversarial learning of two modules for eliminating such demerits. Specifically, the first module is designed as a well-designed Seeded Sequence Growing (SSG) Network for progressively extending seed regions (namely the highly reliable regions initialized by a CAS-based framework) to their expected boundaries. The second module is a specific classifier for mining trivial or incomplete action regions, which is trained on the shared features after erasing the seeded regions activated by SSG. In this way, a whole network composed of these two modules can be trained in an adversarial manner. The goal of the adversary is to mine features that are difficult for the action classifier. That is, erasion from SSG will force the classifier to discover minor or even new action regions on the input feature sequence, and the classifier will drive the seeds to grow, alternately. At last, we could obtain the action locations and categories from the well-trained SSG and the classifier. Extensive experiments on two public benchmarks THUMOS'14 and ActivityNet1.3 demonstrate the impressive performance of our proposed method compared with the state-of-the-arts.
Learned Quality Enhancement via Multi-Frame Priors for HEVC Compliant Low-Delay Applications
May 03, 2019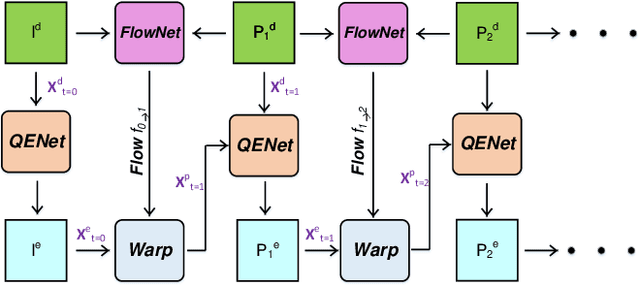

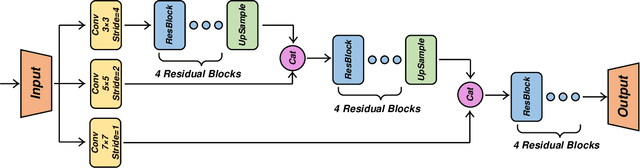

Networked video applications, e.g., video conferencing, often suffer from poor visual quality due to unexpected network fluctuation and limited bandwidth. In this paper, we have developed a Quality Enhancement Network (QENet) to reduce the video compression artifacts, leveraging the spatial and temporal priors generated by respective multi-scale convolutions spatially and warped temporal predictions in a recurrent fashion temporally. We have integrated this QENet as a standard-alone post-processing subsystem to the High Efficiency Video Coding (HEVC) compliant decoder. Experimental results show that our QENet demonstrates the state-of-the-art performance against default in-loop filters in HEVC and other deep learning based methods with noticeable objective gains in Peak-Signal-to-Noise Ratio (PSNR) and subjective gains visually.
Posterior-regularized REINFORCE for Instance Selection in Distant Supervision
Apr 17, 2019
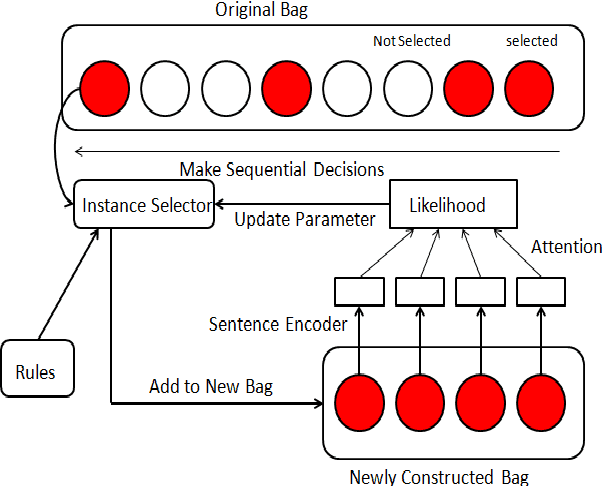
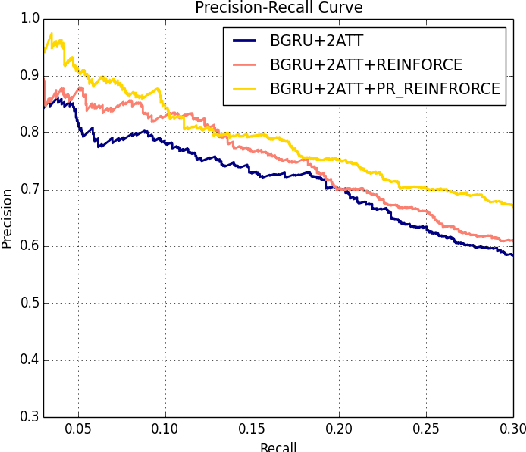
This paper provides a new way to improve the efficiency of the REINFORCE training process. We apply it to the task of instance selection in distant supervision. Modeling the instance selection in one bag as a sequential decision process, a reinforcement learning agent is trained to determine whether an instance is valuable or not and construct a new bag with less noisy instances. However unbiased methods, such as REINFORCE, could usually take much time to train. This paper adopts posterior regularization (PR) to integrate some domain-specific rules in instance selection using REINFORCE. As the experiment results show, this method remarkably improves the performance of the relation classifier trained on cleaned distant supervision dataset as well as the efficiency of the REINFORCE training.
