 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Feb 06, 2024



Mathematical reasoning poses a significant challenge for language models due to its complex and structured nature. In this paper, we introduce DeepSeekMath 7B, which continues pre-training DeepSeek-Coder-Base-v1.5 7B with 120B math-related tokens sourced from Common Crawl, together with natural language and code data. DeepSeekMath 7B has achieved an impressive score of 51.7% on the competition-level MATH benchmark without relying on external toolkits and voting techniques, approaching the performance level of Gemini-Ultra and GPT-4. Self-consistency over 64 samples from DeepSeekMath 7B achieves 60.9% on MATH. The mathematical reasoning capability of DeepSeekMath is attributed to two key factors: First, we harness the significant potential of publicly available web data through a meticulously engineered data selection pipeline. Second, we introduce Group Relative Policy Optimization (GRPO), a variant of Proximal Policy Optimization (PPO), that enhances mathematical reasoning abilities while concurrently optimizing the memory usage of PPO.
A Double-Graph Based Framework for Frame Semantic Parsing
Jun 18, 2022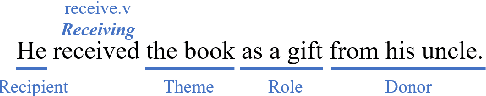
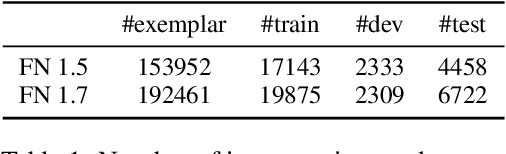
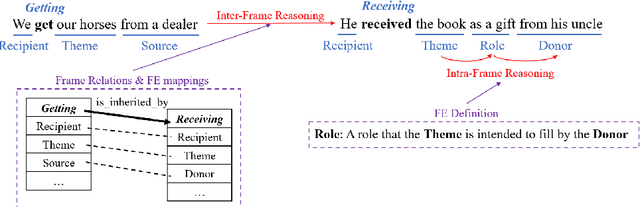
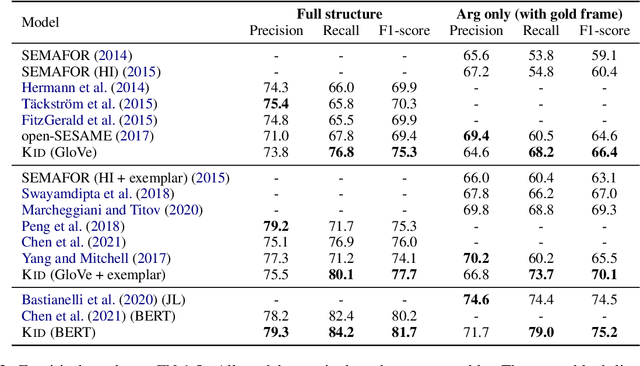
Frame semantic parsing is a fundamental NLP task, which consists of three subtasks: frame identification, argument identification and role classification. Most previous studies tend to neglect relations between different subtasks and arguments and pay little attention to ontological frame knowledge defined in FrameNet. In this paper, we propose a Knowledge-guided Incremental semantic parser with Double-graph (KID). We first introduce Frame Knowledge Graph (FKG), a heterogeneous graph containing both frames and FEs (Frame Elements) built on the frame knowledge so that we can derive knowledge-enhanced representations for frames and FEs. Besides, we propose Frame Semantic Graph (FSG) to represent frame semantic structures extracted from the text with graph structures. In this way, we can transform frame semantic parsing into an incremental graph construction problem to strengthen interactions between subtasks and relations between arguments. Our experiments show that KID outperforms the previous state-of-the-art method by up to 1.7 F1-score on two FrameNet datasets. Our code is availavle at https://github.com/PKUnlp-icler/KID.
