 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaichuan-M4: A Clinical-Grade Medical Agent System for Continuous Care
Jun 09, 2026Baichuan-M4 is Baichuan Intelligence's clinical-grade medical large model, designed for continuous care rather than single-turn medical question answering. It is built as a coordinated medical agent system around three pillars: Baichuan-Harness, a unified runtime that keeps reinforcement-learning training and real-world deployment consistent while enforcing action constraints, tool use, long-term patient memory, and multi-agent coordination; a core reasoning model trained with a continuous-care reinforcement-learning framework that integrates span-level reward modeling (SPAR++), reasoning-path compression, curriculum learning, and stabilized policy optimization; and a clinical tool layer for patient-memory management, authoritative evidence-based retrieval, and multimodal medical perception across documents, X-rays, and dermatology. On a cross-dimensional medical evaluation suite, Baichuan-M4 attains leading results in static medical knowledge and safety, dynamic OSCE-style consultation, long-context clinical memory, evidence-based retrieval, medical document OCR, and multimodal image understanding, while lowering the hallucination rate to 3.3%.
LEMON: Learning Executable Multi-Agent Orchestration via Counterfactual Reinforcement Learning
May 14, 2026Large language models (LLMs) have become a strong foundation for multi-agent systems, but their effectiveness depends heavily on orchestration design. Across different tasks, role design, capacity assignment, and dependency construction jointly affect both solution quality and execution efficiency. Existing approaches automate parts of this design process, yet they often optimize these decisions partially or sequentially, and rely on execution-level feedback that provides limited credit assignment for local orchestration decisions. We propose LEMON (\textbf{L}earning \textbf{E}xecutable \textbf{M}ulti-agent \textbf{O}rchestratio\textbf{N} via Counterfactual Reinforcement Learning), an LLM-based orchestrator that generates an executable orchestration specification. The specification integrates task-specific roles, customized duties, capacity levels, and dependency structure into a single deployable system. To train the orchestrator, we augment the orchestration-level GRPO objective with a localized counterfactual signal that edits role, capacity, or dependency fields and applies the resulting reward contrast only to the edited spans. Experiments on six reasoning and coding benchmarks, including MMLU, GSM8K, AQuA, MultiArith, SVAMP, and HumanEval, show that LEMON achieves state-of-the-art performance among the evaluated multi-agent orchestration methods. Our code is available at https://anonymous.4open.science/r/LEMON-B23C.
Real-time Ad retrieval via LLM-generative Commercial Intention for Sponsored Search Advertising
Apr 02, 2025



The integration of Large Language Models (LLMs) with retrieval systems has shown promising potential in retrieving documents (docs) or advertisements (ads) for a given query. Existing LLM-based retrieval methods generate numeric or content-based DocIDs to retrieve docs/ads. However, the one-to-few mapping between numeric IDs and docs, along with the time-consuming content extraction, leads to semantic inefficiency and limits scalability in large-scale corpora. In this paper, we propose the Real-time Ad REtrieval (RARE) framework, which leverages LLM-generated text called Commercial Intentions (CIs) as an intermediate semantic representation to directly retrieve ads for queries in real-time. These CIs are generated by a customized LLM injected with commercial knowledge, enhancing its domain relevance. Each CI corresponds to multiple ads, yielding a lightweight and scalable set of CIs. RARE has been implemented in a real-world online system, handling daily search volumes in the hundreds of millions. The online implementation has yielded significant benefits: a 5.04% increase in consumption, a 6.37% rise in Gross Merchandise Volume (GMV), a 1.28% enhancement in click-through rate (CTR) and a 5.29% increase in shallow conversions. Extensive offline experiments show RARE's superiority over ten competitive baselines in four major categories.