* Five pages
Extreme Image Compression via Multiscale Autoencoders With Generative Adversarial Optimization
Apr 08, 2019
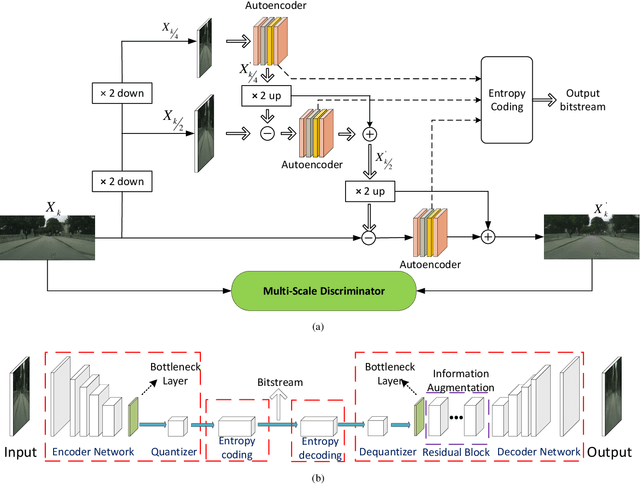

We propose a MultiScale AutoEncoder(MSAE) based extreme image compression framework to offer visually pleasing reconstruction at a very low bitrate. Our method leverages the "priors" at different resolution scale to improve the compression efficiency, and also employs the generative adversarial network(GAN) with multiscale discriminators to perform the end-to-end trainable rate-distortion optimization. We compare the perceptual quality of our reconstructions with traditional compression algorithms using High-Efficiency Video Coding(HEVC) based Intra Profile and JPEG2000 on the public Cityscapes and ADE20K datasets, demonstrating the significant subjective quality improvement.
All You Need is a Few Shifts: Designing Efficient Convolutional Neural Networks for Image Classification
Mar 13, 2019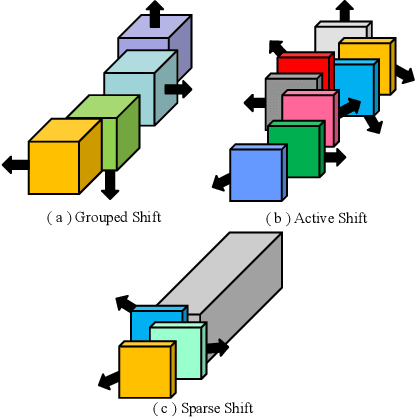
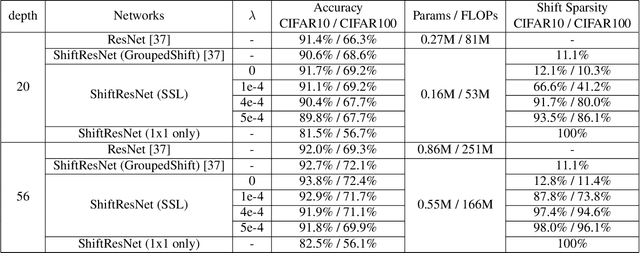

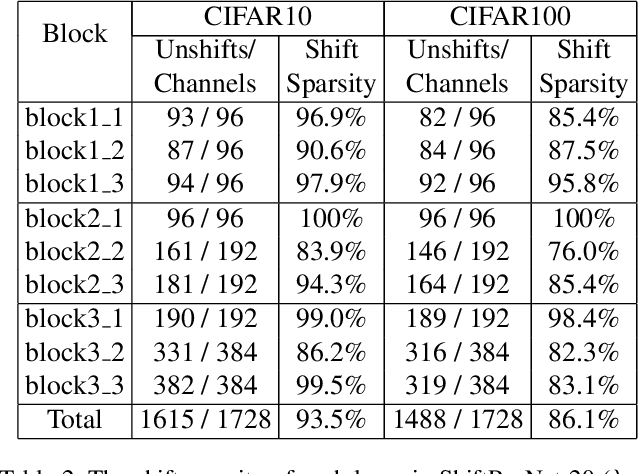
Shift operation is an efficient alternative over depthwise separable convolution. However, it is still bottlenecked by its implementation manner, namely memory movement. To put this direction forward, a new and novel basic component named Sparse Shift Layer (SSL) is introduced in this paper to construct efficient convolutional neural networks. In this family of architectures, the basic block is only composed by 1x1 convolutional layers with only a few shift operations applied to the intermediate feature maps. To make this idea feasible, we introduce shift operation penalty during optimization and further propose a quantization-aware shift learning method to impose the learned displacement more friendly for inference. Extensive ablation studies indicate that only a few shift operations are sufficient to provide spatial information communication. Furthermore, to maximize the role of SSL, we redesign an improved network architecture to Fully Exploit the limited capacity of neural Network (FE-Net). Equipped with SSL, this network can achieve 75.0% top-1 accuracy on ImageNet with only 563M M-Adds. It surpasses other counterparts constructed by depthwise separable convolution and the networks searched by NAS in terms of accuracy and practical speed.