A Two-Stream AMR-enhanced Model for Document-level Event Argument Extraction
Apr 30, 2022
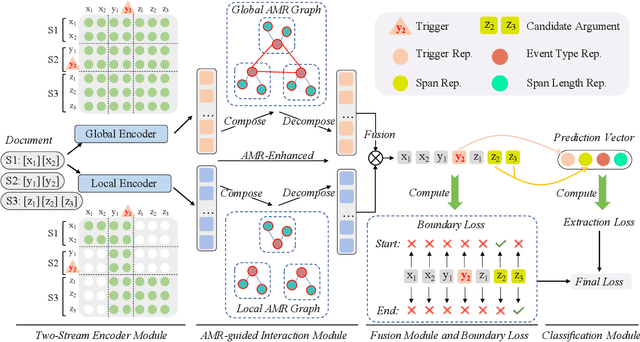

Most previous studies aim at extracting events from a single sentence, while document-level event extraction still remains under-explored. In this paper, we focus on extracting event arguments from an entire document, which mainly faces two critical problems: a) the long-distance dependency between trigger and arguments over sentences; b) the distracting context towards an event in the document. To address these issues, we propose a Two-Stream Abstract meaning Representation enhanced extraction model (TSAR). TSAR encodes the document from different perspectives by a two-stream encoding module, to utilize local and global information and lower the impact of distracting context. Besides, TSAR introduces an AMR-guided interaction module to capture both intra-sentential and inter-sentential features, based on the locally and globally constructed AMR semantic graphs. An auxiliary boundary loss is introduced to enhance the boundary information for text spans explicitly. Extensive experiments illustrate that TSAR outperforms previous state-of-the-art by a large margin, with 2.54 F1 and 5.13 F1 performance gain on the public RAMS and WikiEvents datasets respectively, showing the superiority in the cross-sentence arguments extraction. We release our code in https://github.com/ PKUnlp-icler/TSAR.
ATP: AMRize Then Parse! Enhancing AMR Parsing with PseudoAMRs
Apr 20, 2022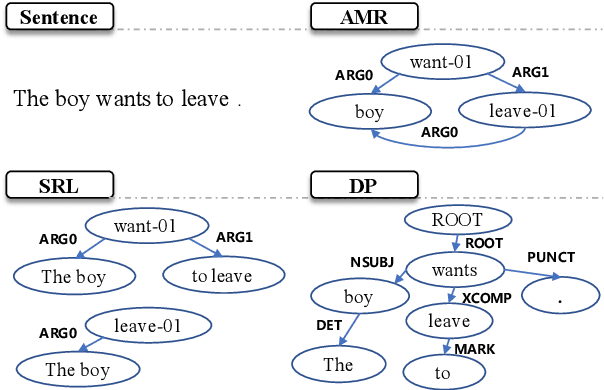

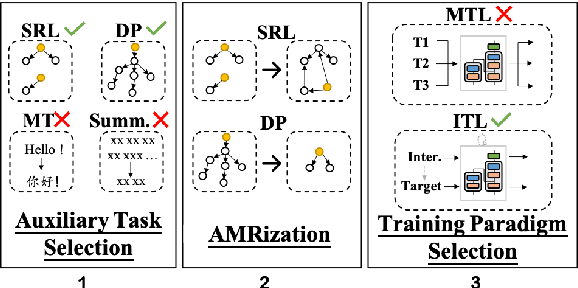
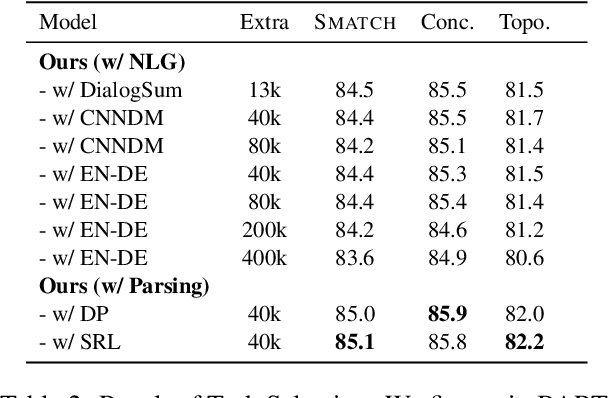
As Abstract Meaning Representation (AMR) implicitly involves compound semantic annotations, we hypothesize auxiliary tasks which are semantically or formally related can better enhance AMR parsing. We find that 1) Semantic role labeling (SRL) and dependency parsing (DP), would bring more performance gain than other tasks e.g. MT and summarization in the text-to-AMR transition even with much less data. 2) To make a better fit for AMR, data from auxiliary tasks should be properly "AMRized" to PseudoAMR before training. Knowledge from shallow level parsing tasks can be better transferred to AMR Parsing with structure transform. 3) Intermediate-task learning is a better paradigm to introduce auxiliary tasks to AMR parsing, compared to multitask learning. From an empirical perspective, we propose a principled method to involve auxiliary tasks to boost AMR parsing. Extensive experiments show that our method achieves new state-of-the-art performance on different benchmarks especially in topology-related scores.
