 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePVT++: A Simple End-to-End Latency-Aware Visual Tracking Framework
Nov 21, 2022



Visual object tracking is an essential capability of intelligent robots. Most existing approaches have ignored the online latency that can cause severe performance degradation during real-world processing. Especially for unmanned aerial vehicle, where robust tracking is more challenging and onboard computation is limited, latency issue could be fatal. In this work, we present a simple framework for end-to-end latency-aware tracking, i.e., end-to-end predictive visual tracking (PVT++). PVT++ is capable of turning most leading-edge trackers into predictive trackers by appending an online predictor. Unlike existing solutions that use model-based approaches, our framework is learnable, such that it can take not only motion information as input but it can also take advantage of visual cues or a combination of both. Moreover, since PVT++ is end-to-end optimizable, it can further boost the latency-aware tracking performance by joint training. Additionally, this work presents an extended latency-aware evaluation benchmark for assessing an any-speed tracker in the online setting. Empirical results on robotic platform from aerial perspective show that PVT++ can achieve up to 60% performance gain on various trackers and exhibit better robustness than prior model-based solution, largely mitigating the degradation brought by latency. Code and models will be made public.
Challenges in Close-Proximity Safe and Seamless Operation of Manned and Unmanned Aircraft in Shared Airspace
Nov 13, 2022



We propose developing an integrated system to keep autonomous unmanned aircraft safely separated and behave as expected in conjunction with manned traffic. The main goal is to achieve safe manned-unmanned vehicle teaming to improve system performance, have each (robot/human) teammate learn from each other in various aircraft operations, and reduce the manning needs of manned aircraft. The proposed system anticipates and reacts to other aircraft using natural language instructions and can serve as a co-pilot or operate entirely autonomously. We point out the main technical challenges where improvements on current state-of-the-art are needed to enable Visual Flight Rules to fully autonomous aerial operations, bringing insights to these critical areas. Furthermore, we present an interactive demonstration in a prototypical scenario with one AI pilot and one human pilot sharing the same terminal airspace, interacting with each other using language, and landing safely on the same runway. We also show a demonstration of a vision-only aircraft detection system.
Pseudo-Label Noise Suppression Techniques for Semi-Supervised Semantic Segmentation
Oct 19, 2022
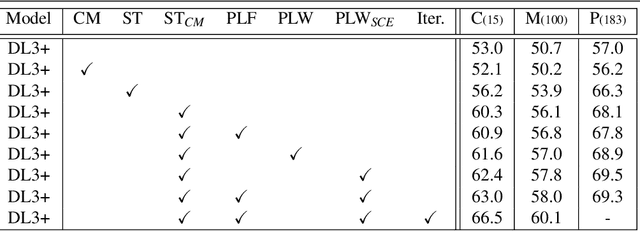
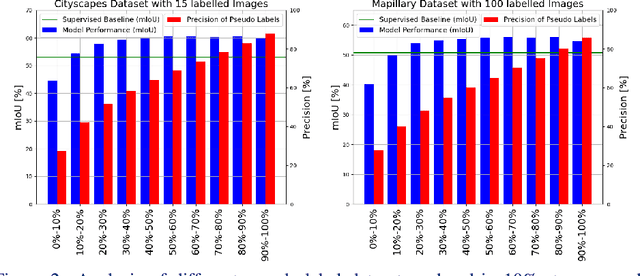
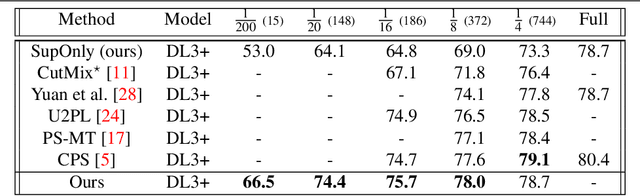
