 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Large Language Models: A Survey
Dec 23, 2023



Large Language Models (LLMs) have demonstrated remarkable capabilities in important tasks such as natural language understanding, language generation, and complex reasoning and have the potential to make a substantial impact on our society. Such capabilities, however, come with the considerable resources they demand, highlighting the strong need to develop effective techniques for addressing their efficiency challenges. In this survey, we provide a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from model-centric, data-centric, and framework-centric perspective, respectively. We have also created a GitHub repository where we compile the papers featured in this survey at https://github.com/AIoT-MLSys-Lab/EfficientLLMs, and will actively maintain this repository and incorporate new research as it emerges. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of the research developments in efficient LLMs and inspire them to contribute to this important and exciting field.
Pixel Aligned Language Models
Dec 14, 2023Large language models have achieved great success in recent years, so as their variants in vision. Existing vision-language models can describe images in natural languages, answer visual-related questions, or perform complex reasoning about the image. However, it is yet unclear how localization tasks, such as word grounding or referring localization, can be performed using large language models. In this work, we aim to develop a vision-language model that can take locations, for example, a set of points or boxes, as either inputs or outputs. When taking locations as inputs, the model performs location-conditioned captioning, which generates captions for the indicated object or region. When generating locations as outputs, our model regresses pixel coordinates for each output word generated by the language model, and thus performs dense word grounding. Our model is pre-trained on the Localized Narrative dataset, which contains pixel-word-aligned captioning from human attention. We show our model can be applied to various location-aware vision-language tasks, including referring localization, location-conditioned captioning, and dense object captioning, archiving state-of-the-art performance on RefCOCO and Visual Genome. Project page: https://jerryxu.net/PixelLLM .
UnLoc: A Unified Framework for Video Localization Tasks
Aug 21, 2023



While large-scale image-text pretrained models such as CLIP have been used for multiple video-level tasks on trimmed videos, their use for temporal localization in untrimmed videos is still a relatively unexplored task. We design a new approach for this called UnLoc, which uses pretrained image and text towers, and feeds tokens to a video-text fusion model. The output of the fusion module are then used to construct a feature pyramid in which each level connects to a head to predict a per-frame relevancy score and start/end time displacements. Unlike previous works, our architecture enables Moment Retrieval, Temporal Localization, and Action Segmentation with a single stage model, without the need for action proposals, motion based pretrained features or representation masking. Unlike specialized models, we achieve state of the art results on all three different localization tasks with a unified approach. Code will be available at: \url{https://github.com/google-research/scenic}.
AutoTaskFormer: Searching Vision Transformers for Multi-task Learning
Apr 20, 2023Vision Transformers have shown great performance in single tasks such as classification and segmentation. However, real-world problems are not isolated, which calls for vision transformers that can perform multiple tasks concurrently. Existing multi-task vision transformers are handcrafted and heavily rely on human expertise. In this work, we propose a novel one-shot neural architecture search framework, dubbed AutoTaskFormer (Automated Multi-Task Vision TransFormer), to automate this process. AutoTaskFormer not only identifies the weights to share across multiple tasks automatically, but also provides thousands of well-trained vision transformers with a wide range of parameters (e.g., number of heads and network depth) for deployment under various resource constraints. Experiments on both small-scale (2-task Cityscapes and 3-task NYUv2) and large-scale (16-task Taskonomy) datasets show that AutoTaskFormer outperforms state-of-the-art handcrafted vision transformers in multi-task learning. The entire code and models will be open-sourced.
Long-term Visual Localization with Mobile Sensors
Apr 16, 2023



Despite the remarkable advances in image matching and pose estimation, image-based localization of a camera in a temporally-varying outdoor environment is still a challenging problem due to huge appearance disparity between query and reference images caused by illumination, seasonal and structural changes. In this work, we propose to leverage additional sensors on a mobile phone, mainly GPS, compass, and gravity sensor, to solve this challenging problem. We show that these mobile sensors provide decent initial poses and effective constraints to reduce the searching space in image matching and final pose estimation. With the initial pose, we are also able to devise a direct 2D-3D matching network to efficiently establish 2D-3D correspondences instead of tedious 2D-2D matching in existing systems. As no public dataset exists for the studied problem, we collect a new dataset that provides a variety of mobile sensor data and significant scene appearance variations, and develop a system to acquire ground-truth poses for query images. We benchmark our method as well as several state-of-the-art baselines and demonstrate the effectiveness of the proposed approach. The code and dataset will be released publicly.
Towards Memory- and Time-Efficient Backpropagation for Training Spiking Neural Networks
Mar 07, 2023



