 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Should Action Generation Begin? A Learnable Source Prior for Generative Robot Policies
Jun 16, 2026Generative robot policies typically begin action generation from an observation-independent standard Gaussian distribution, leaving the choice of source distribution underexplored. This work asks a simple question: where should action generation begin? We propose LeaP, a Learnable source Prior that replaces the standard Gaussian with a proprioception-conditioned diagonal Gaussian over action chunks. Parameterized by a lightweight MLP, LeaP jointly predicts the mean and state-adaptive variance of the source distribution, while keeping the downstream generator architecture and inference solver unchanged. This design provides an observation-informed yet stochastic initialization, allowing the generator to focus on precise action refinement rather than transporting samples from an uninformed noise source. On 15 RoboTwin manipulation tasks, LeaP achieves an average success rate of 81.6%, outperforming four representative baselines -- including deterministic-source methods, a no-prior counterpart, and a diffusion-bridge policy -- by 6.5 to 25.5 percentage points. The same prior consistently improves both flow-matching and diffusion-bridge generators, while using fewer parameters and converging faster. The advantage carries over to real-world deployment, where LeaP attains the best performance. These results suggest that the source distribution is an independent and reusable design axis for generative robot policies, complementary to the choice of generative dynamics.
Beyond Binary Success: A Diagnostic Meta-Evaluation Framework for Fine-Grained Manipulation
May 19, 2026Fine-grained manipulation marks a regime where global scene context no longer suffices, and success hinges on the tight coupling of local attribute grounding, high-fidelity spatial perception, and constraint-respecting motor execution. However, current embodied AI benchmarks collapse these capacities into binary success rates, systematically inflating reported capabilities by up to 70% and masking the architectural bottlenecks that impede real-world deployment. We introduce MetaFine, a diagnostic meta-evaluation framework that disentangles manipulation competency along three axes: understanding, perception, and controlled behavior. Built on a compositional task graph, MetaFine absorbs heterogeneous external benchmarks and reconstructs them into diagnostic scenarios of varying complexity under a unified protocol. Evaluating state-of-the-art vision-language-action (VLA) models through this lens exposes severe dimension-specific failures invisible to conventional metrics. Through targeted causal intervention, we identify the visual encoder's ability to preserve local spatial structure as a key bottleneck for fine-grained precision: improving it directly unlocks previously inaccessible manipulation capabilities without modifying downstream policies. MetaFine further supports hybrid real-sim validation, using limited paired real-world rollouts to calibrate scalable simulation-based estimates for more stable physical benchmarking. By shifting evaluation from ranking to diagnosis, MetaFine turns benchmarking into an actionable compass for repairing the layered capacities underlying genuine physical dexterity. The MetaFine framework, benchmarks, and supporting resources will be publicly released at our project page: https://metafine.github.io/.
RAAP: Retrieval-Augmented Affordance Prediction with Cross-Image Action Alignment
Mar 31, 2026Understanding object affordances is essential for enabling robots to perform purposeful and fine-grained interactions in diverse and unstructured environments. However, existing approaches either rely on retrieval, which is fragile due to sparsity and coverage gaps, or on large-scale models, which frequently mislocalize contact points and mispredict post-contact actions when applied to unseen categories, thereby hindering robust generalization. We introduce Retrieval-Augmented Affordance Prediction (RAAP), a framework that unifies affordance retrieval with alignment-based learning. By decoupling static contact localization and dynamic action direction, RAAP transfers contact points via dense correspondence and predicts action directions through a retrieval-augmented alignment model that consolidates multiple references with dual-weighted attention. Trained on compact subsets of DROID and HOI4D with as few as tens of samples per task, RAAP achieves consistent performance across unseen objects and categories, and enables zero-shot robotic manipulation in both simulation and the real world. Project website: https://github.com/SEU-VIPGroup/RAAP.
AutoFly: Vision-Language-Action Model for UAV Autonomous Navigation in the Wild
Feb 10, 2026Vision-language navigation (VLN) requires intelligent agents to navigate environments by interpreting linguistic instructions alongside visual observations, serving as a cornerstone task in Embodied AI. Current VLN research for unmanned aerial vehicles (UAVs) relies on detailed, pre-specified instructions to guide the UAV along predetermined routes. However, real-world outdoor exploration typically occurs in unknown environments where detailed navigation instructions are unavailable. Instead, only coarse-grained positional or directional guidance can be provided, requiring UAVs to autonomously navigate through continuous planning and obstacle avoidance. To bridge this gap, we propose AutoFly, an end-to-end Vision-Language-Action (VLA) model for autonomous UAV navigation. AutoFly incorporates a pseudo-depth encoder that derives depth-aware features from RGB inputs to enhance spatial reasoning, coupled with a progressive two-stage training strategy that effectively aligns visual, depth, and linguistic representations with action policies. Moreover, existing VLN datasets have fundamental limitations for real-world autonomous navigation, stemming from their heavy reliance on explicit instruction-following over autonomous decision-making and insufficient real-world data. To address these issues, we construct a novel autonomous navigation dataset that shifts the paradigm from instruction-following to autonomous behavior modeling through: (1) trajectory collection emphasizing continuous obstacle avoidance, autonomous planning, and recognition workflows; (2) comprehensive real-world data integration. Experimental results demonstrate that AutoFly achieves a 3.9% higher success rate compared to state-of-the-art VLA baselines, with consistent performance across simulated and real environments.
