 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe iMaterialist Fashion Attribute Dataset
Jun 14, 2019
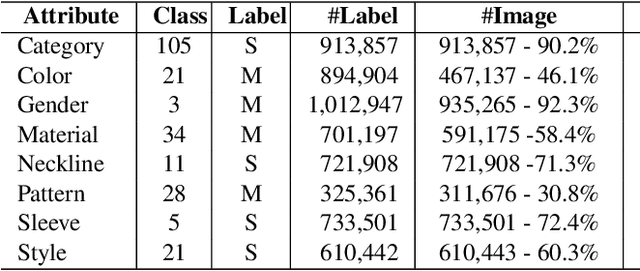
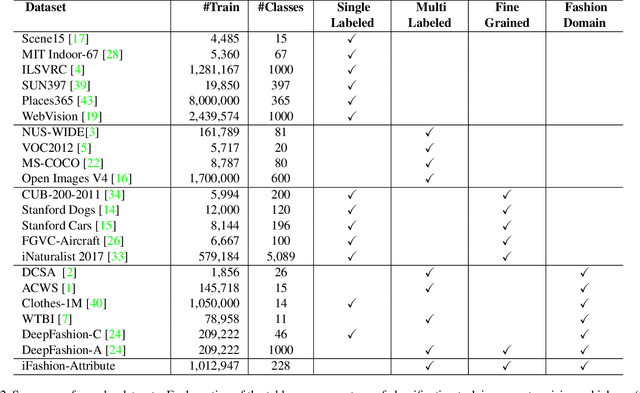
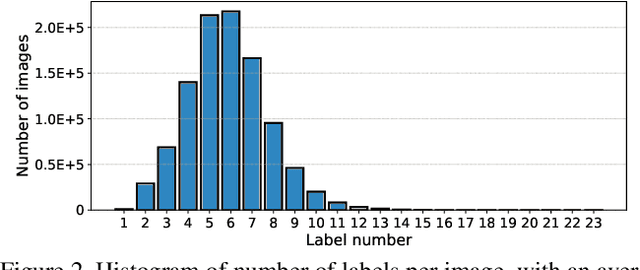
Large-scale image databases such as ImageNet have significantly advanced image classification and other visual recognition tasks. However much of these datasets are constructed only for single-label and coarse object-level classification. For real-world applications, multiple labels and fine-grained categories are often needed, yet very few such datasets exist publicly, especially those of large-scale and high quality. In this work, we contribute to the community a new dataset called iMaterialist Fashion Attribute (iFashion-Attribute) to address this problem in the fashion domain. The dataset is constructed from over one million fashion images with a label space that includes 8 groups of 228 fine-grained attributes in total. Each image is annotated by experts with multiple, high-quality fashion attributes. The result is the first known million-scale multi-label and fine-grained image dataset. We conduct extensive experiments and provide baseline results with modern deep Convolutional Neural Networks (CNNs). Additionally, we demonstrate models pre-trained on iFashion-Attribute achieve superior transfer learning performance on fashion related tasks compared with pre-training from ImageNet or other fashion datasets. Data is available at: https://github.com/visipedia/imat_fashion_comp
The iMet Collection 2019 Challenge Dataset
Jun 04, 2019
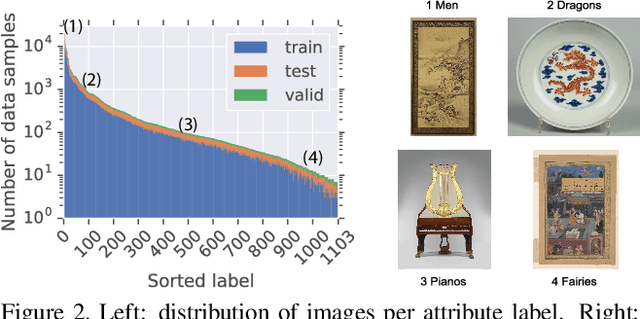
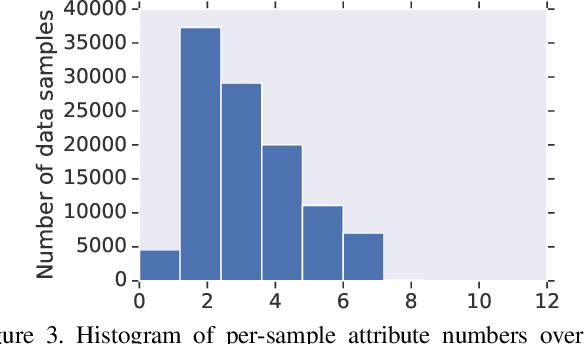
