 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning for Vehicle-to-Vehicle Cooperative Perception under Lossy Communication
Dec 16, 2022



Deep learning has been widely used in the perception (e.g., 3D object detection) of intelligent vehicle driving. Due to the beneficial Vehicle-to-Vehicle (V2V) communication, the deep learning based features from other agents can be shared to the ego vehicle so as to improve the perception of the ego vehicle. It is named as Cooperative Perception in the V2V research, whose algorithms have been dramatically advanced recently. However, all the existing cooperative perception algorithms assume the ideal V2V communication without considering the possible lossy shared features because of the Lossy Communication (LC) which is common in the complex real-world driving scenarios. In this paper, we first study the side effect (e.g., detection performance drop) by the lossy communication in the V2V Cooperative Perception, and then we propose a novel intermediate LC-aware feature fusion method to relieve the side effect of lossy communication by a LC-aware Repair Network (LCRN) and enhance the interaction between the ego vehicle and other vehicles by a specially designed V2V Attention Module (V2VAM) including intra-vehicle attention of ego vehicle and uncertainty-aware inter-vehicle attention. The extensive experiment on the public cooperative perception dataset OPV2V (based on digital-twin CARLA simulator) demonstrates that the proposed method is quite effective for the cooperative point cloud based 3D object detection under lossy V2V communication.
Analyzing Infrastructure LiDAR Placement with Realistic LiDAR
Nov 29, 2022



Recently, Vehicle-to-Everything(V2X) cooperative perception has attracted increasing attention. Infrastructure sensors play a critical role in this research field, however, how to find the optimal placement of infrastructure sensors is rarely studied. In this paper, we investigate the problem of infrastructure sensor placement and propose a pipeline that can efficiently and effectively find optimal installation positions for infrastructure sensors in a realistic simulated environment. To better simulate and evaluate LiDAR placement, we establish a Realistic LiDAR Simulation library that can simulate the unique characteristics of different popular LiDARs and produce high-fidelity LiDAR point clouds in the CARLA simulator. Through simulating point cloud data in different LiDAR placements, we can evaluate the perception accuracy of these placements using multiple detection models. Then, we analyze the correlation between the point cloud distribution and perception accuracy by calculating the density and uniformity of regions of interest. Experiments show that the placement of infrastructure LiDAR can heavily affect the accuracy of perception. We also analyze the correlation between perception performance in the region of interest and LiDAR point cloud distribution and validate that density and uniformity can be indicators of performance.
Automated Driving Systems Data Acquisition and Processing Platform
Nov 24, 2022This paper presents an automated driving system (ADS) data acquisition and processing platform for vehicle trajectory extraction, reconstruction, and evaluation based on connected automated vehicle (CAV) cooperative perception. This platform presents a holistic pipeline from the raw advanced sensory data collection to data processing, which can process the sensor data from multiple CAVs and extract the objects' Identity (ID) number, position, speed, and orientation information in the map and Frenet coordinates. First, the ADS data acquisition and analytics platform are presented. Specifically, the experimental CAVs platform and sensor configuration are shown, and the processing software, including a deep-learning-based object detection algorithm using LiDAR information, a late fusion scheme to leverage cooperative perception to fuse the detected objects from multiple CAVs, and a multi-object tracking method is introduced. To further enhance the object detection and tracking results, high definition maps consisting of point cloud and vector maps are generated and forwarded to a world model to filter out the objects off the road and extract the objects' coordinates in Frenet coordinates and the lane information. In addition, a post-processing method is proposed to refine trajectories from the object tracking algorithms. Aiming to tackle the ID switch issue of the object tracking algorithm, a fuzzy-logic-based approach is proposed to detect the discontinuous trajectories of the same object. Finally, results, including object detection and tracking and a late fusion scheme, are presented, and the post-processing algorithm's improvements in noise level and outlier removal are discussed, confirming the functionality and effectiveness of the proposed holistic data collection and processing platform.
