 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fast Adaptation of Pretrained Contrastive Models for Multi-channel Video-Language Retrieval
Jun 05, 2022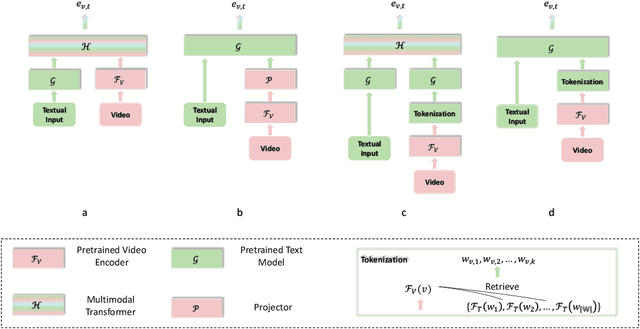

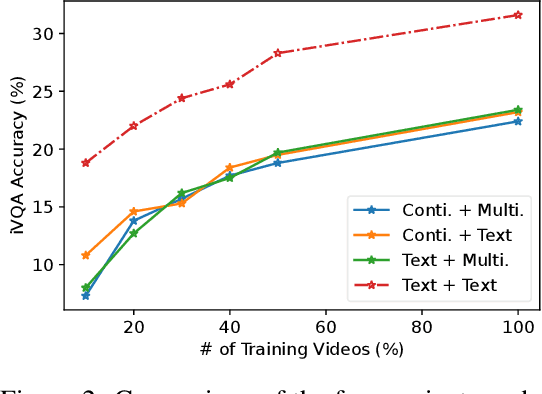
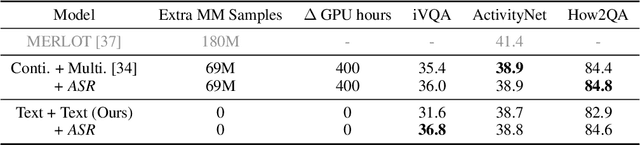
Multi-channel video-language retrieval require models to understand information from different modalities (e.g. video+question, video+speech) and real-world knowledge to correctly link a video with a textual response or query. Fortunately, multimodal contrastive models have been shown to be highly effective at aligning entities in images/videos and text, e.g., CLIP; text contrastive models have been extensively studied recently for their strong ability of producing discriminative sentence embeddings, e.g., SimCSE. Their abilities are exactly needed by multi-channel video-language retrieval. However, it is not clear how to quickly adapt these two lines of models to multi-channel video-language retrieval-style tasks. In this paper, we identify a principled model design space with two axes: how to represent videos and how to fuse video and text information. Based on categorization of recent methods, we investigate the options of representing videos using continuous feature vectors or discrete text tokens; for the fusion method, we explore a multimodal transformer or a pretrained contrastive text model. We extensively evaluate the four combinations on five video-language datasets. We surprisingly find that discrete text tokens coupled with a pretrained contrastive text model yields the best performance. This combination can even outperform state-of-the-art on the iVQA dataset without the additional training on millions of video-language data. Further analysis shows that this is because representing videos as text tokens captures the key visual information with text tokens that are naturally aligned with text models and the text models obtained rich knowledge during contrastive pretraining process. All the empirical analysis we obtain for the four variants establishes a solid foundation for future research on leveraging the rich knowledge of pretrained contrastive models.
Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners
May 29, 2022
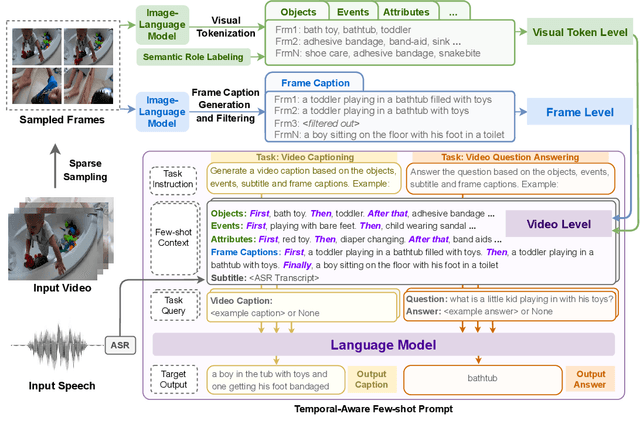
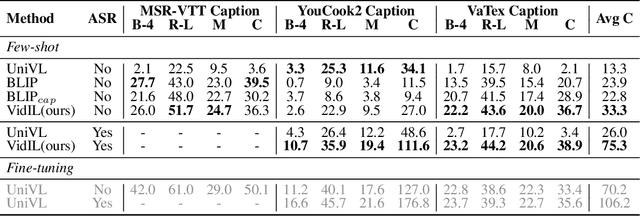

The goal of this work is to build flexible video-language models that can generalize to various video-to-text tasks from few examples, such as domain-specific captioning, question answering, and future event prediction. Existing few-shot video-language learners focus exclusively on the encoder, resulting in the absence of a video-to-text decoder to handle generative tasks. Video captioners have been pretrained on large-scale video-language datasets, but they rely heavily on finetuning and lack the ability to generate text for unseen tasks in a few-shot setting. We propose VidIL, a few-shot Video-language Learner via Image and Language models, which demonstrates strong performance on few-shot video-to-text tasks without the necessity of pretraining or finetuning on any video datasets. We use the image-language models to translate the video content into frame captions, object, attribute, and event phrases, and compose them into a temporal structure template. We then instruct a language model, with a prompt containing a few in-context examples, to generate a target output from the composed content. The flexibility of prompting allows the model to capture any form of text input, such as automatic speech recognition (ASR) transcripts. Our experiments demonstrate the power of language models in understanding videos on a wide variety of video-language tasks, including video captioning, video question answering, video caption retrieval, and video future event prediction. Especially, on video future event prediction, our few-shot model significantly outperforms state-of-the-art supervised models trained on large-scale video datasets. Code and resources are publicly available for research purposes at https://github.com/MikeWangWZHL/VidIL .
Multimodal Few-Shot Object Detection with Meta-Learning Based Cross-Modal Prompting
Apr 16, 2022
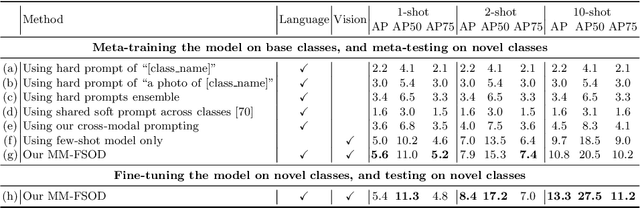
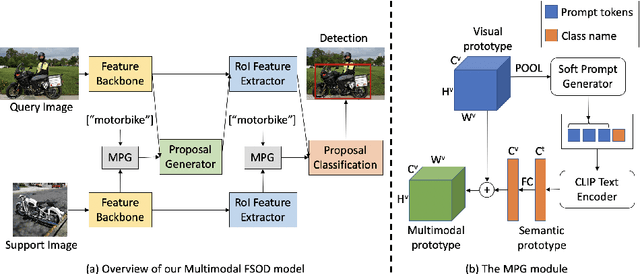
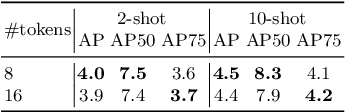
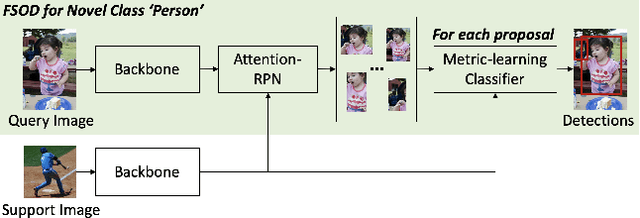
We study multimodal few-shot object detection (FSOD) in this paper, using both few-shot visual examples and class semantic information for detection. Most of previous works focus on either few-shot or zero-shot object detection, ignoring the complementarity of visual and semantic information. We first show that meta-learning and prompt-based learning, the most commonly-used methods for few-shot learning and zero-shot transferring from pre-trained vision-language models to downstream tasks, are conceptually similar. They both reformulate the objective of downstream tasks the same as the pre-training tasks, and mostly without tuning the parameters of pre-trained models. Based on this observation, we propose to combine meta-learning with prompt-based learning for multimodal FSOD without fine-tuning, by learning transferable class-agnostic multimodal FSOD models over many-shot base classes. Specifically, to better exploit the pre-trained vision-language models, the meta-learning based cross-modal prompting is proposed to generate soft prompts and further used to extract the semantic prototype, conditioned on the few-shot visual examples. Then, the extracted semantic prototype and few-shot visual prototype are fused to generate the multimodal prototype for detection. Our models can efficiently fuse the visual and semantic information at both token-level and feature-level. We comprehensively evaluate the proposed multimodal FSOD models on multiple few-shot object detection benchmarks, achieving promising results.
