 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolynomial Neural Fields for Subband Decomposition and Manipulation
Feb 09, 2023



Neural fields have emerged as a new paradigm for representing signals, thanks to their ability to do it compactly while being easy to optimize. In most applications, however, neural fields are treated like black boxes, which precludes many signal manipulation tasks. In this paper, we propose a new class of neural fields called polynomial neural fields (PNFs). The key advantage of a PNF is that it can represent a signal as a composition of a number of manipulable and interpretable components without losing the merits of neural fields representation. We develop a general theoretical framework to analyze and design PNFs. We use this framework to design Fourier PNFs, which match state-of-the-art performance in signal representation tasks that use neural fields. In addition, we empirically demonstrate that Fourier PNFs enable signal manipulation applications such as texture transfer and scale-space interpolation. Code is available at https://github.com/stevenygd/PNF.
Does unsupervised grammar induction need pixels?
Dec 20, 2022Are extralinguistic signals such as image pixels crucial for inducing constituency grammars? While past work has shown substantial gains from multimodal cues, we investigate whether such gains persist in the presence of rich information from large language models (LLMs). We find that our approach, LLM-based C-PCFG (LC-PCFG), outperforms previous multi-modal methods on the task of unsupervised constituency parsing, achieving state-of-the-art performance on a variety of datasets. Moreover, LC-PCFG results in an over 50% reduction in parameter count, and speedups in training time of 1.7x for image-aided models and more than 5x for video-aided models, respectively. These results challenge the notion that extralinguistic signals such as image pixels are needed for unsupervised grammar induction, and point to the need for better text-only baselines in evaluating the need of multi-modality for the task.
PyTorch Adapt
Nov 28, 2022

PyTorch Adapt is a library for domain adaptation, a type of machine learning algorithm that re-purposes existing models to work in new domains. It is a fully-featured toolkit, allowing users to create a complete train/test pipeline in a few lines of code. It is also modular, so users can import just the parts they need, and not worry about being locked into a framework. One defining feature of this library is its customizability. In particular, complex training algorithms can be easily modified and combined, thanks to a system of composable, lazily-evaluated hooks. In this technical report, we explain in detail these features and the overall design of the library. Code is available at https://www.github.com/KevinMusgrave/pytorch-adapt
Assessing Neural Network Robustness via Adversarial Pivotal Tuning
Nov 17, 2022The ability to assess the robustness of image classifiers to a diverse set of manipulations is essential to their deployment in the real world. Recently, semantic manipulations of real images have been considered for this purpose, as they may not arise using standard adversarial settings. However, such semantic manipulations are often limited to style, color or attribute changes. While expressive, these manipulations do not consider the full capacity of a pretrained generator to affect adversarial image manipulations. In this work, we aim at leveraging the full capacity of a pretrained image generator to generate highly detailed, diverse and photorealistic image manipulations. Inspired by recent GAN-based image inversion methods, we propose a method called Adversarial Pivotal Tuning (APT). APT first finds a pivot latent space input to a pretrained generator that best reconstructs an input image. It then adjusts the weights of the generator to create small, but semantic, manipulations which fool a pretrained classifier. Crucially, APT changes both the input and the weights of the pretrained generator, while preserving its expressive latent editing capability, thus allowing the use of its full capacity in creating semantic adversarial manipulations. We demonstrate that APT generates a variety of semantic image manipulations, which preserve the input image class, but which fool a variety of pretrained classifiers. We further demonstrate that classifiers trained to be robust to other robustness benchmarks, are not robust to our generated manipulations and propose an approach to improve the robustness towards our generated manipulations. Code available at: https://captaine.github.io/apt/
Benchmarking Validation Methods for Unsupervised Domain Adaptation
Aug 15, 2022



This paper compares and ranks 11 UDA validation methods. Validators estimate model accuracy, which makes them an essential component of any UDA train-test pipeline. We rank these validators to indicate which of them are most useful for the purpose of selecting optimal models, checkpoints, and hyperparameters. In addition, we propose and compare new effective validators and significantly improved versions of existing validators. To the best of our knowledge, this large-scale benchmark study is the first of its kind in the UDA field.