Efficient Video Scene Text Spotting: Unifying Detection, Tracking, and Recognition
Mar 08, 2019


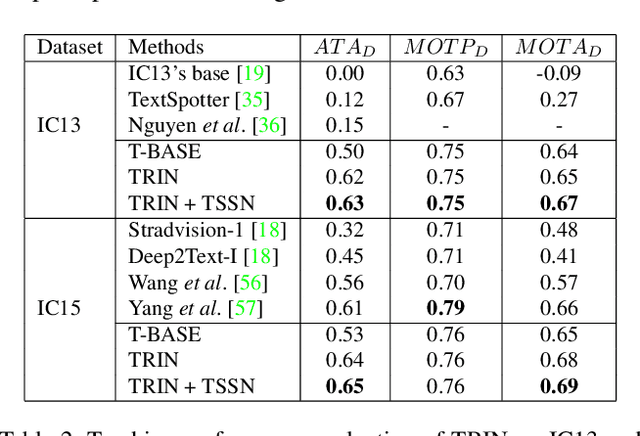
This paper proposes an unified framework for efficiently spotting scene text in videos. The method localizes and tracks text in each frame, and recognizes each tracked text stream one-time. Specifically, we first train a spatial-temporal text detector for localizing text regions in the sequential frames. Secondly, a well-designed text tracker is trained for grouping the localized text regions into corresponding cropped text streams. To efficiently spot video text, we recognize each tracked text stream one-time with a text region quality scoring mechanism instead of identifying the cropped text regions one-by-one. Experiments on two public benchmarks demonstrate that our method achieves impressive performance.
Collaborative Spatio-temporal Feature Learning for Video Action Recognition
Mar 04, 2019
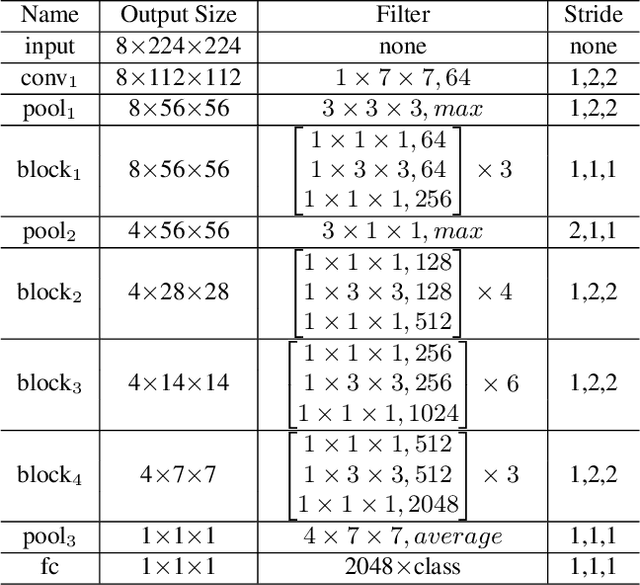
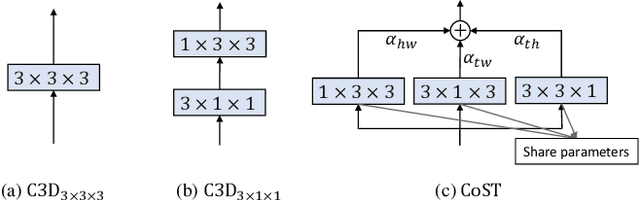
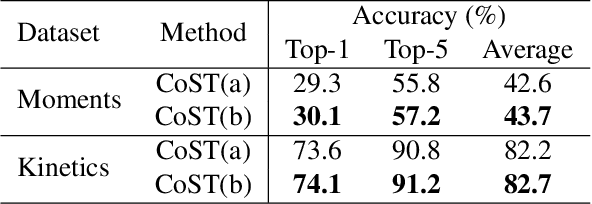
Spatio-temporal feature learning is of central importance for action recognition in videos. Existing deep neural network models either learn spatial and temporal features independently (C2D) or jointly with unconstrained parameters (C3D). In this paper, we propose a novel neural operation which encodes spatio-temporal features collaboratively by imposing a weight-sharing constraint on the learnable parameters. In particular, we perform 2D convolution along three orthogonal views of volumetric video data,which learns spatial appearance and temporal motion cues respectively. By sharing the convolution kernels of different views, spatial and temporal features are collaboratively learned and thus benefit from each other. The complementary features are subsequently fused by a weighted summation whose coefficients are learned end-to-end. Our approach achieves state-of-the-art performance on large-scale benchmarks and won the 1st place in the Moments in Time Challenge 2018. Moreover, based on the learned coefficients of different views, we are able to quantify the contributions of spatial and temporal features. This analysis sheds light on interpretability of the model and may also guide the future design of algorithm for video recognition.