Fine-Grained Visual Entailment
Mar 29, 2022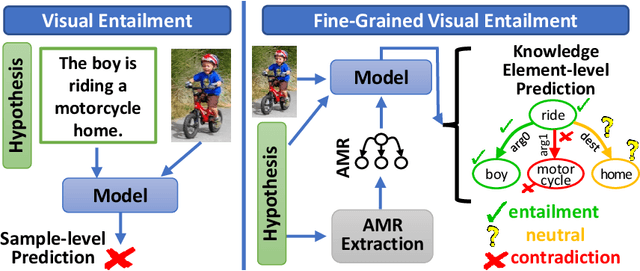
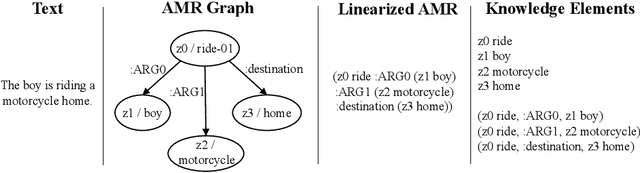
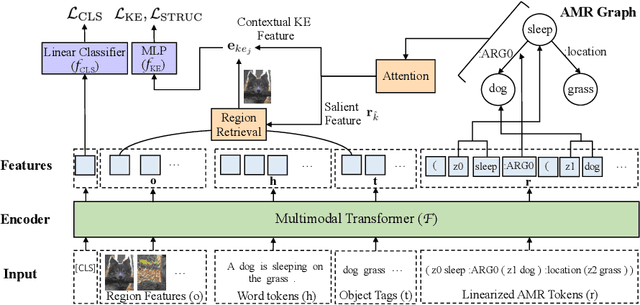
Visual entailment is a recently proposed multimodal reasoning task where the goal is to predict the logical relationship of a piece of text to an image. In this paper, we propose an extension of this task, where the goal is to predict the logical relationship of fine-grained knowledge elements within a piece of text to an image. Unlike prior work, our method is inherently explainable and makes logical predictions at different levels of granularity. Because we lack fine-grained labels to train our method, we propose a novel multi-instance learning approach which learns a fine-grained labeling using only sample-level supervision. We also impose novel semantic structural constraints which ensure that fine-grained predictions are internally semantically consistent. We evaluate our method on a new dataset of manually annotated knowledge elements and show that our method achieves 68.18\% accuracy at this challenging task while significantly outperforming several strong baselines. Finally, we present extensive qualitative results illustrating our method's predictions and the visual evidence our method relied on. Our code and annotated dataset can be found here: https://github.com/SkrighYZ/FGVE.