Semi-supervised learning (SSL) can reduce the need for large labelled datasets by incorporating unlabelled data into the training. This is particularly interesting for semantic segmentation, where labelling data is very costly and time-consuming. Current SSL approaches use an initially supervised trained model to generate predictions for unlabelled images, called pseudo-labels, which are subsequently used for training a new model from scratch. Since the predictions usually do not come from an error-free neural network, they are naturally full of errors. However, training with partially incorrect labels often reduce the final model performance. Thus, it is crucial to manage errors/noise of pseudo-labels wisely. In this work, we use three mechanisms to control pseudo-label noise and errors: (1) We construct a solid base framework by mixing images with cow-patterns on unlabelled images to reduce the negative impact of wrong pseudo-labels. Nevertheless, wrong pseudo-labels still have a negative impact on the performance. Therefore, (2) we propose a simple and effective loss weighting scheme for pseudo-labels defined by the feedback of the model trained on these pseudo-labels. This allows us to soft-weight the pseudo-label training examples based on their determined confidence score during training. (3) We also study the common practice to ignore pseudo-labels with low confidence and empirically analyse the influence and effect of pseudo-labels with different confidence ranges on SSL and the contribution of pseudo-label filtering to the achievable performance gains. We show that our method performs superior to state of-the-art alternatives on various datasets. Furthermore, we show that our findings also transfer to other tasks such as human pose estimation. Our code is available at https://github.com/ChristmasFan/SSL_Denoising_Segmentation.
TartanCalib: Iterative Wide-Angle Lens Calibration using Adaptive SubPixel Refinement of AprilTags
Oct 05, 2022
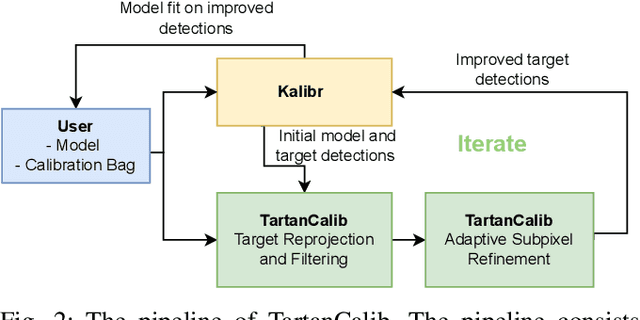

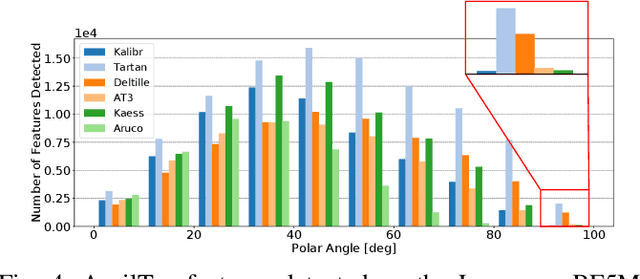
Wide-angle cameras are uniquely positioned for mobile robots, by virtue of the rich information they provide in a small, light, and cost-effective form factor. An accurate calibration of the intrinsics and extrinsics is a critical pre-requisite for using the edge of a wide-angle lens for depth perception and odometry. Calibrating wide-angle lenses with current state-of-the-art techniques yields poor results due to extreme distortion at the edge, as most algorithms assume a lens with low to medium distortion closer to a pinhole projection. In this work we present our methodology for accurate wide-angle calibration. Our pipeline generates an intermediate model, and leverages it to iteratively improve feature detection and eventually the camera parameters. We test three key methods to utilize intermediate camera models: (1) undistorting the image into virtual pinhole cameras, (2) reprojecting the target into the image frame, and (3) adaptive subpixel refinement. Combining adaptive subpixel refinement and feature reprojection significantly improves reprojection errors by up to 26.59 %, helps us detect up to 42.01 % more features, and improves performance in the downstream task of dense depth mapping. Finally, TartanCalib is open-source and implemented into an easy-to-use calibration toolbox. We also provide a translation layer with other state-of-the-art works, which allows for regressing generic models with thousands of parameters or using a more robust solver. To this end, TartanCalib is the tool of choice for wide-angle calibration. Project website and code: http://tartancalib.com.
