 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISA: Group-wise Visual Token Selection and Aggregation via Graph Summarization for Efficient MLLMs Inference
Aug 25, 2025In this study, we introduce a novel method called group-wise \textbf{VI}sual token \textbf{S}election and \textbf{A}ggregation (VISA) to address the issue of inefficient inference stemming from excessive visual tokens in multimoal large language models (MLLMs). Compared with previous token pruning approaches, our method can preserve more visual information while compressing visual tokens. We first propose a graph-based visual token aggregation (VTA) module. VTA treats each visual token as a node, forming a graph based on semantic similarity among visual tokens. It then aggregates information from removed tokens into kept tokens based on this graph, producing a more compact visual token representation. Additionally, we introduce a group-wise token selection strategy (GTS) to divide visual tokens into kept and removed ones, guided by text tokens from the final layers of each group. This strategy progressively aggregates visual information, enhancing the stability of the visual information extraction process. We conduct comprehensive experiments on LLaVA-1.5, LLaVA-NeXT, and Video-LLaVA across various benchmarks to validate the efficacy of VISA. Our method consistently outperforms previous methods, achieving a superior trade-off between model performance and inference speed. The code is available at https://github.com/mobiushy/VISA.
DS$^2$Net: Detail-Semantic Deep Supervision Network for Medical Image Segmentation
Aug 06, 2025



Deep Supervision Networks exhibit significant efficacy for the medical imaging community. Nevertheless, existing work merely supervises either the coarse-grained semantic features or fine-grained detailed features in isolation, which compromises the fact that these two types of features hold vital relationships in medical image analysis. We advocate the powers of complementary feature supervision for medical image segmentation, by proposing a Detail-Semantic Deep Supervision Network (DS$^2$Net). DS$^2$Net navigates both low-level detailed and high-level semantic feature supervision through Detail Enhance Module (DEM) and Semantic Enhance Module (SEM). DEM and SEM respectively harness low-level and high-level feature maps to create detail and semantic masks for enhancing feature supervision. This is a novel shift from single-view deep supervision to multi-view deep supervision. DS$^2$Net is also equipped with a novel uncertainty-based supervision loss that adaptively assigns the supervision strength of features within distinct scales based on their uncertainty, thus circumventing the sub-optimal heuristic design that typifies previous works. Through extensive experiments on six benchmarks captured under either colonoscopy, ultrasound and microscope, we demonstrate that DS$^2$Net consistently outperforms state-of-the-art methods for medical image analysis.
MIHBench: Benchmarking and Mitigating Multi-Image Hallucinations in Multimodal Large Language Models
Aug 01, 2025Despite growing interest in hallucination in Multimodal Large Language Models, existing studies primarily focus on single-image settings, leaving hallucination in multi-image scenarios largely unexplored. To address this gap, we conduct the first systematic study of hallucinations in multi-image MLLMs and propose MIHBench, a benchmark specifically tailored for evaluating object-related hallucinations across multiple images. MIHBench comprises three core tasks: Multi-Image Object Existence Hallucination, Multi-Image Object Count Hallucination, and Object Identity Consistency Hallucination, targeting semantic understanding across object existence, quantity reasoning, and cross-view identity consistency. Through extensive evaluation, we identify key factors associated with the occurrence of multi-image hallucinations, including: a progressive relationship between the number of image inputs and the likelihood of hallucination occurrences; a strong correlation between single-image hallucination tendencies and those observed in multi-image contexts; and the influence of same-object image ratios and the positional placement of negative samples within image sequences on the occurrence of object identity consistency hallucination. To address these challenges, we propose a Dynamic Attention Balancing mechanism that adjusts inter-image attention distributions while preserving the overall visual attention proportion. Experiments across multiple state-of-the-art MLLMs demonstrate that our method effectively reduces hallucination occurrences and enhances semantic integration and reasoning stability in multi-image scenarios.
Towards Universal Modal Tracking with Online Dense Temporal Token Learning
Jul 27, 2025



We propose a universal video-level modality-awareness tracking model with online dense temporal token learning (called {\modaltracker}). It is designed to support various tracking tasks, including RGB, RGB+Thermal, RGB+Depth, and RGB+Event, utilizing the same model architecture and parameters. Specifically, our model is designed with three core goals: \textbf{Video-level Sampling}. We expand the model's inputs to a video sequence level, aiming to see a richer video context from an near-global perspective. \textbf{Video-level Association}. Furthermore, we introduce two simple yet effective online dense temporal token association mechanisms to propagate the appearance and motion trajectory information of target via a video stream manner. \textbf{Modality Scalable}. We propose two novel gated perceivers that adaptively learn cross-modal representations via a gated attention mechanism, and subsequently compress them into the same set of model parameters via a one-shot training manner for multi-task inference. This new solution brings the following benefits: (i) The purified token sequences can serve as temporal prompts for the inference in the next video frames, whereby previous information is leveraged to guide future inference. (ii) Unlike multi-modal trackers that require independent training, our one-shot training scheme not only alleviates the training burden, but also improves model representation. Extensive experiments on visible and multi-modal benchmarks show that our {\modaltracker} achieves a new \textit{SOTA} performance. The code will be available at https://github.com/GXNU-ZhongLab/ODTrack.