Few-Shot Object Detection with Fully Cross-Transformer
Mar 28, 2022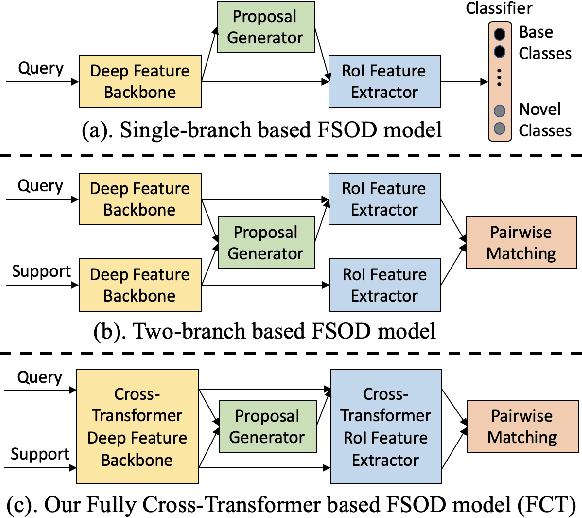
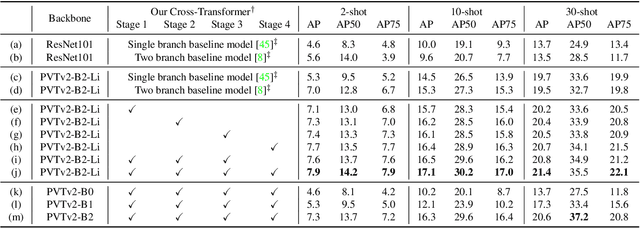
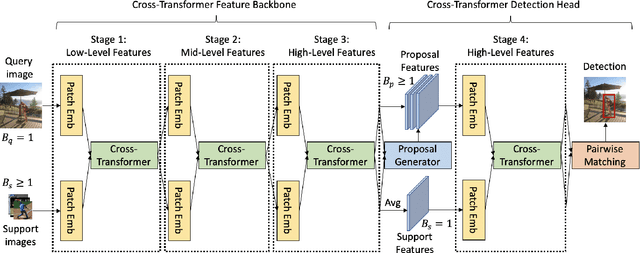
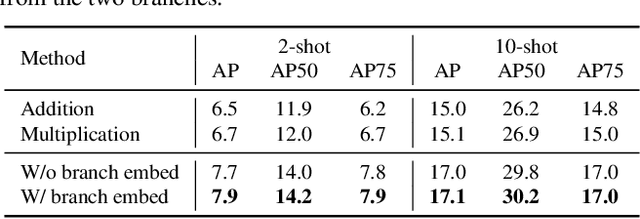
Few-shot object detection (FSOD), with the aim to detect novel objects using very few training examples, has recently attracted great research interest in the community. Metric-learning based methods have been demonstrated to be effective for this task using a two-branch based siamese network, and calculate the similarity between image regions and few-shot examples for detection. However, in previous works, the interaction between the two branches is only restricted in the detection head, while leaving the remaining hundreds of layers for separate feature extraction. Inspired by the recent work on vision transformers and vision-language transformers, we propose a novel Fully Cross-Transformer based model (FCT) for FSOD by incorporating cross-transformer into both the feature backbone and detection head. The asymmetric-batched cross-attention is proposed to aggregate the key information from the two branches with different batch sizes. Our model can improve the few-shot similarity learning between the two branches by introducing the multi-level interactions. Comprehensive experiments on both PASCAL VOC and MSCOCO FSOD benchmarks demonstrate the effectiveness of our model.
Learning To Recognize Procedural Activities with Distant Supervision
Jan 26, 2022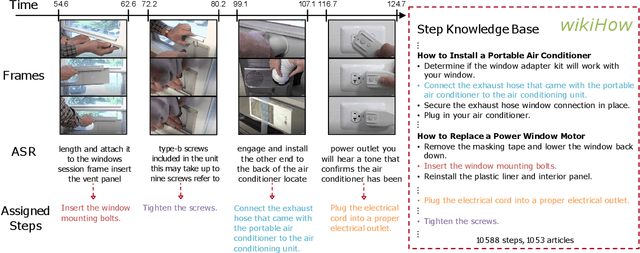

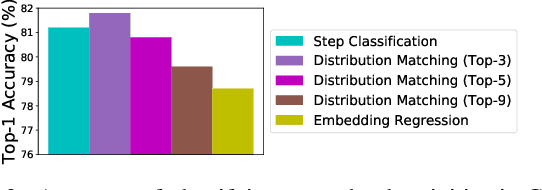

In this paper we consider the problem of classifying fine-grained, multi-step activities (e.g., cooking different recipes, making disparate home improvements, creating various forms of arts and crafts) from long videos spanning up to several minutes. Accurately categorizing these activities requires not only recognizing the individual steps that compose the task but also capturing their temporal dependencies. This problem is dramatically different from traditional action classification, where models are typically optimized on videos that span only a few seconds and that are manually trimmed to contain simple atomic actions. While step annotations could enable the training of models to recognize the individual steps of procedural activities, existing large-scale datasets in this area do not include such segment labels due to the prohibitive cost of manually annotating temporal boundaries in long videos. To address this issue, we propose to automatically identify steps in instructional videos by leveraging the distant supervision of a textual knowledge base (wikiHow) that includes detailed descriptions of the steps needed for the execution of a wide variety of complex activities. Our method uses a language model to match noisy, automatically-transcribed speech from the video to step descriptions in the knowledge base. We demonstrate that video models trained to recognize these automatically-labeled steps (without manual supervision) yield a representation that achieves superior generalization performance on four downstream tasks: recognition of procedural activities, step classification, step forecasting and egocentric video classification.
