 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Does Hierarchy Work So Well in Reinforcement Learning?
Sep 23, 2019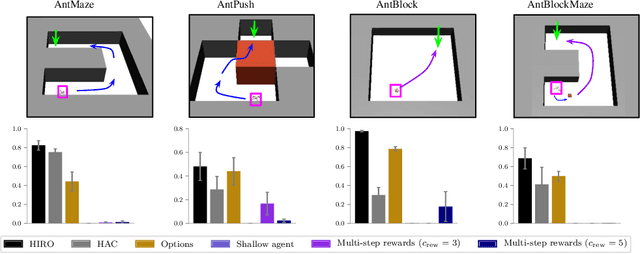
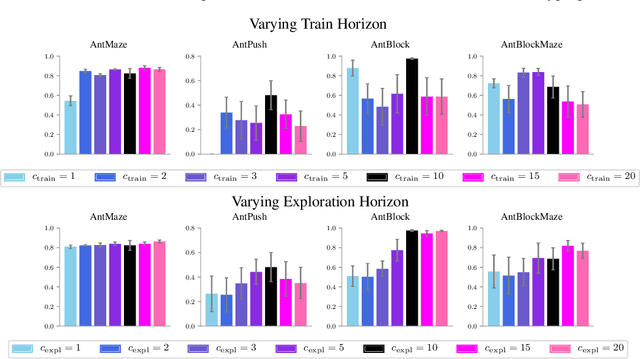
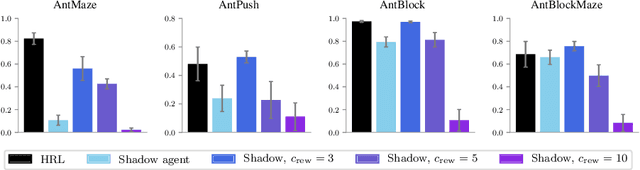
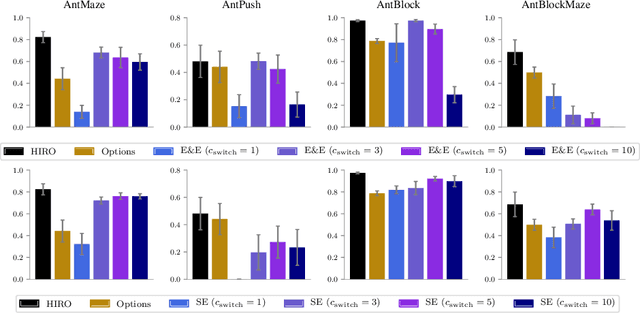
Hierarchical reinforcement learning has demonstrated significant success at solving difficult reinforcement learning (RL) tasks. Previous works have motivated the use of hierarchy by appealing to a number of intuitive benefits, including learning over temporally extended transitions, exploring over temporally extended periods, and training and exploring in a more semantically meaningful action space, among others. However, in fully observed, Markovian settings, it is not immediately clear why hierarchical RL should provide benefits over standard "shallow" RL architectures. In this work, we isolate and evaluate the claimed benefits of hierarchical RL on a suite of tasks encompassing locomotion, navigation, and manipulation. Surprisingly, we find that most of the observed benefits of hierarchy can be attributed to improved exploration, as opposed to easier policy learning or imposed hierarchical structures. Given this insight, we present exploration techniques inspired by hierarchy that achieve performance competitive with hierarchical RL while at the same time being much simpler to use and implement.
