 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepwise Credit Assignment for GRPO on Flow-Matching Models
Mar 30, 2026Flow-GRPO successfully applies reinforcement learning to flow models, but uses uniform credit assignment across all steps. This ignores the temporal structure of diffusion generation: early steps determine composition and content (low-frequency structure), while late steps resolve details and textures (high-frequency details). Moreover, assigning uniform credit based solely on the final image can inadvertently reward suboptimal intermediate steps, especially when errors are corrected later in the diffusion trajectory. We propose Stepwise-Flow-GRPO, which assigns credit based on each step's reward improvement. By leveraging Tweedie's formula to obtain intermediate reward estimates and introducing gain-based advantages, our method achieves superior sample efficiency and faster convergence. We also introduce a DDIM-inspired SDE that improves reward quality while preserving stochasticity for policy gradients.
Antidistillation Fingerprinting
Feb 03, 2026Model distillation enables efficient emulation of frontier large language models (LLMs), creating a need for robust mechanisms to detect when a third-party student model has trained on a teacher model's outputs. However, existing fingerprinting techniques that could be used to detect such distillation rely on heuristic perturbations that impose a steep trade-off between generation quality and fingerprinting strength, often requiring significant degradation of utility to ensure the fingerprint is effectively internalized by the student. We introduce antidistillation fingerprinting (ADFP), a principled approach that aligns the fingerprinting objective with the student's learning dynamics. Building upon the gradient-based framework of antidistillation sampling, ADFP utilizes a proxy model to identify and sample tokens that directly maximize the expected detectability of the fingerprint in the student after fine-tuning, rather than relying on the incidental absorption of the un-targeted biases of a more naive watermark. Experiments on GSM8K and OASST1 benchmarks demonstrate that ADFP achieves a significant Pareto improvement over state-of-the-art baselines, yielding stronger detection confidence with minimal impact on utility, even when the student model's architecture is unknown.
Safety Pretraining: Toward the Next Generation of Safe AI
Apr 23, 2025As large language models (LLMs) are increasingly deployed in high-stakes settings, the risk of generating harmful or toxic content remains a central challenge. Post-hoc alignment methods are brittle: once unsafe patterns are learned during pretraining, they are hard to remove. We present a data-centric pretraining framework that builds safety into the model from the start. Our contributions include: (i) a safety classifier trained on 10,000 GPT-4 labeled examples, used to filter 600B tokens; (ii) the largest synthetic safety dataset to date (100B tokens) generated via recontextualization of harmful web data; (iii) RefuseWeb and Moral Education datasets that convert harmful prompts into refusal dialogues and web-style educational material; (iv) Harmfulness-Tag annotations injected during pretraining to flag unsafe content and steer away inference from harmful generations; and (v) safety evaluations measuring base model behavior before instruction tuning. Our safety-pretrained models reduce attack success rates from 38.8% to 8.4% with no performance degradation on standard LLM safety benchmarks.
Not All Rollouts are Useful: Down-Sampling Rollouts in LLM Reinforcement Learning
Apr 18, 2025Reinforcement learning (RL) has emerged as a powerful paradigm for enhancing reasoning capabilities in large language models, but faces a fundamental asymmetry in computation and memory requirements: inference is embarrassingly parallel with a minimal memory footprint, while policy updates require extensive synchronization and are memory-intensive. To address this asymmetry, we introduce PODS (Policy Optimization with Down-Sampling), a framework that strategically decouples these phases by generating numerous rollouts in parallel but updating only on an informative subset. Within this framework, we develop max-variance down-sampling, a theoretically motivated method that selects rollouts with maximally diverse reward signals. We prove that this approach has an efficient algorithmic solution, and empirically demonstrate that GRPO with PODS using max-variance down-sampling achieves superior performance over standard GRPO on the GSM8K benchmark.
Antidistillation Sampling
Apr 17, 2025Frontier models that generate extended reasoning traces inadvertently produce rich token sequences that can facilitate model distillation. Recognizing this vulnerability, model owners may seek sampling strategies that limit the effectiveness of distillation without compromising model performance. \emph{Antidistillation sampling} provides exactly this capability. By strategically modifying a model's next-token probability distribution, antidistillation sampling poisons reasoning traces, rendering them significantly less effective for distillation while preserving the model's practical utility. For further details, see https://antidistillation.com.