CLIP-TD: CLIP Targeted Distillation for Vision-Language Tasks
Jan 15, 2022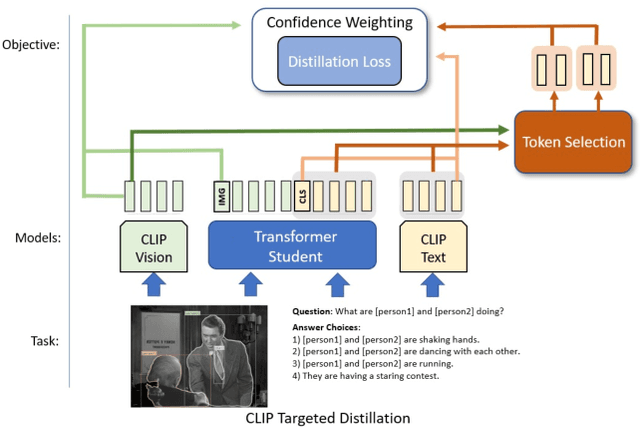
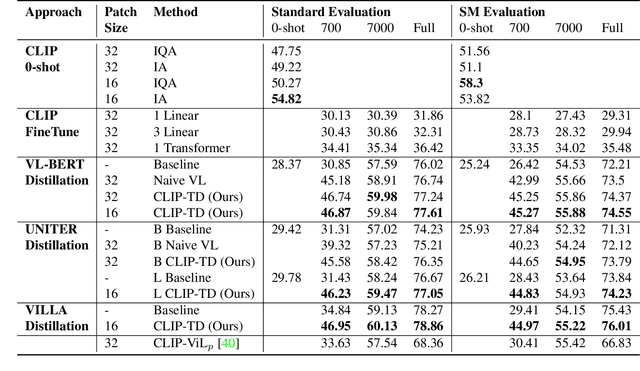
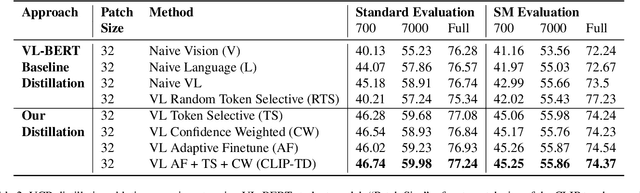

Contrastive language-image pretraining (CLIP) links vision and language modalities into a unified embedding space, yielding the tremendous potential for vision-language (VL) tasks. While early concurrent works have begun to study this potential on a subset of tasks, important questions remain: 1) What is the benefit of CLIP on unstudied VL tasks? 2) Does CLIP provide benefit in low-shot or domain-shifted scenarios? 3) Can CLIP improve existing approaches without impacting inference or pretraining complexity? In this work, we seek to answer these questions through two key contributions. First, we introduce an evaluation protocol that includes Visual Commonsense Reasoning (VCR), Visual Entailment (SNLI-VE), and Visual Question Answering (VQA), across a variety of data availability constraints and conditions of domain shift. Second, we propose an approach, named CLIP Targeted Distillation (CLIP-TD), to intelligently distill knowledge from CLIP into existing architectures using a dynamically weighted objective applied to adaptively selected tokens per instance. Experiments demonstrate that our proposed CLIP-TD leads to exceptional gains in the low-shot (up to 51.9%) and domain-shifted (up to 71.3%) conditions of VCR, while simultaneously improving performance under standard fully-supervised conditions (up to 2%), achieving state-of-art performance on VCR compared to other single models that are pretrained with image-text data only. On SNLI-VE, CLIP-TD produces significant gains in low-shot conditions (up to 6.6%) as well as fully supervised (up to 3%). On VQA, CLIP-TD provides improvement in low-shot (up to 9%), and in fully-supervised (up to 1.3%). Finally, CLIP-TD outperforms concurrent works utilizing CLIP for finetuning, as well as baseline naive distillation approaches. Code will be made available.