On Effectively Learning of Knowledge in Continual Pre-training
Apr 17, 2022
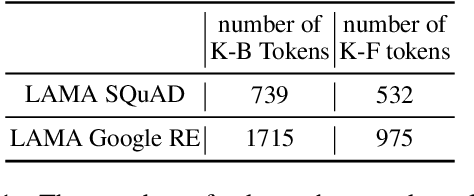
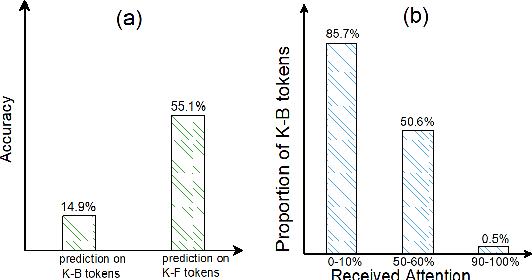

Pre-trained language models (PLMs) like BERT have made significant progress in various downstream NLP tasks. However, by asking models to do cloze-style tests, recent work finds that PLMs are short in acquiring knowledge from unstructured text. To understand the internal behaviour of PLMs in retrieving knowledge, we first define knowledge-baring (K-B) tokens and knowledge-free (K-F) tokens for unstructured text and ask professional annotators to label some samples manually. Then, we find that PLMs are more likely to give wrong predictions on K-B tokens and attend less attention to those tokens inside the self-attention module. Based on these observations, we develop two solutions to help the model learn more knowledge from unstructured text in a fully self-supervised manner. Experiments on knowledge-intensive tasks show the effectiveness of the proposed methods. To our best knowledge, we are the first to explore fully self-supervised learning of knowledge in continual pre-training.
Probing Structured Pruning on Multilingual Pre-trained Models: Settings, Algorithms, and Efficiency
Apr 06, 2022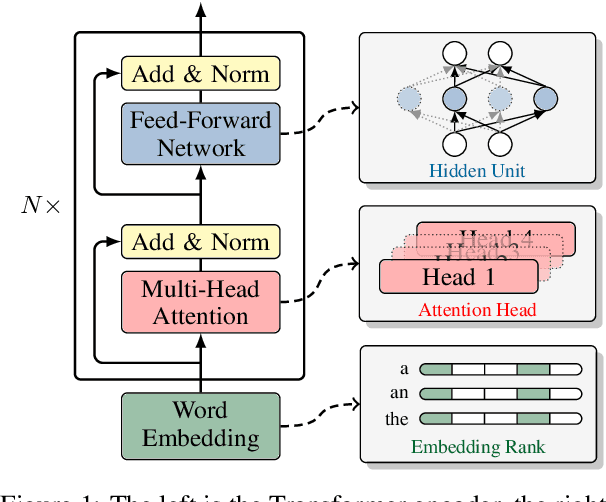
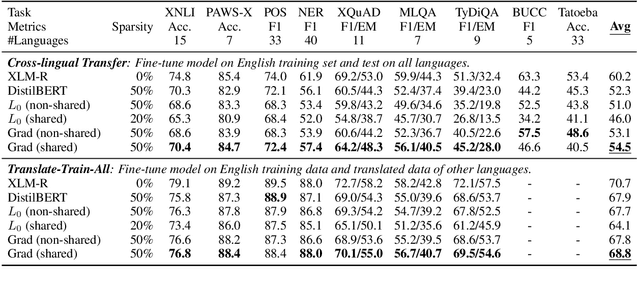
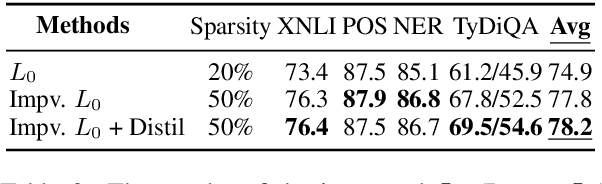
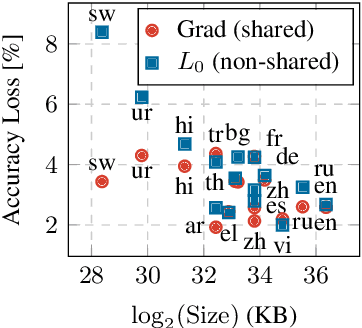
Structured pruning has been extensively studied on monolingual pre-trained language models and is yet to be fully evaluated on their multilingual counterparts. This work investigates three aspects of structured pruning on multilingual pre-trained language models: settings, algorithms, and efficiency. Experiments on nine downstream tasks show several counter-intuitive phenomena: for settings, individually pruning for each language does not induce a better result; for algorithms, the simplest method performs the best; for efficiency, a