 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMNN-LLM: A Generic Inference Engine for Fast Large Language Model Deployment on Mobile Devices
Jun 12, 2025Large language models (LLMs) have demonstrated exceptional performance across a variety of tasks. However, their substantial scale leads to significant computational resource consumption during inference, resulting in high costs. Consequently, edge device inference presents a promising solution. The primary challenges of edge inference include memory usage and inference speed. This paper introduces MNN-LLM, a framework specifically designed to accelerate the deployment of large language models on mobile devices. MNN-LLM addresses the runtime characteristics of LLMs through model quantization and DRAM-Flash hybrid storage, effectively reducing memory usage. It rearranges weights and inputs based on mobile CPU instruction sets and GPU characteristics while employing strategies such as multicore load balancing, mixed-precision floating-point operations, and geometric computations to enhance performance. Notably, MNN-LLM achieves up to a 8.6x speed increase compared to current mainstream LLM-specific frameworks.
Infi-MMR: Curriculum-based Unlocking Multimodal Reasoning via Phased Reinforcement Learning in Multimodal Small Language Models
May 29, 2025



Recent advancements in large language models (LLMs) have demonstrated substantial progress in reasoning capabilities, such as DeepSeek-R1, which leverages rule-based reinforcement learning to enhance logical reasoning significantly. However, extending these achievements to multimodal large language models (MLLMs) presents critical challenges, which are frequently more pronounced for Multimodal Small Language Models (MSLMs) given their typically weaker foundational reasoning abilities: (1) the scarcity of high-quality multimodal reasoning datasets, (2) the degradation of reasoning capabilities due to the integration of visual processing, and (3) the risk that direct application of reinforcement learning may produce complex yet incorrect reasoning processes. To address these challenges, we design a novel framework Infi-MMR to systematically unlock the reasoning potential of MSLMs through a curriculum of three carefully structured phases and propose our multimodal reasoning model Infi-MMR-3B. The first phase, Foundational Reasoning Activation, leverages high-quality textual reasoning datasets to activate and strengthen the model's logical reasoning capabilities. The second phase, Cross-Modal Reasoning Adaptation, utilizes caption-augmented multimodal data to facilitate the progressive transfer of reasoning skills to multimodal contexts. The third phase, Multimodal Reasoning Enhancement, employs curated, caption-free multimodal data to mitigate linguistic biases and promote robust cross-modal reasoning. Infi-MMR-3B achieves both state-of-the-art multimodal math reasoning ability (43.68% on MathVerse testmini, 27.04% on MathVision test, and 21.33% on OlympiadBench) and general reasoning ability (67.2% on MathVista testmini).
Cuff-KT: Tackling Learners' Real-time Learning Pattern Adjustment via Tuning-Free Knowledge State Guided Model Updating
May 26, 2025



Knowledge Tracing (KT) is a core component of Intelligent Tutoring Systems, modeling learners' knowledge state to predict future performance and provide personalized learning support. Traditional KT models assume that learners' learning abilities remain relatively stable over short periods or change in predictable ways based on prior performance. However, in reality, learners' abilities change irregularly due to factors like cognitive fatigue, motivation, and external stress -- a task introduced, which we refer to as Real-time Learning Pattern Adjustment (RLPA). Existing KT models, when faced with RLPA, lack sufficient adaptability, because they fail to timely account for the dynamic nature of different learners' evolving learning patterns. Current strategies for enhancing adaptability rely on retraining, which leads to significant overfitting and high time overhead issues. To address this, we propose Cuff-KT, comprising a controller and a generator. The controller assigns value scores to learners, while the generator generates personalized parameters for selected learners. Cuff-KT controllably adapts to data changes fast and flexibly without fine-tuning. Experiments on five datasets from different subjects demonstrate that Cuff-KT significantly improves the performance of five KT models with different structures under intra- and inter-learner shifts, with an average relative increase in AUC of 10% and 4%, respectively, at a negligible time cost, effectively tackling RLPA task. Our code and datasets are fully available at https://github.com/zyy-2001/Cuff-KT.
Multimodal LLM-Guided Semantic Correction in Text-to-Image Diffusion
May 26, 2025