CLIP-Event: Connecting Text and Images with Event Structures
Jan 13, 2022
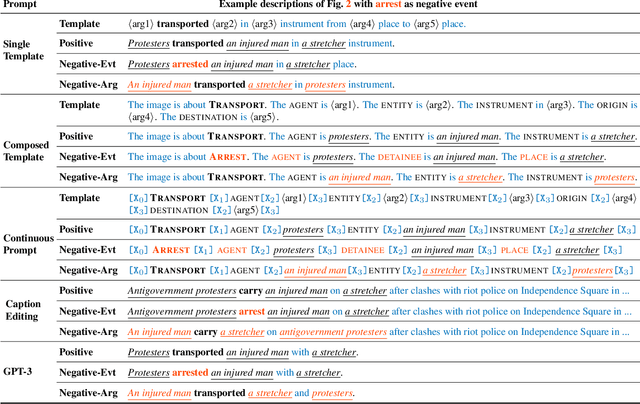
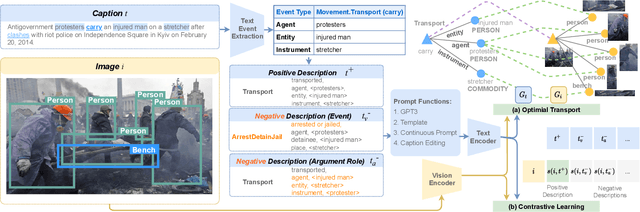

Vision-language (V+L) pretraining models have achieved great success in supporting multimedia applications by understanding the alignments between images and text. While existing vision-language pretraining models primarily focus on understanding objects in images or entities in text, they often ignore the alignment at the level of events and their argument structures. % In this work, we propose a contrastive learning framework to enforce vision-language pretraining models to comprehend events and associated argument (participant) roles. To achieve this, we take advantage of text information extraction technologies to obtain event structural knowledge, and utilize multiple prompt functions to contrast difficult negative descriptions by manipulating event structures. We also design an event graph alignment loss based on optimal transport to capture event argument structures. In addition, we collect a large event-rich dataset (106,875 images) for pretraining, which provides a more challenging image retrieval benchmark to assess the understanding of complicated lengthy sentences. Experiments show that our zero-shot CLIP-Event outperforms the state-of-the-art supervised model in argument extraction on Multimedia Event Extraction, achieving more than 5\% absolute F-score gain in event extraction, as well as significant improvements on a variety of downstream tasks under zero-shot settings.
MuMuQA: Multimedia Multi-Hop News Question Answering via Cross-Media Knowledge Extraction and Grounding
Dec 20, 2021

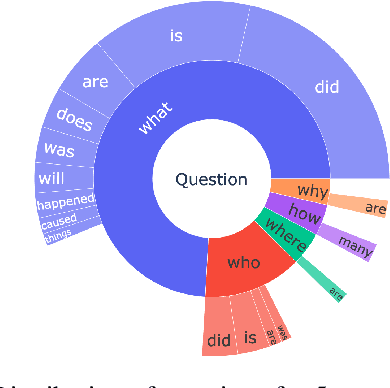
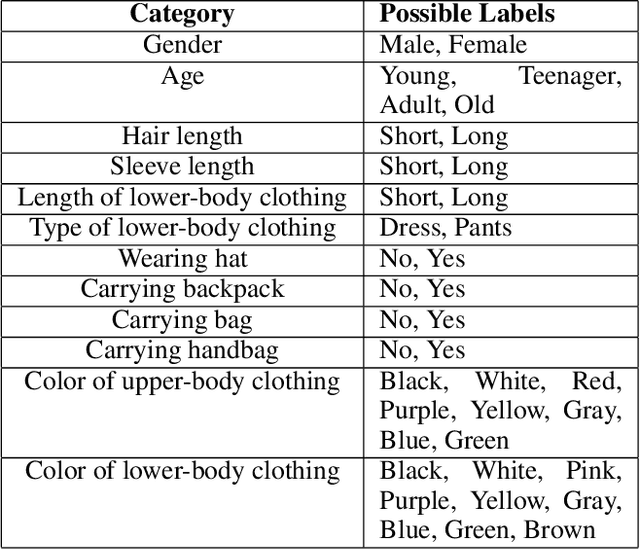
Recently, there has been an increasing interest in building question answering (QA) models that reason across multiple modalities, such as text and images. However, QA using images is often limited to just picking the answer from a pre-defined set of options. In addition, images in the real world, especially in news, have objects that are co-referential to the text, with complementary information from both modalities. In this paper, we present a new QA evaluation benchmark with 1,384 questions over news articles that require cross-media grounding of objects in images onto text. Specifically, the task involves multi-hop questions that require reasoning over image-caption pairs to identify the grounded visual object being referred to and then predicting a span from the news body text to answer the question. In addition, we introduce a novel multimedia data augmentation framework, based on cross-media knowledge extraction and synthetic question-answer generation, to automatically augment data that can provide weak supervision for this task. We evaluate both pipeline-based and end-to-end pretraining-based multimedia QA models on our benchmark, and show that they achieve promising performance, while considerably lagging behind human performance hence leaving large room for future work on this challenging new task.