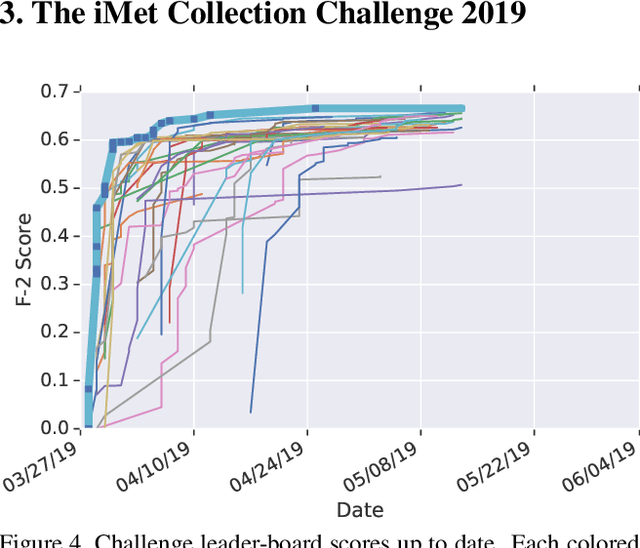
Existing computer vision technologies in artwork recognition focus mainly on instance retrieval or coarse-grained attribute classification. In this work, we present a novel dataset for fine-grained artwork attribute recognition. The images in the dataset are professional photographs of classic artworks from the Metropolitan Museum of Art, and annotations are curated and verified by world-class museum experts. In addition, we also present the iMet Collection 2019 Challenge as part of the FGVC6 workshop. Through the competition, we aim to spur the enthusiasm of the fine-grained visual recognition research community and advance the state-of-the-art in digital curation of museum collections.
Class-Balanced Loss Based on Effective Number of Samples
Jan 16, 2019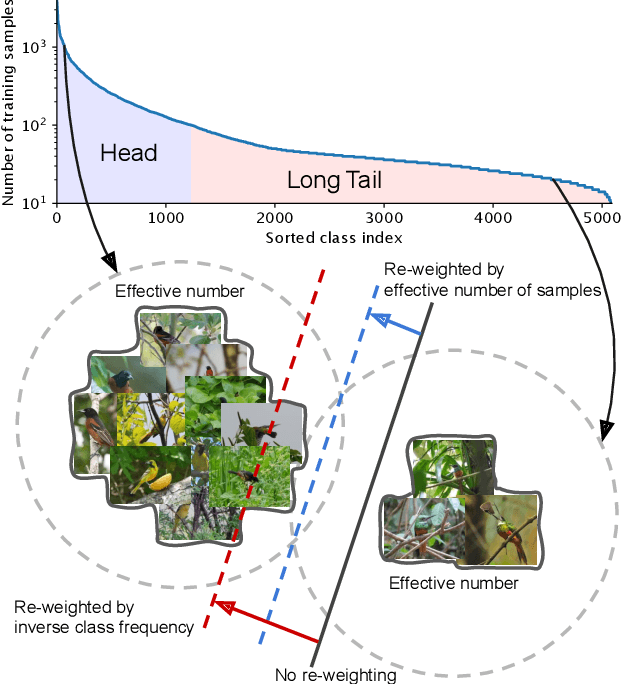
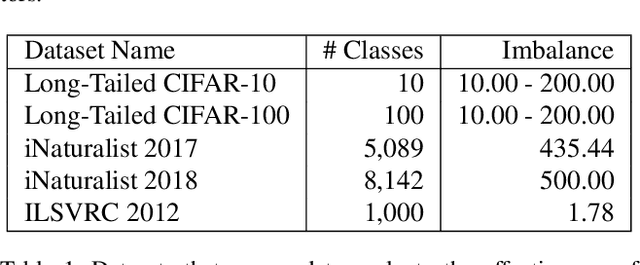
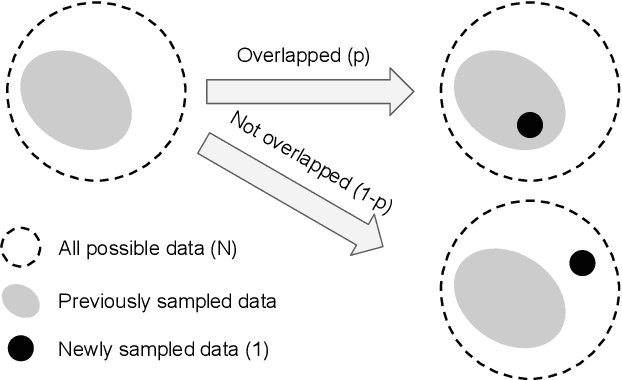
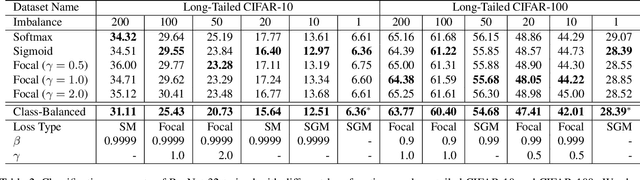
With the rapid increase of large-scale, real-world datasets, it becomes critical to address the problem of long-tailed data distribution (i.e., a few classes account for most of the data, while most classes are under-represented). Existing solutions typically adopt class re-balancing strategies such as re-sampling and re-weighting based on the number of observations for each class. In this work, we argue that as the number of samples increases, the additional benefit of a newly added data point will diminish. We introduce a novel theoretical framework to measure data overlap by associating with each sample a small neighboring region rather than a single point. The effective number of