 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoVQA-G: Self-Improving Agentic Framework for Automated Visual Question Answering and Grounding Annotation
Apr 19, 2026Manual annotation of high-quality visual question answering with grounding (VQA-G) datasets, which pair visual questions with evidential grounding, is crucial for advancing vision-language models (VLMs), but remains unscalable. Existing automated methods are often hindered by two key issues: (1) inconsistent data fidelity due to model hallucinations; (2) brittle verification mechanisms based on simple heuristics. To address these limitations, we introduce AutoVQA-G, a self-improving agentic framework for automated VQA-G annotation. AutoVQA-G employs an iterative refinement loop where a Consistency Evaluation module uses Chain-of-Thought (CoT) reasoning for fine-grained visual verification. Based on this feedback, a memory-augmented Prompt Optimization agent analyzes critiques from failed samples to progressively refine generation prompts. Our experiments show that AutoVQA-G generates VQA-G datasets with superior visual grounding accuracy compared to leading multimodal LLMs, offering a promising approach for creating high-fidelity data to facilitate more robust VLM training and evaluation. Code: https://github.com/rohnson1999/AutoVQA-G
Sparse Adversarial Attack to Object Detection
Dec 26, 2020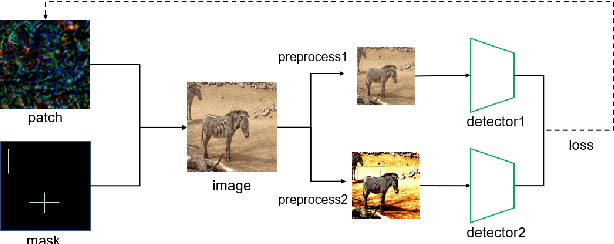


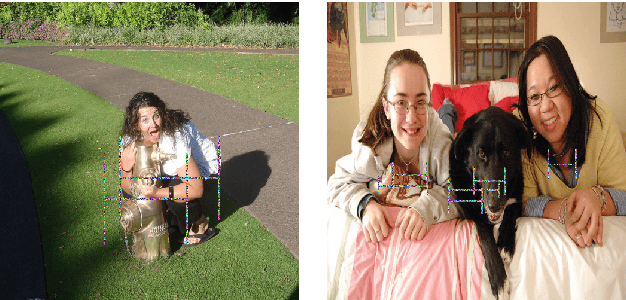
Adversarial examples have gained tons of attention in recent years. Many adversarial attacks have been proposed to attack image classifiers, but few work shift attention to object detectors. In this paper, we propose Sparse Adversarial Attack (SAA) which enables adversaries to perform effective evasion attack on detectors with bounded \emph{l$_{0}$} norm perturbation. We select the fragile position of the image and designed evasion loss function for the task. Experiment results on YOLOv4 and FasterRCNN reveal the effectiveness of our method. In addition, our SAA shows great transferability across different detectors in the black-box attack setting. Codes are available at \emph{https://github.com/THUrssq/Tianchi04}.