MemFusionMap: Working Memory Fusion for Online Vectorized HD Map Construction
Sep 26, 2024



High-definition (HD) maps provide environmental information for autonomous driving systems and are essential for safe planning. While existing methods with single-frame input achieve impressive performance for online vectorized HD map construction, they still struggle with complex scenarios and occlusions. We propose MemFusionMap, a novel temporal fusion model with enhanced temporal reasoning capabilities for online HD map construction. Specifically, we contribute a working memory fusion module that improves the model's memory capacity to reason across history frames. We also design a novel temporal overlap heatmap to explicitly inform the model about the temporal overlap information and vehicle trajectory in the Bird's Eye View space. By integrating these two designs, MemFusionMap significantly outperforms existing methods while also maintaining a versatile design for scalability. We conduct extensive evaluation on open-source benchmarks and demonstrate a maximum improvement of 5.4% in mAP over state-of-the-art methods. The code for MemFusionMap will be made open-source upon publication of this paper.
CipherDM: Secure Three-Party Inference for Diffusion Model Sampling
Sep 09, 2024



Diffusion Models (DMs) achieve state-of-the-art synthesis results in image generation and have been applied to various fields. However, DMs sometimes seriously violate user privacy during usage, making the protection of privacy an urgent issue. Using traditional privacy computing schemes like Secure Multi-Party Computation (MPC) directly in DMs faces significant computation and communication challenges. To address these issues, we propose CipherDM, the first novel, versatile and universal framework applying MPC technology to DMs for secure sampling, which can be widely implemented on multiple DM based tasks. We thoroughly analyze sampling latency breakdown, find time-consuming parts and design corresponding secure MPC protocols for computing nonlinear activations including SoftMax, SiLU and Mish. CipherDM is evaluated on popular architectures (DDPM, DDIM) using MNIST dataset and on SD deployed by diffusers. Compared to direct implementation on SPU, our approach improves running time by approximately 1.084\times \sim 2.328\times, and reduces communication costs by approximately 1.212\times \sim 1.791\times.
Strong anti-Hebbian plasticity alters the convexity of network attractor landscapes
Dec 22, 2023



In this paper, we study recurrent neural networks in the presence of pairwise learning rules. We are specifically interested in how the attractor landscapes of such networks become altered as a function of the strength and nature (Hebbian vs. anti-Hebbian) of learning, which may have a bearing on the ability of such rules to mediate large-scale optimization problems. Through formal analysis, we show that a transition from Hebbian to anti-Hebbian learning brings about a pitchfork bifurcation that destroys convexity in the network attractor landscape. In larger-scale settings, this implies that anti-Hebbian plasticity will bring about multiple stable equilibria, and such effects may be outsized at interconnection or `choke' points. Furthermore, attractor landscapes are more sensitive to slower learning rates than faster ones. These results provide insight into the types of objective functions that can be encoded via different pairwise plasticity rules.
A universal and improved mutation strategy for iterative wavefront shaping
Nov 21, 2022Recent advances in iterative wavefront shaping (WFS) techniques have made it possible to manipulate the light focusing and transport in scattering media. To improve the optimization performance, various optimization algorithms and improved strategies have been utilized. Here, a novel guided mutation (GM) strategy is proposed to improve optimization efficiency for iterative WFS. For both phase modulation and binary amplitude modulation, considerable improvements in optimization effect and rate have been obtained using multiple GM-enhanced algorithms. Due of its improvements and universality, GM is beneficial for applications ranging from controlling the transmission of light through disordered media to optical manipulation behind them.