fast model does not imply that it is also small. To facilitate the comparison on all sparsity levels, we present Dynamic Sparsification, a simple approach that allows training the model once and adapting to different model sizes at inference. We hope this work fills the gap in the study of structured pruning on multilingual pre-trained models and sheds light on future research.
Making Pre-trained Language Models End-to-end Few-shot Learners with Contrastive Prompt Tuning
Apr 01, 2022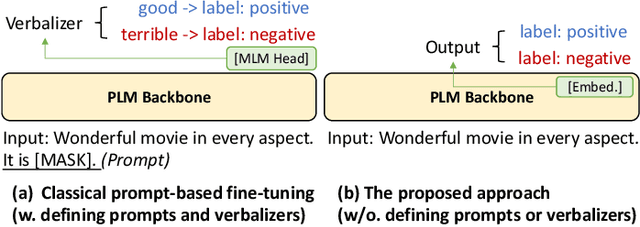

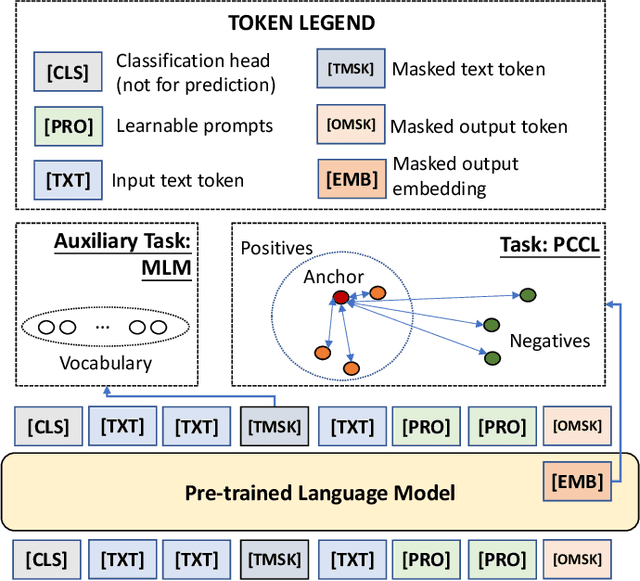
Pre-trained Language Models (PLMs) have achieved remarkable performance for various language understanding tasks in IR systems, which require the fine-tuning process based on labeled training data. For low-resource scenarios, prompt-based learning for PLMs exploits prompts as task guidance and turns downstream tasks into masked language problems for effective few-shot fine-tuning. In most existing approaches, the high performance of prompt-based learning heavily relies on handcrafted prompts and verbalizers, which may limit the application of such approaches in real-world scenarios. To solve this issue, we present CP-Tuning, the first end-to-end Contrastive Prompt Tuning framework for fine-tuning PLMs without any manual engineering of task-specific prompts and verbalizers. It is integrated with the task-invariant continuous prompt encoding technique with fully trainable prompt parameters. We further propose the pair-wise cost-sensitive contrastive learning procedure to optimize the model in order to achieve verbalizer-free class mapping and enhance the task-invariance of prompts. It explicitly learns to distinguish different classes and makes the decision boundary smoother by assigning different costs to easy and hard cases. Experiments over a variety of language understanding tasks used in IR systems and different PLMs show that CP-Tuning outperforms state-of-the-art methods.