Domain Adaptive Object Detection for Autonomous Driving under Foggy Weather
Oct 27, 2022



Most object detection methods for autonomous driving usually assume a consistent feature distribution between training and testing data, which is not always the case when weathers differ significantly. The object detection model trained under clear weather might not be effective enough in foggy weather because of the domain gap. This paper proposes a novel domain adaptive object detection framework for autonomous driving under foggy weather. Our method leverages both image-level and object-level adaptation to diminish the domain discrepancy in image style and object appearance. To further enhance the model's capabilities under challenging samples, we also come up with a new adversarial gradient reversal layer to perform adversarial mining for the hard examples together with domain adaptation. Moreover, we propose to generate an auxiliary domain by data augmentation to enforce a new domain-level metric regularization. Experimental results on public benchmarks show the effectiveness and accuracy of the proposed method. The code is available at https://github.com/jinlong17/DA-Detect.
Bridging the Domain Gap for Multi-Agent Perception
Oct 16, 2022Existing multi-agent perception algorithms usually select to share deep neural features extracted from raw sensing data between agents, achieving a trade-off between accuracy and communication bandwidth limit. However, these methods assume all agents have identical neural networks, which might not be practical in the real world. The transmitted features can have a large domain gap when the models differ, leading to a dramatic performance drop in multi-agent perception. In this paper, we propose the first lightweight framework to bridge such domain gaps for multi-agent perception, which can be a plug-in module for most existing systems while maintaining confidentiality. Our framework consists of a learnable feature resizer to align features in multiple dimensions and a sparse cross-domain transformer for domain adaption. Extensive experiments on the public multi-agent perception dataset V2XSet have demonstrated that our method can effectively bridge the gap for features from different domains and outperform other baseline methods significantly by at least 8% for point-cloud-based 3D object detection.
V2XP-ASG: Generating Adversarial Scenes for Vehicle-to-Everything Perception
Sep 27, 2022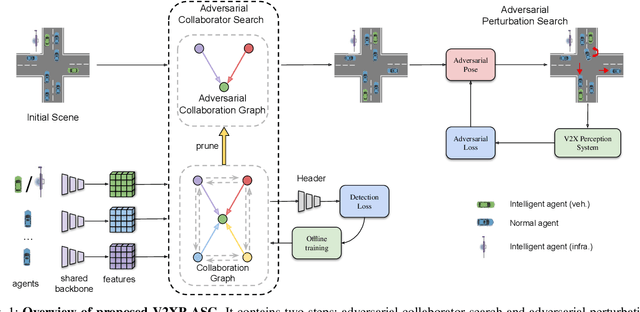
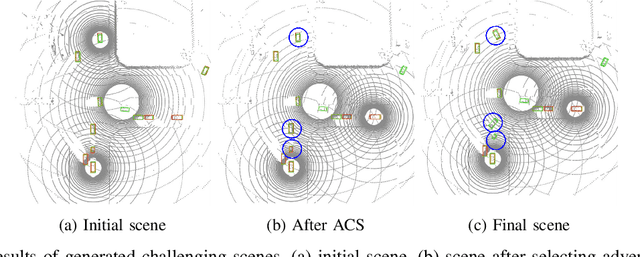
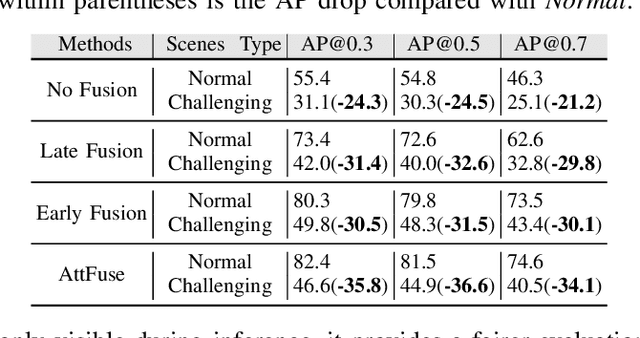

Recent advancements in Vehicle-to-Everything communication technology have enabled autonomous vehicles to share sensory information to obtain better perception performance. With the rapid growth of autonomous vehicles and intelligent infrastructure, the V2X perception systems will soon be deployed at scale, which raises a safety-critical question: how can we evaluate and improve its performance under challenging traffic scenarios before the real-world deployment? Collecting diverse large-scale real-world test scenes seems to be the most straightforward solution, but it is expensive and time-consuming, and the collections can only cover limited scenarios. To this end, we propose the first open adversarial scene generator V2XP-ASG that can produce realistic, challenging scenes for modern LiDAR-based multi-agent perception system. V2XP-ASG learns to construct an adversarial collaboration graph and simultaneously perturb multiple agents' poses in an adversarial and plausible manner. The experiments demonstrate that V2XP-ASG can effectively identify challenging scenes for a large range of V2X perception systems. Meanwhile, by training on the limited number of generated challenging scenes, the accuracy of V2X perception systems can be further improved by 12.3% on challenging and 4% on normal scenes.
