 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistory-Guided Video Diffusion
Feb 10, 2025



Classifier-free guidance (CFG) is a key technique for improving conditional generation in diffusion models, enabling more accurate control while enhancing sample quality. It is natural to extend this technique to video diffusion, which generates video conditioned on a variable number of context frames, collectively referred to as history. However, we find two key challenges to guiding with variable-length history: architectures that only support fixed-size conditioning, and the empirical observation that CFG-style history dropout performs poorly. To address this, we propose the Diffusion Forcing Transformer (DFoT), a video diffusion architecture and theoretically grounded training objective that jointly enable conditioning on a flexible number of history frames. We then introduce History Guidance, a family of guidance methods uniquely enabled by DFoT. We show that its simplest form, vanilla history guidance, already significantly improves video generation quality and temporal consistency. A more advanced method, history guidance across time and frequency further enhances motion dynamics, enables compositional generalization to out-of-distribution history, and can stably roll out extremely long videos. Website: https://boyuan.space/history-guidance
Planning Shorter Paths in Graphs of Convex Sets by Undistorting Parametrized Configuration Spaces
Nov 28, 2024Optimization based motion planning provides a useful modeling framework through various costs and constraints. Using Graph of Convex Sets (GCS) for trajectory optimization gives guarantees of feasibility and optimality by representing configuration space as the finite union of convex sets. Nonlinear parametrizations can be used to extend this technique to handle cases such as kinematic loops, but this distorts distances, such that solving with convex objectives will yield paths that are suboptimal in the original space. We present a method to extend GCS to nonconvex objectives, allowing us to "undistort" the optimization landscape while maintaining feasibility guarantees. We demonstrate our method's efficacy on three different robotic planning domains: a bimanual robot moving an object with both arms, the set of 3D rotations using Euler angles, and a rational parametrization of kinematics that enables certifying regions as collision free. Across the board, our method significantly improves path length and trajectory duration with only a minimal increase in runtime. Website: https://shrutigarg914.github.io/pgd-gcs-results/
Faster Algorithms for Growing Collision-Free Convex Polytopes in Robot Configuration Space
Oct 16, 2024We propose two novel algorithms for constructing convex collision-free polytopes in robot configuration space. Finding these polytopes enables the application of stronger motion-planning frameworks such as trajectory optimization with Graphs of Convex Sets [1] and is currently a major roadblock in the adoption of these approaches. In this paper, we build upon IRIS-NP (Iterative Regional Inflation by Semidefinite & Nonlinear Programming) [2] to significantly improve tunability, runtimes, and scaling to complex environments. IRIS-NP uses nonlinear programming paired with uniform random initialization to find configurations on the boundary of the free configuration space. Our key insight is that finding near-by configuration-space obstacles using sampling is inexpensive and greatly accelerates region generation. We propose two algorithms using such samples to either employ nonlinear programming more efficiently (IRIS-NP2 ) or circumvent it altogether using a massively-parallel zero-order optimization strategy (IRIS-ZO). We also propose a termination condition that controls the probability of exceeding a user-specified permissible fraction-in-collision, eliminating a significant source of tuning difficulty in IRIS-NP. We compare performance across eight robot environments, showing that IRIS-ZO achieves an order-of-magnitude speed advantage over IRIS-NP. IRISNP2, also significantly faster than IRIS-NP, builds larger polytopes using fewer hyperplanes, enabling faster downstream computation. Website: https://sites.google.com/view/fastiris
Multi-Query Shortest-Path Problem in Graphs of Convex Sets
Sep 29, 2024



The Shortest-Path Problem in Graph of Convex Sets (SPP in GCS) is a recently developed optimization framework that blends discrete and continuous decision making. Many relevant problems in robotics, such as collision-free motion planning, can be cast and solved as an SPP in GCS, yielding lower-cost solutions and faster runtimes than state-of-the-art algorithms. In this paper, we are motivated by motion planning of robot arms that must operate swiftly in static environments. We consider a multi-query extension of the SPP in GCS, where the goal is to efficiently precompute optimal paths between given sets of initial and target conditions. Our solution consists of two stages. Offline, we use semidefinite programming to compute a coarse lower bound on the problem's cost-to-go function. Then, online, this lower bound is used to incrementally generate feasible paths by solving short-horizon convex programs. For a robot arm with seven joints, our method designs higher quality trajectories up to two orders of magnitude faster than existing motion planners.
GCS*: Forward Heuristic Search on Implicit Graphs of Convex Sets
Jul 11, 2024



