 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToon3D: Seeing Cartoons from a New Perspective
May 17, 2024In this work, we recover the underlying 3D structure of non-geometrically consistent scenes. We focus our analysis on hand-drawn images from cartoons and anime. Many cartoons are created by artists without a 3D rendering engine, which means that any new image of a scene is hand-drawn. The hand-drawn images are usually faithful representations of the world, but only in a qualitative sense, since it is difficult for humans to draw multiple perspectives of an object or scene 3D consistently. Nevertheless, people can easily perceive 3D scenes from inconsistent inputs! In this work, we correct for 2D drawing inconsistencies to recover a plausible 3D structure such that the newly warped drawings are consistent with each other. Our pipeline consists of a user-friendly annotation tool, camera pose estimation, and image deformation to recover a dense structure. Our method warps images to obey a perspective camera model, enabling our aligned results to be plugged into novel-view synthesis reconstruction methods to experience cartoons from viewpoints never drawn before. Our project page is https://toon3d.studio .
Learning to Taste: A Multimodal Wine Dataset
Sep 07, 2023



We present WineSensed, a large multimodal wine dataset for studying the relations between visual perception, language, and flavor. The dataset encompasses 897k images of wine labels and 824k reviews of wines curated from the Vivino platform. It has over 350k unique vintages, annotated with year, region, rating, alcohol percentage, price, and grape composition. We obtained fine-grained flavor annotations on a subset by conducting a wine-tasting experiment with 256 participants who were asked to rank wines based on their similarity in flavor, resulting in more than 5k pairwise flavor distances. We propose a low-dimensional concept embedding algorithm that combines human experience with automatic machine similarity kernels. We demonstrate that this shared concept embedding space improves upon separate embedding spaces for coarse flavor classification (alcohol percentage, country, grape, price, rating) and aligns with the intricate human perception of flavor.
DAC: Detector-Agnostic Spatial Covariances for Deep Local Features
May 20, 2023



Current deep visual local feature detectors do not model the spatial uncertainty of detected features, producing suboptimal results in downstream applications. In this work, we propose two post-hoc covariance estimates that can be plugged into any pretrained deep feature detector: a simple, isotropic covariance estimate that uses the predicted score at a given pixel location, and a full covariance estimate via the local structure tensor of the learned score maps. Both methods are easy to implement and can be applied to any deep feature detector. We show that these covariances are directly related to errors in feature matching, leading to improvements in downstream tasks, including triangulation, solving the perspective-n-point problem and motion-only bundle adjustment. Code is available at https://github.com/javrtg/DAC
Nerfbusters: Removing Ghostly Artifacts from Casually Captured NeRFs
Apr 21, 2023Casually captured Neural Radiance Fields (NeRFs) suffer from artifacts such as floaters or flawed geometry when rendered outside the camera trajectory. Existing evaluation protocols often do not capture these effects, since they usually only assess image quality at every 8th frame of the training capture. To push forward progress in novel-view synthesis, we propose a new dataset and evaluation procedure, where two camera trajectories are recorded of the scene: one used for training, and the other for evaluation. In this more challenging in-the-wild setting, we find that existing hand-crafted regularizers do not remove floaters nor improve scene geometry. Thus, we propose a 3D diffusion-based method that leverages local 3D priors and a novel density-based score distillation sampling loss to discourage artifacts during NeRF optimization. We show that this data-driven prior removes floaters and improves scene geometry for casual captures.
Laplacian Segmentation Networks: Improved Epistemic Uncertainty from Spatial Aleatoric Uncertainty
Mar 23, 2023



Out of distribution (OOD) medical images are frequently encountered, e.g. because of site- or scanner differences, or image corruption. OOD images come with a risk of incorrect image segmentation, potentially negatively affecting downstream diagnoses or treatment. To ensure robustness to such incorrect segmentations, we propose Laplacian Segmentation Networks (LSN) that jointly model epistemic (model) and aleatoric (data) uncertainty in image segmentation. We capture data uncertainty with a spatially correlated logit distribution. For model uncertainty, we propose the first Laplace approximation of the weight posterior that scales to large neural networks with skip connections that have high-dimensional outputs. Empirically, we demonstrate that modelling spatial pixel correlation allows the Laplacian Segmentation Network to successfully assign high epistemic uncertainty to out-of-distribution objects appearing within images.
Bayesian Metric Learning for Uncertainty Quantification in Image Retrieval
Feb 04, 2023