Diffusion models have become the mainstream architecture for text-to-image generation, achieving remarkable progress in visual quality and prompt controllability. However, current inference pipelines generally lack interpretable semantic supervision and correction mechanisms throughout the denoising process. Most existing approaches rely solely on post-hoc scoring of the final image, prompt filtering, or heuristic resampling strategies-making them ineffective in providing actionable guidance for correcting the generative trajectory. As a result, models often suffer from object confusion, spatial errors, inaccurate counts, and missing semantic elements, severely compromising prompt-image alignment and image quality. To tackle these challenges, we propose MLLM Semantic-Corrected Ping-Pong-Ahead Diffusion (PPAD), a novel framework that, for the first time, introduces a Multimodal Large Language Model (MLLM) as a semantic observer during inference. PPAD performs real-time analysis on intermediate generations, identifies latent semantic inconsistencies, and translates feedback into controllable signals that actively guide the remaining denoising steps. The framework supports both inference-only and training-enhanced settings, and performs semantic correction at only extremely few diffusion steps, offering strong generality and scalability. Extensive experiments demonstrate PPAD's significant improvements.
ThinkRec: Thinking-based recommendation via LLM
May 21, 2025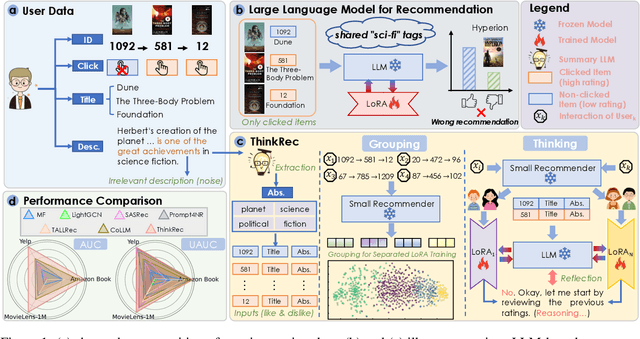
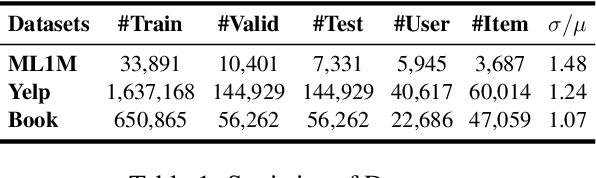
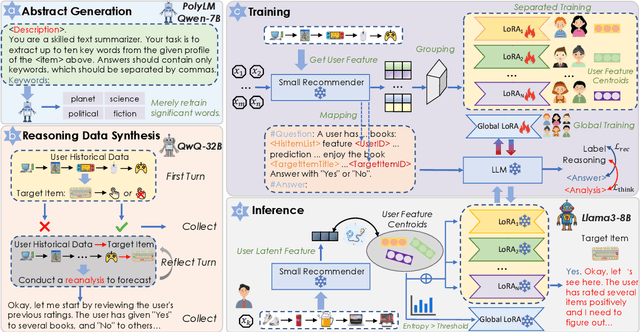