Cross-relation Cross-bag Attention for Distantly-supervised Relation Extraction
Dec 27, 2018
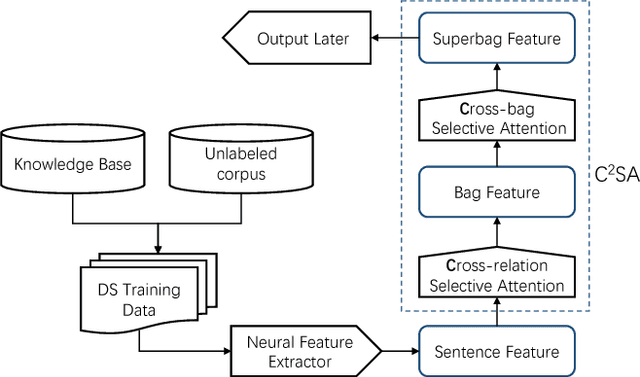
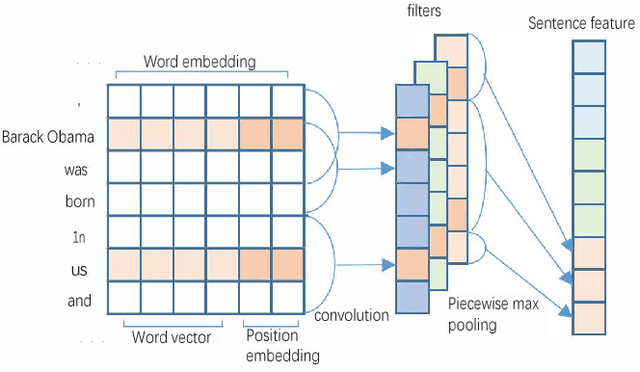
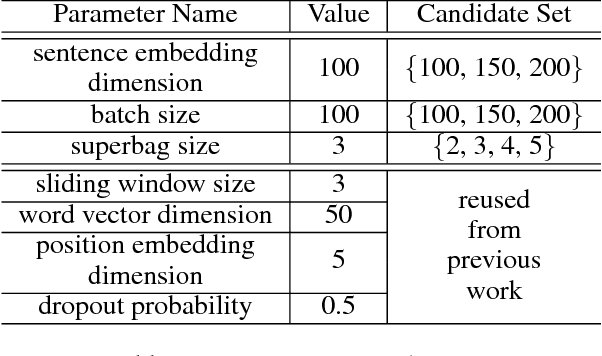
Distant supervision leverages knowledge bases to automatically label instances, thus allowing us to train relation extractor without human annotations. However, the generated training data typically contain massive noise, and may result in poor performances with the vanilla supervised learning. In this paper, we propose to conduct multi-instance learning with a novel Cross-relation Cross-bag Selective Attention (C$^2$SA), which leads to noise-robust training for distant supervised relation extractor. Specifically, we employ the sentence-level selective attention to reduce the effect of noisy or mismatched sentences, while the correlation among relations were captured to improve the quality of attention weights. Moreover, instead of treating all entity-pairs equally, we try to pay more attention to entity-pairs with a higher quality. Similarly, we adopt the selective attention mechanism to achieve this goal. Experiments with two types of relation extractor demonstrate the superiority of the proposed approach over the state-of-the-art, while further ablation studies verify our intuitions and demonstrate the effectiveness of our proposed two techniques.