360FusionNeRF: Panoramic Neural Radiance Fields with Joint Guidance
Oct 03, 2022
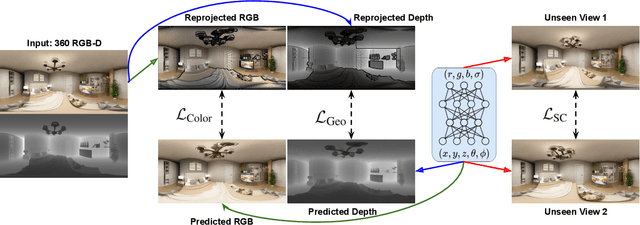

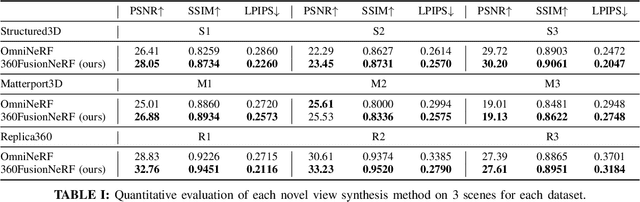
We present a method to synthesize novel views from a single $360^\circ$ panorama image based on the neural radiance field (NeRF). Prior studies in a similar setting rely on the neighborhood interpolation capability of multi-layer perceptions to complete missing regions caused by occlusion, which leads to artifacts in their predictions. We propose 360FusionNeRF, a semi-supervised learning framework where we introduce geometric supervision and semantic consistency to guide the progressive training process. Firstly, the input image is re-projected to $360^\circ$ images, and auxiliary depth maps are extracted at other camera positions. The depth supervision, in addition to the NeRF color guidance, improves the geometry of the synthesized views. Additionally, we introduce a semantic consistency loss that encourages realistic renderings of novel views. We extract these semantic features using a pre-trained visual encoder such as CLIP, a Vision Transformer trained on hundreds of millions of diverse 2D photographs mined from the web with natural language supervision. Experiments indicate that our proposed method can produce plausible completions of unobserved regions while preserving the features of the scene. When trained across various scenes, 360FusionNeRF consistently achieves the state-of-the-art performance when transferring to synthetic Structured3D dataset (PSNR~5%, SSIM~3% LPIPS~13%), real-world Matterport3D dataset (PSNR~3%, SSIM~3% LPIPS~9%) and Replica360 dataset (PSNR~8%, SSIM~2% LPIPS~18%).