Focus on the Target's Vocabulary: Masked Label Smoothing for Machine Translation
Mar 11, 2022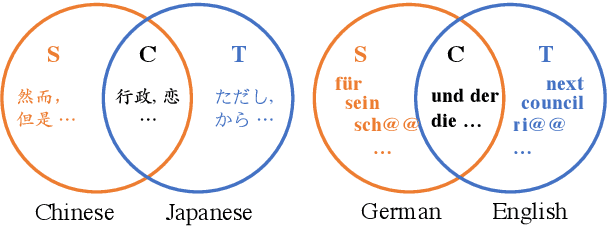
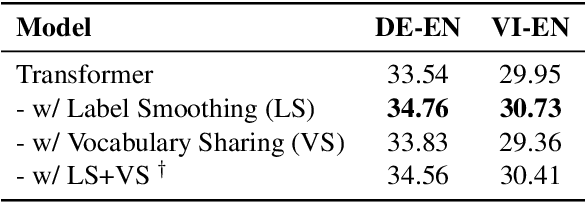

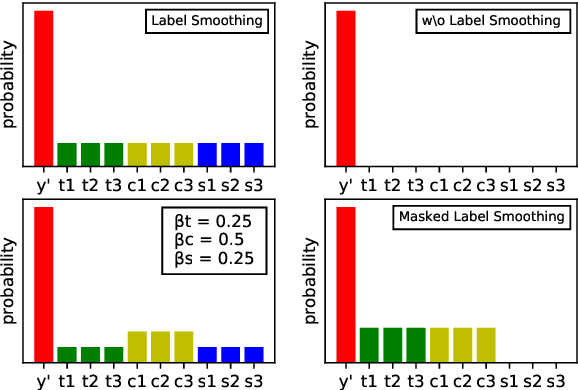
Label smoothing and vocabulary sharing are two widely used techniques in neural machine translation models. However, we argue that simply applying both techniques can be conflicting and even leads to sub-optimal performance. When allocating smoothed probability, original label smoothing treats the source-side words that would never appear in the target language equally to the real target-side words, which could bias the translation model. To address this issue, we propose Masked Label Smoothing (MLS), a new mechanism that masks the soft label probability of source-side words to zero. Simple yet effective, MLS manages to better integrate label smoothing with vocabulary sharing. Our extensive experiments show that MLS consistently yields improvement over original label smoothing on different datasets, including bilingual and multilingual translation from both translation quality and model's calibration. Our code is released at https://github.com/PKUnlp-icler/MLS
From Dense to Sparse: Contrastive Pruning for Better Pre-trained Language Model Compression
Dec 14, 2021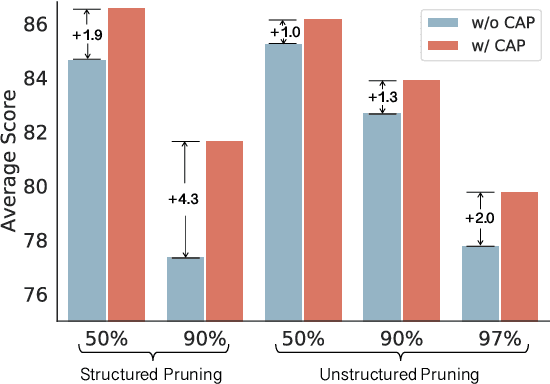
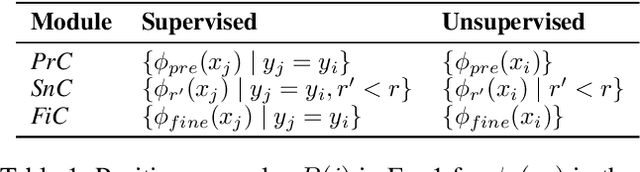
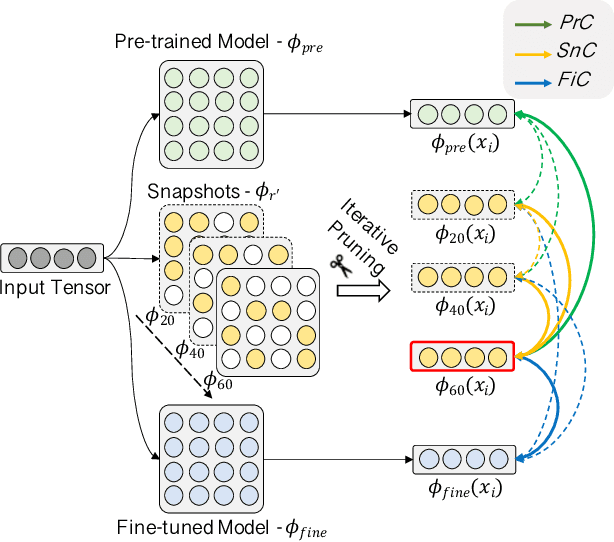
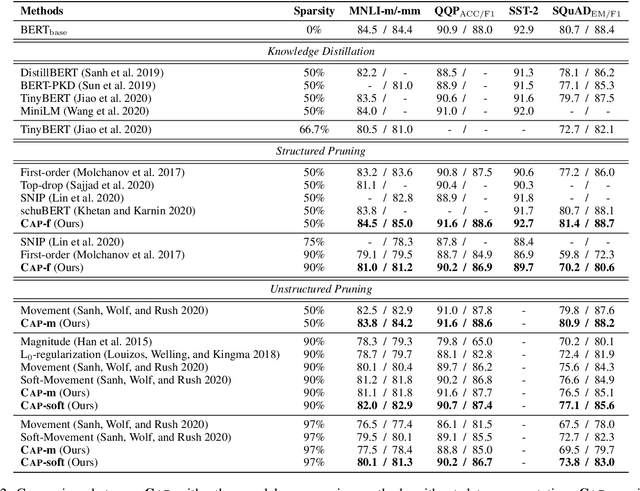