We consider large-scale, implicit-search-based solutions to the Shortest Path Problems on Graphs of Convex Sets (GCS). We propose GCS*, a forward heuristic search algorithm that generalizes A* search to the GCS setting, where a continuous-valued decision is made at each graph vertex, and constraints across graph edges couple these decisions, influencing costs and feasibility. Such mixed discrete-continuous planning is needed in many domains, including motion planning around obstacles and planning through contact. This setting provides a unique challenge for best-first search algorithms: the cost and feasibility of a path depend on continuous-valued points chosen along the entire path. We show that by pruning paths that are cost-dominated over their entire terminal vertex, GCS* can search efficiently while still guaranteeing cost optimality and completeness. To find satisficing solutions quickly, we also present a complete but suboptimal variation, pruning instead reachability-dominated paths. We implement these checks using polyhedral-containment or sampling-based methods. The sampling-based implementation is probabilistically complete and asymptotically cost optimal, and performs effectively even with minimal samples in practice. We demonstrate GCS* on planar pushing tasks where the combinatorial explosion of contact modes renders prior methods intractable and show it performs favorably compared to the state-of-the-art. Project website: https://shaoyuan.cc/research/gcs-star/
Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion
Jul 02, 2024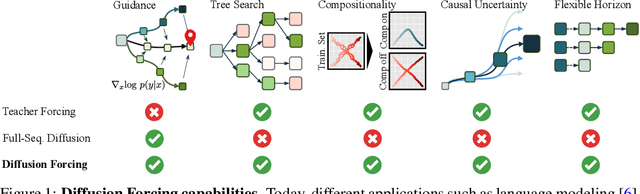
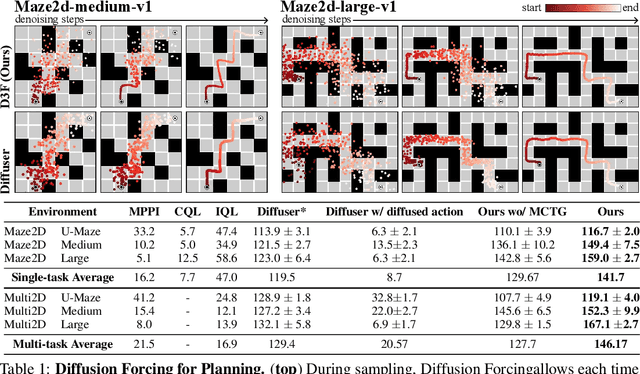
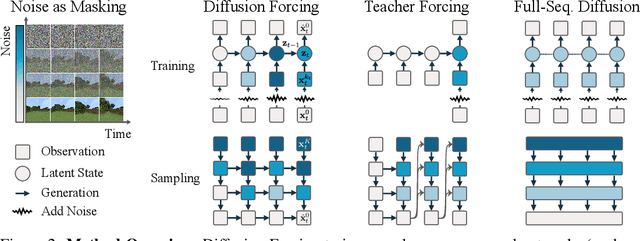
This paper presents Diffusion Forcing, a new training paradigm where a diffusion model is trained to denoise a set of tokens with independent per-token noise levels. We apply Diffusion Forcing to sequence generative modeling by training a causal next-token prediction model to generate one or several future tokens without fully diffusing past ones. Our approach is shown to combine the strengths of next-token prediction models, such as variable-length generation, with the strengths of full-sequence diffusion models, such as the ability to guide sampling to desirable trajectories. Our method offers a range of additional capabilities, such as (1) rolling-out sequences of continuous tokens, such as video, with lengths past the training horizon, where baselines diverge and (2) new sampling and guiding schemes that uniquely profit from Diffusion Forcing's variable-horizon and causal architecture, and which lead to marked performance gains in decision-making and planning tasks. In addition to its empirical success, our method is proven to optimize a variational lower bound on the likelihoods of all subsequences of tokens drawn from the true joint distribution. Project website: https://boyuan.space/diffusion-forcing/
OpenVLA: An Open-Source Vision-Language-Action Model
Jun 13, 2024