Diffusion Models: A Comprehensive Survey of Methods and Applications
Sep 15, 2022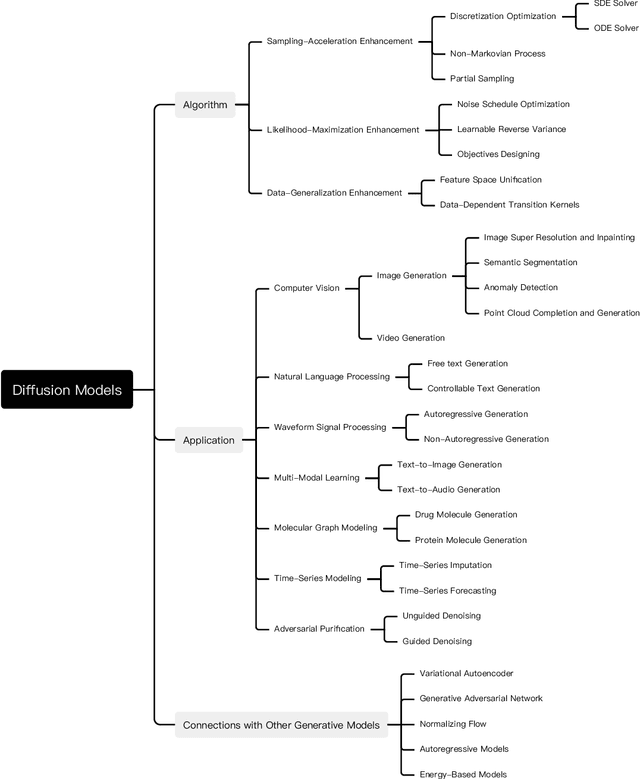
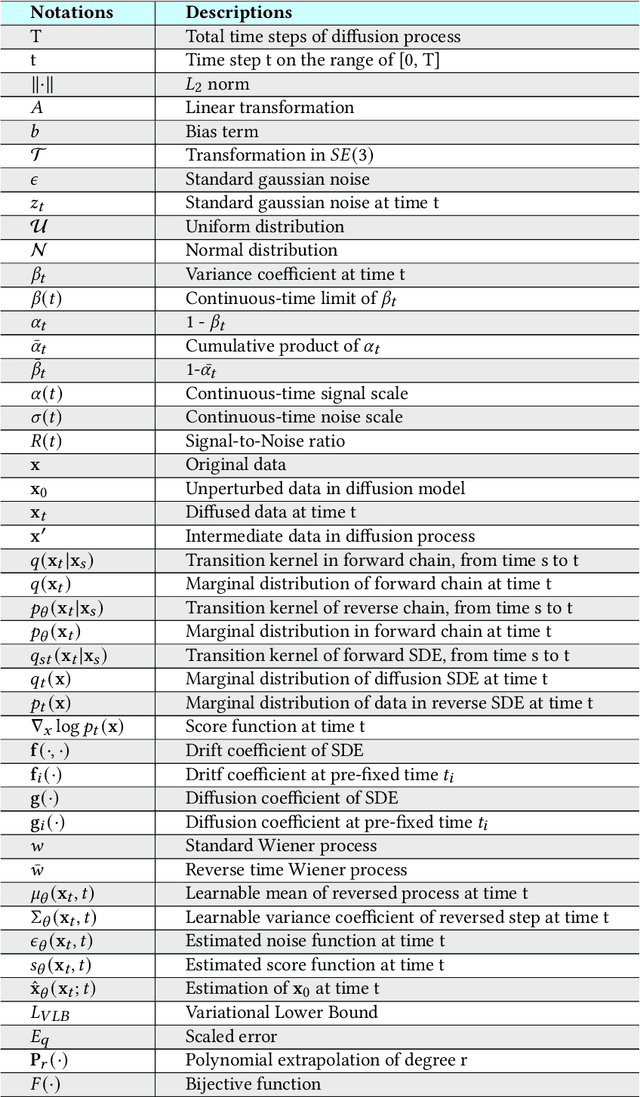
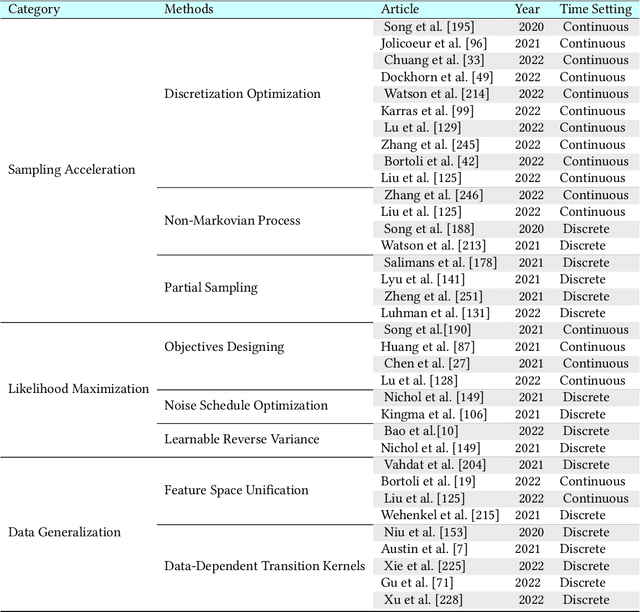
Diffusion models are a class of deep generative models that have shown impressive results on various tasks with a solid theoretical foundation. Despite demonstrated success than state-of-the-art approaches, diffusion models often entail costly sampling procedures and sub-optimal likelihood estimation. Significant efforts have been made to improve the performance of diffusion models in various aspects. In this article, we present a comprehensive review of existing variants of diffusion models. Specifically, we provide the taxonomy of diffusion models and categorize them into three types: sampling-acceleration enhancement, likelihood-maximization enhancement, and data-generalization enhancement. We also introduce the other generative models (i.e., variational autoencoders, generative adversarial networks, normalizing flow, autoregressive models, and energy-based models) and discuss the connections between diffusion models and these generative models. Then we review the applications of diffusion models, including computer vision, natural language processing, waveform signal processing, multi-modal modeling, molecular graph generation, time series modeling, and adversarial purification. Furthermore, we propose new perspectives pertaining to the development of generative models. Github: https://github.com/YangLing0818/Diffusion-Models-Papers-Survey-Taxonomy.
CoBEVT: Cooperative Bird's Eye View Semantic Segmentation with Sparse Transformers