samples is defined as the volume of samples and can be calculated by a simple formula $(1-\beta^{n})/(1-\beta)$, where $n$ is the number of samples and $\beta \in [0,1)$ is a hyperparameter. We design a re-weighting scheme that uses the effective number of samples for each class to re-balance the loss, thereby yielding a class-balanced loss. Comprehensive experiments are conducted on artificially induced long-tailed CIFAR datasets and large-scale datasets including ImageNet and iNaturalist. Our results show that when trained with the proposed class-balanced loss, the network is able to achieve significant performance gains on long-tailed datasets.
Adversarial Example Decomposition
Dec 04, 2018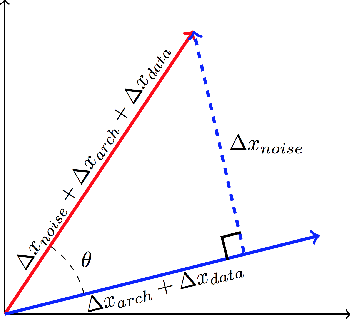

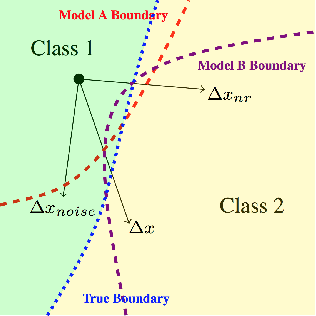
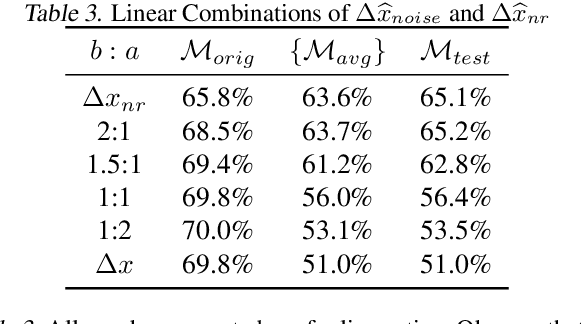
Research has shown that widely used deep neural networks are vulnerable to carefully crafted adversarial perturbations. Moreover, these adversarial perturbations often transfer across models. We hypothesize that adversarial weakness is composed of three sources of bias: architecture, dataset, and random initialization. We show that one can decompose adversarial examples into an architecture-dependent component, data-dependent component, and noise-dependent component and that these components behave intuitively. For example, noise-dependent components transfer poorly to all other models, while architecture-dependent components transfer better to retrained models with the same architecture. In addition, we demonstrate that these components can be recombined to improve transferability without sacrificing efficacy on the original model.