Scaled Autonomy: Enabling Human Operators to Control Robot Fleets
Sep 22, 2019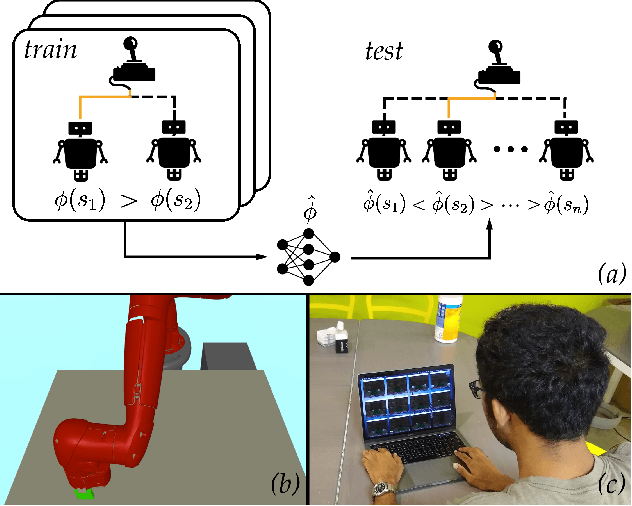
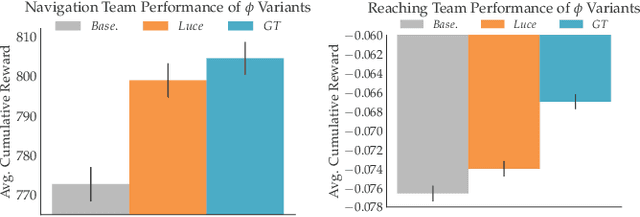
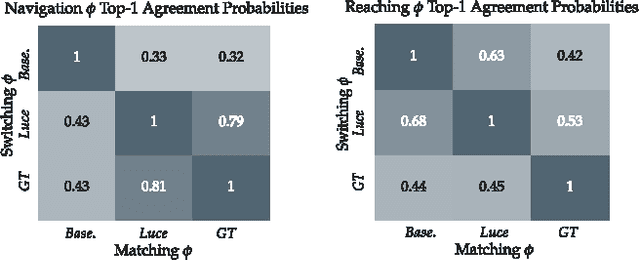
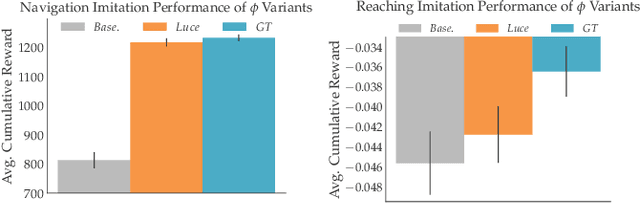
Autonomous robots often encounter challenging situations where their control policies fail and an expert human operator must briefly intervene, e.g., through teleoperation. In settings where multiple robots act in separate environments, a single human operator can manage a fleet of robots by identifying and teleoperating one robot at any given time. The key challenge is that users have limited attention: as the number of robots increases, users lose the ability to decide which robot requires teleoperation the most. Our goal is to automate this decision, thereby enabling users to supervise more robots than their attention would normally allow for. Our insight is that we can model the user's choice of which robot to control as an approximately optimal decision that maximizes the user's utility function. We learn a model of the user's preferences from observations of the user's choices in easy settings with a few robots, and use it in challenging settings with more robots to automatically identify which robot the user would most likely choose to control, if they were able to evaluate the states of all robots at all times. We run simulation experiments and a user study with twelve participants that show our method can be used to assist users in performing a navigation task and manipulator reaching task.
Meta-Learning with Implicit Gradients
Sep 10, 2019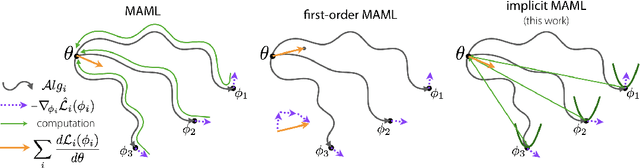

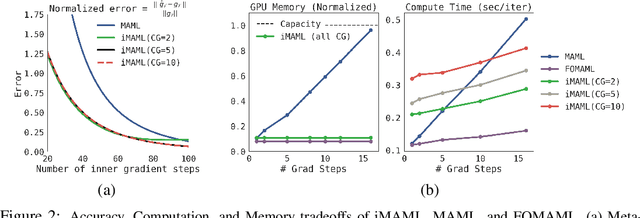
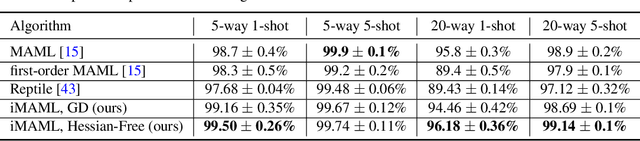
A core capability of intelligent systems is the ability to quickly learn new tasks by drawing on prior experience. Gradient (or optimization) based meta-learning has recently emerged as an effective approach for few-shot learning. In this formulation, meta-parameters are learned in the outer loop, while task-specific models are learned in the inner-loop, by using only a small amount of data from the current task. A key challenge in scaling these approaches is the need to differentiate through the inner loop learning process, which can impose considerable computational and memory burdens. By drawing upon implicit differentiation, we develop the implicit MAML algorithm, which depends only on the solution to the inner level optimization and not the path taken by the inner loop optimizer. This effectively decouples the meta-gradient computation from the choice of inner loop optimizer. As a result, our approach is agnostic to the choice of inner loop optimizer and can gracefully handle many gradient steps without vanishing gradients or memory constraints. Theoretically, we prove that implicit MAML can compute accurate meta-gradients with a memory footprint that is, up to small constant factors, no more than that which is required to compute a single inner loop gradient and at no overall increase in the total computational cost. Experimentally, we show that these benefits of implicit MAML translate into empirical gains on few-shot image recognition benchmarks.