PyPose: A Library for Robot Learning with Physics-based Optimization
Sep 30, 2022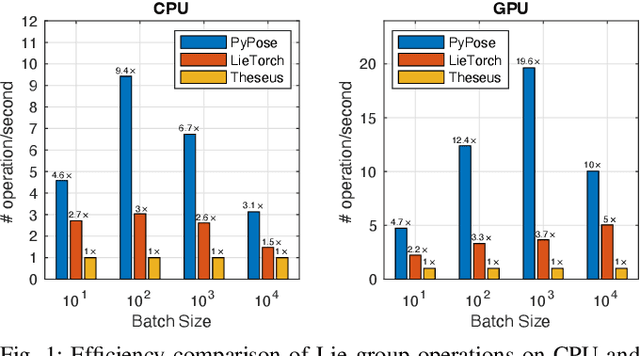
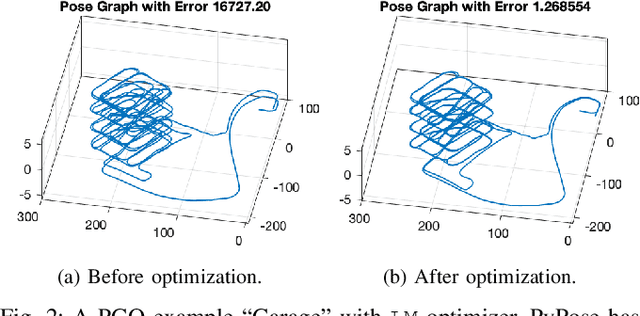
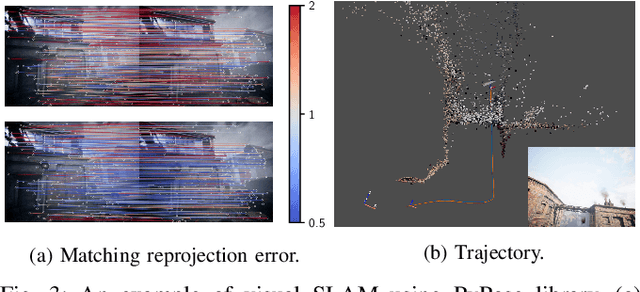
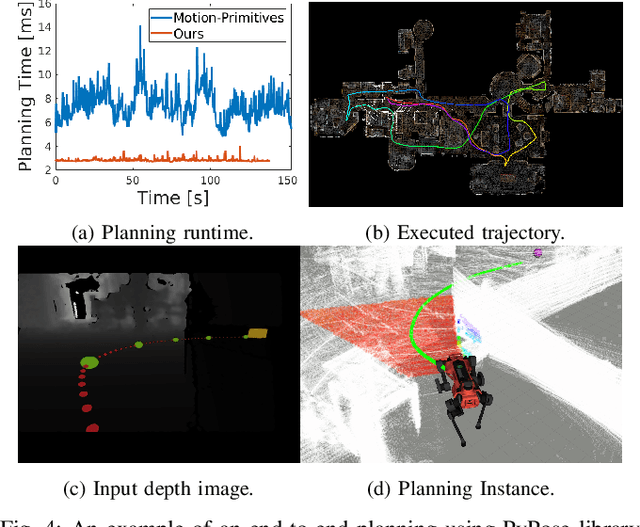
Deep learning has had remarkable success in robotic perception, but its data-centric nature suffers when it comes to generalizing to ever-changing environments. By contrast, physics-based optimization generalizes better, but it does not perform as well in complicated tasks due to the lack of high-level semantic information and the reliance on manual parametric tuning. To take advantage of these two complementary worlds, we present PyPose: a robotics-oriented, PyTorch-based library that combines deep perceptual models with physics-based optimization techniques. Our design goal for PyPose is to make it user-friendly, efficient, and interpretable with a tidy and well-organized architecture. Using an imperative style interface, it can be easily integrated into real-world robotic applications. Besides, it supports parallel computing of any order gradients of Lie groups and Lie algebras and $2^{\text{nd}}$-order optimizers, such as trust region methods. Experiments show that PyPose achieves 3-20$\times$ speedup in computation compared to state-of-the-art libraries. To boost future research, we provide concrete examples across several fields of robotics, including SLAM, inertial navigation, planning, and control.