Understanding Image Quality and Trust in Peer-to-Peer Marketplaces
Nov 26, 2018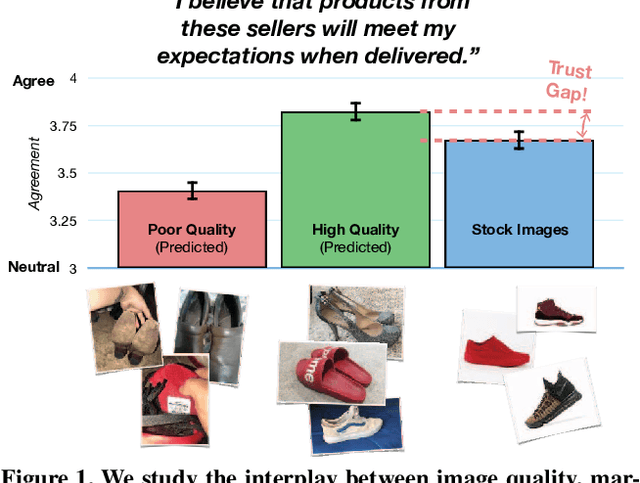

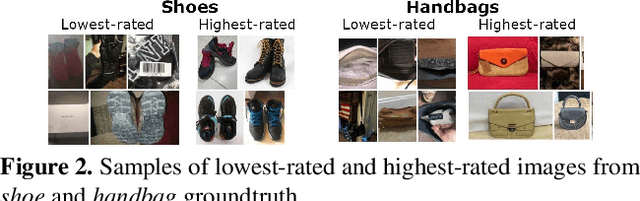
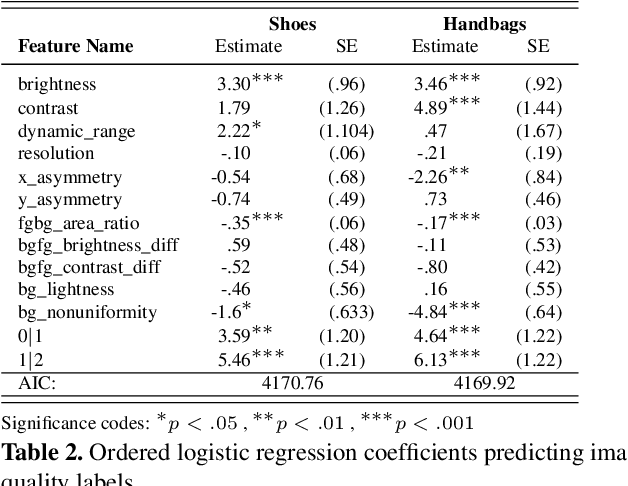
As any savvy online shopper knows, second-hand peer-to-peer marketplaces are filled with images of mixed quality. How does image quality impact marketplace outcomes, and can quality be automatically predicted? In this work, we conducted a large-scale study on the quality of user-generated images in peer-to-peer marketplaces. By gathering a dataset of common second-hand products (~75,000 images) and annotating a subset with human-labeled quality judgments, we were able to model and predict image quality with decent accuracy (~87%). We then conducted two studies focused on understanding the relationship between these image quality scores and two marketplace outcomes: sales and perceived trustworthiness. We show that image quality is associated with higher likelihood that an item will be sold, though other factors such as view count were better predictors of sales. Nonetheless, we show that high quality user-generated images selected by our models outperform stock imagery in eliciting perceptions of trust from users. Our findings can inform the design of future marketplaces and guide potential sellers to take better product images.