Query Adaptive Few-Shot Object Detection with Heterogeneous Graph Convolutional Networks
Dec 17, 2021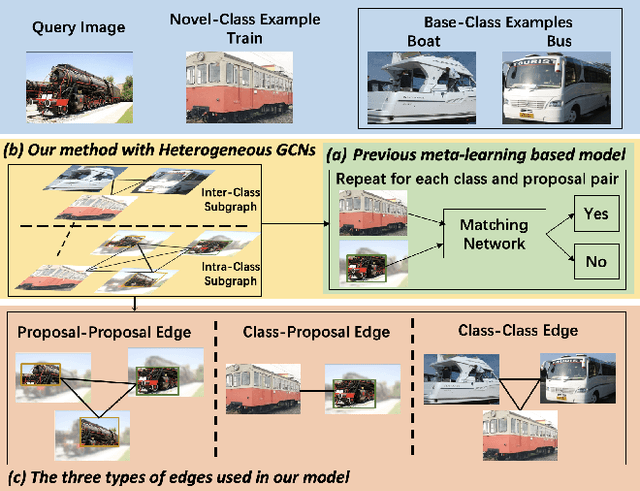
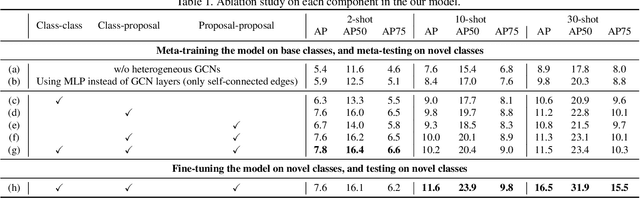
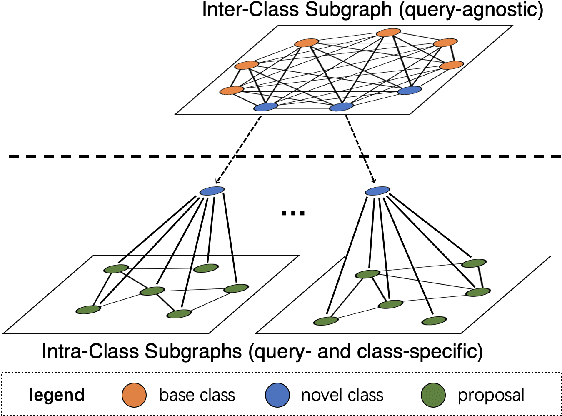
Few-shot object detection (FSOD) aims to detect never-seen objects using few examples. This field sees recent improvement owing to the meta-learning techniques by learning how to match between the query image and few-shot class examples, such that the learned model can generalize to few-shot novel classes. However, currently, most of the meta-learning-based methods perform pairwise matching between query image regions (usually proposals) and novel classes separately, therefore failing to take into account multiple relationships among them. In this paper, we propose a novel FSOD model using heterogeneous graph convolutional networks. Through efficient message passing among all the proposal and class nodes with three different types of edges, we could obtain context-aware proposal features and query-adaptive, multiclass-enhanced prototype representations for each class, which could help promote the pairwise matching and improve final FSOD accuracy. Extensive experimental results show that our proposed model, denoted as QA-FewDet, outperforms the current state-of-the-art approaches on the PASCAL VOC and MSCOCO FSOD benchmarks under different shots and evaluation metrics.