Jul 05, 2022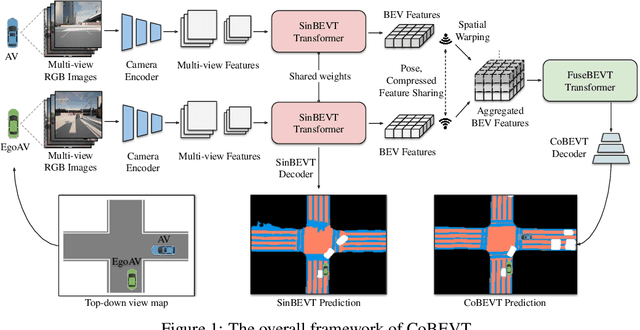

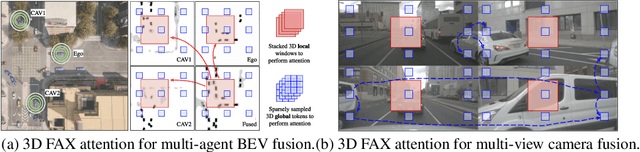
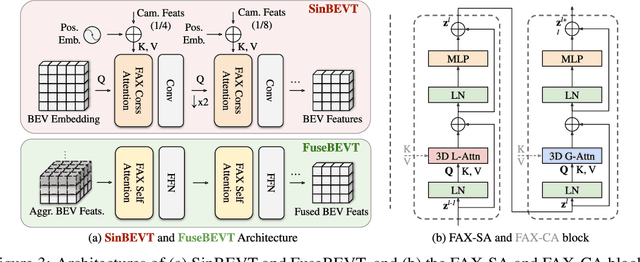
Bird's eye view (BEV) semantic segmentation plays a crucial role in spatial sensing for autonomous driving. Although recent literature has made significant progress on BEV map understanding, they are all based on single-agent camera-based systems which are difficult to handle occlusions and detect distant objects in complex traffic scenes. Vehicle-to-Vehicle (V2V) communication technologies have enabled autonomous vehicles to share sensing information, which can dramatically improve the perception performance and range as compared to single-agent systems. In this paper, we propose CoBEVT, the first generic multi-agent multi-camera perception framework that can cooperatively generate BEV map predictions. To efficiently fuse camera features from multi-view and multi-agent data in an underlying Transformer architecture, we design a fused axial attention or FAX module, which can capture sparsely local and global spatial interactions across views and agents. The extensive experiments on the V2V perception dataset, OPV2V, demonstrate that CoBEVT achieves state-of-the-art performance for cooperative BEV semantic segmentation. Moreover, CoBEVT is shown to be generalizable to other tasks, including 1) BEV segmentation with single-agent multi-camera and 2) 3D object detection with multi-agent LiDAR systems, and achieves state-of-the-art performance with real-time inference speed.
Pik-Fix: Restoring and Colorizing Old Photos
May 11, 2022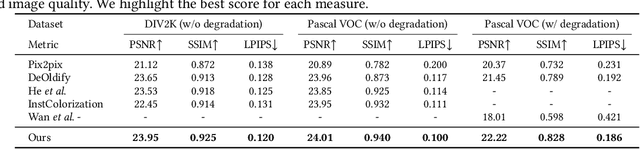