GS-Bias: Global-Spatial Bias Learner for Single-Image Test-Time Adaptation of Vision-Language Models
Jul 16, 2025Recent advances in test-time adaptation (TTA) for Vision-Language Models (VLMs) have garnered increasing attention, particularly through the use of multiple augmented views of a single image to boost zero-shot generalization. Unfortunately, existing methods fail to strike a satisfactory balance between performance and efficiency, either due to excessive overhead of tuning text prompts or unstable benefits from handcrafted, training-free visual feature enhancement. In this paper, we present Global-Spatial Bias Learner (GS-Bias), an efficient and effective TTA paradigm that incorporates two learnable biases during TTA, unfolded as the global bias and spatial bias. Particularly, the global bias captures the global semantic features of a test image by learning consistency across augmented views, while spatial bias learns the semantic coherence between regions in the image's spatial visual representation. It is worth highlighting that these two sets of biases are directly added to the logits outputed by the pretrained VLMs, which circumvent the full backpropagation through VLM that hinders the efficiency of existing TTA methods. This endows GS-Bias with extremely high efficiency while achieving state-of-the-art performance on 15 benchmark datasets. For example, it achieves a 2.23% improvement over TPT in cross-dataset generalization and a 2.72% improvement in domain generalization, while requiring only 6.5% of TPT's memory usage on ImageNet.
AIGI-Holmes: Towards Explainable and Generalizable AI-Generated Image Detection via Multimodal Large Language Models
Jul 03, 2025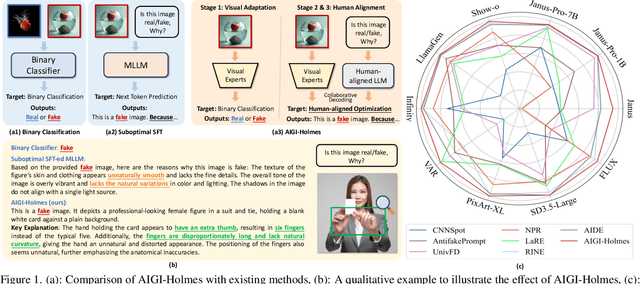
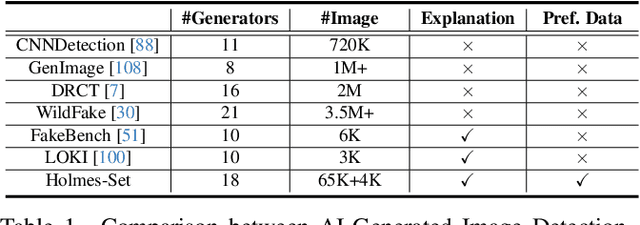
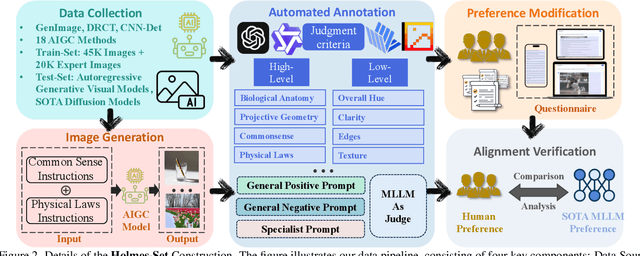
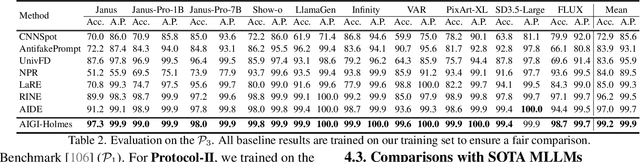
The rapid development of AI-generated content (AIGC) technology has led to the misuse of highly realistic AI-generated images (AIGI) in spreading misinformation, posing a threat to public information security. Although existing AIGI detection techniques are generally effective, they face two issues: 1) a lack of human-verifiable explanations, and 2) a lack of generalization in the latest generation technology. To address these issues, we introduce a large-scale and comprehensive dataset, Holmes-Set, which includes the Holmes-SFTSet, an instruction-tuning dataset with explanations on whether images are AI-generated, and the Holmes-DPOSet, a human-aligned preference dataset. Our work introduces an efficient data annotation method called the Multi-Expert Jury, enhancing data generation through structured MLLM explanations and quality control via cross-model evaluation, expert defect filtering, and human preference modification. In addition, we propose Holmes Pipeline, a meticulously designed three-stage training framework comprising visual expert pre-training, supervised fine-tuning, and direct preference optimization. Holmes Pipeline adapts multimodal large language models (MLLMs) for AIGI detection while generating human-verifiable and human-aligned explanations, ultimately yielding our model AIGI-Holmes. During the inference stage, we introduce a collaborative decoding strategy that integrates the model perception of the visual expert with the semantic reasoning of MLLMs, further enhancing the generalization capabilities. Extensive experiments on three benchmarks validate the effectiveness of our AIGI-Holmes.