Intermediate Level Adversarial Attack for Enhanced Transferability
Nov 20, 2018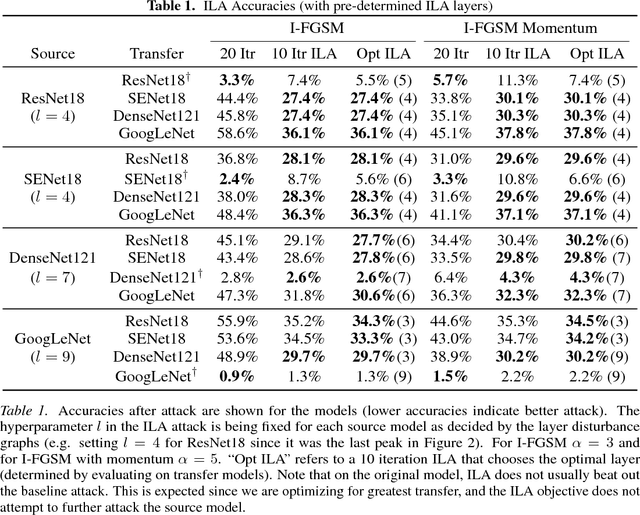
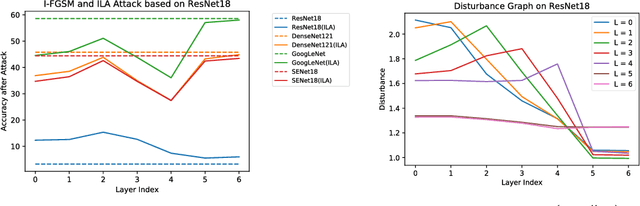
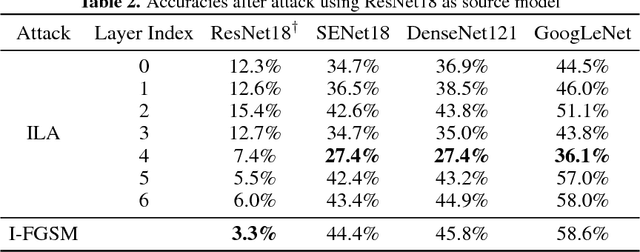
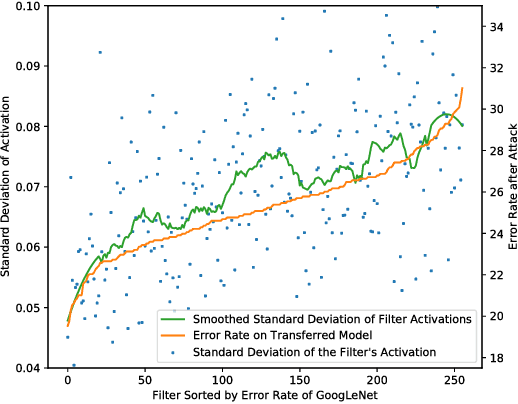
Neural networks are vulnerable to adversarial examples, malicious inputs crafted to fool trained models. Adversarial examples often exhibit black-box transfer, meaning that adversarial examples for one model can fool another model. However, adversarial examples may be overfit to exploit the particular architecture and feature representation of a source model, resulting in sub-optimal black-box transfer attacks to other target models. This leads us to introduce the Intermediate Level Attack (ILA), which attempts to fine-tune an existing adversarial example for greater black-box transferability by increasing its perturbation on a pre-specified layer of the source model. We show that our method can effectively achieve this goal and that we can decide a nearly-optimal layer of the source model to perturb without any knowledge of the target models.