SOM-Net: Unrolling the Subspace-based Optimization for Solving Full-wave Inverse Scattering Problems
Sep 08, 2022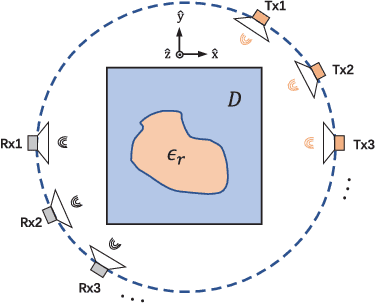
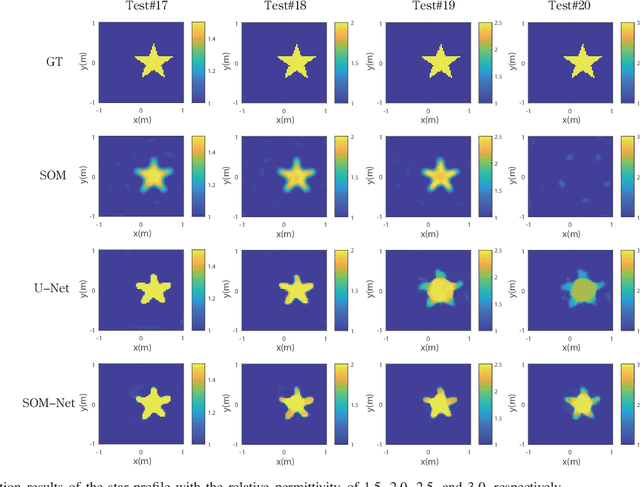
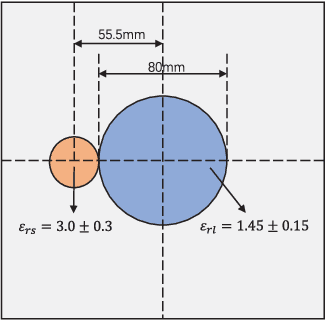
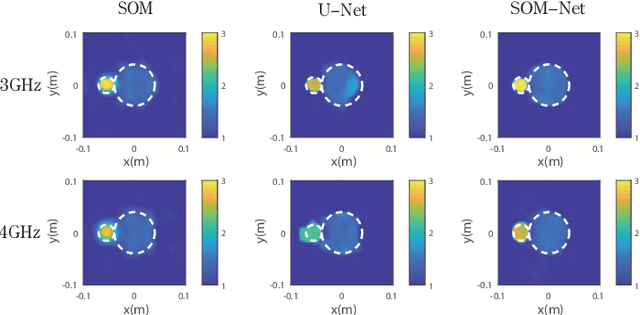
In this paper, an unrolling algorithm of the iterative subspace-based optimization method (SOM) is proposed for solving full-wave inverse scattering problems (ISPs). The unrolling network, named SOM-Net, inherently embeds the Lippmann- Schwinger physical model into the design of network structures. The SOM-Net takes the deterministic induced current and the raw permittivity image obtained from back-propagation (BP) as the input. It then updates the induced current and the permittivity successively in sub-network blocks of the SOM- Net by imitating iterations of the SOM. The final output of the SOM-Net is the full predicted induced current, from which the scattered field and the permittivity image can also be deduced analytically. The parameters of the SOM-Net are optimized in a supervised manner with the total loss to simultaneously ensure the consistency of the induced current, the scattered field, and the permittivity in the governing equations. Numerical tests on both synthetic and experimental data verify the superior performance of the proposed SOM-Net over typical ones. The results on challenging examples like scatterers with tough profiles or high permittivity demonstrate the good generalization ability of the SOM-Net. With the use of deep unrolling technology, this work builds a bridge between traditional iterative methods and deep learning methods for solving ISPs.
A Double-Graph Based Framework for Frame Semantic Parsing
Jun 18, 2022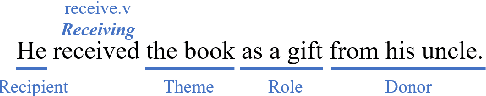
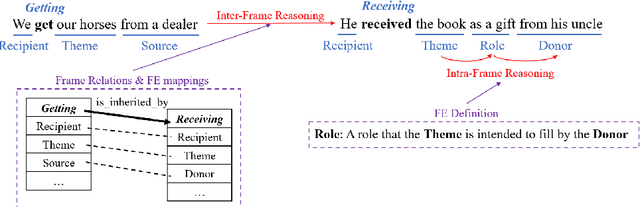
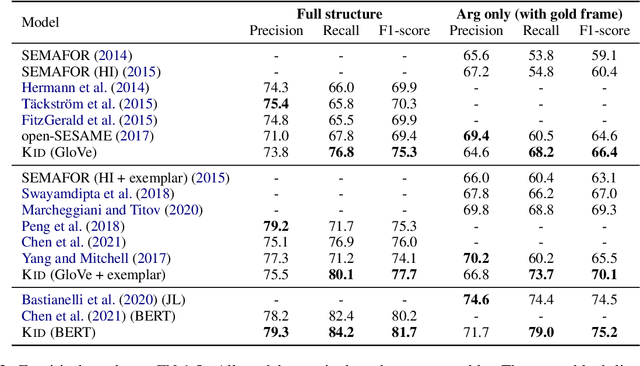
Frame semantic parsing is a fundamental NLP task, which consists of three subtasks: frame identification, argument identification and role classification. Most previous studies tend to neglect relations between different subtasks and arguments and pay little attention to ontological frame knowledge defined in FrameNet. In this paper, we propose a Knowledge-guided Incremental semantic parser with Double-graph (KID). We first introduce Frame Knowledge Graph (FKG), a heterogeneous graph containing both frames and FEs (Frame Elements) built on the frame knowledge so that we can derive knowledge-enhanced representations for frames and FEs. Besides, we propose Frame Semantic Graph (FSG) to represent frame semantic structures extracted from the text with graph structures. In this way, we can transform frame semantic parsing into an incremental graph construction problem to strengthen interactions between subtasks and relations between arguments. Our experiments show that KID outperforms the previous state-of-the-art method by up to 1.7 F1-score on two FrameNet datasets. Our code is availavle at https://github.com/PKUnlp-icler/KID.