DeOcc-1-to-3: 3D De-Occlusion from a Single Image via Self-Supervised Multi-View Diffusion
Jun 26, 2025Reconstructing 3D objects from a single image is a long-standing challenge, especially under real-world occlusions. While recent diffusion-based view synthesis models can generate consistent novel views from a single RGB image, they generally assume fully visible inputs and fail when parts of the object are occluded. This leads to inconsistent views and degraded 3D reconstruction quality. To overcome this limitation, we propose an end-to-end framework for occlusion-aware multi-view generation. Our method directly synthesizes six structurally consistent novel views from a single partially occluded image, enabling downstream 3D reconstruction without requiring prior inpainting or manual annotations. We construct a self-supervised training pipeline using the Pix2Gestalt dataset, leveraging occluded-unoccluded image pairs and pseudo-ground-truth views to teach the model structure-aware completion and view consistency. Without modifying the original architecture, we fully fine-tune the view synthesis model to jointly learn completion and multi-view generation. Additionally, we introduce the first benchmark for occlusion-aware reconstruction, encompassing diverse occlusion levels, object categories, and mask patterns. This benchmark provides a standardized protocol for evaluating future methods under partial occlusions. Our code is available at https://github.com/Quyans/DeOcc123.
SpaCE-10: A Comprehensive Benchmark for Multimodal Large Language Models in Compositional Spatial Intelligence
Jun 09, 2025Multimodal Large Language Models (MLLMs) have achieved remarkable progress in various multimodal tasks. To pursue higher intelligence in space, MLLMs require integrating multiple atomic spatial capabilities to handle complex and dynamic tasks. However, existing benchmarks struggle to comprehensively evaluate the spatial intelligence of common MLLMs from the atomic level to the compositional level. To fill this gap, we present SpaCE-10, a comprehensive benchmark for compositional spatial evaluations. In SpaCE-10, we define 10 atomic spatial capabilities, which are combined to form 8 compositional capabilities. Based on these definitions, we propose a novel hierarchical annotation pipeline to generate high-quality and diverse question-answer (QA) pairs. With over 150+ hours of human expert effort, we obtain over 5k QA pairs for 811 real indoor scenes in SpaCE-10, which covers various evaluation settings like point cloud input and multi-choice QA. We conduct an extensive evaluation of common MLLMs on SpaCE-10 and find that even the most advanced MLLM still lags behind humans by large margins. Through our careful study, we also draw several significant findings that benefit the MLLM community. For example, we reveal that the shortcoming of counting capability greatly limits the compositional spatial capabilities of existing MLLMs. The evaluation code and benchmark datasets are available at https://github.com/Cuzyoung/SpaCE-10.
Benchmarking Abstract and Reasoning Abilities Through A Theoretical Perspective
May 28, 2025



In this paper, we aim to establish a simple, effective, and theoretically grounded benchmark for rigorously probing abstract reasoning in Large Language Models (LLMs). To achieve this, we first develop a mathematic framework that defines abstract reasoning as the ability to: (i) extract essential patterns independent of surface representations, and (ii) apply consistent rules to these abstract patterns. Based on this framework, we introduce two novel complementary metrics: \(\scoreGamma\) measures basic reasoning accuracy, while \(\scoreDelta\) quantifies a model's reliance on specific symbols rather than underlying patterns - a key indicator of true abstraction versus mere memorization. To implement this measurement, we design a benchmark: systematic symbol remapping in rule-based tasks, which forces models to demonstrate genuine pattern recognition beyond superficial token matching. Extensive LLM evaluations using this benchmark (commercial API models, 7B-70B, multi-agent) reveal:1) critical limitations in non-decimal arithmetic and symbolic reasoning; 2) persistent abstraction gaps despite chain-of-thought prompting; and 3) \(\scoreDelta\)'s effectiveness in robustly measuring memory dependence by quantifying performance degradation under symbol remapping, particularly highlighting operand-specific memorization. These findings underscore that current LLMs, despite domain-specific strengths, still lack robust abstract reasoning, highlighting key areas for future improvement.
Zooming from Context to Cue: Hierarchical Preference Optimization for Multi-Image MLLMs
May 28, 2025Multi-modal Large Language Models (MLLMs) excel at single-image tasks but struggle with multi-image understanding due to cross-modal misalignment, leading to hallucinations (context omission, conflation, and misinterpretation). Existing methods using Direct Preference Optimization (DPO) constrain optimization to a solitary image reference within the input sequence, neglecting holistic context modeling. We propose Context-to-Cue Direct Preference Optimization (CcDPO), a multi-level preference optimization framework that enhances per-image perception in multi-image settings by zooming into visual clues -- from sequential context to local details. It features: (i) Context-Level Optimization : Re-evaluates cognitive biases underlying MLLMs' multi-image context comprehension and integrates a spectrum of low-cost global sequence preferences for bias mitigation. (ii) Needle-Level Optimization : Directs attention to fine-grained visual details through region-targeted visual prompts and multimodal preference supervision. To support scalable optimization, we also construct MultiScope-42k, an automatically generated dataset with high-quality multi-level preference pairs. Experiments show that CcDPO significantly reduces hallucinations and yields consistent performance gains across general single- and multi-image tasks.