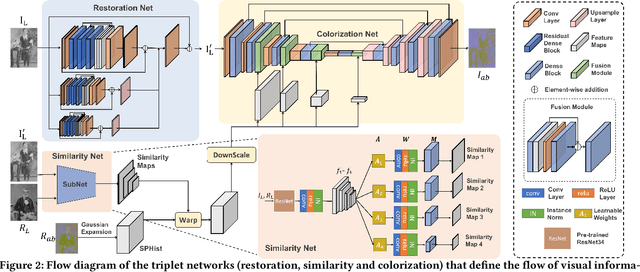
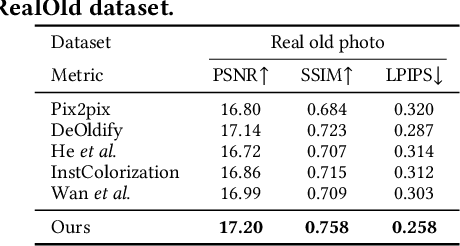

Restoring and inpainting the visual memories that are present, but often impaired, in old photos remains an intriguing but unsolved research topic. Decades-old photos often suffer from severe and commingled degradation such as cracks, defocus, and color-fading, which are difficult to treat individually and harder to repair when they interact. Deep learning presents a plausible avenue, but the lack of large-scale datasets of old photos makes addressing this restoration task very challenging. Here we present a novel reference-based end-to-end learning framework that is able to both repair and colorize old and degraded pictures. Our proposed framework consists of three modules: a restoration sub-network that conducts restoration from degradations, a similarity sub-network that performs color histogram matching and color transfer, and a colorization subnet that learns to predict the chroma elements of images that have been conditioned on chromatic reference signals. The overall system makes use of color histogram priors from reference images, which greatly reduces the need for large-scale training data. We have also created a first-of-a-kind public dataset of real old photos that are paired with ground truth "pristine" photos that have been that have been manually restored by PhotoShop experts. We conducted extensive experiments on this dataset and synthetic datasets, and found that our method significantly outperforms previous state-of-the-art models using both qualitative comparisons and quantitative measurements.