Vision-based Real Estate Price Estimation
Oct 03, 2018
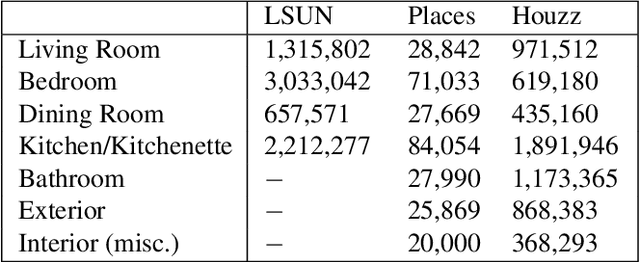


Since the advent of online real estate database companies like Zillow, Trulia and Redfin, the problem of automatic estimation of market values for houses has received considerable attention. Several real estate websites provide such estimates using a proprietary formula. Although these estimates are often close to the actual sale prices, in some cases they are highly inaccurate. One of the key factors that affects the value of a house is its interior and exterior appearance, which is not considered in calculating automatic value estimates. In this paper, we evaluate the impact of visual characteristics of a house on its market value. Using deep convolutional neural networks on a large dataset of photos of home interiors and exteriors, we develop a method for estimating the luxury level of real estate photos. We also develop a novel framework for automated value assessment using the above photos in addition to home characteristics including size, offered price and number of bedrooms. Finally, by applying our proposed method for price estimation to a new dataset of real estate photos and metadata, we show that it outperforms Zillow's estimates.
Deep Fundamental Matrix Estimation without Correspondences
Oct 03, 2018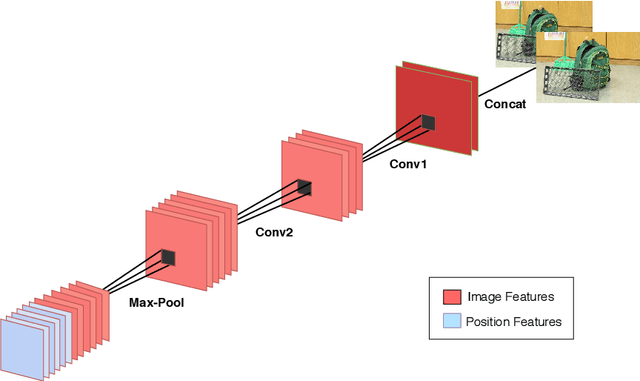
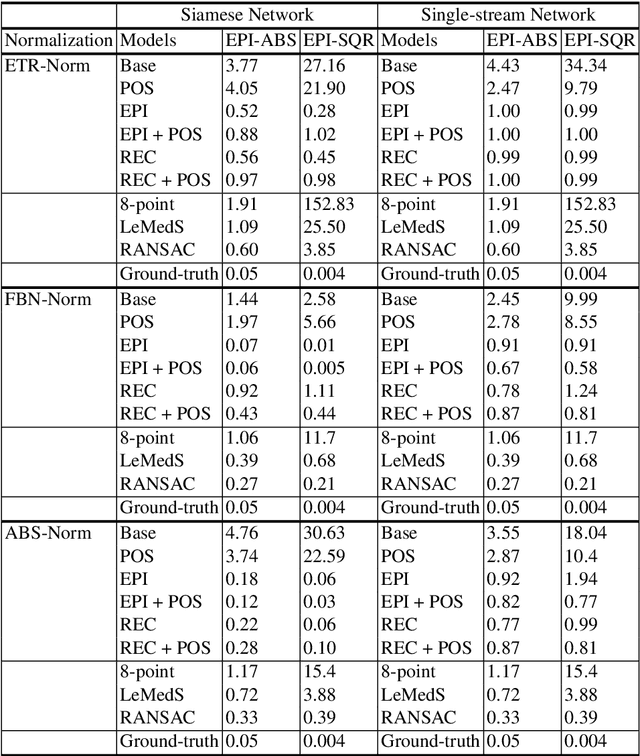
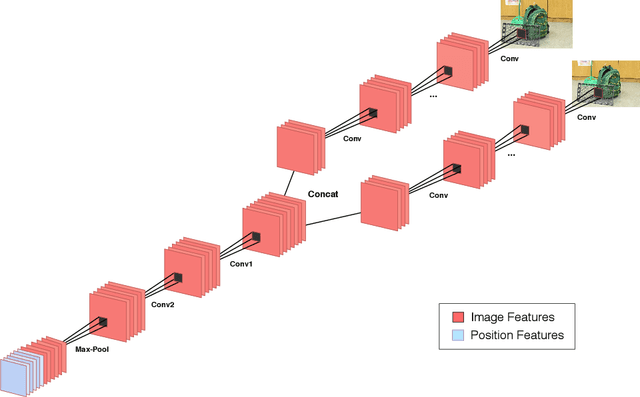
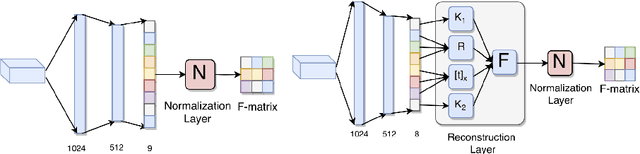