Pre-trained Language Models (PLMs) have achieved great success in various Natural Language Processing (NLP) tasks under the pre-training and fine-tuning paradigm. With large quantities of parameters, PLMs are computation-intensive and resource-hungry. Hence, model pruning has been introduced to compress large-scale PLMs. However, most prior approaches only consider task-specific knowledge towards downstream tasks, but ignore the essential task-agnostic knowledge during pruning, which may cause catastrophic forgetting problem and lead to poor generalization ability. To maintain both task-agnostic and task-specific knowledge in our pruned model, we propose ContrAstive Pruning (CAP) under the paradigm of pre-training and fine-tuning. It is designed as a general framework, compatible with both structured and unstructured pruning. Unified in contrastive learning, CAP enables the pruned model to learn from the pre-trained model for task-agnostic knowledge, and fine-tuned model for task-specific knowledge. Besides, to better retain the performance of the pruned model, the snapshots (i.e., the intermediate models at each pruning iteration) also serve as effective supervisions for pruning. Our extensive experiments show that adopting CAP consistently yields significant improvements, especially in extremely high sparsity scenarios. With only 3% model parameters reserved (i.e., 97% sparsity), CAP successfully achieves 99.2% and 96.3% of the original BERT performance in QQP and MNLI tasks. In addition, our probing experiments demonstrate that the model pruned by CAP tends to achieve better generalization ability.