Exploring Fine-Grained Audiovisual Categorization with the SSW60 Dataset
Jul 21, 2022
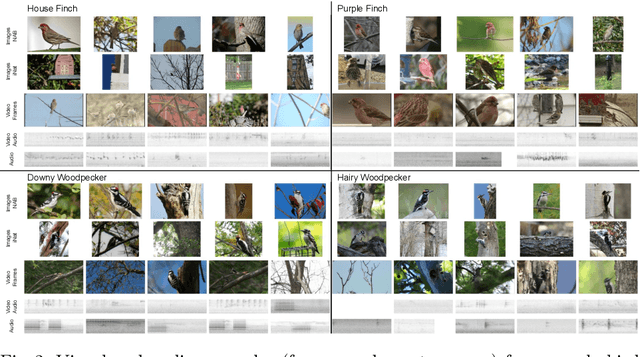
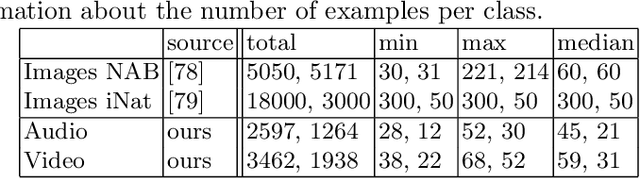
We present a new benchmark dataset, Sapsucker Woods 60 (SSW60), for advancing research on audiovisual fine-grained categorization. While our community has made great strides in fine-grained visual categorization on images, the counterparts in audio and video fine-grained categorization are relatively unexplored. To encourage advancements in this space, we have carefully constructed the SSW60 dataset to enable researchers to experiment with classifying the same set of categories in three different modalities: images, audio, and video. The dataset covers 60 species of birds and is comprised of images from existing datasets, and brand new, expert-curated audio and video datasets. We thoroughly benchmark audiovisual classification performance and modality fusion experiments through the use of state-of-the-art transformer methods. Our findings show that performance of audiovisual fusion methods is better than using exclusively image or audio based methods for the task of video classification. We also present interesting modality transfer experiments, enabled by the unique construction of SSW60 to encompass three different modalities. We hope the SSW60 dataset and accompanying baselines spur research in this fascinating area.
On Label Granularity and Object Localization
Jul 20, 2022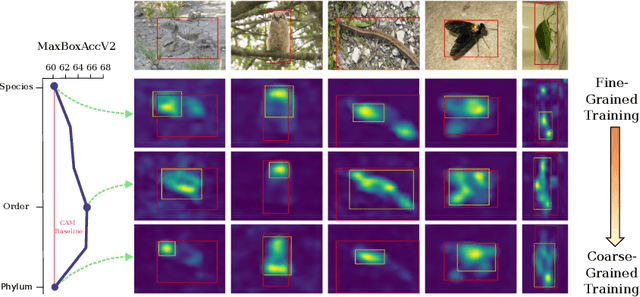

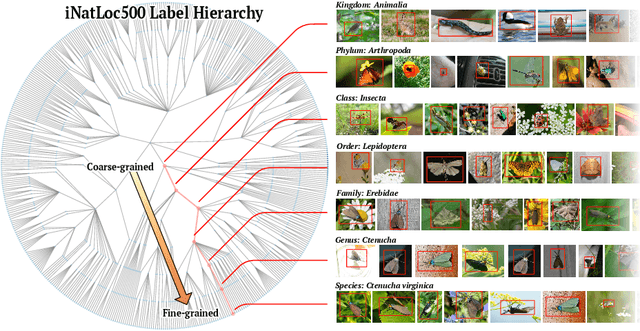
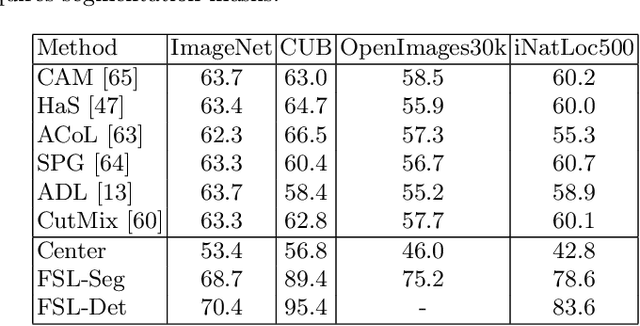
Weakly supervised object localization (WSOL) aims to learn representations that encode object location using only image-level category labels. However, many objects can be labeled at different levels of granularity. Is it an animal, a bird, or a great horned owl? Which image-level labels should we use? In this paper we study the role of label granularity in WSOL. To facilitate this investigation we introduce iNatLoc500, a new large-scale fine-grained benchmark dataset for WSOL. Surprisingly, we find that choosing the right training label granularity provides a much larger performance boost than choosing the best WSOL algorithm. We also show that changing the label granularity can significantly improve data efficiency.