Large policies pretrained on a combination of Internet-scale vision-language data and diverse robot demonstrations have the potential to change how we teach robots new skills: rather than training new behaviors from scratch, we can fine-tune such vision-language-action (VLA) models to obtain robust, generalizable policies for visuomotor control. Yet, widespread adoption of VLAs for robotics has been challenging as 1) existing VLAs are largely closed and inaccessible to the public, and 2) prior work fails to explore methods for efficiently fine-tuning VLAs for new tasks, a key component for adoption. Addressing these challenges, we introduce OpenVLA, a 7B-parameter open-source VLA trained on a diverse collection of 970k real-world robot demonstrations. OpenVLA builds on a Llama 2 language model combined with a visual encoder that fuses pretrained features from DINOv2 and SigLIP. As a product of the added data diversity and new model components, OpenVLA demonstrates strong results for generalist manipulation, outperforming closed models such as RT-2-X (55B) by 16.5% in absolute task success rate across 29 tasks and multiple robot embodiments, with 7x fewer parameters. We further show that we can effectively fine-tune OpenVLA for new settings, with especially strong generalization results in multi-task environments involving multiple objects and strong language grounding abilities, and outperform expressive from-scratch imitation learning methods such as Diffusion Policy by 20.4%. We also explore compute efficiency; as a separate contribution, we show that OpenVLA can be fine-tuned on consumer GPUs via modern low-rank adaptation methods and served efficiently via quantization without a hit to downstream success rate. Finally, we release model checkpoints, fine-tuning notebooks, and our PyTorch codebase with built-in support for training VLAs at scale on Open X-Embodiment datasets.
Lyapunov-stable Neural Control for State and Output Feedback: A Novel Formulation for Efficient Synthesis and Verification
Apr 11, 2024



Learning-based neural network (NN) control policies have shown impressive empirical performance in a wide range of tasks in robotics and control. However, formal (Lyapunov) stability guarantees over the region-of-attraction (ROA) for NN controllers with nonlinear dynamical systems are challenging to obtain, and most existing approaches rely on expensive solvers such as sums-of-squares (SOS), mixed-integer programming (MIP), or satisfiability modulo theories (SMT). In this paper, we demonstrate a new framework for learning NN controllers together with Lyapunov certificates using fast empirical falsification and strategic regularizations. We propose a novel formulation that defines a larger verifiable region-of-attraction (ROA) than shown in the literature, and refines the conventional restrictive constraints on Lyapunov derivatives to focus only on certifiable ROAs. The Lyapunov condition is rigorously verified post-hoc using branch-and-bound with scalable linear bound propagation-based NN verification techniques. The approach is efficient and flexible, and the full training and verification procedure is accelerated on GPUs without relying on expensive solvers for SOS, MIP, nor SMT. The flexibility and efficiency of our framework allow us to demonstrate Lyapunov-stable output feedback control with synthesized NN-based controllers and NN-based observers with formal stability guarantees, for the first time in literature. Source code at https://github.com/Verified-Intelligence/Lyapunov_Stable_NN_Controllers.
Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots
Feb 19, 2024



We present Universal Manipulation Interface (UMI) -- a data collection and policy learning framework that allows direct skill transfer from in-the-wild human demonstrations to deployable robot policies. UMI employs hand-held grippers coupled with careful interface design to enable portable, low-cost, and information-rich data collection for challenging bimanual and dynamic manipulation demonstrations. To facilitate deployable policy learning, UMI incorporates a carefully designed policy interface with inference-time latency matching and a relative-trajectory action representation. The resulting learned policies are hardware-agnostic and deployable across multiple robot platforms. Equipped with these features, UMI framework unlocks new robot manipulation capabilities, allowing zero-shot generalizable dynamic, bimanual, precise, and long-horizon behaviors, by only changing the training data for each task. We demonstrate UMI's versatility and efficacy with comprehensive real-world experiments, where policies learned via UMI zero-shot generalize to novel environments and objects when trained on diverse human demonstrations. UMI's hardware and software system is open-sourced at https://umi-gripper.github.io.
Towards Tight Convex Relaxations for Contact-Rich Manipulation
Feb 15, 2024We present a method for global motion planning of robotic systems that interact with the environment through contacts. Our method directly handles the hybrid nature of such tasks using tools from convex optimization. We formulate the motion-planning problem as a shortest-path problem in a graph of convex sets, where a path in the graph corresponds to a contact sequence and a convex set models the quasi-static dynamics within a fixed contact mode. For each contact mode, we use semidefinite programming to relax the nonconvex dynamics that results from the simultaneous optimization of the object's pose, contact locations, and contact forces. The result is a tight convex relaxation of the overall planning problem, that can be efficiently solved and quickly rounded to find a feasible contact-rich trajectory. As a first application of this technique, we focus on the task of planar pushing. Exhaustive experiments show that our convex-optimization method generates plans that are consistently within a small percentage of the global optimum. We demonstrate the quality of these plans on a real robotic system.