Model-Agnostic Multi-Agent Perception Framework
Mar 24, 2022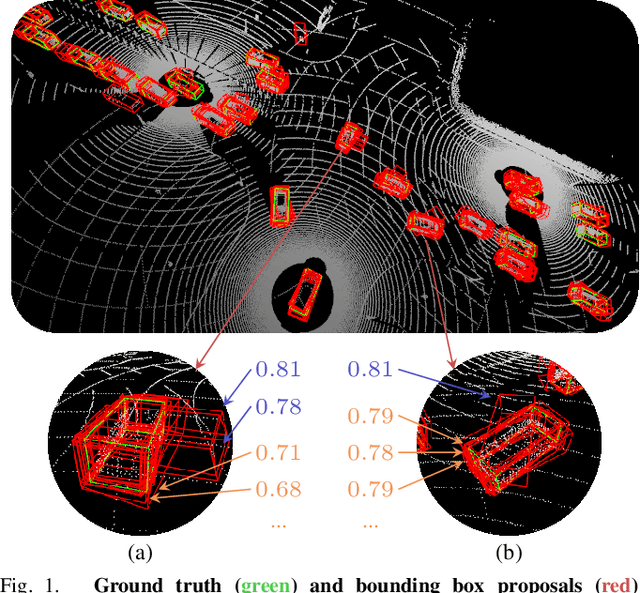
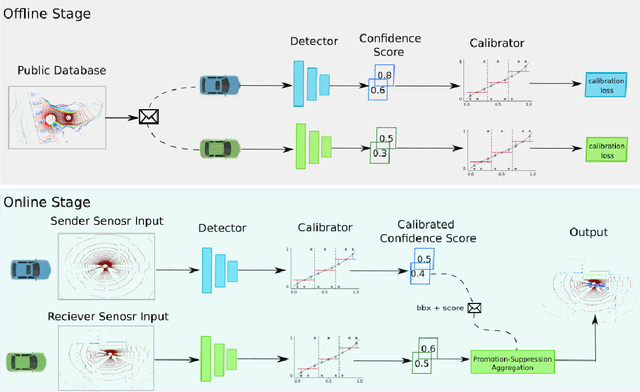
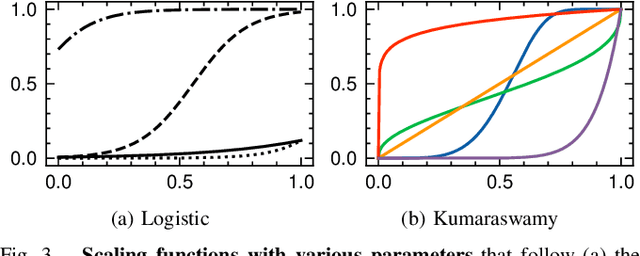
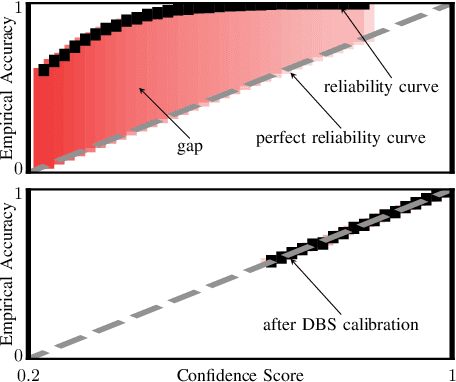
Existing multi-agent perception systems assume that every agent utilizes the same models with identical parameters and architecture, which is often impractical in the real world. The significant performance boost brought by the multi-agent system can be degraded dramatically when the perception models are noticeably different. In this work, we propose a model-agnostic multi-agent framework to reduce the negative effect caused by model discrepancies and maintain confidentiality. Specifically, we consider the perception heterogeneity between agents by integrating a novel uncertainty calibrator which can eliminate the bias among agents' predicted confidence scores. Each agent performs such calibration independently on a standard public database, and therefore the intellectual property can be protected. To further refine the detection accuracy, we also propose a new algorithm called Promotion-Suppression Aggregation (PSA) that considers not only the confidence score of proposals but also the spatial agreement of their neighbors. Our experiments emphasize the necessity of model calibration across different agents, and the results show that our proposed approach outperforms the state-of-the-art baseline methods for 3D object detection on the open OPV2V dataset.