Spiking Neural Networks (SNNs) are promising energy-efficient models for neuromorphic computing. For training the non-differentiable SNN models, the backpropagation through time (BPTT) with surrogate gradients (SG) method has achieved high performance. However, this method suffers from considerable memory cost and training time during training. In this paper, we propose the Spatial Learning Through Time (SLTT) method that can achieve high performance while greatly improving training efficiency compared with BPTT. First, we show that the backpropagation of SNNs through the temporal domain contributes just a little to the final calculated gradients. Thus, we propose to ignore the unimportant routes in the computational graph during backpropagation. The proposed method reduces the number of scalar multiplications and achieves a small memory occupation that is independent of the total time steps. Furthermore, we propose a variant of SLTT, called SLTT-K, that allows backpropagation only at K time steps, then the required number of scalar multiplications is further reduced and is independent of the total time steps. Experiments on both static and neuromorphic datasets demonstrate superior training efficiency and performance of our SLTT. In particular, our method achieves state-of-the-art accuracy on ImageNet, while the memory cost and training time are reduced by more than 70% and 50%, respectively, compared with BPTT.
Render-and-Compare: Cross-View 6 DoF Localization from Noisy Prior
Feb 13, 2023



Despite the significant progress in 6-DoF visual localization, researchers are mostly driven by ground-level benchmarks. Compared with aerial oblique photography, ground-level map collection lacks scalability and complete coverage. In this work, we propose to go beyond the traditional ground-level setting and exploit the cross-view localization from aerial to ground. We solve this problem by formulating camera pose estimation as an iterative render-and-compare pipeline and enhancing the robustness through augmenting seeds from noisy initial priors. As no public dataset exists for the studied problem, we collect a new dataset that provides a variety of cross-view images from smartphones and drones and develop a semi-automatic system to acquire ground-truth poses for query images. We benchmark our method as well as several state-of-the-art baselines and demonstrate that our method outperforms other approaches by a large margin.
Video-Text Modeling with Zero-Shot Transfer from Contrastive Captioners
Dec 09, 2022



This work explores an efficient approach to establish a foundational video-text model for tasks including open-vocabulary video classification, text-to-video retrieval, video captioning and video question-answering. We present VideoCoCa that reuses a pretrained image-text contrastive captioner (CoCa) model and adapt it to video-text tasks with minimal extra training. While previous works adapt image-text models with various cross-frame fusion modules (for example, cross-frame attention layer or perceiver resampler) and finetune the modified architecture on video-text data, we surprisingly find that the generative attentional pooling and contrastive attentional pooling layers in the image-text CoCa design are instantly adaptable to ``flattened frame embeddings'', yielding a strong zero-shot transfer baseline for many video-text tasks. Specifically, the frozen image encoder of a pretrained image-text CoCa takes each video frame as inputs and generates \(N\) token embeddings per frame for totally \(T\) video frames. We flatten \(N \times T\) token embeddings as a long sequence of frozen video representation and apply CoCa's generative attentional pooling and contrastive attentional pooling on top. All model weights including pooling layers are directly loaded from an image-text CoCa pretrained model. Without any video or video-text data, VideoCoCa's zero-shot transfer baseline already achieves state-of-the-art results on zero-shot video classification on Kinetics 400/600/700, UCF101, HMDB51, and Charades, as well as zero-shot text-to-video retrieval on MSR-VTT and ActivityNet Captions. We also explore lightweight finetuning on top of VideoCoCa, and achieve strong results on video question-answering (iVQA, MSRVTT-QA, MSVD-QA) and video captioning (MSR-VTT, ActivityNet, Youcook2). Our approach establishes a simple and effective video-text baseline for future research.
Soft Augmentation for Image Classification
Nov 09, 2022