Dynamical Distance Learning for Unsupervised and Semi-Supervised Skill Discovery
Jul 18, 2019
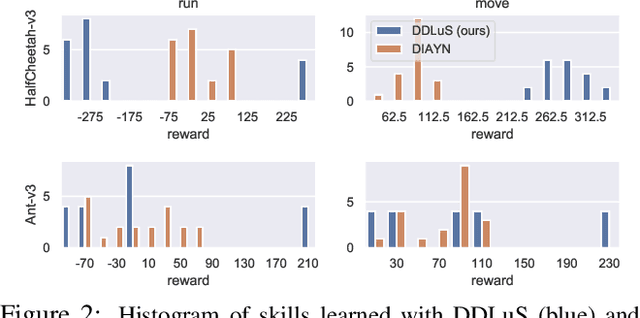
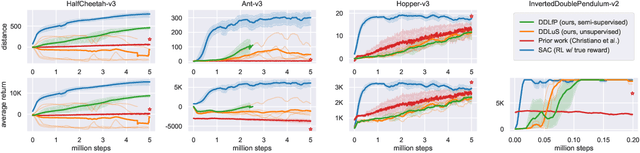
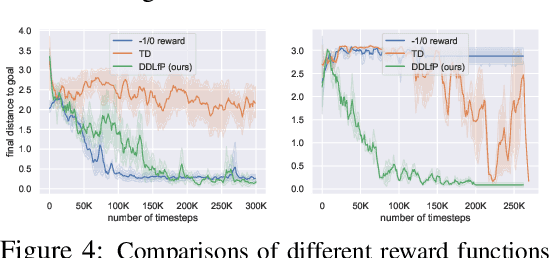
Reinforcement learning requires manual specification of a reward function to learn a task. While in principle this reward function only needs to specify the task goal, in practice reinforcement learning can be very time-consuming or even infeasible unless the reward function is shaped so as to provide a smooth gradient towards a successful outcome. This shaping is difficult to specify by hand, particularly when the task is learned from raw observations, such as images. In this paper, we study how we can automatically learn dynamical distances: a measure of the expected number of time steps to reach a given goal state from any other state. These dynamical distances can be used to provide well-shaped reward functions for reaching new goals, making it possible to learn complex tasks efficiently. We also show that dynamical distances can be used in a semi-supervised regime, where unsupervised interaction with the environment is used to learn the dynamical distances, while a small amount of preference supervision is used to determine the task goal, without any manually engineered reward function or goal examples. We evaluate our method both in simulation and on a real-world robot. We show that our method can learn locomotion skills in simulation without any supervision. We also show that it can learn to turn a valve with a real-world 9-DoF hand, using raw image observations and ten preference labels, without any other supervision. Videos of the learned skills can be found on the project website: https://sites.google.com/view/skills-via-distance-learning.