Follow The Rules: Online Signal Temporal Logic Tree Search for Guided Imitation Learning in Stochastic Domains
Sep 27, 2022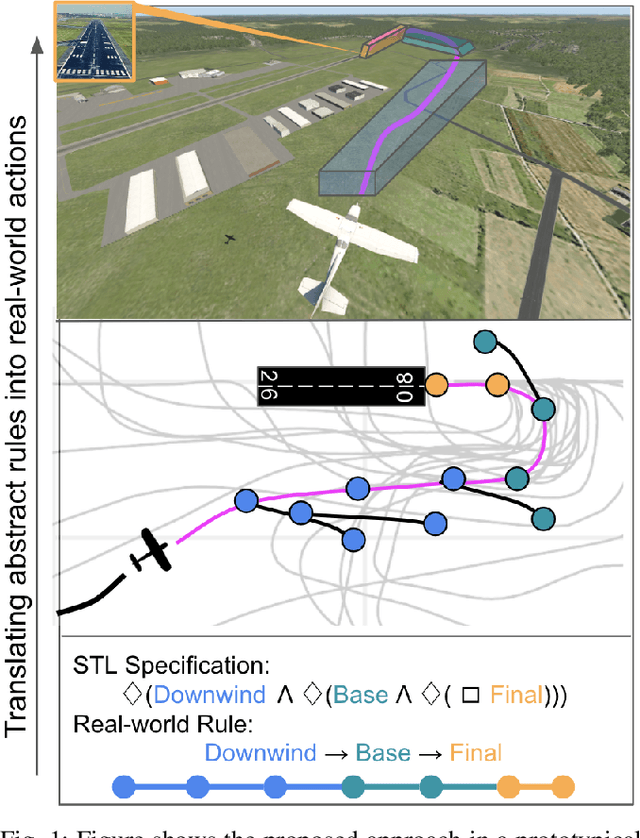
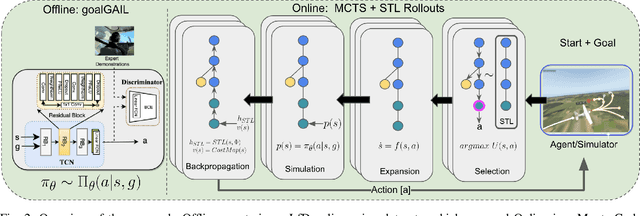
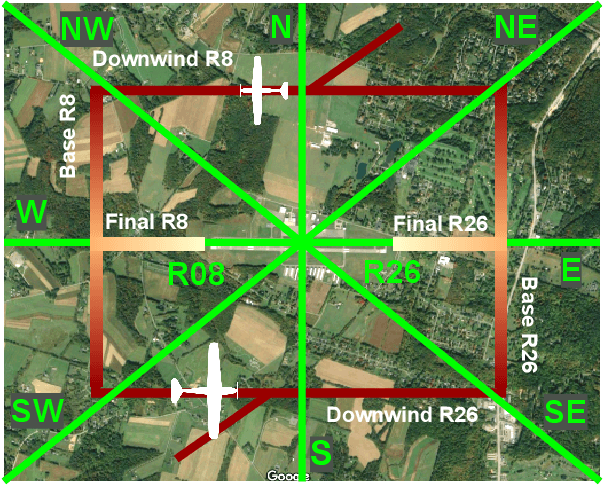
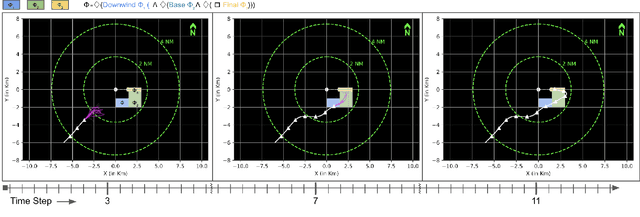
Seamlessly integrating rules in Learning-from-Demonstrations (LfD) policies is a critical requirement to enable the real-world deployment of AI agents. Recently Signal Temporal Logic (STL) has been shown to be an effective language for encoding rules as spatio-temporal constraints. This work uses Monte Carlo Tree Search (MCTS) as a means of integrating STL specification into a vanilla LfD policy to improve constraint satisfaction. We propose augmenting the MCTS heuristic with STL robustness values to bias the tree search towards branches with higher constraint satisfaction. While the domain-independent method can be applied to integrate STL rules online into any pre-trained LfD algorithm, we choose goal-conditioned Generative Adversarial Imitation Learning as the offline LfD policy. We apply the proposed method to the domain of planning trajectories for General Aviation aircraft around a non-towered airfield. Results using the simulator trained on real-world data showcase 60% improved performance over baseline LfD methods that do not use STL heuristics.