An Enhanced Span-based Decomposition Method for Few-Shot Sequence Labeling
Sep 27, 2021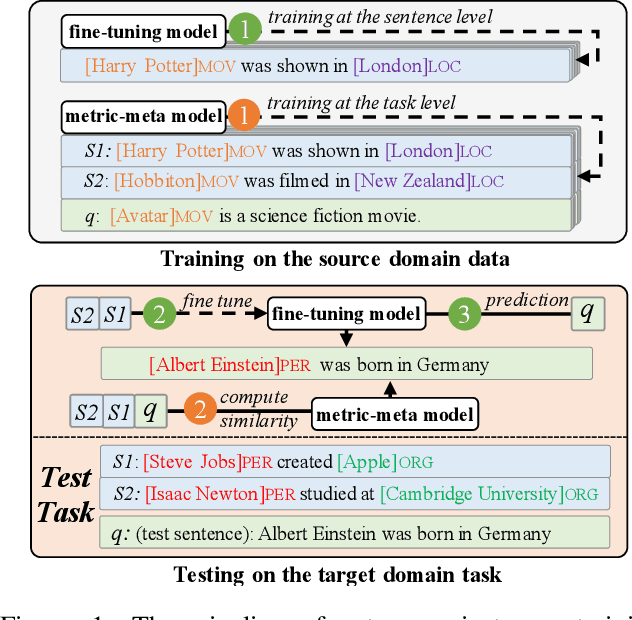

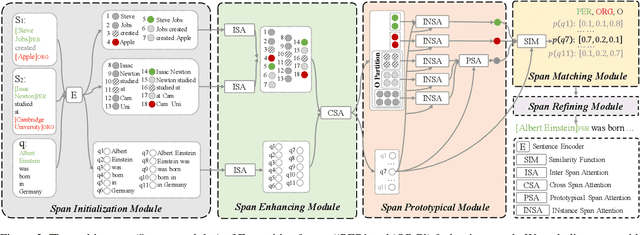
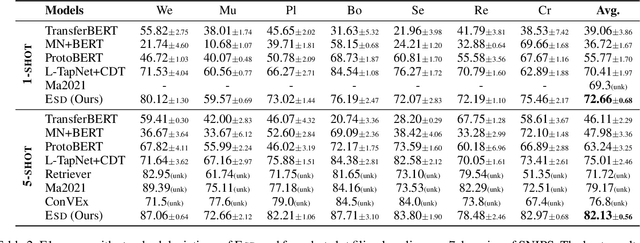
Few-Shot Sequence Labeling (FSSL) is a canonical solution for the tagging models to generalize on an emerging, resource-scarce domain. In this paper, we propose ESD, an Enhanced Span-based Decomposition method, which follows the metric-based meta-learning paradigm for FSSL. ESD improves previous methods from two perspectives: a) Introducing an optimal span decomposition framework. We formulate FSSL as an optimization problem that seeks for an optimal span matching between test query and supporting instances. During inference, we propose a post-processing algorithm to alleviate false positive labeling by resolving span conflicts. b) Enhancing representation for spans and class prototypes. We refine span representation by inter- and cross-span attention, and obtain the class prototypical representation with multi-instance learning. To avoid the semantic drift when representing the O-type (not a specific entity or slot) prototypes, we divide the O-type spans into three categories according to their boundary information. ESD outperforms previous methods in two popular FSSL benchmarks, FewNERD and SNIPS, and is proven to be more robust in the nested and noisy tagging scenarios.