Dynamics-Aware Unsupervised Discovery of Skills
Jul 02, 2019
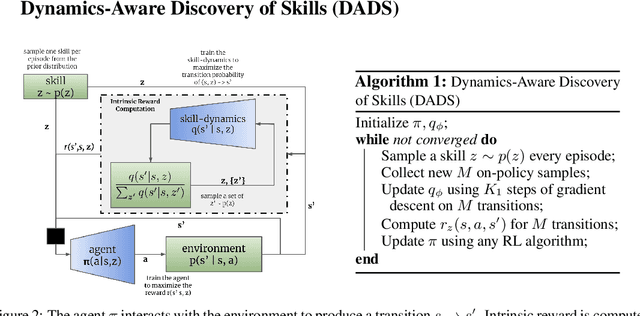
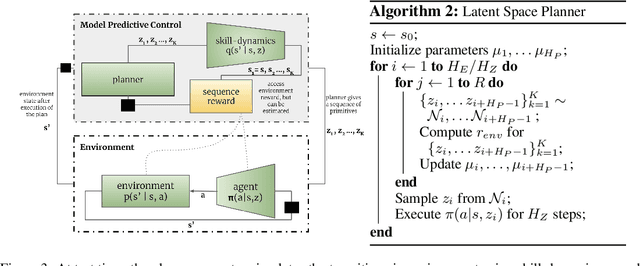

Conventionally, model-based reinforcement learning (MBRL) aims to learn a global model for the dynamics of the environment. A good model can potentially enable planning algorithms to generate a large variety of behaviors and solve diverse tasks. However, learning an accurate model for complex dynamical systems is difficult, and even then, the model might not generalize well outside the distribution of states on which it was trained. In this work, we combine model-based learning with model-free learning of primitives that make model-based planning easy. To that end, we aim to answer the question: how can we discover skills whose outcomes are easy to predict? We propose an unsupervised learning algorithm, Dynamics-Aware Discovery of Skills (DADS), which simultaneously discovers predictable behaviors and learns their dynamics. Our method can leverage continuous skill spaces, theoretically, allowing us to learn infinitely many behaviors even for high-dimensional state-spaces. We demonstrate that zero-shot planning in the learned latent space significantly outperforms standard MBRL and model-free goal-conditioned RL, can handle sparse-reward tasks, and substantially improves over prior hierarchical RL methods for unsupervised skill discovery.
Stochastic Latent Actor-Critic: Deep Reinforcement Learning with a Latent Variable Model
Jul 01, 2019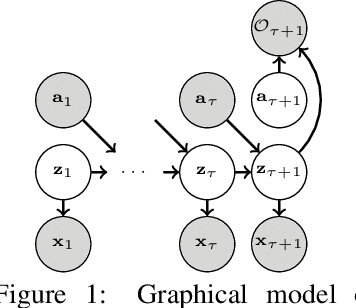
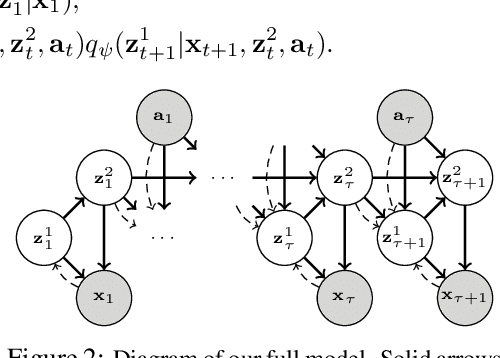

Deep reinforcement learning (RL) algorithms can use high-capacity deep networks to learn directly from image observations. However, these kinds of observation spaces present a number of challenges in practice, since the policy must now solve two problems: a representation learning problem, and a task learning problem. In this paper, we aim to explicitly learn representations that can accelerate reinforcement learning from images. We propose the stochastic latent actor-critic (SLAC) algorithm: a sample-efficient and high-performing RL algorithm for learning policies for complex continuous control tasks directly from high-dimensional image inputs. SLAC learns a compact latent representation space using a stochastic sequential latent variable model, and then learns a critic model within this latent space. By learning a critic within a compact state space, SLAC can learn much more efficiently than standard RL methods. The proposed model improves performance substantially over alternative representations as well, such as variational autoencoders. In fact, our experimental evaluation demonstrates that the sample efficiency of our resulting method is comparable to that of model-based RL methods that directly use a similar type of model for control. Furthermore, our method outperforms both model-free and model-based alternatives in terms of final performance and sample efficiency, on a range of difficult image-based control tasks.