DytanVO: Joint Refinement of Visual Odometry and Motion Segmentation in Dynamic Environments
Sep 24, 2022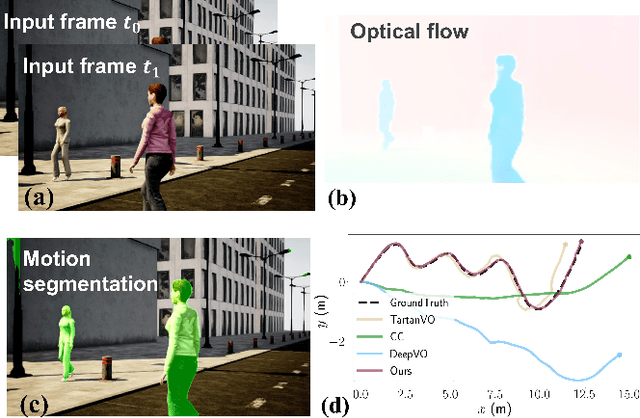
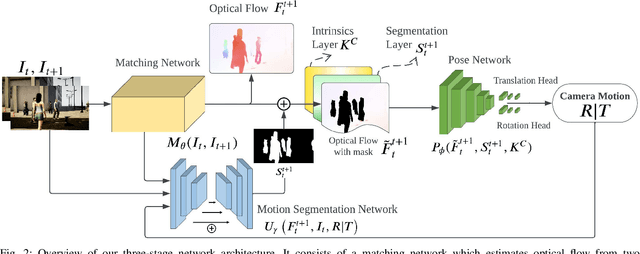
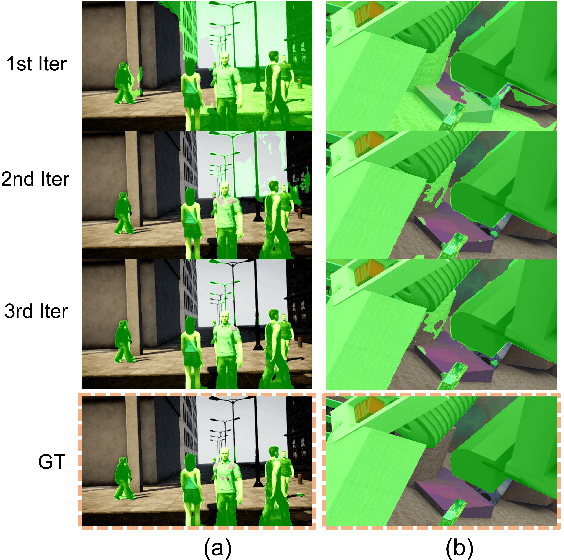
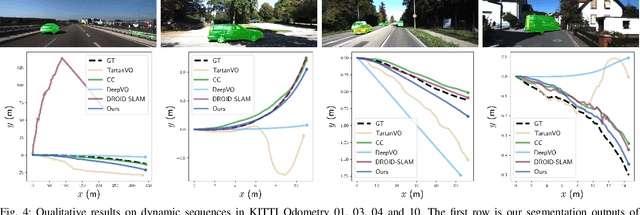
Learning-based visual odometry (VO) algorithms achieve remarkable performance on common static scenes, benefiting from high-capacity models and massive annotated data, but tend to fail in dynamic, populated environments. Semantic segmentation is largely used to discard dynamic associations before estimating camera motions but at the cost of discarding static features and is hard to scale up to unseen categories. In this paper, we leverage the mutual dependence between camera ego-motion and motion segmentation and show that both can be jointly refined in a single learning-based framework. In particular, we present DytanVO, the first supervised learning-based VO method that deals with dynamic environments. It takes two consecutive monocular frames in real-time and predicts camera ego-motion in an iterative fashion. Our method achieves an average improvement of 27.7% in ATE over state-of-the-art VO solutions in real-world dynamic environments, and even performs competitively among dynamic visual SLAM systems which optimize the trajectory on the backend. Experiments on plentiful unseen environments also demonstrate our method's generalizability.