A Fast Alternating Minimization Algorithm for Coded Aperture Snapshot Spectral Imaging Based on Sparsity and Deep Image Priors
Jun 12, 2022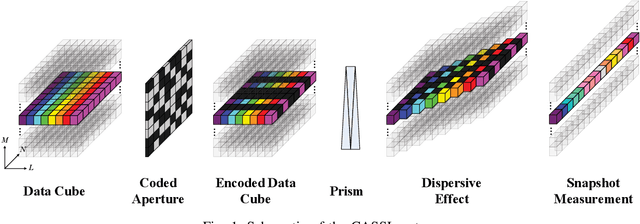
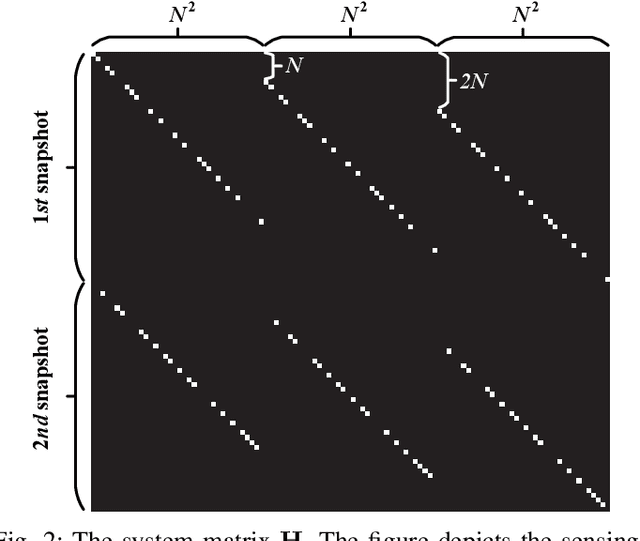
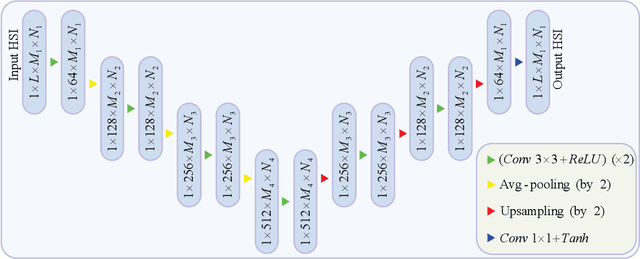

Coded aperture snapshot spectral imaging (CASSI) is a technique used to reconstruct three-dimensional hyperspectral images (HSIs) from one or several two-dimensional projection measurements. However, fewer projection measurements or more spectral channels leads to a severly ill-posed problem, in which case regularization methods have to be applied. In order to significantly improve the accuracy of reconstruction, this paper proposes a fast alternating minimization algorithm based on the sparsity and deep image priors (Fama-SDIP) of natural images. By integrating deep image prior (DIP) into the principle of compressive sensing (CS) reconstruction, the proposed algorithm can achieve state-of-the-art results without any training dataset. Extensive experiments show that Fama-SDIP method significantly outperforms prevailing leading methods on simulation and real HSI datasets.