Reinforcement Learning with Competitive Ensembles of Information-Constrained Primitives
Jun 25, 2019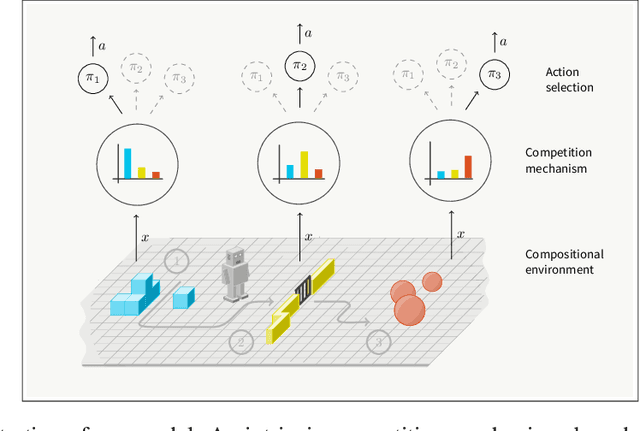

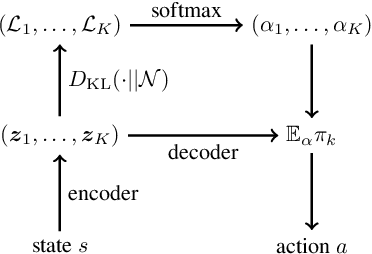
Reinforcement learning agents that operate in diverse and complex environments can benefit from the structured decomposition of their behavior. Often, this is addressed in the context of hierarchical reinforcement learning, where the aim is to decompose a policy into lower-level primitives or options, and a higher-level meta-policy that triggers the appropriate behaviors for a given situation. However, the meta-policy must still produce appropriate decisions in all states. In this work, we propose a policy design that decomposes into primitives, similarly to hierarchical reinforcement learning, but without a high-level meta-policy. Instead, each primitive can decide for themselves whether they wish to act in the current state. We use an information-theoretic mechanism for enabling this decentralized decision: each primitive chooses how much information it needs about the current state to make a decision and the primitive that requests the most information about the current state acts in the world. The primitives are regularized to use as little information as possible, which leads to natural competition and specialization. We experimentally demonstrate that this policy architecture improves over both flat and hierarchical policies in terms of generalization.
Off-Policy Evaluation via Off-Policy Classification
Jun 20, 2019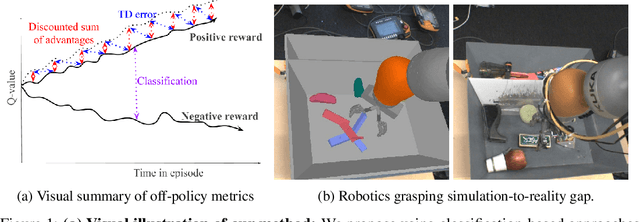

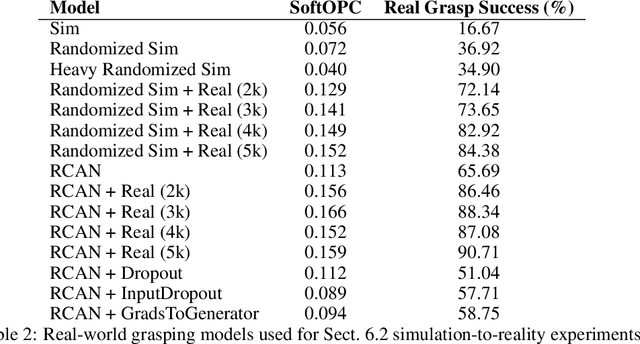

In this work, we consider the problem of model selection for deep reinforcement learning (RL) in real-world environments. Typically, the performance of deep RL algorithms is evaluated via on-policy interactions with the target environment. However, comparing models in a real-world environment for the purposes of early stopping or hyperparameter tuning is costly and often practically infeasible. This leads us to examine off-policy policy evaluation (OPE) in such settings. We focus on OPE for value-based methods, which are of particular interest in deep RL, with applications like robotics, where off-policy algorithms based on Q-function estimation can often attain better sample complexity than direct policy optimization. Existing OPE metrics either rely on a model of the environment, or the use of importance sampling (IS) to correct for the data being off-policy. However, for high-dimensional observations, such as images, models of the environment can be difficult to fit and value-based methods can make IS hard to use or even ill-conditioned, especially when dealing with continuous action spaces. In this paper, we focus on the specific case of MDPs with continuous action spaces and sparse binary rewards, which is representative of many important real-world applications. We propose an alternative metric that relies on neither models nor IS, by framing OPE as a positive-unlabeled (PU) classification problem with the Q-function as the decision function. We experimentally show that this metric outperforms baselines on a number of tasks. Most importantly, it can reliably predict the relative performance of different policies in a number of generalization scenarios, including the transfer to the real-world of policies trained in simulation for an image-based robotic manipulation task.