Diffusing Differentiable Representations
Dec 09, 2024



We introduce a novel, training-free method for sampling differentiable representations (diffreps) using pretrained diffusion models. Rather than merely mode-seeking, our method achieves sampling by "pulling back" the dynamics of the reverse-time process--from the image space to the diffrep parameter space--and updating the parameters according to this pulled-back process. We identify an implicit constraint on the samples induced by the diffrep and demonstrate that addressing this constraint significantly improves the consistency and detail of the generated objects. Our method yields diffreps with substantially improved quality and diversity for images, panoramas, and 3D NeRFs compared to existing techniques. Our approach is a general-purpose method for sampling diffreps, expanding the scope of problems that diffusion models can tackle.
Deep Equilibrium Optical Flow Estimation
Apr 18, 2022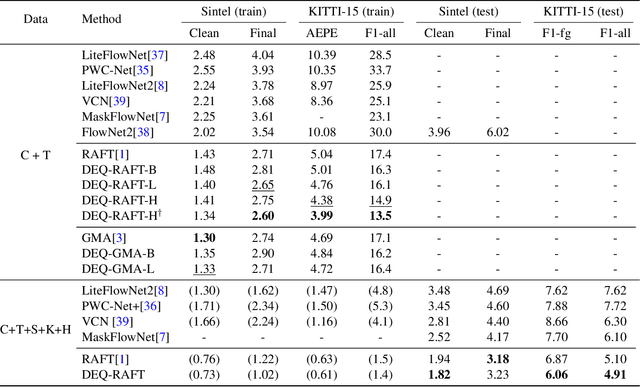
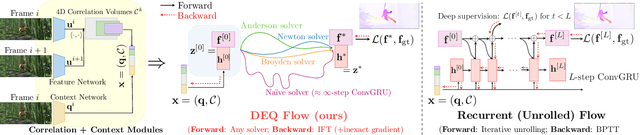
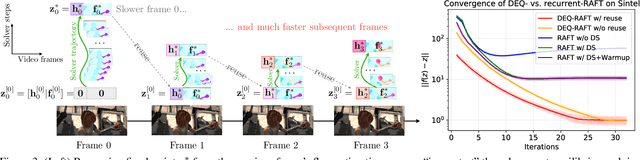
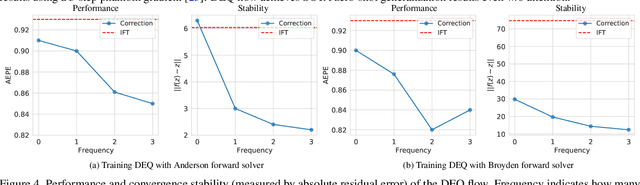
Many recent state-of-the-art (SOTA) optical flow models use finite-step recurrent update operations to emulate traditional algorithms by encouraging iterative refinements toward a stable flow estimation. However, these RNNs impose large computation and memory overheads, and are not directly trained to model such stable estimation. They can converge poorly and thereby suffer from performance degradation. To combat these drawbacks, we propose deep equilibrium (DEQ) flow estimators, an approach that directly solves for the flow as the infinite-level fixed point of an implicit layer (using any black-box solver), and differentiates through this fixed point analytically (thus requiring $O(1)$ training memory). This implicit-depth approach is not predicated on any specific model, and thus can be applied to a wide range of SOTA flow estimation model designs. The use of these DEQ flow estimators allows us to compute the flow faster using, e.g., fixed-point reuse and inexact gradients, consumes $4\sim6\times$ times less training memory than the recurrent counterpart, and achieves better results with the same computation budget. In addition, we propose a novel, sparse fixed-point correction scheme to stabilize our DEQ flow estimators, which addresses a longstanding challenge for DEQ models in general. We test our approach in various realistic settings and show that it improves SOTA methods on Sintel and KITTI datasets with substantially better computational and memory efficiency.