We propose the first Bayesian encoder for metric learning. Rather than relying on neural amortization as done in prior works, we learn a distribution over the network weights with the Laplace Approximation. We actualize this by first proving that the contrastive loss is a valid log-posterior. We then propose three methods that ensure a positive definite Hessian. Lastly, we present a novel decomposition of the Generalized Gauss-Newton approximation. Empirically, we show that our Laplacian Metric Learner (LAM) estimates well-calibrated uncertainties, reliably detects out-of-distribution examples, and yields state-of-the-art predictive performance.
K-Planes: Explicit Radiance Fields in Space, Time, and Appearance
Jan 24, 2023



We introduce k-planes, a white-box model for radiance fields in arbitrary dimensions. Our model uses d choose 2 planes to represent a d-dimensional scene, providing a seamless way to go from static (d=3) to dynamic (d=4) scenes. This planar factorization makes adding dimension-specific priors easy, e.g. temporal smoothness and multi-resolution spatial structure, and induces a natural decomposition of static and dynamic components of a scene. We use a linear feature decoder with a learned color basis that yields similar performance as a nonlinear black-box MLP decoder. Across a range of synthetic and real, static and dynamic, fixed and varying appearance scenes, k-planes yields competitive and often state-of-the-art reconstruction fidelity with low memory usage, achieving 1000x compression over a full 4D grid, and fast optimization with a pure PyTorch implementation. For video results and code, please see sarafridov.github.io/K-Planes.
Laplacian Autoencoders for Learning Stochastic Representations
Jul 03, 2022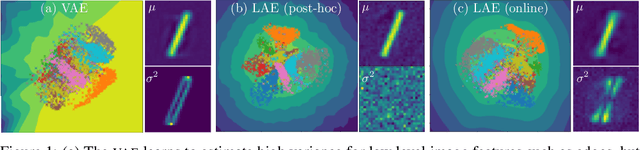
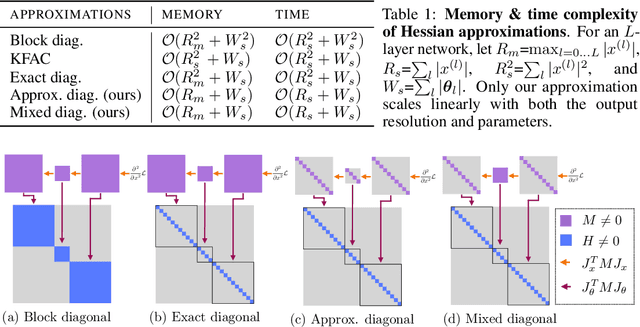
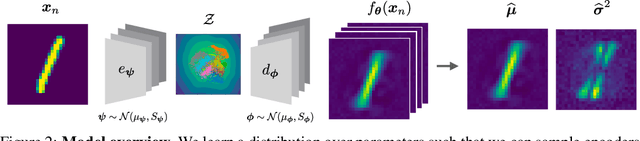
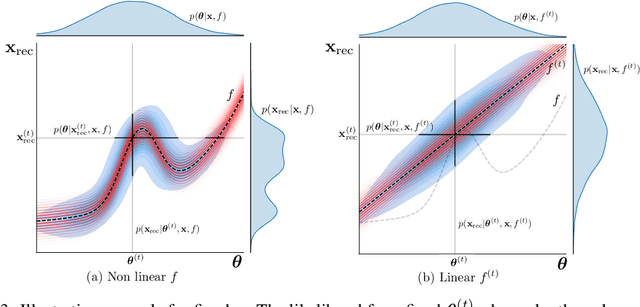
Established methods for unsupervised representation learning such as variational autoencoders produce none or poorly calibrated uncertainty estimates making it difficult to evaluate if learned representations are stable and reliable. In this work, we present a Bayesian autoencoder for unsupervised representation learning, which is trained using a novel variational lower-bound of the autoencoder evidence. This is maximized using Monte Carlo EM with a variational distribution that takes the shape of a Laplace approximation. We develop a new Hessian approximation that scales linearly with data size allowing us to model high-dimensional data. Empirically, we show that our Laplacian autoencoder estimates well-calibrated uncertainties in both latent and output space. We demonstrate that this results in improved performance across a multitude of downstream tasks.
SparseFormer: Attention-based Depth Completion Network
Jun 09, 2022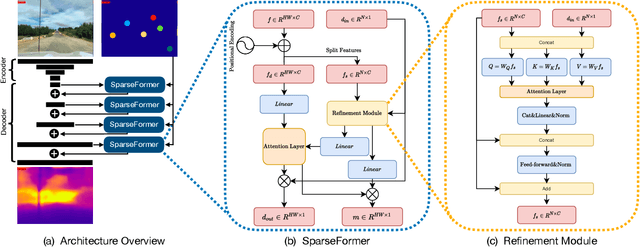
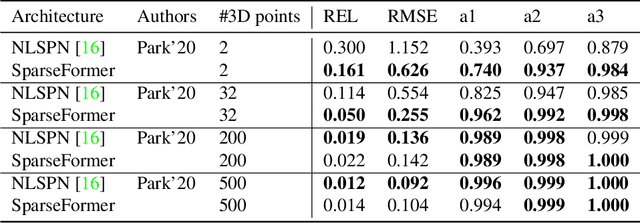