When to Trust Your Model: Model-Based Policy Optimization
Jun 19, 2019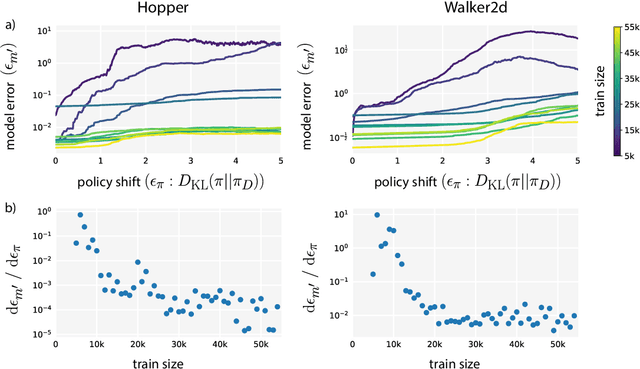

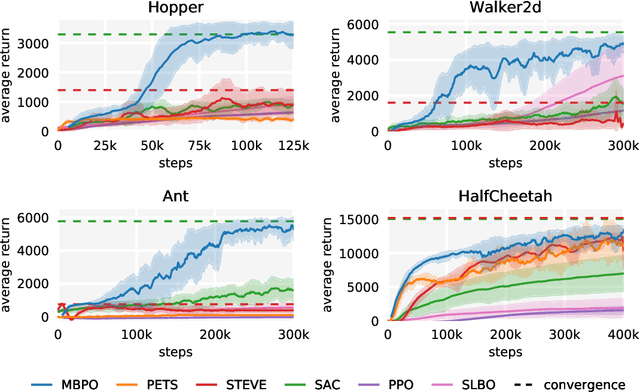
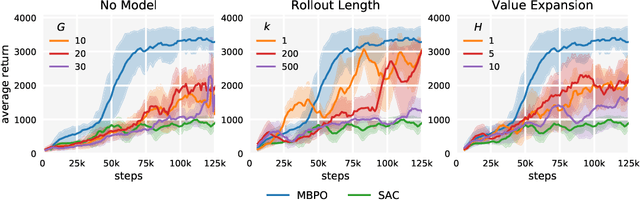
Designing effective model-based reinforcement learning algorithms is difficult because the ease of data generation must be weighed against the bias of model-generated data. In this paper, we study the role of model usage in policy optimization both theoretically and empirically. We first formulate and analyze a model-based reinforcement learning algorithm with a guarantee of monotonic improvement at each step. In practice, this analysis is overly pessimistic and suggests that real off-policy data is always preferable to model-generated on-policy data, but we show that an empirical estimate of model generalization can be incorporated into such analysis to justify model usage. Motivated by this analysis, we then demonstrate that a simple procedure of using short model-generated rollouts branched from real data has the benefits of more complicated model-based algorithms without the usual pitfalls. In particular, this approach surpasses the sample efficiency of prior model-based methods, matches the asymptotic performance of the best model-free algorithms, and scales to horizons that cause other model-based methods to fail entirely.
SQIL: Imitation Learning via Regularized Behavioral Cloning
Jun 14, 2019
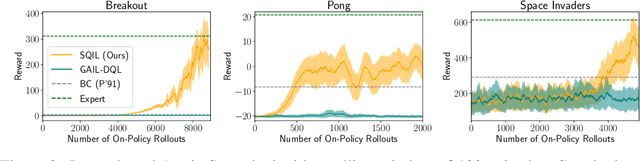
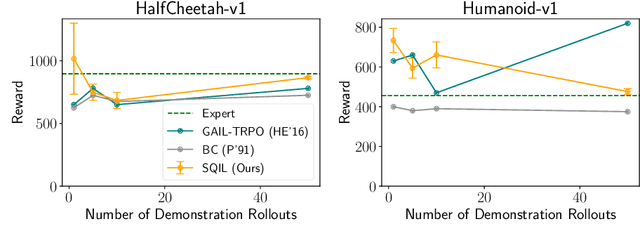

Learning to imitate expert behavior given action demonstrations containing high-dimensional, continuous observations and unknown dynamics is a difficult problem in robotic control. Simple approaches based on behavioral cloning (BC) suffer from state distribution shift, while more complex methods that generalize to out-of-distribution states can be difficult to use, since they typically involve adversarial optimization. We propose an alternative that combines the simplicity of BC with the robustness of adversarial imitation learning. The key insight is that under the maximum entropy model of expert behavior, BC corresponds to fitting a soft Q function that maximizes the likelihood of observed actions. This perspective suggests a way to regularize BC so that it generalizes to out-of-distribution states: combine the standard maximum-likelihood objective with a penalty on the soft Bellman error of the soft Q function. We show that this penalty term gives the agent an incentive to take actions that lead it back to demonstrated states when it encounters new states. Experiments show that our method outperforms BC and GAIL on a variety of image-based and low-dimensional environments in Box2D, Atari, and MuJoCo.