A Layer Decomposition-Recomposition Framework for Neuron Pruning towards Accurate Lightweight Networks
Dec 17, 2018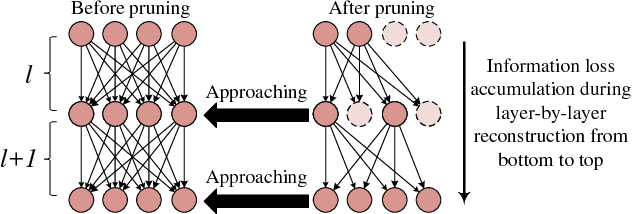
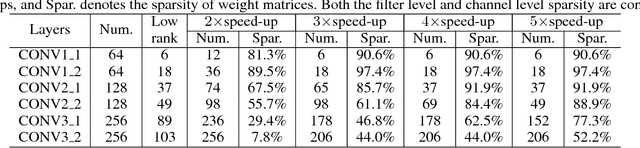
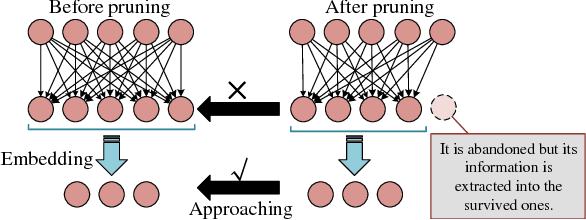
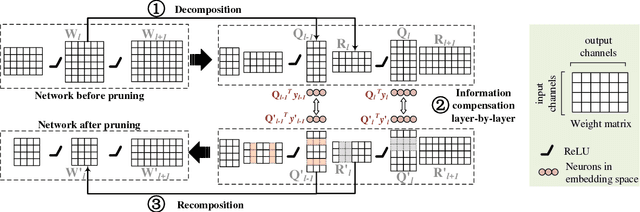
Neuron pruning is an efficient method to compress the network into a slimmer one for reducing the computational cost and storage overhead. Most of state-of-the-art results are obtained in a layer-by-layer optimization mode. It discards the unimportant input neurons and uses the survived ones to reconstruct the output neurons approaching to the original ones in a layer-by-layer manner. However, an unnoticed problem arises that the information loss is accumulated as layer increases since the survived neurons still do not encode the entire information as before. A better alternative is to propagate the entire useful information to reconstruct the pruned layer instead of directly discarding the less important neurons. To this end, we propose a novel Layer Decomposition-Recomposition Framework (LDRF) for neuron pruning, by which each layer's output information is recovered in an embedding space and then propagated to reconstruct the following pruned layers with useful information preserved. We mainly conduct our experiments on ILSVRC-12 benchmark with VGG-16 and ResNet-50. What should be emphasized is that our results before end-to-end fine-tuning are significantly superior owing to the information-preserving property of our proposed framework.With end-to-end fine-tuning, we achieve state-of-the-art results of 5.13x and 3x speed-up with only 0.5% and 0.65% top-5 accuracy drop respectively, which outperform the existing neuron pruning methods.
Learning Incremental Triplet Margin for Person Re-identification
Dec 17, 2018

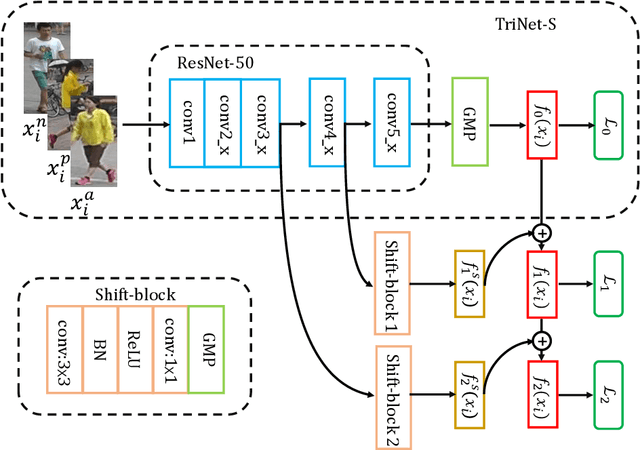

Person re-identification (ReID) aims to match people across multiple non-overlapping video cameras deployed at different locations. To address this challenging problem, many metric learning approaches have been proposed, among which triplet loss is one of the state-of-the-arts. In this work, we explore the margin between positive and negative pairs of triplets and prove that large margin is beneficial. In particular, we propose a novel multi-stage training strategy which learns incremental triplet margin and improves triplet loss effectively. Multiple levels of feature maps are exploited to make the learned features more discriminative. Besides, we introduce global hard identity searching method to sample hard identities when generating a training batch. Extensive experiments on Market-1501, CUHK03, and DukeMTMCreID show that our approach yields a performance boost and outperforms most existing state-of-the-art methods.