AnchorDP3: 3D Affordance Guided Sparse Diffusion Policy for Robotic Manipulation
Jun 24, 2025



We present AnchorDP3, a diffusion policy framework for dual-arm robotic manipulation that achieves state-of-the-art performance in highly randomized environments. AnchorDP3 integrates three key innovations: (1) Simulator-Supervised Semantic Segmentation, using rendered ground truth to explicitly segment task-critical objects within the point cloud, which provides strong affordance priors; (2) Task-Conditioned Feature Encoders, lightweight modules processing augmented point clouds per task, enabling efficient multi-task learning through a shared diffusion-based action expert; (3) Affordance-Anchored Keypose Diffusion with Full State Supervision, replacing dense trajectory prediction with sparse, geometrically meaningful action anchors, i.e., keyposes such as pre-grasp pose, grasp pose directly anchored to affordances, drastically simplifying the prediction space; the action expert is forced to predict both robot joint angles and end-effector poses simultaneously, which exploits geometric consistency to accelerate convergence and boost accuracy. Trained on large-scale, procedurally generated simulation data, AnchorDP3 achieves a 98.7% average success rate in the RoboTwin benchmark across diverse tasks under extreme randomization of objects, clutter, table height, lighting, and backgrounds. This framework, when integrated with the RoboTwin real-to-sim pipeline, has the potential to enable fully autonomous generation of deployable visuomotor policies from only scene and instruction, totally eliminating human demonstrations from learning manipulation skills.
An Embarrassingly Simple Approach to Semi-Supervised Few-Shot Learning
Sep 28, 2022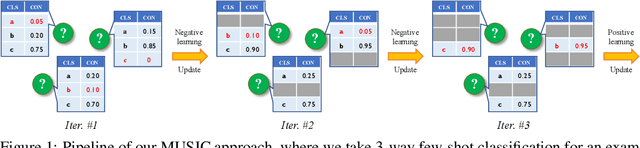
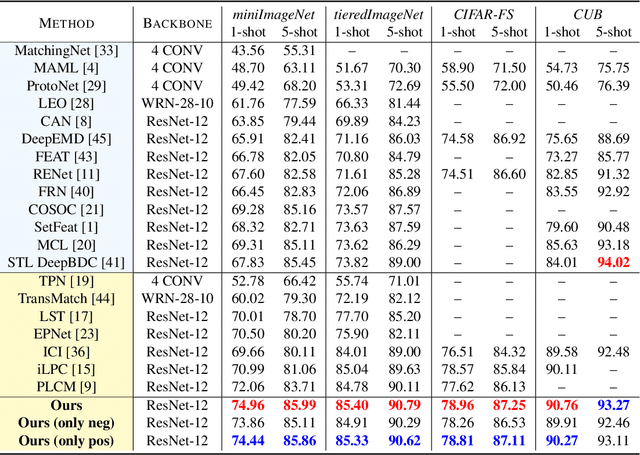
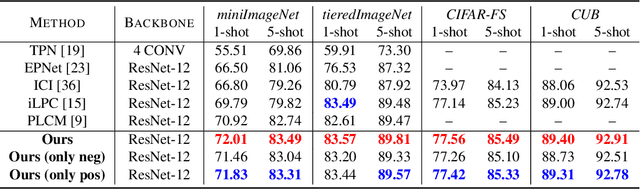
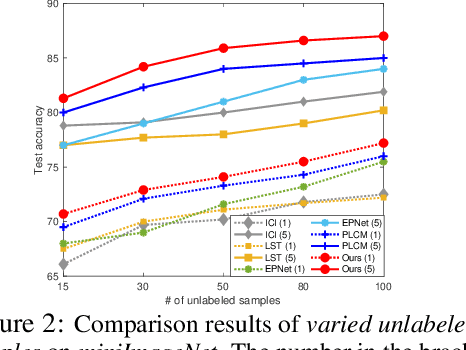
Semi-supervised few-shot learning consists in training a classifier to adapt to new tasks with limited labeled data and a fixed quantity of unlabeled data. Many sophisticated methods have been developed to address the challenges this problem comprises. In this paper, we propose a simple but quite effective approach to predict accurate negative pseudo-labels of unlabeled data from an indirect learning perspective, and then augment the extremely label-constrained support set in few-shot classification tasks. Our approach can be implemented in just few lines of code by only using off-the-shelf operations, yet it is able to outperform state-of-the-art methods on four benchmark datasets.