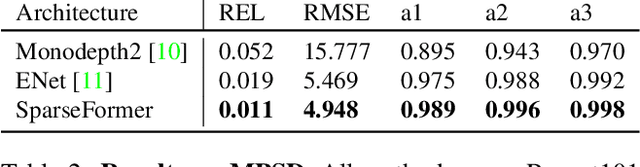
Most pipelines for Augmented and Virtual Reality estimate the ego-motion of the camera by creating a map of sparse 3D landmarks. In this paper, we tackle the problem of depth completion, that is, densifying this sparse 3D map using RGB images as guidance. This remains a challenging problem due to the low density, non-uniform and outlier-prone 3D landmarks produced by SfM and SLAM pipelines. We introduce a transformer block, SparseFormer, that fuses 3D landmarks with deep visual features to produce dense depth. The SparseFormer has a global receptive field, making the module especially effective for depth completion with low-density and non-uniform landmarks. To address the issue of depth outliers among the 3D landmarks, we introduce a trainable refinement module that filters outliers through attention between the sparse landmarks.
Volumetric Disentanglement for 3D Scene Manipulation
Jun 06, 2022
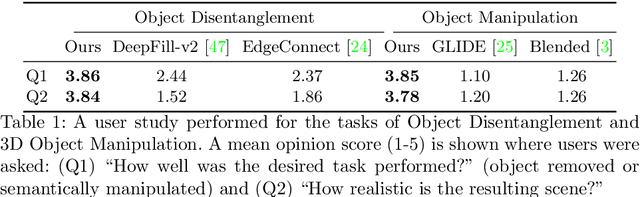
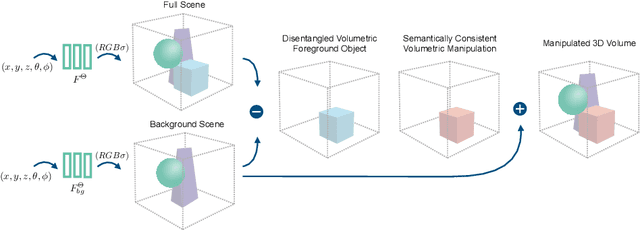
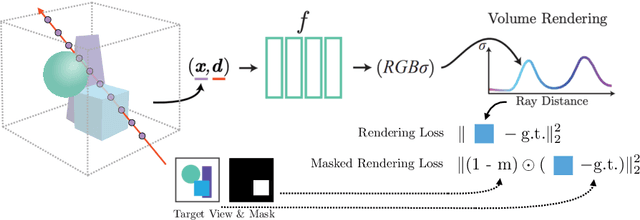
Recently, advances in differential volumetric rendering enabled significant breakthroughs in the photo-realistic and fine-detailed reconstruction of complex 3D scenes, which is key for many virtual reality applications. However, in the context of augmented reality, one may also wish to effect semantic manipulations or augmentations of objects within a scene. To this end, we propose a volumetric framework for (i) disentangling or separating, the volumetric representation of a given foreground object from the background, and (ii) semantically manipulating the foreground object, as well as the background. Our framework takes as input a set of 2D masks specifying the desired foreground object for training views, together with the associated 2D views and poses, and produces a foreground-background disentanglement that respects the surrounding illumination, reflections, and partial occlusions, which can be applied to both training and novel views. Our method enables the separate control of pixel color and depth as well as 3D similarity transformations of both the foreground and background objects. We subsequently demonstrate the applicability of our framework on a number of downstream manipulation tasks including object camouflage, non-negative 3D object inpainting, 3D object translation, 3D object inpainting, and 3D text-based object manipulation. Full results are given in our project webpage at https://sagiebenaim.github.io/volumetric-disentanglement/