Multimodal Open-Vocabulary Video Classification via Pre-Trained Vision and Language Models
Jul 15, 2022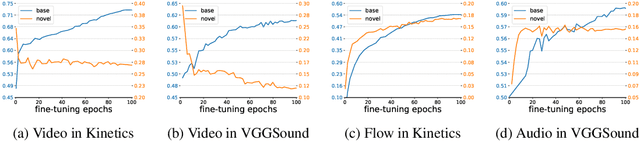
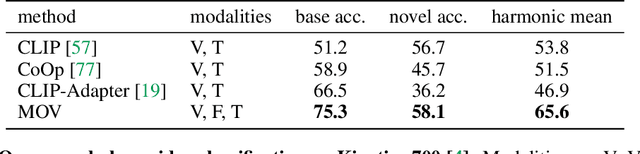
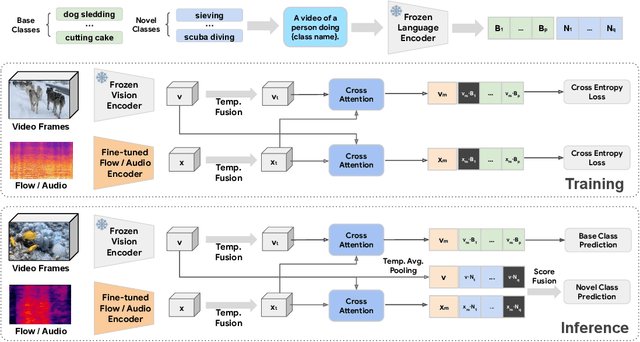
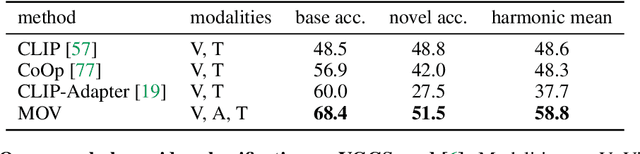
Utilizing vision and language models (VLMs) pre-trained on large-scale image-text pairs is becoming a promising paradigm for open-vocabulary visual recognition. In this work, we extend this paradigm by leveraging motion and audio that naturally exist in video. We present \textbf{MOV}, a simple yet effective method for \textbf{M}ultimodal \textbf{O}pen-\textbf{V}ocabulary video classification. In MOV, we directly use the vision encoder from pre-trained VLMs with minimal modifications to encode video, optical flow and audio spectrogram. We design a cross-modal fusion mechanism to aggregate complimentary multimodal information. Experiments on Kinetics-700 and VGGSound show that introducing flow or audio modality brings large performance gains over the pre-trained VLM and existing methods. Specifically, MOV greatly improves the accuracy on base classes, while generalizes better on novel classes. MOV achieves state-of-the-art results on UCF and HMDB zero-shot video classification benchmarks, significantly outperforming both traditional zero-shot methods and recent methods based on VLMs. Code and models will be released.