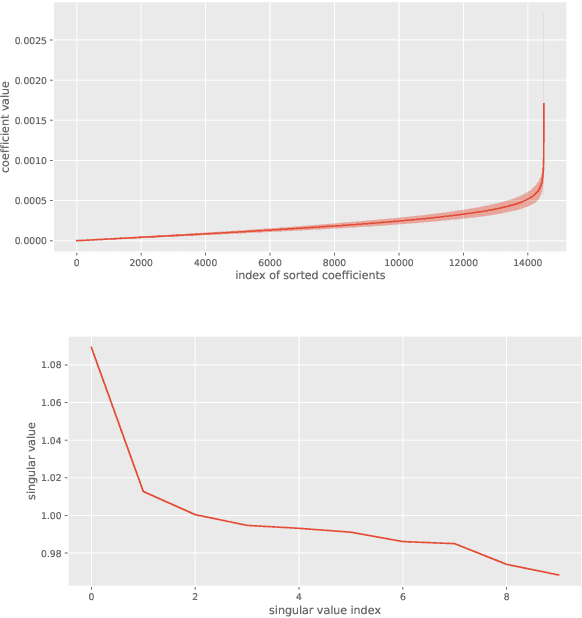
NAS-Bench-x11 and the Power of Learning Curves
Nov 05, 2021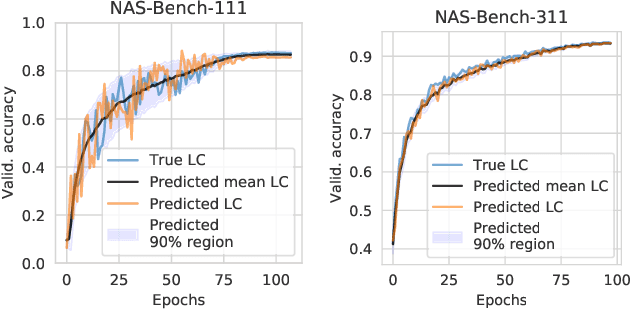
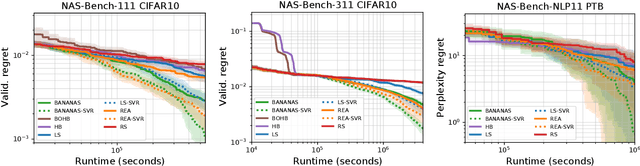
While early research in neural architecture search (NAS) required extreme computational resources, the recent releases of tabular and surrogate benchmarks have greatly increased the speed and reproducibility of NAS research. However, two of the most popular benchmarks do not provide the full training information for each architecture. As a result, on these benchmarks it is not possible to run many types of multi-fidelity techniques, such as learning curve extrapolation, that require evaluating architectures at arbitrary epochs. In this work, we present a method using singular value decomposition and noise modeling to create surrogate benchmarks, NAS-Bench-111, NAS-Bench-311, and NAS-Bench-NLP11, that output the full training information for each architecture, rather than just the final validation accuracy. We demonstrate the power of using the full training information by introducing a learning curve extrapolation framework to modify single-fidelity algorithms, showing that it leads to improvements over popular single-fidelity algorithms which claimed to be state-of-the-art upon release. Our code and pretrained models are available at https://github.com/automl/nas-bench-x11.
A Study on Encodings for Neural Architecture Search
Jul 09, 2020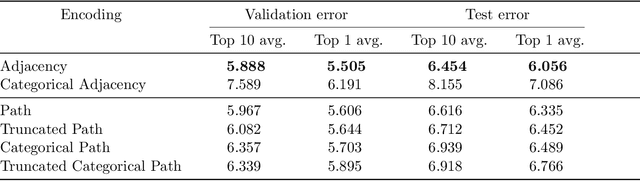
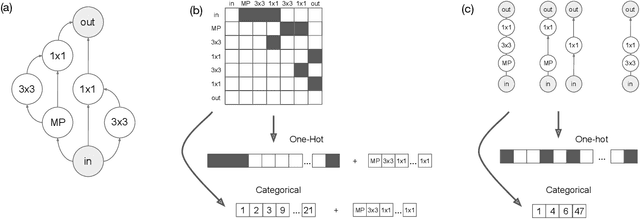
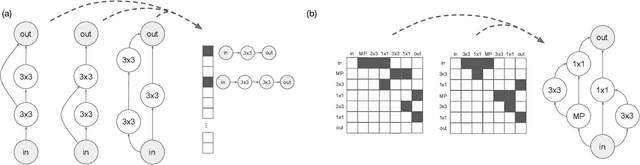
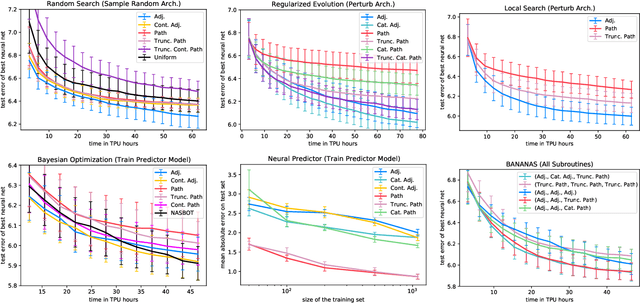
Neural architecture search (NAS) has been extensively studied in the past few years. A popular approach is to represent each neural architecture in the search space as a directed acyclic graph (DAG), and then search over all DAGs by encoding the adjacency matrix and list of operations as a set of hyperparameters. Recent work has demonstrated that even small changes to the way each architecture is encoded can have a significant effect on the performance of NAS algorithms. In this work, we present the first formal study on the effect of architecture encodings for NAS, including a theoretical grounding and an