Modern neural networks are over-parameterized and thus rely on strong regularization such as data augmentation and weight decay to reduce overfitting and improve generalization. The dominant form of data augmentation applies invariant transforms, where the learning target of a sample is invariant to the transform applied to that sample. We draw inspiration from human visual classification studies and propose generalizing augmentation with invariant transforms to soft augmentation where the learning target softens non-linearly as a function of the degree of the transform applied to the sample: e.g., more aggressive image crop augmentations produce less confident learning targets. We demonstrate that soft targets allow for more aggressive data augmentation, offer more robust performance boosts, work with other augmentation policies, and interestingly, produce better calibrated models (since they are trained to be less confident on aggressively cropped/occluded examples). Combined with existing aggressive augmentation strategies, soft target 1) doubles the top-1 accuracy boost across Cifar-10, Cifar-100, ImageNet-1K, and ImageNet-V2, 2) improves model occlusion performance by up to $4\times$, and 3) halves the expected calibration error (ECE). Finally, we show that soft augmentation generalizes to self-supervised classification tasks.
Training High-Performance Low-Latency Spiking Neural Networks by Differentiation on Spike Representation
May 01, 2022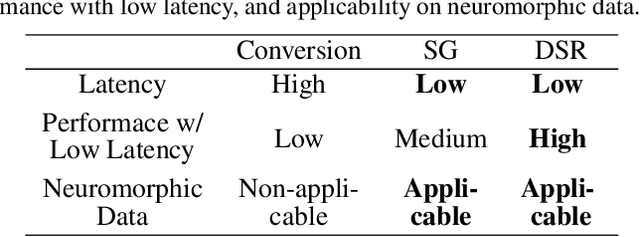
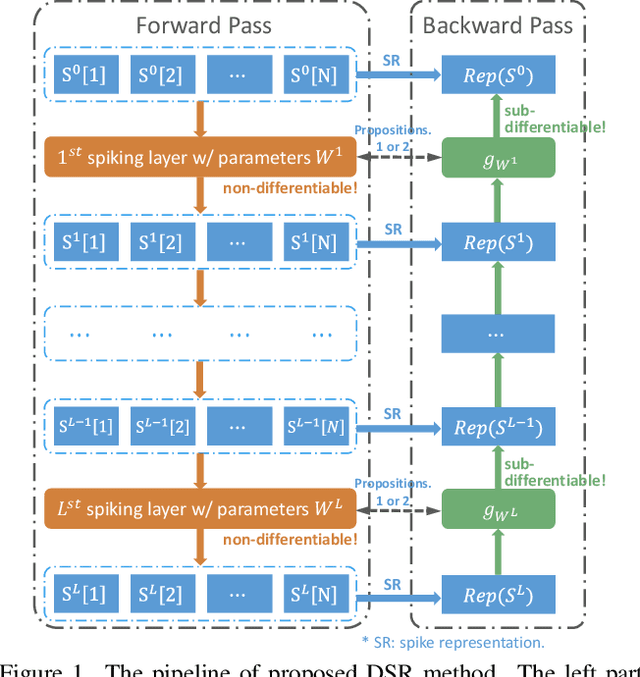
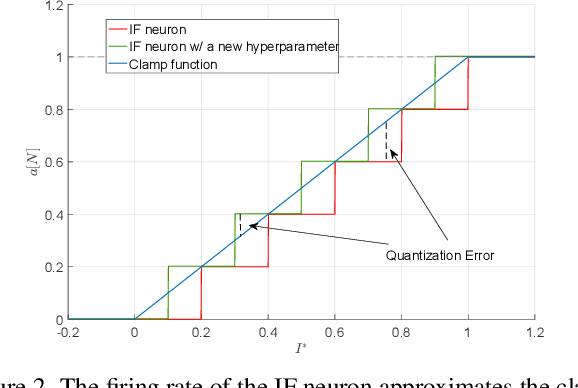
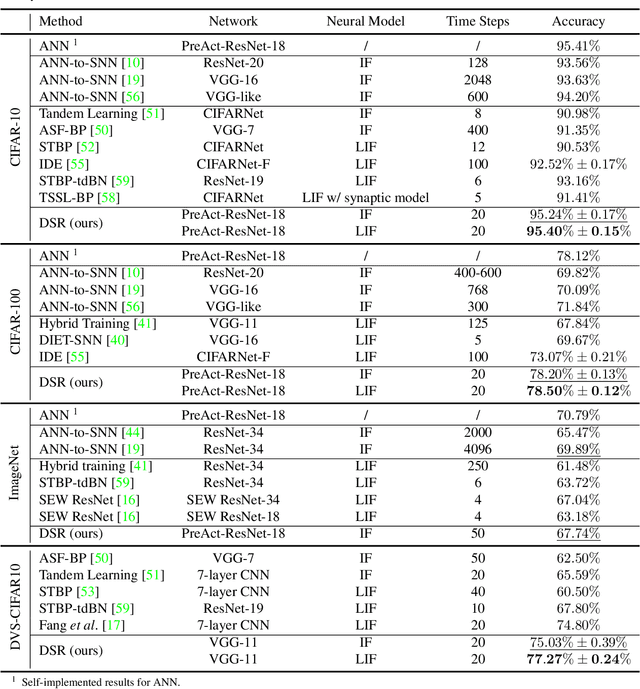
Spiking Neural Network (SNN) is a promising energy-efficient AI model when implemented on neuromorphic hardware. However, it is a challenge to efficiently train SNNs due to their non-differentiability. Most existing methods either suffer from high latency (i.e., long simulation time steps), or cannot achieve as high performance as Artificial Neural Networks (ANNs). In this paper, we propose the Differentiation on Spike Representation (DSR) method, which could achieve high performance that is competitive to ANNs yet with low latency. First, we encode the spike trains into spike representation using (weighted) firing rate coding. Based on the spike representation, we systematically derive that the spiking dynamics with common neural models can be represented as some sub-differentiable mapping. With this viewpoint, our proposed DSR method trains SNNs through gradients of the mapping and avoids the common non-differentiability problem in SNN training. Then we analyze the error when representing the specific mapping with the forward computation of the SNN. To reduce such error, we propose to train the spike threshold in each layer, and to introduce a new hyperparameter for the neural models. With these components, the DSR method can achieve state-of-the-art SNN performance with low latency on both static and neuromorphic datasets, including CIFAR-10, CIFAR-100, ImageNet, and DVS-CIFAR10.