 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealtime-VLA FLASH: Speculative Inference Framework for Diffusion-based VLAs
May 13, 2026Diffusion-based vision-language-action models (dVLAs) are promising for embodied intelligence but are fundamentally limited in real-time deployment by the high latency of full inference. We propose Realtime-VLA FLASH, a speculative inference framework that eliminates most full inference calls during replanning by introducing a lightweight draft model with parallel verification via the main model's Action Expert and a phase-aware fallback mechanism that reverts to the full inference pipeline when needed. This design enables low-latency, high-frequency replanning without sacrificing reliability. Experiments show that on LIBERO, FLASH largely preserves task performance by replacing many 58.0 ms full-inference rounds with speculative rounds as fast as 7.8 ms, lowering task-level average inference latency to 19.1 ms (3.04x speedup). We additionally demonstrate effectiveness on real-world conveyor-belt sorting, highlighting its practical impact for latency-critical embodied tasks.
QiMeng: Fully Automated Hardware and Software Design for Processor Chip
Jun 05, 2025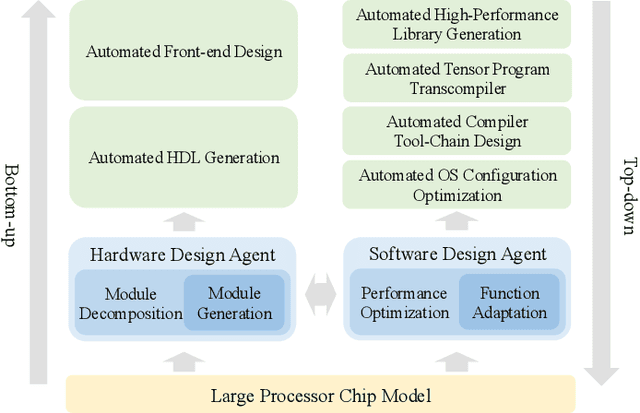
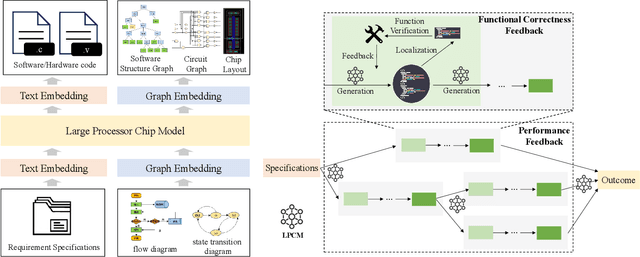
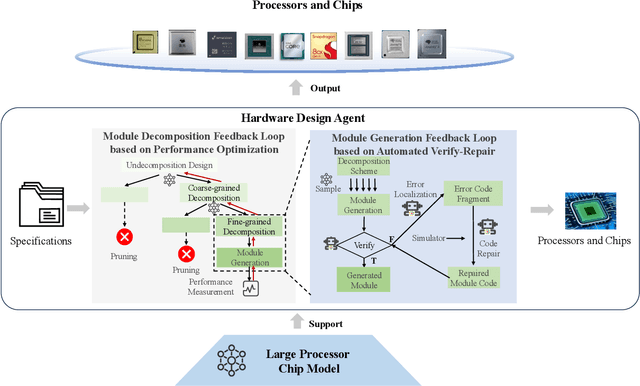
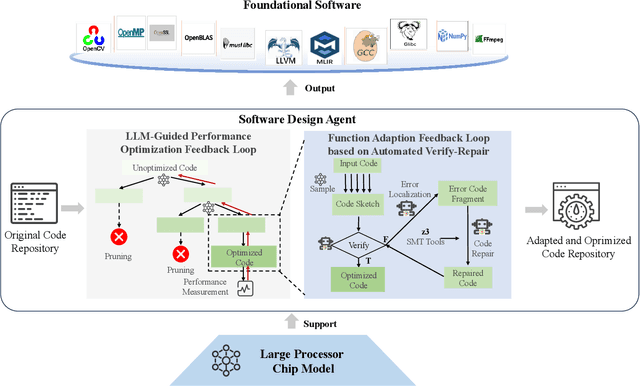
Processor chip design technology serves as a key frontier driving breakthroughs in computer science and related fields. With the rapid advancement of information technology, conventional design paradigms face three major challenges: the physical constraints of fabrication technologies, the escalating demands for design resources, and the increasing diversity of ecosystems. Automated processor chip design has emerged as a transformative solution to address these challenges. While recent breakthroughs in Artificial Intelligence (AI), particularly Large Language Models (LLMs) techniques, have opened new possibilities for fully automated processor chip design, substantial challenges remain in establishing domain-specific LLMs for processor chip design. In this paper, we propose QiMeng, a novel system for fully automated hardware and software design of processor chips. QiMeng comprises three hierarchical layers. In the bottom-layer, we construct a domain-specific Large Processor Chip Model (LPCM) that introduces novel designs in architecture, training, and inference, to address key challenges such as knowledge representation gap, data scarcity, correctness assurance, and enormous solution space. In the middle-layer, leveraging the LPCM's knowledge representation and inference capabilities, we develop the Hardware Design Agent and the Software Design Agent to automate the design of hardware and software for processor chips. Currently, several components of QiMeng have been completed and successfully applied in various top-layer applications, demonstrating significant advantages and providing a feasible solution for efficient, fully automated hardware/software design of processor chips. Future research will focus on integrating all components and performing iterative top-down and bottom-up design processes to establish a comprehensive QiMeng system.