empirical study. First we formally define architecture encodings and give a theoretical characterization on the scalability of the encodings we study Then we identify the main encoding-dependent subroutines which NAS algorithms employ, running experiments to show which encodings work best with each subroutine for many popular algorithms. The experiments act as an ablation study for prior work, disentangling the algorithmic and encoding-based contributions, as well as a guideline for future work. Our results demonstrate that NAS encodings are an important design decision which can have a significant impact on overall performance. Our code is available at https://github.com/naszilla/nas-encodings.
Post-Hoc Methods for Debiasing Neural Networks
Jun 15, 2020
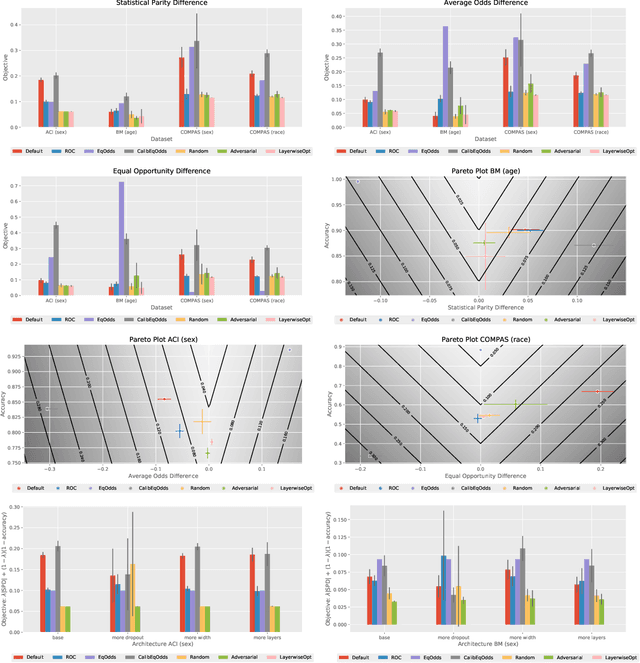
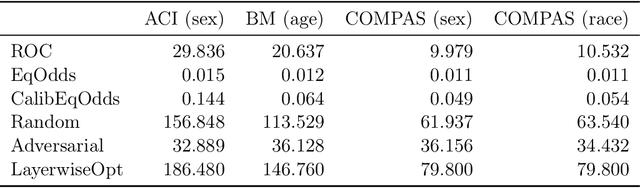
As deep learning models become tasked with more and more decisions that impact human lives, such as hiring, criminal recidivism, and loan repayment, bias is becoming a growing concern. This has led to dozens of definitions of fairness and numerous algorithmic techniques to improve the fairness of neural networks. Most debiasing algorithms require retraining a neural network from scratch, however, this is not feasible in many applications, especially when the model takes days to train or when the full training dataset is no longer available. In this work, we present a study on post-hoc methods for debiasing neural networks. First we study the nature of the problem, showing that the difficulty of post-hoc debiasing is highly dependent on the initial conditions of the original model. Then we define three new fine-tuning techniques: random perturbation, layer-wise optimization, and adversarial fine-tuning. All three techniques work for any group fairness constraint. We give a comparison with six algorithms - three popular post-processing debiasing algorithms and our three proposed methods - across three datasets and three popular bias measures. We show that no post-hoc debiasing technique dominates all others, and we identify settings in which each algorithm performs the best. Our code is available at https://github.com/realityengines/post_hoc_debiasing.