Recent advances in large language models (LLMs) have enabled more semantic-aware recommendations through natural language generation. Existing LLM for recommendation (LLM4Rec) methods mostly operate in a System 1-like manner, relying on superficial features to match similar items based on click history, rather than reasoning through deeper behavioral logic. This often leads to superficial and erroneous recommendations. Motivated by this, we propose ThinkRec, a thinking-based framework that shifts LLM4Rec from System 1 to System 2 (rational system). Technically, ThinkRec introduces a thinking activation mechanism that augments item metadata with keyword summarization and injects synthetic reasoning traces, guiding the model to form interpretable reasoning chains that consist of analyzing interaction histories, identifying user preferences, and making decisions based on target items. On top of this, we propose an instance-wise expert fusion mechanism to reduce the reasoning difficulty. By dynamically assigning weights to expert models based on users' latent features, ThinkRec adapts its reasoning path to individual users, thereby enhancing precision and personalization. Extensive experiments on real-world datasets demonstrate that ThinkRec significantly improves the accuracy and interpretability of recommendations. Our implementations are available in anonymous Github: https://anonymous.4open.science/r/ThinkRec_LLM.
EcoAgent: An Efficient Edge-Cloud Collaborative Multi-Agent Framework for Mobile Automation
May 08, 2025Cloud-based mobile agents powered by (multimodal) large language models ((M)LLMs) offer strong reasoning abilities but suffer from high latency and cost. While fine-tuned (M)SLMs enable edge deployment, they often lose general capabilities and struggle with complex tasks. To address this, we propose EcoAgent, an Edge-Cloud cOllaborative multi-agent framework for mobile automation. EcoAgent features a closed-loop collaboration among a cloud-based Planning Agent and two edge-based agents: the Execution Agent for action execution and the Observation Agent for verifying outcomes. The Observation Agent uses a Pre-Understanding Module to compress screen images into concise text, reducing token usage. In case of failure, the Planning Agent retrieves screen history and replans via a Reflection Module. Experiments on AndroidWorld show that EcoAgent maintains high task success rates while significantly reducing MLLM token consumption, enabling efficient and practical mobile automation.
InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reasoners
Apr 19, 2025Multimodal Large Language Models (MLLMs) have powered Graphical User Interface (GUI) Agents, showing promise in automating tasks on computing devices. Recent works have begun exploring reasoning in GUI tasks with encouraging results. However, many current approaches rely on manually designed reasoning templates, which may result in reasoning that is not sufficiently robust and adaptive for complex GUI environments. Meanwhile, some existing agents continue to operate as Reactive Actors, relying primarily on implicit reasoning that may lack sufficient depth for GUI tasks demanding planning and error recovery. We argue that advancing these agents requires a shift from reactive acting towards acting based on deliberate reasoning. To facilitate this transformation, we introduce InfiGUI-R1, an MLLM-based GUI agent developed through our Actor2Reasoner framework, a reasoning-centric, two-stage training approach designed to progressively evolve agents from Reactive Actors to Deliberative Reasoners. The first stage, Reasoning Injection, focuses on establishing a basic reasoner. We employ Spatial Reasoning Distillation to transfer cross-modal spatial reasoning capabilities from teacher models to MLLMs through trajectories with explicit reasoning steps, enabling models to integrate GUI visual-spatial information with logical reasoning before action generation. The second stage, Deliberation Enhancement, refines the basic reasoner into a deliberative one using Reinforcement Learning. This stage introduces two approaches: Sub-goal Guidance, which rewards models for generating accurate intermediate sub-goals, and Error Recovery Scenario Construction, which creates failure-and-recovery training scenarios from identified prone-to-error steps. Experimental results show InfiGUI-R1 achieves strong performance in GUI grounding and trajectory tasks. Resources at https://github.com/Reallm-Labs/InfiGUI-R1.
Disentangled Knowledge Tracing for Alleviating Cognitive Bias
Mar 04, 2025In the realm of Intelligent Tutoring System (ITS), the accurate assessment of students' knowledge states through Knowledge Tracing (KT) is crucial for personalized learning. However, due to data bias, $\textit{i.e.}$, the unbalanced distribution of question groups ($\textit{e.g.}$, concepts), conventional KT models are plagued by cognitive bias, which tends to result in cognitive underload for overperformers and cognitive overload for underperformers. More seriously, this bias is amplified with the exercise recommendations by ITS. After delving into the causal relations in the KT models, we identify the main cause as the confounder effect of students' historical correct rate distribution over question groups on the student representation and prediction score. Towards this end, we propose a Disentangled Knowledge Tracing (DisKT) model, which separately models students' familiar and unfamiliar abilities based on causal effects and eliminates the impact of the confounder in student representation within the model. Additionally, to shield the contradictory psychology ($\textit{e.g.}$, guessing and mistaking) in the students' biased data, DisKT introduces a contradiction attention mechanism. Furthermore, DisKT enhances the interpretability of the model predictions by integrating a variant of Item Response Theory. Experimental results on 11 benchmarks and 3 synthesized datasets with different bias strengths demonstrate that DisKT significantly alleviates cognitive bias and outperforms 16 baselines in evaluation accuracy.
AEIA-MN: Evaluating the Robustness of Multimodal LLM-Powered Mobile Agents Against Active Environmental Injection Attacks
Feb 18, 2025



As researchers continuously optimize AI agents to perform tasks more effectively within operating systems, they often neglect to address the critical need for enabling these agents to identify "impostors" within the system. Through an analysis of the agents' operating environment, we identified a potential threat: attackers can disguise their attack methods as environmental elements, injecting active disturbances into the agents' execution process, thereby disrupting their decision-making. We define this type of attack as Active Environment Injection Attack (AEIA). Based on this, we propose AEIA-MN, an active environment injection attack scheme that exploits interaction vulnerabilities in the mobile operating system to evaluate the robustness of MLLM-based agents against such threats. Experimental results show that even advanced MLLMs are highly vulnerable to this attack, achieving a maximum attack success rate of 93% in the AndroidWorld benchmark.
InfiR : Crafting Effective Small Language Models and Multimodal Small Language Models in Reasoning
Feb 17, 2025



Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) have made significant advancements in reasoning capabilities. However, they still face challenges such as high computational demands and privacy concerns. This paper focuses on developing efficient Small Language Models (SLMs) and Multimodal Small Language Models (MSLMs) that retain competitive reasoning abilities. We introduce a novel training pipeline that enhances reasoning capabilities and facilitates deployment on edge devices, achieving state-of-the-art performance while minimizing development costs. \InfR~ aims to advance AI systems by improving reasoning, reducing adoption barriers, and addressing privacy concerns through smaller model sizes. Resources are available at https://github. com/Reallm-Labs/InfiR.