CodeV-R1: Reasoning-Enhanced Verilog Generation
May 30, 2025Large language models (LLMs) trained via reinforcement learning with verifiable reward (RLVR) have achieved breakthroughs on tasks with explicit, automatable verification, such as software programming and mathematical problems. Extending RLVR to electronic design automation (EDA), especially automatically generating hardware description languages (HDLs) like Verilog from natural-language (NL) specifications, however, poses three key challenges: the lack of automated and accurate verification environments, the scarcity of high-quality NL-code pairs, and the prohibitive computation cost of RLVR. To this end, we introduce CodeV-R1, an RLVR framework for training Verilog generation LLMs. First, we develop a rule-based testbench generator that performs robust equivalence checking against golden references. Second, we propose a round-trip data synthesis method that pairs open-source Verilog snippets with LLM-generated NL descriptions, verifies code-NL-code consistency via the generated testbench, and filters out inequivalent examples to yield a high-quality dataset. Third, we employ a two-stage "distill-then-RL" training pipeline: distillation for the cold start of reasoning abilities, followed by adaptive DAPO, our novel RLVR algorithm that can reduce training cost by adaptively adjusting sampling rate. The resulting model, CodeV-R1-7B, achieves 68.6% and 72.9% pass@1 on VerilogEval v2 and RTLLM v1.1, respectively, surpassing prior state-of-the-art by 12~20%, while matching or even exceeding the performance of 671B DeepSeek-R1. We will release our model, training pipeline, and dataset to facilitate research in EDA and LLM communities.
InstInfer: In-Storage Attention Offloading for Cost-Effective Long-Context LLM Inference
Sep 08, 2024



The widespread of Large Language Models (LLMs) marks a significant milestone in generative AI. Nevertheless, the increasing context length and batch size in offline LLM inference escalate the memory requirement of the key-value (KV) cache, which imposes a huge burden on the GPU VRAM, especially for resource-constraint scenarios (e.g., edge computing and personal devices). Several cost-effective solutions leverage host memory or SSDs to reduce storage costs for offline inference scenarios and improve the throughput. Nevertheless, they suffer from significant performance penalties imposed by intensive KV cache accesses due to limited PCIe bandwidth. To address these issues, we propose InstInfer, a novel LLM inference system that offloads the most performance-critical computation (i.e., attention in decoding phase) and data (i.e., KV cache) parts to Computational Storage Drives (CSDs), which minimize the enormous KV transfer overheads. InstInfer designs a dedicated flash-aware in-storage attention engine with KV cache management mechanisms to exploit the high internal bandwidths of CSDs instead of being limited by the PCIe bandwidth. The optimized P2P transmission between GPU and CSDs further reduces data migration overheads. Experimental results demonstrate that for a 13B model using an NVIDIA A6000 GPU, InstInfer improves throughput for long-sequence inference by up to 11.1$\times$, compared to existing SSD-based solutions such as FlexGen.