How Does It Feel? Self-Supervised Costmap Learning for Off-Road Vehicle Traversability
Sep 22, 2022
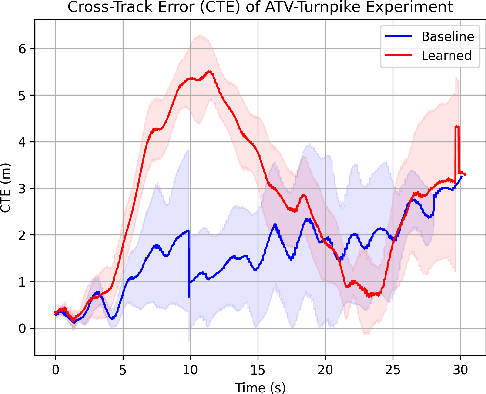
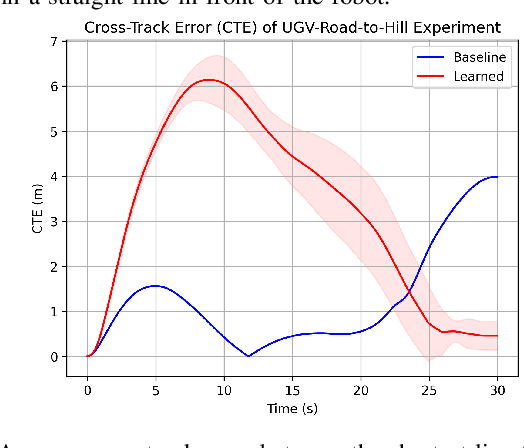
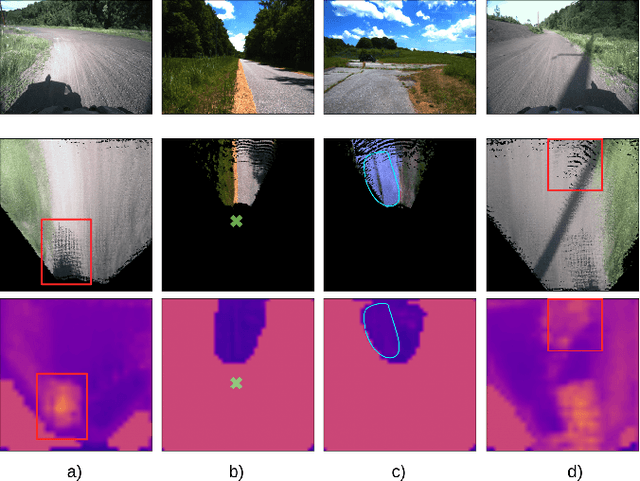
Estimating terrain traversability in off-road environments requires reasoning about complex interaction dynamics between the robot and these terrains. However, it is challenging to build an accurate physics model, or create informative labels to learn a model in a supervised manner, for these interactions. We propose a method that learns to predict traversability costmaps by combining exteroceptive environmental information with proprioceptive terrain interaction feedback in a self-supervised manner. Additionally, we propose a novel way of incorporating robot velocity in the costmap prediction pipeline. We validate our method in multiple short and large-scale navigation tasks on a large, autonomous all-terrain vehicle (ATV) on challenging off-road terrains, and demonstrate ease of integration on a separate large ground robot. Our short-scale navigation results show that using our learned costmaps leads to overall smoother navigation, and provides the robot with a more fine-grained understanding of the interactions between the robot and different terrain types, such as grass and gravel. Our large-scale navigation trials show that we can reduce the number of interventions by up to 57% compared to an occupancy-based navigation baseline in challenging off-road courses ranging from 400 m to 3150 m.