Estimating fundamental matrices is a classic problem in computer vision. Traditional methods rely heavily on the correctness of estimated key-point correspondences, which can be noisy and unreliable. As a result, it is difficult for these methods to handle image pairs with large occlusion or significantly different camera poses. In this paper, we propose novel neural network architectures to estimate fundamental matrices in an end-to-end manner without relying on point correspondences. New modules and layers are introduced in order to preserve mathematical properties of the fundamental matrix as a homogeneous rank-2 matrix with seven degrees of freedom. We analyze performance of the proposed models using various metrics on the KITTI dataset, and show that they achieve competitive performance with traditional methods without the need for extracting correspondences.
ICDAR2017 Competition on Reading Chinese Text in the Wild (RCTW-17)
Sep 26, 2018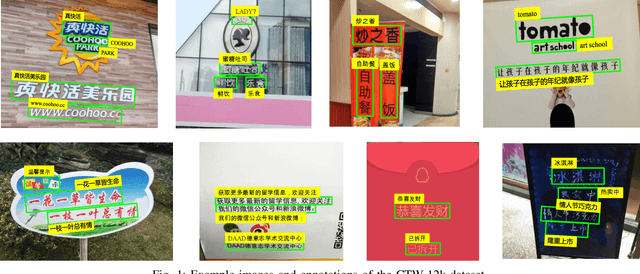
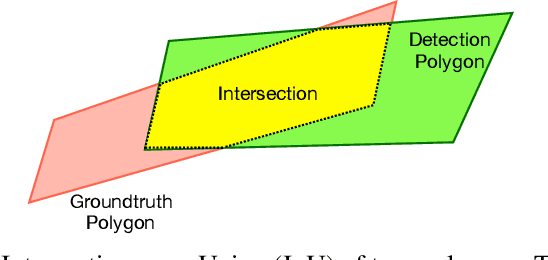
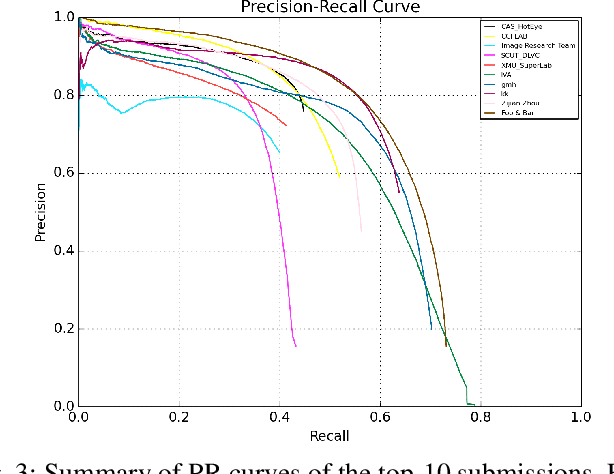

Chinese is the most widely used language in the world. Algorithms that read Chinese text in natural images facilitate applications of various kinds. Despite the large potential value, datasets and competitions in the past primarily focus on English, which bares very different characteristics than Chinese. This report introduces RCTW, a new competition that focuses on Chinese text reading. The competition features a large-scale dataset with 12,263 annotated images. Two tasks, namely text localization and end-to-end recognition, are set up. The competition took place from January 20 to May 31, 2017. 23 valid submissions were received from 19 teams. This report includes dataset description, task definitions, evaluation protocols, and results summaries and analysis. Through this competition, we call for more future research on the Chinese text reading problem. The official website for the competition is http://rctw.vlrlab.net