Natural language is not enough: Benchmarking multi-modal generative AI for Verilog generation
Jul 11, 2024



Natural language interfaces have exhibited considerable potential in the automation of Verilog generation derived from high-level specifications through the utilization of large language models, garnering significant attention. Nevertheless, this paper elucidates that visual representations contribute essential contextual information critical to design intent for hardware architectures possessing spatial complexity, potentially surpassing the efficacy of natural-language-only inputs. Expanding upon this premise, our paper introduces an open-source benchmark for multi-modal generative models tailored for Verilog synthesis from visual-linguistic inputs, addressing both singular and complex modules. Additionally, we introduce an open-source visual and natural language Verilog query language framework to facilitate efficient and user-friendly multi-modal queries. To evaluate the performance of the proposed multi-modal hardware generative AI in Verilog generation tasks, we compare it with a popular method that relies solely on natural language. Our results demonstrate a significant accuracy improvement in the multi-modal generated Verilog compared to queries based solely on natural language. We hope to reveal a new approach to hardware design in the large-hardware-design-model era, thereby fostering a more diversified and productive approach to hardware design.
Data is all you need: Finetuning LLMs for Chip Design via an Automated design-data augmentation framework
Mar 17, 2024



Recent advances in large language models have demonstrated their potential for automated generation of hardware description language (HDL) code from high-level prompts. Researchers have utilized fine-tuning to enhance the ability of these large language models (LLMs) in the field of Chip Design. However, the lack of Verilog data hinders further improvement in the quality of Verilog generation by LLMs. Additionally, the absence of a Verilog and Electronic Design Automation (EDA) script data augmentation framework significantly increases the time required to prepare the training dataset for LLM trainers. This paper proposes an automated design-data augmentation framework, which generates high-volume and high-quality natural language aligned with Verilog and EDA scripts. For Verilog generation, it translates Verilog files to an abstract syntax tree and then maps nodes to natural language with a predefined template. For Verilog repair, it uses predefined rules to generate the wrong verilog file and then pairs EDA Tool feedback with the right and wrong verilog file. For EDA Script generation, it uses existing LLM(GPT-3.5) to obtain the description of the Script. To evaluate the effectiveness of our data augmentation method, we finetune Llama2-13B and Llama2-7B models using the dataset generated by our augmentation framework. The results demonstrate a significant improvement in the Verilog generation tasks with LLMs. Moreover, the accuracy of Verilog generation surpasses that of the current state-of-the-art open-source Verilog generation model, increasing from 58.8% to 70.6% with the same benchmark. Our 13B model (ChipGPT-FT) has a pass rate improvement compared with GPT-3.5 in Verilog generation and outperforms in EDA script (i.e., SiliconCompiler) generation with only 200 EDA script data.
ChipGPT: How far are we from natural language hardware design
May 23, 2023



As large language models (LLMs) like ChatGPT exhibited unprecedented machine intelligence, it also shows great performance in assisting hardware engineers to realize higher-efficiency logic design via natural language interaction. To estimate the potential of the hardware design process assisted by LLMs, this work attempts to demonstrate an automated design environment that explores LLMs to generate hardware logic designs from natural language specifications. To realize a more accessible and efficient chip development flow, we present a scalable four-stage zero-code logic design framework based on LLMs without retraining or finetuning. At first, the demo, ChipGPT, begins by generating prompts for the LLM, which then produces initial Verilog programs. Second, an output manager corrects and optimizes these programs before collecting them into the final design space. Eventually, ChipGPT will search through this space to select the optimal design under the target metrics. The evaluation sheds some light on whether LLMs can generate correct and complete hardware logic designs described by natural language for some specifications. It is shown that ChipGPT improves programmability, and controllability, and shows broader design optimization space compared to prior work and native LLMs alone.