MUI-TARE: Multi-Agent Cooperative Exploration with Unknown Initial Position
Sep 22, 2022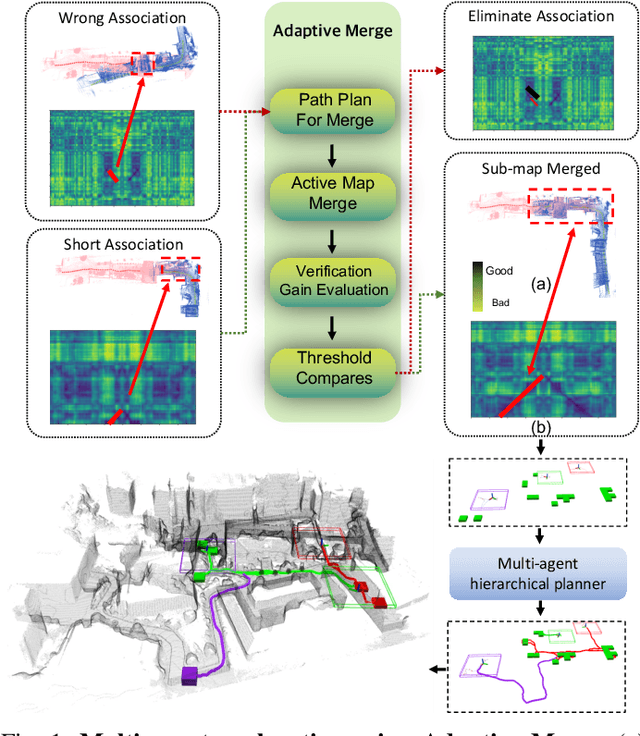
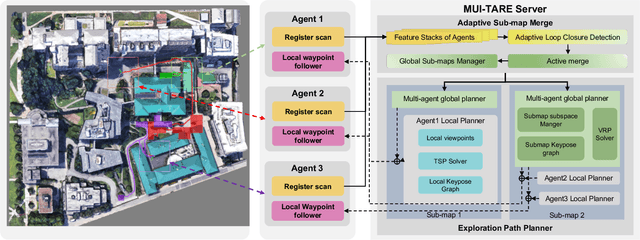
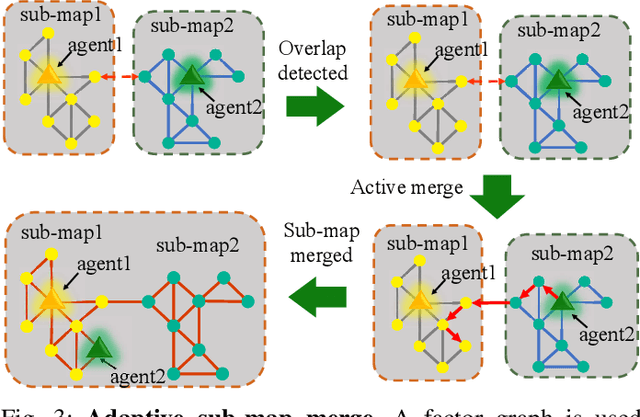
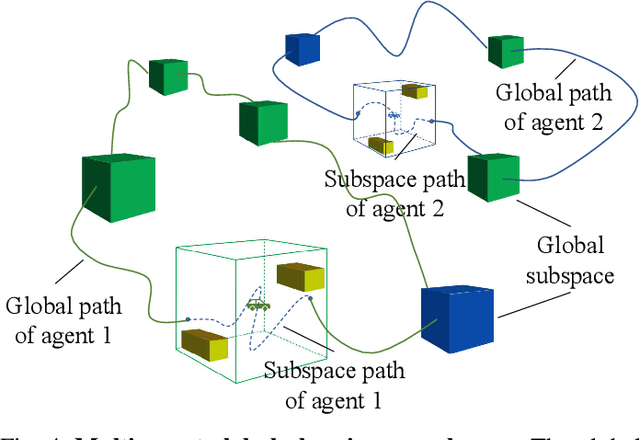
Multi-agent exploration of a bounded 3D environment with unknown initial positions of agents is a challenging problem. It requires quickly exploring the environments as well as robustly merging the sub-maps built by the agents. We take the view that the existing approaches are either aggressive or conservative: Aggressive strategies merge two sub-maps built by different agents together when overlap is detected, which can lead to incorrect merging due to the false-positive detection of the overlap and is thus not robust. Conservative strategies direct one agent to revisit an excessive amount of the historical trajectory of another agent for verification before merging, which can lower the exploration efficiency due to the repeated exploration of the same space. To intelligently balance the robustness of sub-map merging and exploration efficiency, we develop a new approach for lidar-based multi-agent exploration, which can direct one agent to repeat another agent's trajectory in an \emph{adaptive} manner based on the quality indicator of the sub-map merging process. Additionally, our approach extends the recent single-agent hierarchical exploration strategy to multiple agents in a \emph{cooperative} manner by planning for agents with merged sub-maps together to further improve exploration efficiency. Our experiments show that our approach is up to 50\% more efficient than the baselines on average while merging sub-maps robustly.