Multimodal Unsupervised Image-to-Image Translation
Aug 14, 2018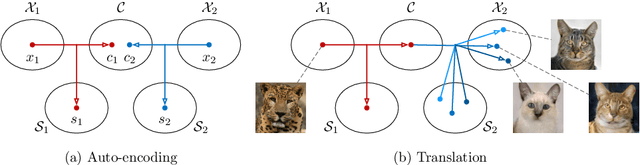
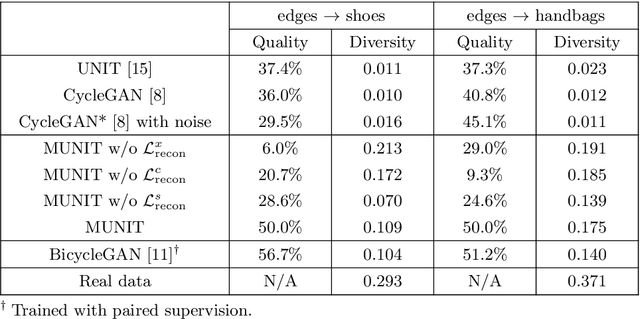
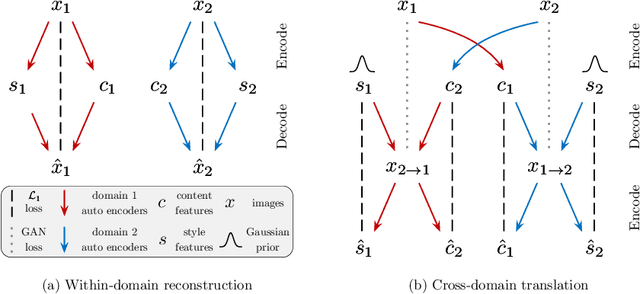
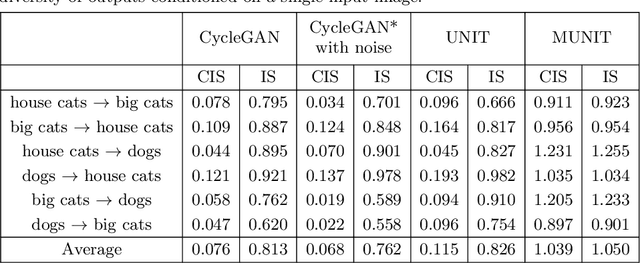
Unsupervised image-to-image translation is an important and challenging problem in computer vision. Given an image in the source domain, the goal is to learn the conditional distribution of corresponding images in the target domain, without seeing any pairs of corresponding images. While this conditional distribution is inherently multimodal, existing approaches make an overly simplified assumption, modeling it as a deterministic one-to-one mapping. As a result, they fail to generate diverse outputs from a given source domain image. To address this limitation, we propose a Multimodal Unsupervised Image-to-image Translation (MUNIT) framework. We assume that the image representation can be decomposed into a content code that is domain-invariant, and a style code that captures domain-specific properties. To translate an image to another domain, we recombine its content code with a random style code sampled from the style space of the target domain. We analyze the proposed framework and establish several theoretical results. Extensive experiments with comparisons to the state-of-the-art approaches further demonstrates the advantage of the proposed framework. Moreover, our framework allows users to control the style of translation outputs by providing an example style image. Code and pretrained models are available at https://github.com/nvlabs/MUNIT