Text-Driven Stylization of Video Objects
Jun 27, 2022
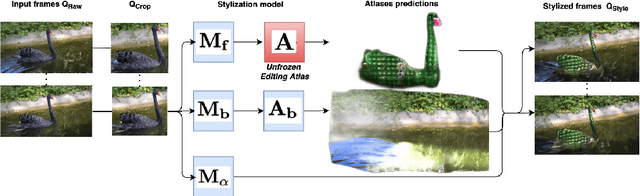
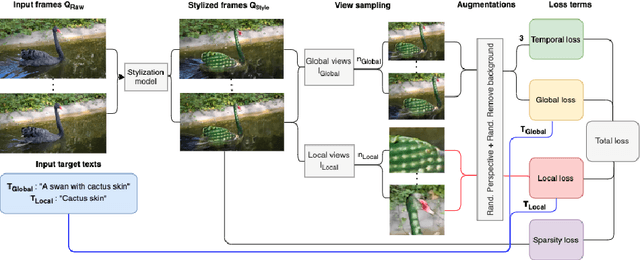

We tackle the task of stylizing video objects in an intuitive and semantic manner following a user-specified text prompt. This is a challenging task as the resulting video must satisfy multiple properties: (1) it has to be temporally consistent and avoid jittering or similar artifacts, (2) the resulting stylization must preserve both the global semantics of the object and its fine-grained details, and (3) it must adhere to the user-specified text prompt. To this end, our method stylizes an object in a video according to two target texts. The first target text prompt describes the global semantics and the second target text prompt describes the local semantics. To modify the style of an object, we harness the representational power of CLIP to get a similarity score between (1) the local target text and a set of local stylized views, and (2) a global target text and a set of stylized global views. We use a pretrained atlas decomposition network to propagate the edits in a temporally consistent manner. We demonstrate that our method can generate consistent style changes over time for a variety of objects and videos, that adhere to the specification of the target texts. We also show how varying the specificity of the target texts and augmenting the texts with a set of prefixes results in stylizations with different levels of detail. Full results are given on our project webpage: https://sloeschcke.github.io/Text-Driven-Stylization-of-Video-Objects/
Volumetric Disentanglement for 3D Scene Manipulation
Jun 06, 2022
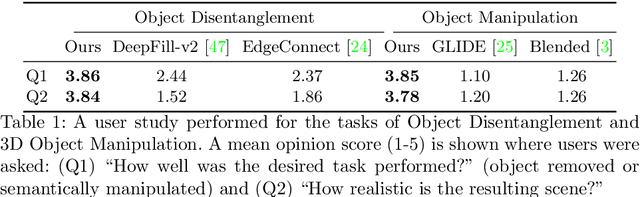
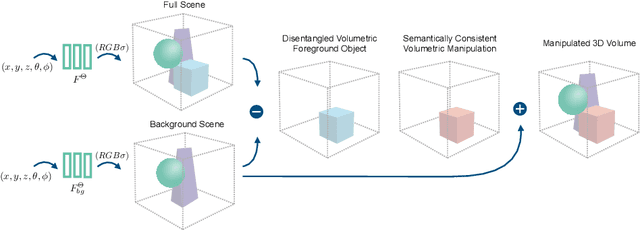
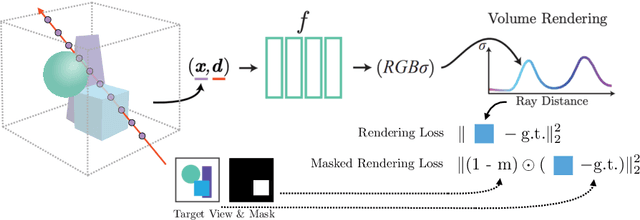
Recently, advances in differential volumetric rendering enabled significant breakthroughs in the photo-realistic and fine-detailed reconstruction of complex 3D scenes, which is key for many virtual reality applications. However, in the context of augmented reality, one may also wish to effect semantic manipulations or augmentations of objects within a scene. To this end, we propose a volumetric framework for (i) disentangling or separating, the volumetric representation of a given foreground object from the background, and (ii) semantically manipulating the foreground object, as well as the background. Our framework takes as input a set of 2D masks specifying the desired foreground object for training views, together with the associated 2D views and poses, and produces a foreground-background disentanglement that respects the surrounding illumination, reflections, and partial occlusions, which can be applied to both training and novel views. Our method enables the separate control of pixel color and depth as well as 3D similarity transformations of both the foreground and background objects. We subsequently demonstrate the applicability of our framework on a number of downstream manipulation tasks including object camouflage, non-negative 3D object inpainting, 3D object translation, 3D object inpainting, and 3D text-based object manipulation. Full results are given in our project webpage at https://sagiebenaim.github.io/volumetric-disentanglement/